【C++】引用详解
前言
在学习C语言时,我们通常会遇到两个数交换的问题,为了实现这一功能,我们会编写一个经典的Swap函数,如下所示:
void Swap(int *a, int *b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}然而,这个Swap函数看起来可能有些繁琐,需要使用指针和解引用操作符。相比之下,C++引入了引用的概念,使得代码更为简洁:(这两个函数还构成了函数重载哦)
void Swap(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}并且引用避免了直接操作指针和解引用的繁琐性,调用时也更加直观,如下所示:
Swap(a, b);虽然这个例子中看似只是减少了取地址的操作,但引用的使用远不止于此。可能你这里会有点懵圈,但没关系,接下来我们将详细探讨引用。
注意:本篇博客中的代码均基于包含头文件 <iostream> 并在使用命名空间 std 的前提下编写。
概念
引用不是新定义一个变量,而是给已存在的变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。比如在外面别人以你的名字来称呼你,而在家中亲人以你的小名称呼你。
用法:类型& 名字 = 引用的变量(对象)名字;
举个例子:
int main()
{
int a = 10;
int& b = a; // b 就是 a 的引用,也就是 a 的别名
return 0;
}
这样就定义了一个引用。
int main()
{
int a = 10;
int& b = a;
cout << &a << endl; // cout 会自动识别数据类型并输出
cout << &b << endl;
b++;
cout << a << endl; // a 的值变成了 11
return 0;
}程序运行后,可以发现 a 和 b 的地址相同,证实了它们共用同一块内存空间,进一步证明了编译器不会为引用变量单独分配内存。因此我们改变 b 的值其实就是改变 a 的值。
引用特性
int main()
{
int& b; // 报错
int* p; // 可以
return 0;
}在 C++ 中,引用在定义时必须进行初始化,而指针则允许延迟初始化,尽管这并不被推荐。
int main()
{
int a = 1;
int& b = a; // b 是 a 的引用
int& c = a; // c 也是 a 的引用
int& d = b; // b 也可以有引用,也就是说给别名取别名也是可以的
// 这四个变量用的都是同一块内存空间
return 0;
}一个变量可以有多个引用,同时也可以为引用取别名。
int main()
{
int a = 1;
int& b = a;
int c = 2;
b = c; // 这里并不是改变引用的指向,而是把 c 的值赋值给 b,而 b 就是 a
cout << a << endl; // 所以 a 的值变成了 2
int* p = &a;
p = &c; // 而指针是可以改变指向的对象的
return 0;
}引用在被初始化后不能改变其引用的对象,也就是不能改变引用的指向。以变量 a 被引用为例,一旦变量 b 引用了 a,就无法改变 b 引用的对象。与指针不同,指针可以灵活地改变指向的对象,因此在某些情境下,指针仍然是不可或缺的。例如,在数据结构中的链表结构,如果用引用替代结构体中的 next 指针,由于引用不能改变指向,插入新节点时无法将新节点链接到原链表中,试图强行改变引用会导致原节点的丢失。
常引用
int main()
{
const int a = 10;
int& b = a; // 报错
const int& b = a; // OK!!
return 0;
}在这段代码中,变量 a 被 const 修饰后变成了常量,也就意味着 a 的值是无法被修改的,这时候如果让 b 引用 a,那么 b 就具有修改 a 的权限,这就出现了权限的放大,显然是不合理的。为了解决这个问题,我们可以将 b 也用 const 修饰,这样 b 也变为常量,实现了权限的平移。在C语言中,被const 修饰的变量具有常属性,不能修改,但本质还是变量。而在C++中,被 const 修饰的变量则彻底成为常量。
int main()
{
int a = 10;
const int& b = a;
return 0;
}在这里,通过 const 修饰 b,成功限制了通过 b 来修改 a 的值,实现了权限的缩小。这个过程可以类比于 const 修饰指针,可以限制指针的指向,或者限制通过指针来修改指向对象的值。
