一文搞懂分库分表算法,通俗易懂(基因法、一致性 hash、时间维度)
一文搞懂分库分表算法,通俗易懂(基因法、一致性 hash、时间维度)目录
前言
最近手上一个系统的访问速度有点慢,老早前用多线程优化过一些接口,将一些复杂 sql 改成单表查询,走内存处理,成功的将 一些 10 多秒的接口优化到 500 ms,但是数据量上来了单表查询效率也有点慢了,不得不考虑进行分库分表了,当然我这里只进行分表,没分库,问就是服务器资源紧张!并借此深入总结一下主流的几种分库还有分表算法。分库分表最繁琐的地方在于迁移数据和比对数据!!!!!!
分库分表算法-时间维度
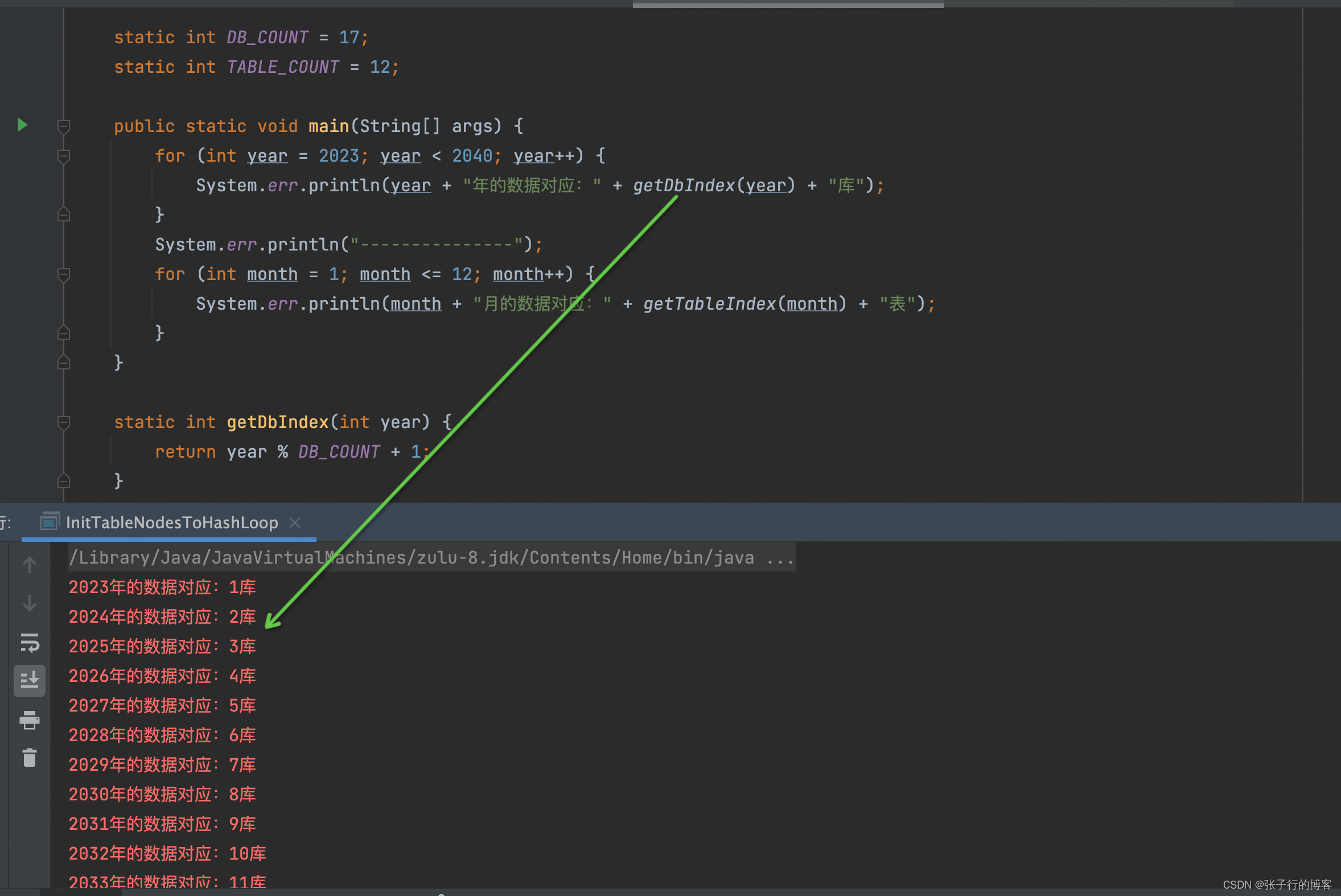
其实分库分表配置很简单,复杂的是旧数据的迁移还有校对。以及后续需要考虑的扩容。举个例子按时间维度扩容很简单,分库算法:按年对库的总数进行取模。分表算法:按月对表的总数进行取模。用代码实现如下
static int DB_COUNT = 17;
static int TABLE_COUNT = 12;
public static void main(String[] args) {
for (int year = 2023; year < 2040; year++) {
System.err.println(year + "年的数据对应:" + getDbIndex(year) + "库");
}
System.err.println("---------------");
