运用Python抓取PDF表格中的特定数据并生成Excel文件
在工作中遇到了一个问题,需要把PDF中的地方债数据粘贴到Excel表格中,在PDF的每个表格中需要找到“金额”“本息和”“项目总收益”“项目名称”“项目类型”……等等数据。每一页表格需要复制粘贴十次,一共四百多页的PDF岂不是要复制粘贴八千次!眼瞎了都粘不完吧!于是我开始尝试用Python来读取PDF表格,然后找到每个表格对应位置的数据,对应到新生成的序列中,最后导出为Excel。
如图一,这是PDF中每一页记录的地方债项目数据。

我需要的Excel表格如下图所示:

接下来就是代码展示:
处理单页PDF的代码
首先运用pdfplumber,如果没有安装需要先安装:
pip install pdfplumber
安装后就可以开始使用了:
import pdfplumber
#导入使用的库
# 读取pdf文件,使用的时候改成自己的路径就行
pdf = pdfplumber.open('D://test1.pdf')
# 访问第一页(使用时改成自己需要的页码即可,页码-1等于[]中需要填的数字
first_page = pdf.pages[0]
# 自动读取表格信息,返回列表
table = first_page.extract_table()
print(table)我读取了对应页码的数据,输出结果如下:

这些数据看起来乱七八糟的,我需要把其中的“None”给去掉:
table = [[cell for cell in row if cell is not None and cell != ''] for row in table]
#table中乱七八糟的none就被去掉了
#接下来将列表转化为dataframe的结构,然后就可以进行进一步操作了
import pandas as pd
# 将列表转化为dataframe
table_data = pd.DataFrame(table)
table_data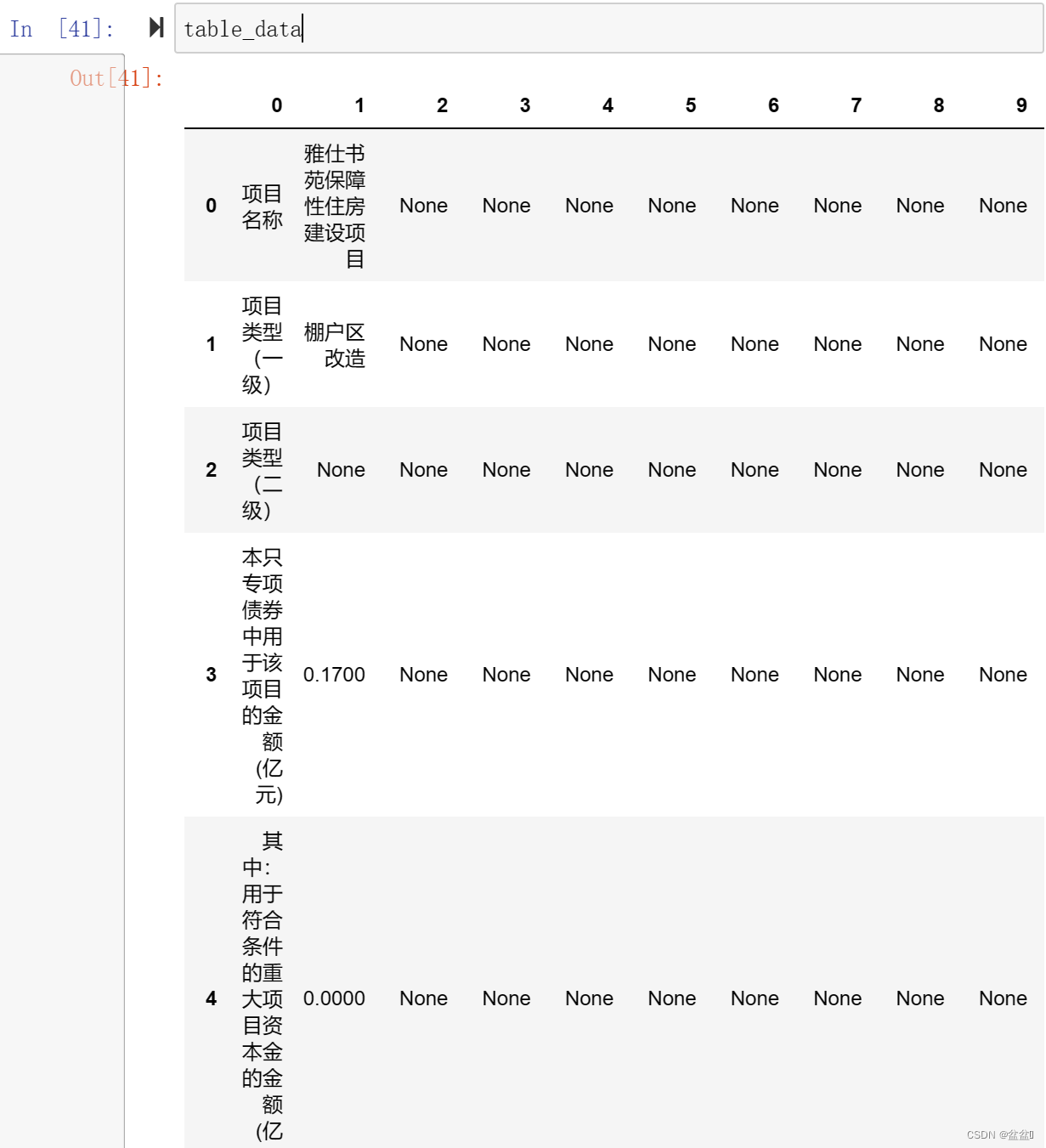
这是输出的结果,我们可以看到,已经出现了表格的形状,接着我们就可以精准定位我们想要的数据所在的位置了,例如第一行第二列的那个数据,就可以表示为table[0][1]
接下来的代码如下:
#生成一个新的表格序列,用来存储我们抓取到的数据
df = pd.DataFrame(columns=["城市", "项目名称", "项目类型(一级)", "项目类型(二级)", "金额(本金)", "期限", "计划总投资", "项目总收益", "本息和", "信用评级结果", "还本方式"])
#变量名称和后面的坐标位置根据实际情况来进行调整
city = ","
project_name = table[0][1]
project_type_1 = table[1][1]
project_type_2 = table[2][1]
amount = table[3][1]
duration = table[5][1]
planned_investment = table[9][1]
total_return = table[17][1]
principal_interest = table[28][1]
credit_rating = "AAA"
repayment_method = "分期还本"
#将抓取到的数据对应到表格序列中
df = df.append({
"城市": city,
"项目名称": project_name,
"项目类型(一级)": project_type_1,
"项目类型(二级)": project_type_2,
"金额(本金)": amount,
"期限": duration,
"计划总投资": planned_investment,
"项目总收益": total_return,