int main()
{
const int& a = 10;
return 0;
}同样道理,这里的 10 是一个常量,因此在引用它时应该使用 const 进行修饰。
int main()
{
int a = 1;
double& b = a; // 报错
return 0;
}这里报错的原因也是与权限的放大有关。让我们首先回顾一下在 C 语言中学到的隐式类型转换。
int main()
{
int a = 1;
double b = a;
return 0;
}由于 a 和 b 的类型不同,将 a 赋值给 b 时发生了隐式类型转换。在这个过程中并未改变变量 a 的类型,而是创建了一个类型与 b 相同的临时变量来接收 a 的值,然后将这个值赋给了 b。值得注意的是,这个临时变量具有常属性,因此不能被修改。该过程可通过下图表示:
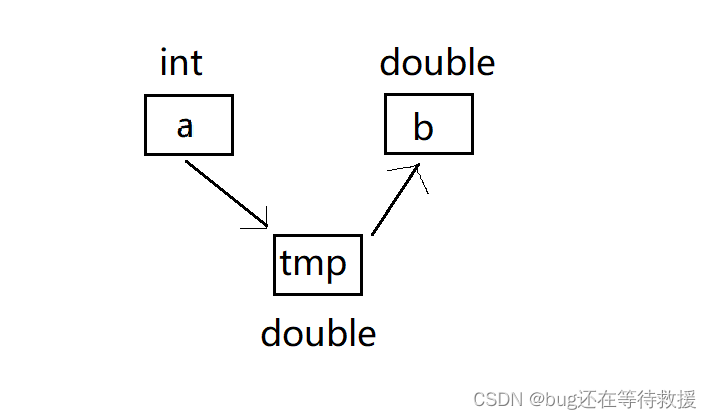 因此,当执行 double& b = a; 时,实际上相当于 double& b = tmp; 这引发了权限的放大,因此我们只需使用 const 来修饰该引用即可。由此可见,在定义引用时,最好让引用类型和引用实体是同类型的,否则需要使用 const 进行修饰,这样会造成无法通过引用来修改对象的值。需要注意的是,在发生类型转换时,都会涉及一个具有常属性的临时变量。
因此,当执行 double& b = a; 时,实际上相当于 double& b = tmp; 这引发了权限的放大,因此我们只需使用 const 来修饰该引用即可。由此可见,在定义引用时,最好让引用类型和引用实体是同类型的,否则需要使用 const 进行修饰,这样会造成无法通过引用来修改对象的值。需要注意的是,在发生类型转换时,都会涉及一个具有常属性的临时变量。
下面我们再来看几个涉及临时变量的例子:
int x = 0;
size_t y = 1;
if (x > y)
{
// ...
}在这个比较中,由于 x 的类型为 int,而 y 的类型为 size_t,所以会发生类型提升,将 x 赋值给一个临时变量,并且其类型与 y 一致。因此在比较时,实际上是比较了两个相同类型的值。 需要注意的是,在这种情况下,如果 x 的值为负数,可能会发生符号扩展。因为在将有符号整数 int 提升为无符号整数 size_t 时,负数会变成一个非常大的正数,这可能会影响比较的结果。
int* ptr = (int*)i;强制类型转换也是如此,i 的类型并没有发生变换,只是借助一个类型为 int* 的临时变量给 ptr 赋值。
int i = 10000;
char ch = i;
在这个例子中,由于 i 的值为 10000,其范围超过了 char 类型的表示范围,发生了截断。在这种情况下,会创建一个类型为 char 的临时变量,将 i 的值截断并赋给 ch。
引用的价值
引用的价值主要在于做参数和做返回值。首先,引用作为函数参数时,可以直接修改传递的实参,同时提高了传参的效率。其次,引用作为函数返回值时,可以直接修改返回的值,并且在传递返回值的过程中提高了效率。接下来,我们将逐一介绍这两种用法。
做参数
我们在前言中改写的 Swap 函数就是引用做参数,接下来看一下引用在单向链表结构中的应用:
typedef struct SListNode
{
struct SListNode* next;
int val;
}SListNode;
void SListPushBack(SListNode** pphead, int val)
{
if (*pphead == NULL)
{
// ...
// *pphead = newnode;
}
else
{
// 找尾,链接newnode
// tail->next = newnode;
}
}我们知道在单向链表中涉及到头节点的修改,因此我们需要传入二级结构体指针。但是我们学习了引用之后就可以简化点了:
typedef struct SListNode
{
struct SListNode* next;
int val;
}SListNode, * PSListNode;
// PSListNode 就是节点指针类型
// SListNode* 等价于 PSListNode
// 这里 phead 是传入的 头节点指针 的别名
void SListPushBack(PSListNode& phead, int val)
{
if (phead == NULL)
{
// ...