for (int month = 1; month <= 12; month++) {
System.err.println(month + "月的数据对应:" + getTableIndex(month) + "表");
}
}
//分库算法
static int getDbIndex(int year) {
return year % DB_COUNT + 1;
}
//分表算法
static int getTableIndex(int month) {
return month % TABLE_COUNT + 1;
}
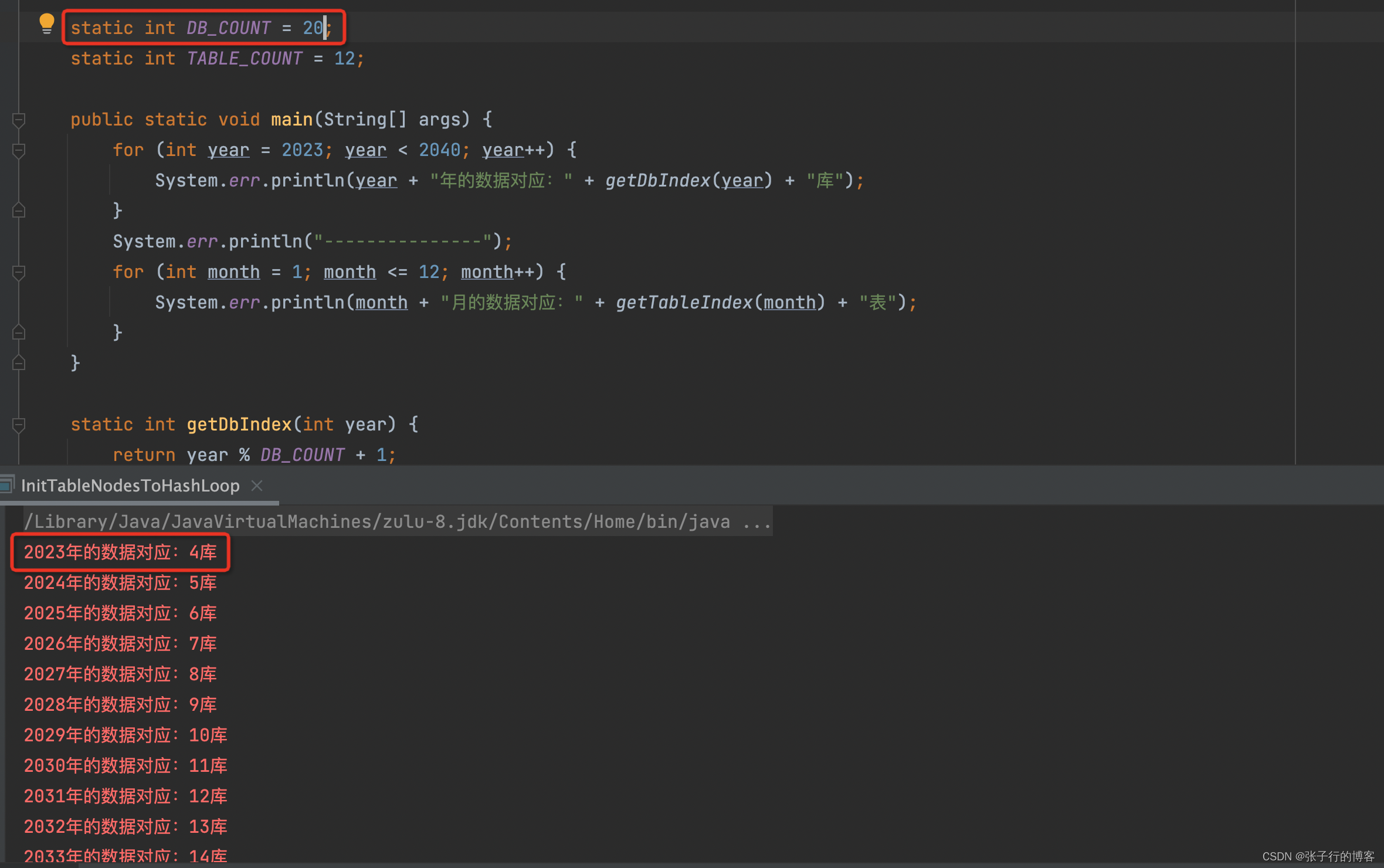
可以看到 2023 年到 2040 年的数据被划分到了我们的 1-17 库中,当我们需要扩容到 20 个库的时候需要做什么操作呢?请看下文
当扩容到 20 个库的时候,原本在 1 库 2023 年的数据需要迁移到 4 库,2 库 2024 年的数据需要迁移到 5 库。其他年的数据同理比对迁移,这个迁移好办对整个库迁移,直接改配置文件就行。
取模操作相对来说比较好理解接下来介绍一下基因法分库分表算法
分库分表算法-基因替换法(使用)
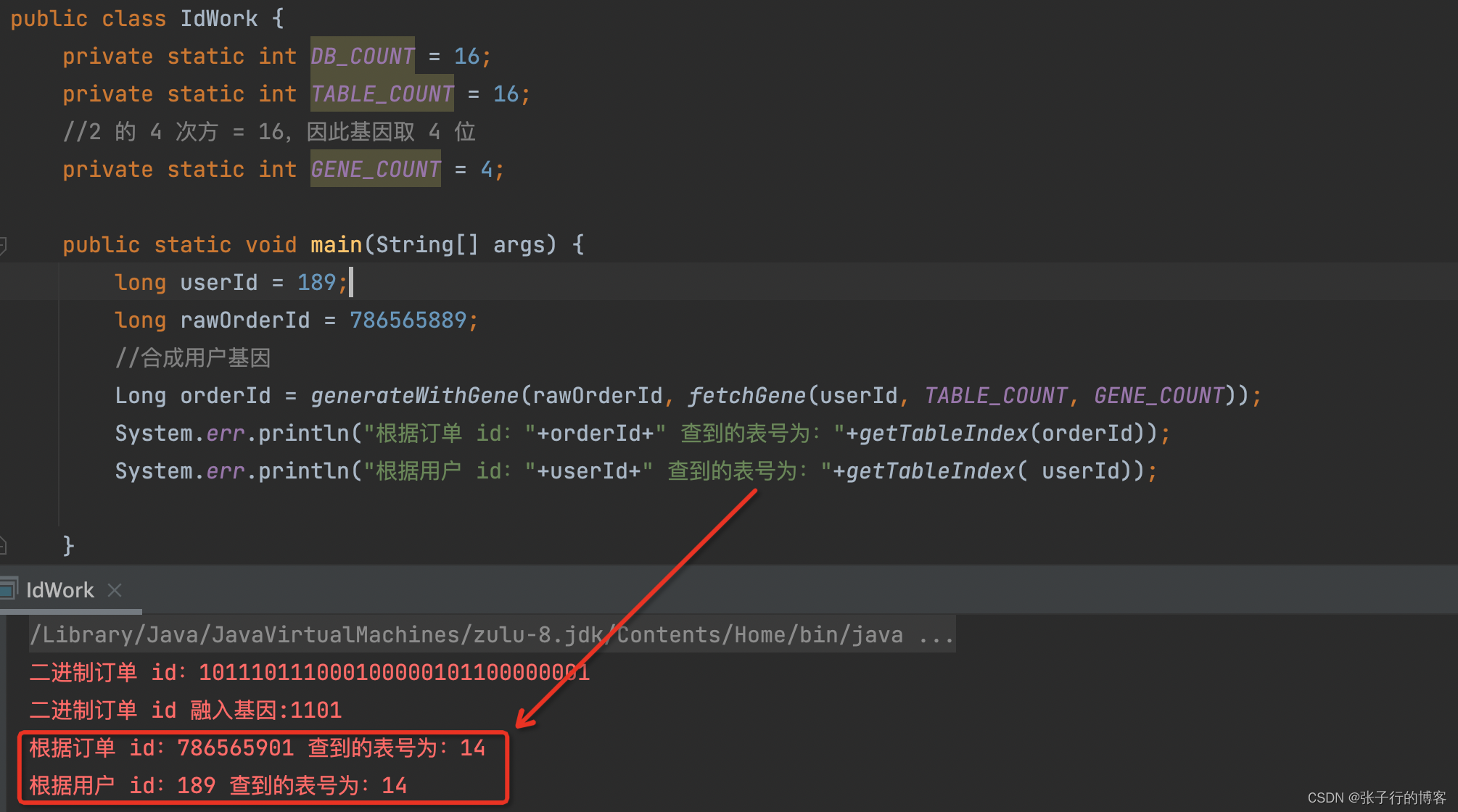
现在有这么一个需求,让同一个用户的所有订单全部存到一个表里面,且查询的时候让开发者既可以通过用户 id ,也可以通过订单 id ,做到精准查询这一个表,避免查询所有表的情况出现,这个需求该怎么实现呢?这个时候就可以用基因法去实现了,基因法其实就是利用了一个