"本息和": principal_interest,
"信用评级结果": credit_rating,
"还本方式": repayment_method
}, ignore_index=True)
#最后输出excel表格即可。路径根据自己实际需要修改
output_file = "D:\\test1.xlsx"
df.to_excel(output_file, index=False)
遍历每一页的工作代码:
上面只是单页的代码,你可以根据单页的情况来确定定位表格位置的数据,接下来展示遍历每一页的代码:
import pdfplumber
import pandas as pd
pdf = pdfplumber.open('D://test1.pdf')
df = pd.DataFrame(columns=["城市", "项目名称", "项目类型(一级)", "项目类型(二级)", "金额(本金)", "期限", "计划总投资", "项目总收益", "本息和", "信用评级结果", "还本方式"])
#遍历每一页
for page in pdf.pages:
table = page.extract_table()
if table is not None:
table = [[cell for cell in row if cell is not None and cell != ''] for row in table]
print(f"Page {page.page_number}:")
for row in table:
print(row)
#此处要注意,我处理的pdf中,有些页面的表格是不对的,所以我确定了表格大于30行时才是我需要的表格,这里30这个数据根据实际情况调整,一般情况改为0也可以。
if len(table) >= 30 :
project_name = table[0][1]
project_type_1 = table[1][1]
#此处注意,我的pdf表格中,有些表格的项目类型二是空的,直接运行会报错,或者会忽略掉整条数据,因此这条代码的含义是,空着的就显示空就行。
try:
project_type_2 = table[2][1]
except IndexError:
project_type_2 = None
#其他变量如果有空的情况也可以用上面的这种格式来处理
amount = table[3][1]
duration = table[8][1]
planned_investment = table[9][1]
total_return = table[17][1]
principal_interest = table[28][1]
credit_rating = "AAA"
repayment_method = "分期还本"
df = df.append({
"城市": "",
"项目名称": project_name,
"项目类型(一级)": project_type_1,
"项目类型(二级)": project_type_2,
"金额(本金)": amount,
"期限": duration,
"计划总投资": planned_investment,
"项目总收益": total_return,
"本息和": principal_interest,
"信用评级结果": credit_rating,
"还本方式": repayment_method
}, ignore_index=True)
output_file = "D:\\test1.xlsx"
df.to_excel(output_file, index=False)
这样运行过后,上百页的pdf,原本要把眼睛都复制粘贴瞎的excel表格就生成出来了!
工作效率大大提升!
另外大家在代码使用过程中有什么问题也可以问chatgpt,根据实际情况去调试~