DataStreamApi简介
什么可以转化为流
flink的java和scala DataStream API可以将任何可序列化的对象转化为流
1、flink自带的序列化器有
基本类型:String、Long、Integer、Boolean、Array
复合类型:Tuples、POJOs 和 Scala case classes
2、并且flink会交给kryo序列化其他类型。也可以将其他序列化器和 Flink 一起使用。特别是有良好支持的 Avro。
POJOS
如果满足以下条件,flink会将数据类型识别为POJO类型(并允许"按名称"字段引用)
- 公有且独立
- 有公有的无参构造
- 类及父类中所有的不被static、transient修饰的属性要么是公有的且不被final修饰,要么包含公有的getter和setter方法
stream执行环境
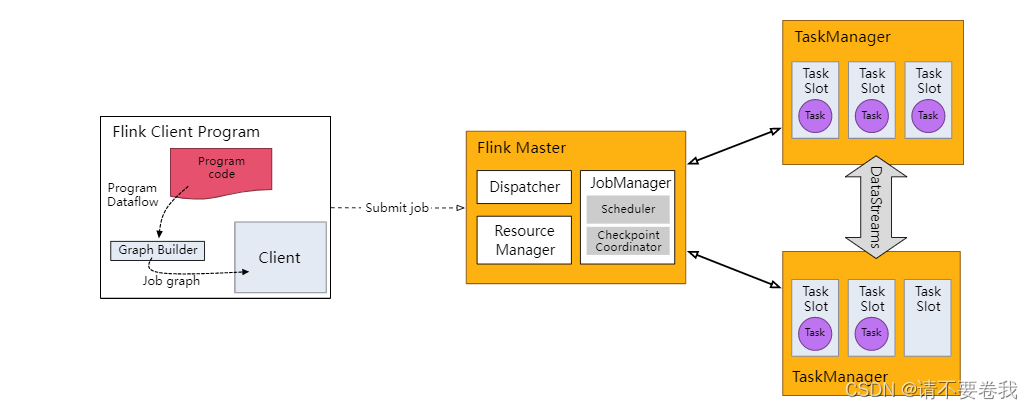
DataStream API将应用构建为一个job graph,并附加到StreamExcutionEnvironment。当调用 env.execute() 时此 graph 就被打包并发送到 JobManager 上,后者对作业并行处理并将其子任务分发给 Task Manager 来执行。每个作业的并行子任务将在 task slot 中执行。如果没有调用 execute(),应用就不会运行
基本的stream source
1、数据类型转换
2、socket接收
3、读取文件
基本的stream sink
使用print()方法打印结果到task manager的日志中。会对流中的每个元素都调用toString()方法