取模的特性:(前提被除数是 2 的 n 次方,除数除以被除数的得到的余数,这个余数转换成二进制一定会等于除数二进制最后 n 位)
基因法举个例子来说:189%16 = 13
- 189 对应二进制:10111101
- 13 对应二进制:1101
- 16 为 2 的 4 次方
那么13 对应的二进制数是不是等于 189 二进制数最后四位,都是 1101。将这个 1101 的基因随便替换一个二进制数后四位,然后对 16 取模得到的余数都是 13。请看下图用 189 的基因填充随便一个订单 id 中,无论用用户 id 对 16 取模还是订单 id 对 16 取模最终得到的表号都是 13。我下图取模那里对结果加了 1 所以是 14!!!!
说了这么多那难道基因法就没有缺点了吗,答案肯定是有的,我这里如果大家项目中用到的 id 是雪花算法生成的,在替换基因的时候是直接把基因拼接还是替换后 n 位?接下来来聊一下优缺点。
分库分表算法-基因替换法(缺点之扩容难)
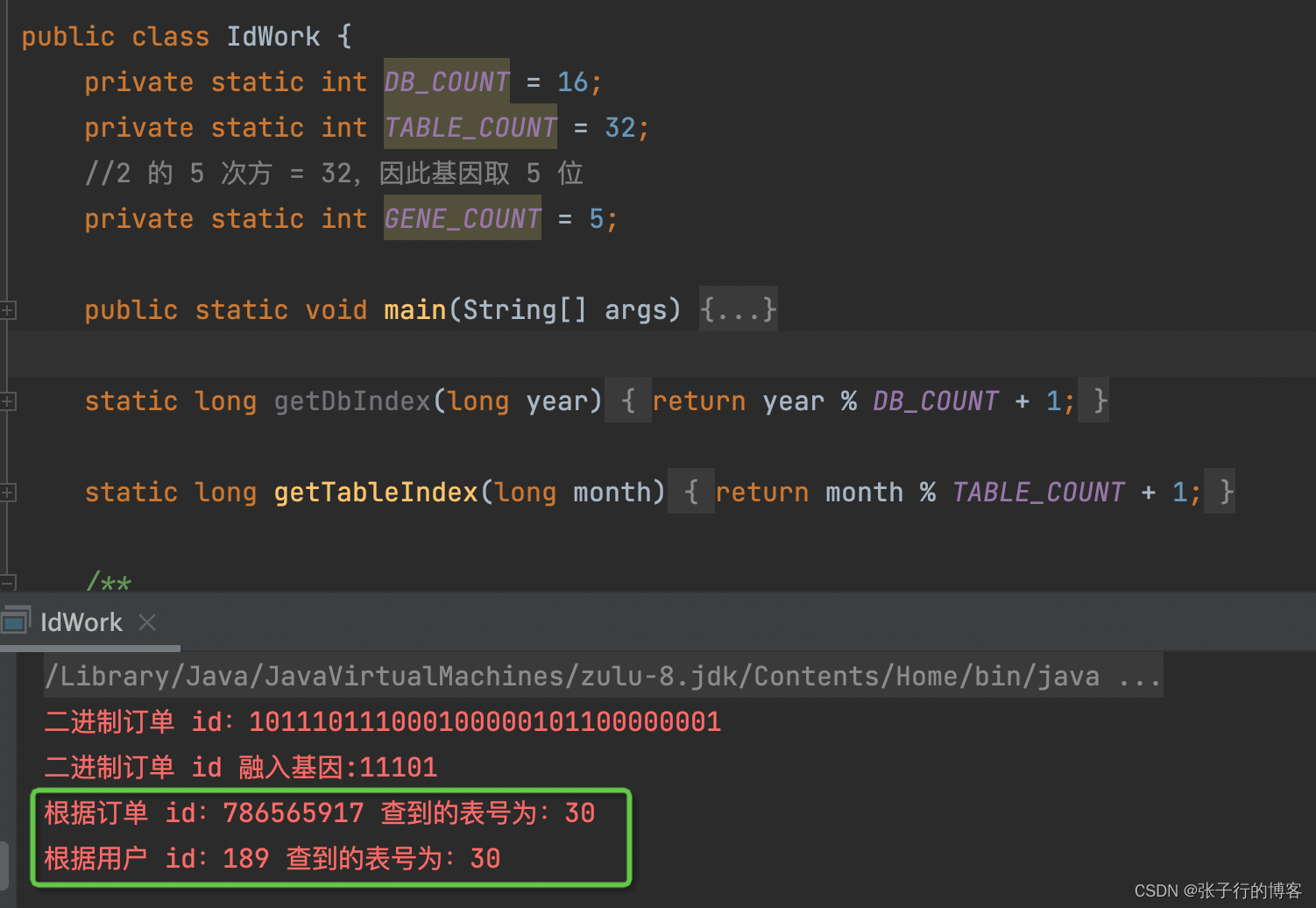
其实基因替换法本质也是取模操作,这玩意一但后续要扩容,举个例子有个用户的 id 是 189 原本所有的订单都存储在 14 表,现在需要扩容到 32 个表,该用户所有的订单数据需要全部迁移到 30 表,其他用户的订单数据同理迁移,迁移完后还要写脚本进行校验数据。这个就是他的缺点!优点就是查询速度快,因为可以通过基因取模快速得到精准的表号,避免查所有表,查询效率高,是你你会怎么选择呢?
分库分表算法-基因替换法(缺点之容易生成重复订单号)
what 发?熟悉雪花算法的朋友们应该知道,雪花算法可以生成唯一的分布式 id,其原理就是利用二进制的移位运算得到唯一 id。找一张烂大街雪花算法图贴上来。

在顺时高并发下可能生成如下俩个雪花 id,问他们是怎么生成的就是同一机器统一毫秒内,序列号相差 1 这种情况下生成的,假设这时候我们是分 16 张表,因此需取 4 位基因替换订单 id 后 4 位。这时候俩个生成的俩个订单 id 是不是就重复了。替换完成后对应的二进制都相同了。但是这种情况发生的概率很低。需要满足条件(同一个用户在一毫秒内创建了 2 个订单,除非是机器刷单感觉是个正常人都遇不到这个情况)。那有人抬杠了,我绝不容忍我的代码有任何的潜在风险,有什么好的解决办法解决这个问题吗?答案肯定是有的。自己改造雪花算法将基因拼接上去或者不用雪花算法,自己写一个订单 id 生成逻辑。
1147200516128903171 对应二进制111111101011101011001100101010010010000000100001000000000100
1147200516128903172 对应二进制
111111101011101011001100101010010010000000100001000000000011
分库分表算法-基因拼接法介绍
顾名思义将基因拼接到订单 id 上去,这里着重说一下雪花算法,先贴一下烂大街的雪花算法源码
/**
* 常规雪花算法:1-42bit位:时间戳 (共 42 位)
* 43-47 bit位:数据中心ID (共 5 位,最大支持 2 的 5 次方减 1 个数据中心)
* 47-52 bit位:工作台ID (共 5 位,最大支持 2 的 5 次方减 1 个工作台)
* 52-64 bit位:累加数ID (共 12 位,最大支持 2 的 12 次方)
*/
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
}
else {
sequence = 0L;
}
lastTimestamp = timestamp;
// System.err.println(Long.toBinaryString((timestamp - twepoch) << 19));
// System.err.println(Long.toBinaryString(datacenterId << 17));
// System.err.println(Long.toBinaryString(workerId << 12));
// System.err.println(Long.toBinaryString(sequence));
return ((timestamp - twepoch) << 22)
| (datacenterId << 17)
| (workerId << 12)
| sequence;
}
我们直接进行改造,留 7 bit 位给序列号,留 5 bit 位给用户基因对应的 10 进制数,让其最大支持 32 张表。
((timestamp - twepoch) << 22)
| (datacenterId << 17)
| (workerId << 12)
| (sequence << 5)
| 截取的用户基因转换成的 10 进制数;
这样雪花算法原本的 bit 位我们不做干预,是不是可以避免订单号重复的问题了?下面做个简单测试来验证一下。
分库分表算法-基因拼接法使用
改造雪花算法后的代码如下,这里不清楚雪花算法源码的读者,后续我会专门写一篇博客介绍雪花算法的原理
41 bit 位时间戳,5 bit 位数据中心,5 bit 机器位,5 bit累加位,7 bit 用户基因位拼接在最后,加上符号标识位正好 64 bit 位
使用的话一行代码即可生成分库分表的唯一订单 id!!!!!
snowflakeIdWorker.nextUserId(userId % TABLE_COUNT)
public synchronized long nextUserId(long uid) {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
//41 bit 位时间戳,8 bit 位业务编码,5 bit 机器位,9 bit累加位
//long userId = (timestamp - idepoch) << 22 | machineId << 14 | busid << 9 | this.sequence;
//41 bit 位时间戳,5 bit 位数据中心,5 bit 机器位,5 bit累加位,7 bit 用户基因位
return ((timestamp - twepoch) << 22)
| (datacenterId << 17)
| (workerId << 12)
| sequence << 7
| uid;
}
基因拼接、替换法生成重复订单号数量对比测试
基因替换法:一个用户秒级下 100 单,只有 10 个订单号可用
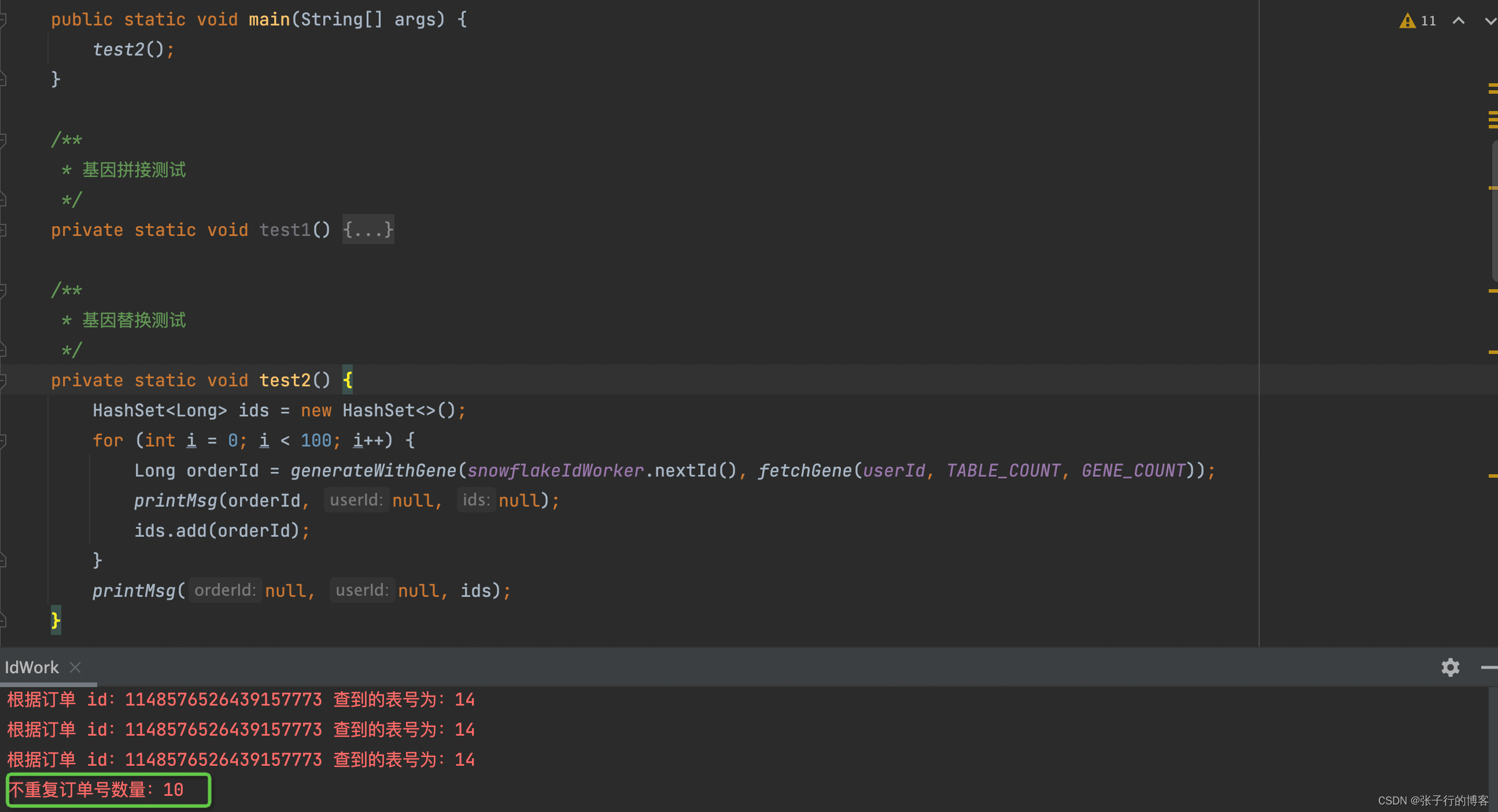
基因拼接法:一个用户毫秒级下 100 个订单有 79 个订单号可用
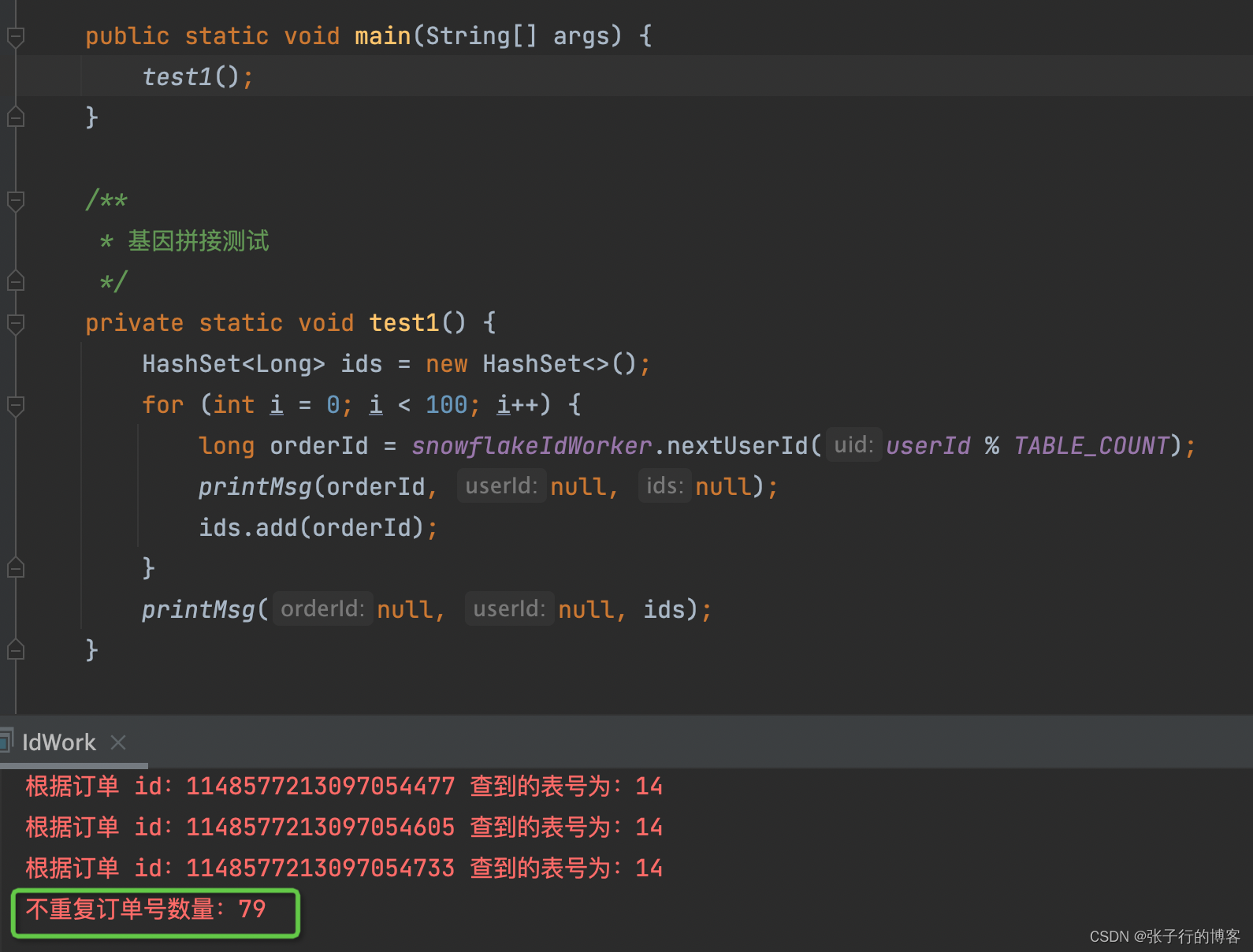
通过俩者的对比可见,使用雪花算法生成的订单 id,在毫秒级采用基因法生成的订单号不能避免重复的现象,只能去规避他。原因也很好理解,拿我改造过后的雪花算法来说,变量只有累加位,累加 bit 位只留 5 位,也就是最大累加 2 的 5 次方(32),累加到 4(00100)时一切正常 00100 正常参与或运算,累加到 36(100100)时,二进制有 6 位,和我们规定的 5 位超了一位,有效参与到计算的实际上是 00100,这时候变量累加位也一致了,恰好此时第 100100 的第一位 1 参与或运算对结果没影响,此时的订单号是不是就重复了!
说了这么多,其实这个累加位就是毫秒时间内可最大生成不重复 id 的个数!!!!!
return ((timestamp - twepoch) << 22)
| (datacenterId << 17)
| (workerId << 12)
| sequence << 7
| uid;
由于我们累加有效位只留 5 bit 位,最大毫秒级别生成 2 的 5 次方,也就是 32 个无重复订单号生成,因此将循环次数降低至 32,可以看到压根不会有重复订单号产生!!!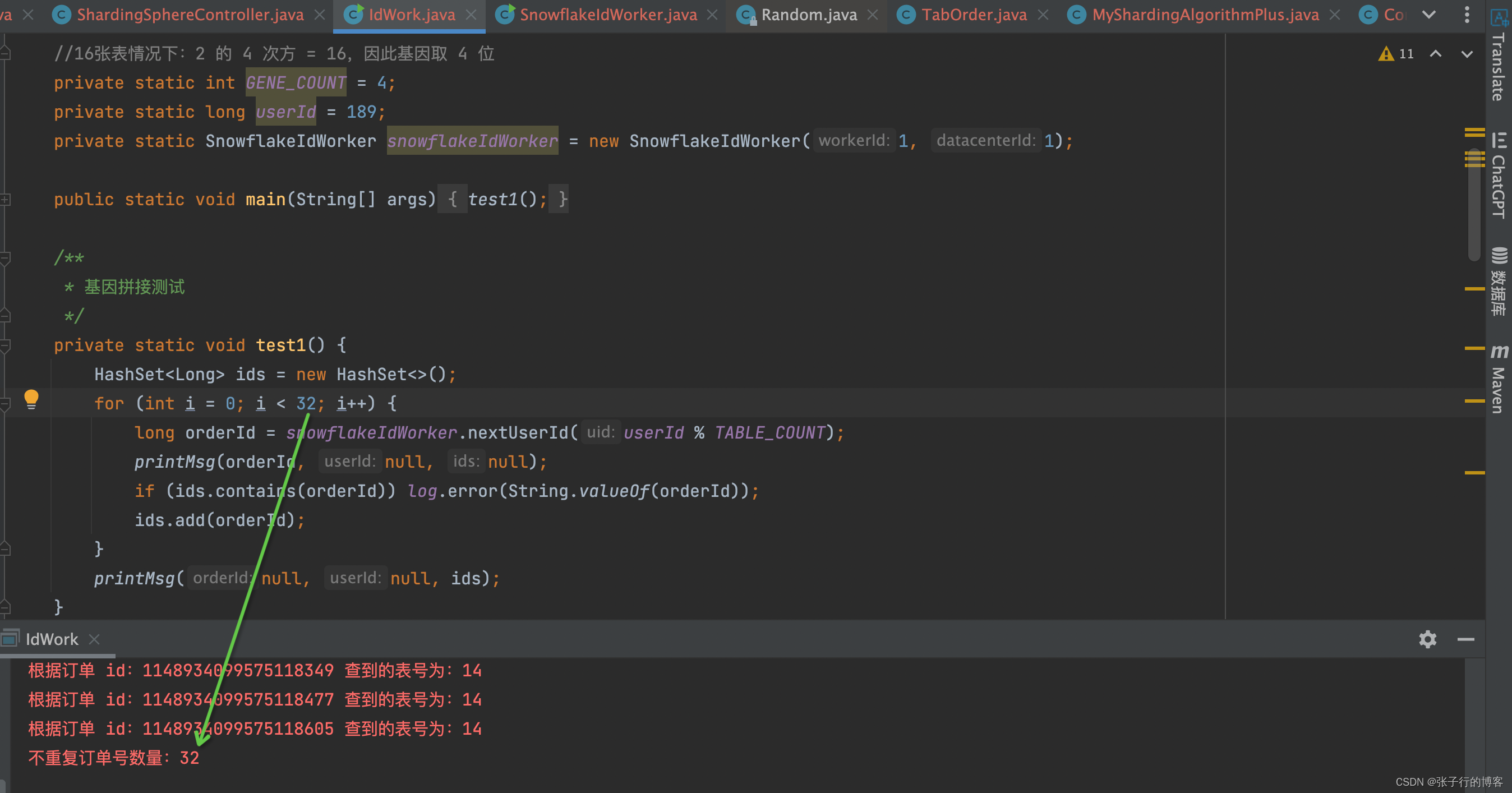
因此大家在使用雪花算法的时候,可以根据实际情况调节机器 bit、累加位、用户基因位的大小
分库分表算法之一致性 Hash 法(使用)
假设有 4 张表,表名分别是 order1,order2,order3,order4。他们的 hash 值不用说肯定是递增的,假设 hash 值依次为 1,3,5,7。把四个表平均分摊到一个圈里面
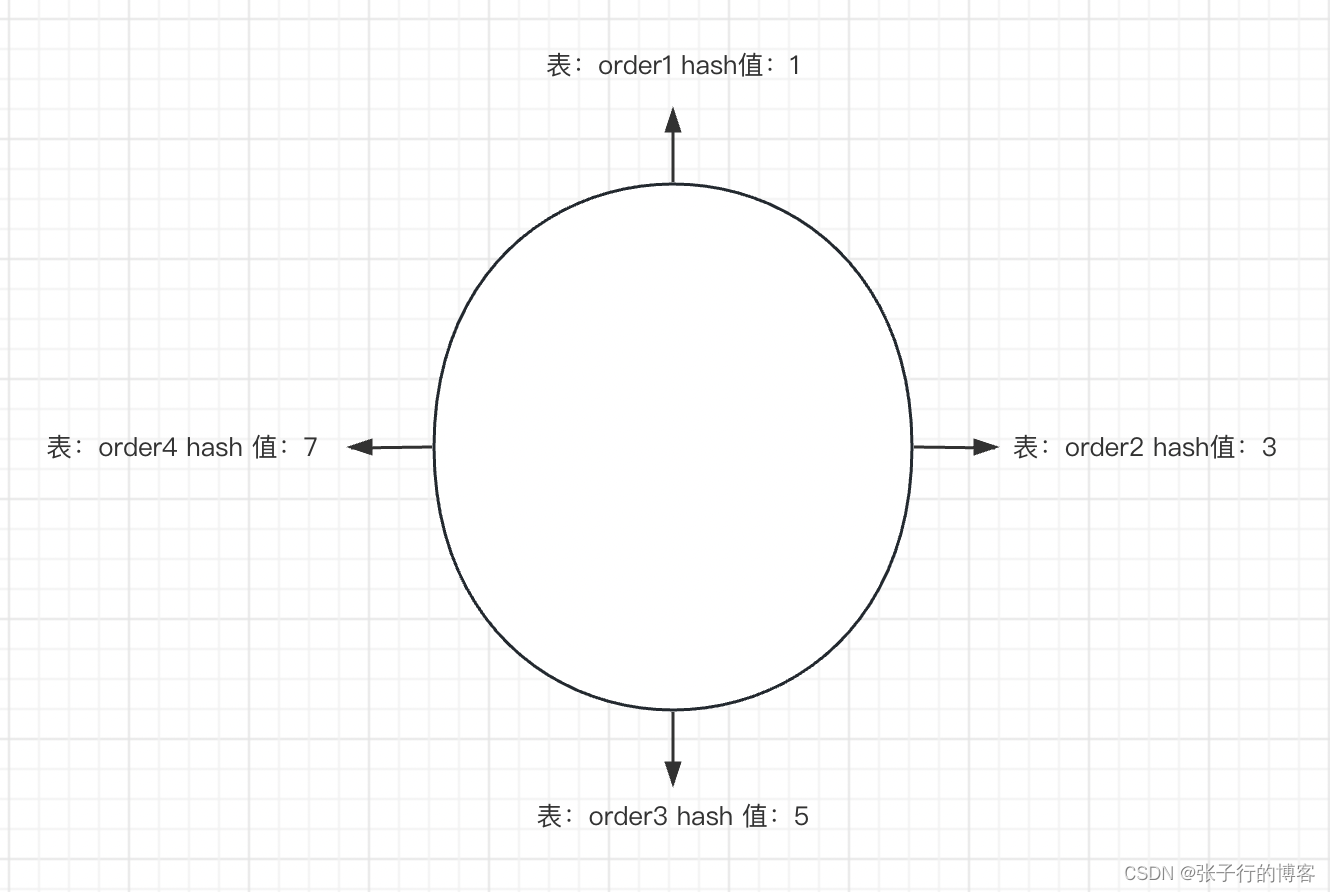
假设此时的分区键是 id,这个时候有一条 id 为 2 的数据需要入库,假设 id 为 2 的这条数据 hash 值为 2。与 hash 环上的所有 hash 值进行比较,获取 hash 值大于 2 的所有节点其中最近的一个节点,发现只有 order2 对应的 hash 匹配,于是这条数据就被入库到 order2 表中了.其实就是 hash 值 1 到 3 的数据落库到 order2 表, hash 值 3 到 5 的数据落库到 order3 表, hash 值 5 到 无穷大 的数据落库到 order1 表
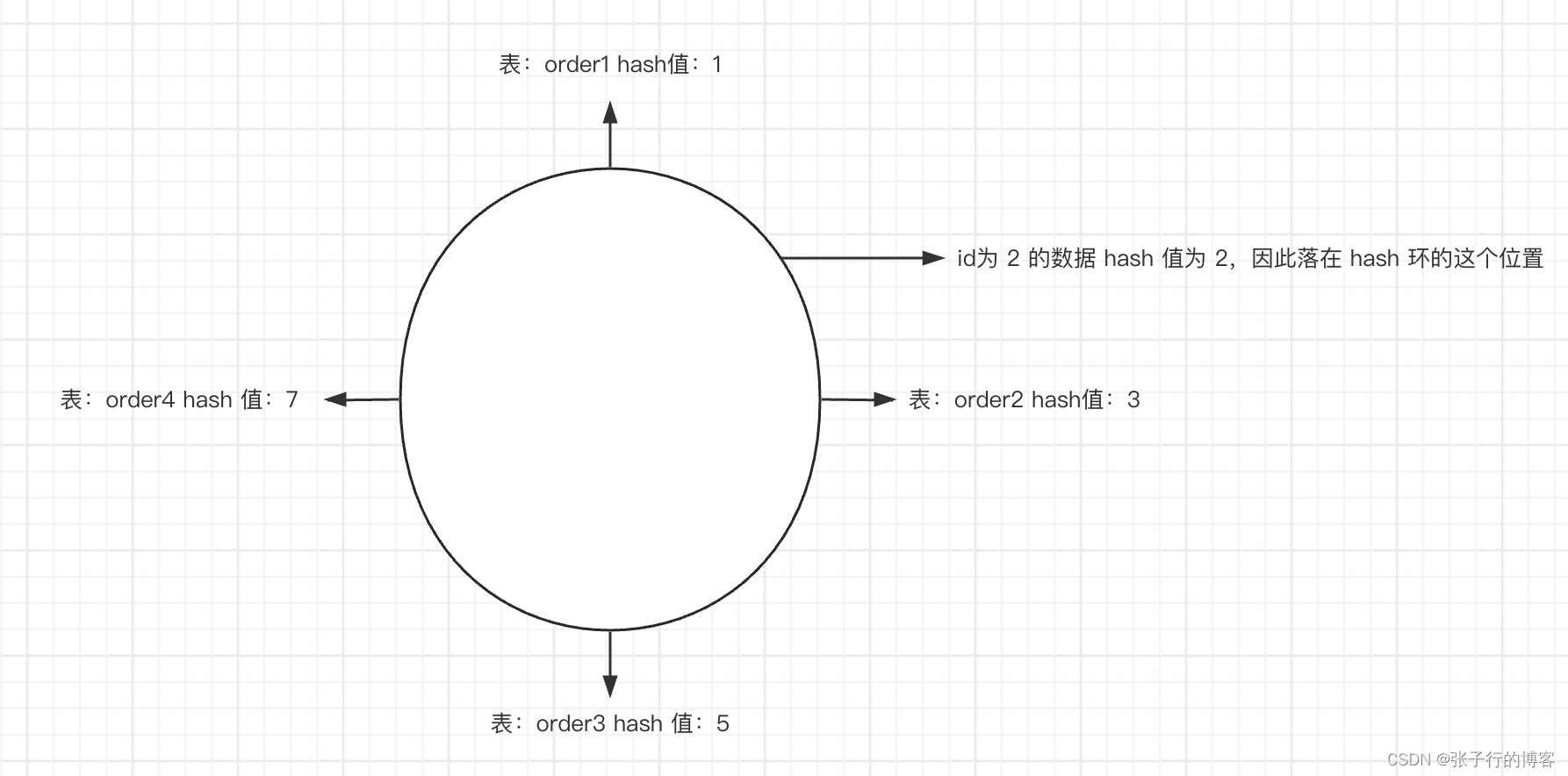
查数据的时候由于用的都是一致性 hash 算法,因此查也只会查 order2 表。这个就是一致性 hash 算法。
分库分表算法之一致性 Hash 优缺点
- 缺点就是:由于数据都是随机离散分布到各个表或者库中,如果需要查某个用户下的所有订单时需要扫描所有表。
- 优点就是:数据散列均匀,扩容的时候只会影响扩容节点的下一个节点,其他节点的数据正常查询
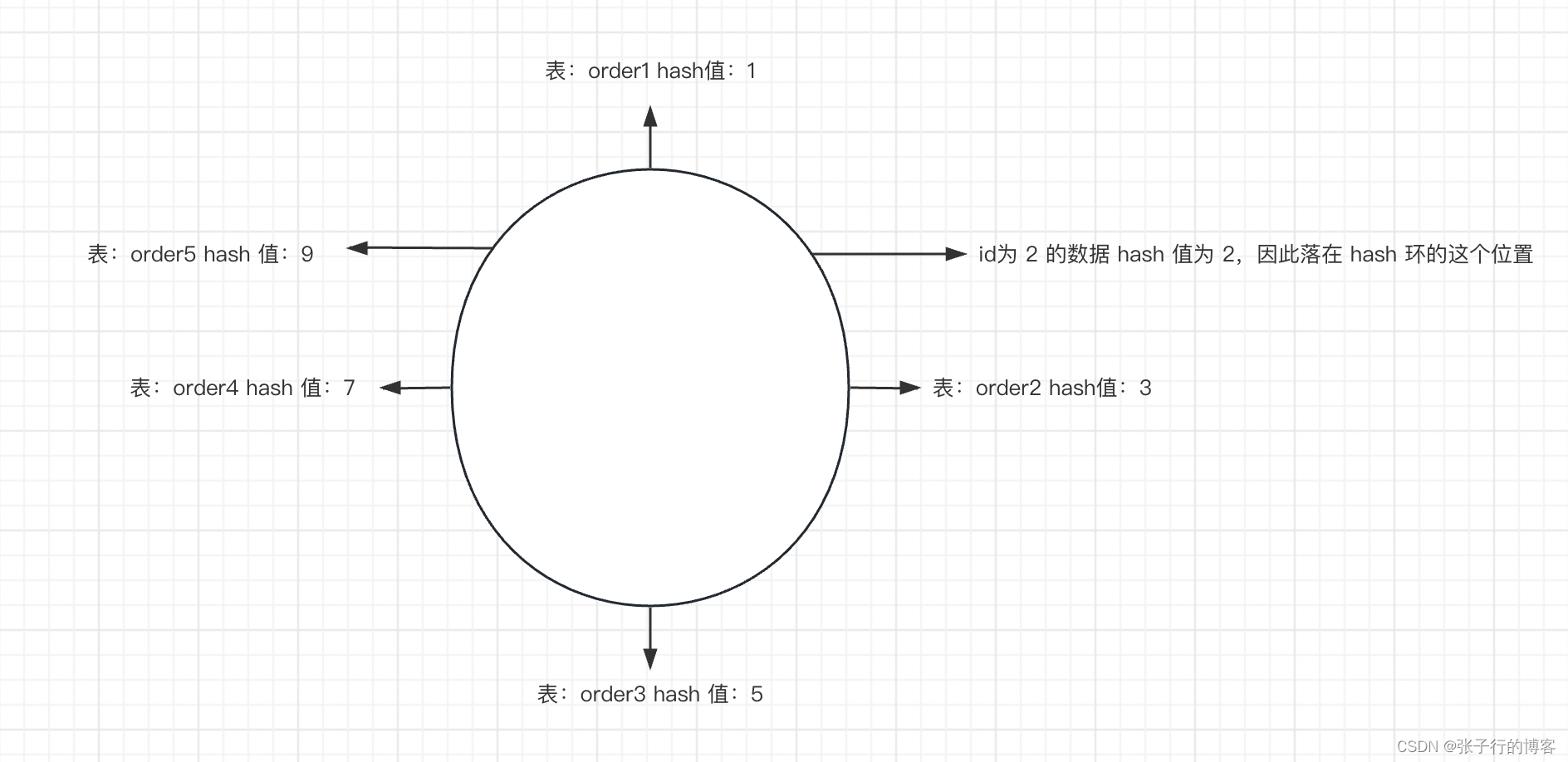
现在新加了 order5 表落在 hash 环上的如下位置,原本 hash 值为 8 的数据是在 order1 表的,由于扩容的原因,现在去查 order5 表去了 ,因此查不到数据,这个时候就需要把 order1 表中 hash 值为 7 到 9 的数据全部迁移到 order5 表了。这样就完成了扩容!!!!
小咸鱼的技术窝
关注不迷路,日后分享更多技术干货B站、CSDN、微信公众号同名,名称都是(小咸鱼的技术窝),更多详情在主页