// phead = newnode;
}
else
{
// 找尾,链接newnode
// tail->next = newnode;
}
}由于 phead 是 头节点的引用,所以修改 phead 其实就是修改头节点。
引用作为函数参数有助于提升效率。在C语言中,我们了解到函数的形参是实参的一份临时拷贝,因此传递引用与传递指针一样,都可以避免拷贝这一操作。
做返回值
首先来看普通的传值返回:
int Count()
{
int n = 0;
n++;
return n;
}这里返回的是局部变量 n 的拷贝。在函数栈帧销毁前,如果要返回的值比较小,编译器可能会将其存储在寄存器中。然而,对于较大的对象,可能会使用堆栈或寄存器之间的其他内存空间,例如在两个栈帧之间。这种传值返回的方式可能会导致效率下降,特别是对于大型对象而言。
下面我们看一下传引用返回:
int& Count()
{
int n = 0;
n++;
return n;
// 这里返回的是n的别名,相当于n
}
int main()
{
int ret = Count(); // 把 n 这块内存空间的值赋值给 ret
cout << ret << endl;
return 0;
}在vs2019下,程序运行后的结果是 1,然而这是由于该编译器没有及时清理销毁的函数栈帧空间的缘故。这段代码存在悬空引用的问题。返回类型声明为 int&,表示返回一个整数的引用,但函数内部的局部变量 n 在函数结束后会被销毁,导致返回的引用指向一个不再有效的内存位置。尽管某些编译器可能未能检测到这种错误,但这种行为是不安全的,可能导致未定义的行为,如这段程序的结果理应是随机值。为避免悬空引用问题,应该避免返回对局部变量的引用。
再来看一个有趣的例子,同样是返回对局部变量的引用:
int& Add(int a, int b)
{
int n = a + b;
return n;
}
int main()
{
int& ret = Add(1, 2);
cout << "Add(1, 2) = " << ret << endl;
Add(2, 3);
cout << "Add(1, 2) = " << ret << endl;
return 0;
}这段代码中的 ret 是引用,实际上它是指向函数 Add 中局部变量 n 那块空间,但由于 n 是在函数栈上分配的,其生命周期在函数调用结束时就结束了。因此,ret 变成了一个悬挂引用,指向已经释放的内存。这会导致未定义行为,因为在第二次调用 Add 时,编译器可能会复用第一次调用时的栈帧,就是说使用第一次函数调用时开辟的变量 n 那块空间,导致 ret 的值被修改为 5 。值得注意的是,这里的结果可能是由于编译器优化策略导致的,也就是vs2019没有及时清理销毁的栈帧空间。实际结果应该是不确定的随机值。
下面通过一个例子帮助大家更好地理解函数栈帧的复用:
void func()
{
int a = 0;
cout << &a << endl;
}
int main()
{
func();
func();
return 0;
}观察到两次调用该函数后,打印的局部变量 a 的地址是相同的,这证实了函数栈帧空间可以复用。在函数执行完成后,函数的栈帧空间被释放,但由于编译器的优化,第二次调用函数时可以复用第一次调用时的栈帧,因此局部变量 a 的地址保持一致。
总结一下:
函数运行时栈的分配和释放: 在函数运行时,系统会为该函数分配独立的栈空间,用于存储函数的形参、局部变量以及一些寄存器信息等。这确保了函数之间的独立性,每个函数都有自己的栈帧。当函数执行结束后,该函数对应的栈空间会被系统回收,这意味着该栈帧中的内存被标记为可用,但并不是立即被清空。
内存回收但内存仍在:空间被回收指该块栈空间暂时不能使用,但是内存还在。比如:在酒店开了一间房间,时间到了之后要办理退房手续,但是这个房间本身还在,不是说退房后这个房间就没有了。
如果返回的对象是在函数作用域内创建的,它的生命周期将在函数执行结束时终结。在这种情况下,使用引用返回可能导致未定义的行为,因为引用将指向已经被销毁的内存。因此,在这种情况下,引用作为返回值是没有意义的,并可能导致程序错误,得到的结果取决于编译器是否及时清理栈帧。相反,如果返回值是存放在静态区或堆区的(通过动态内存分配),那么对象的生命周期不受函数作用域的限制。在这种情况下,引用作为返回值是安全的,并且可以提升效率。
int& Add(int a, int b)
{
static int c = a + b;
return c;
}由于变量 c 被 static 修饰,因此它是静态局部变量,出作用域不会销毁,这时候返回对 c 的引用是安全的,需要注意的是,静态局部变量只在第一次调用函数时进行初始化,后续调用函数时 c 的值不会改变。值得强调的是,当我们在函数中定义一个静态局部变量时,它实际上只是一个声明,真正的内存空间分配和初始化则发生在第一次调用该函数时。如果程序在运行时没有执行包含该静态局部变量的函数,系统将不会为该变量分配内存空间,也不会执行初始化操作。
int& Add(int a, int b)
{
static int c;
c = a + b;
return c;
}稍加改动就可以实现返回值随着参数的变化而变化了。
相对于传值返回,在处理较大的返回值对象时,传引用返回通常能够提高效率。这是因为传值返回涉及对返回对象的临时拷贝,而传引用允许直接操作原对象,避免了不必要的复制操作,从而提升了性能。此外,传引用返回在一些需要修改返回对象的场景中非常实用,例如顺序表中的数据修改操作。
引用与指针
底层实现
从语法上来看引用就是一个别名,没有独立空间,和它引用的对象共用同一块空间。这一点我们在前面的例子中通过打印地址也能看到确实是一样的。但是从底层来看,引用的实现方式和指针是一样的,也就是说它其实是有空间的。
int main()
{
int a = 10;
int* p = &a;
int& ref = a;
return 0;
}这段代码的汇编代码如下图所示:
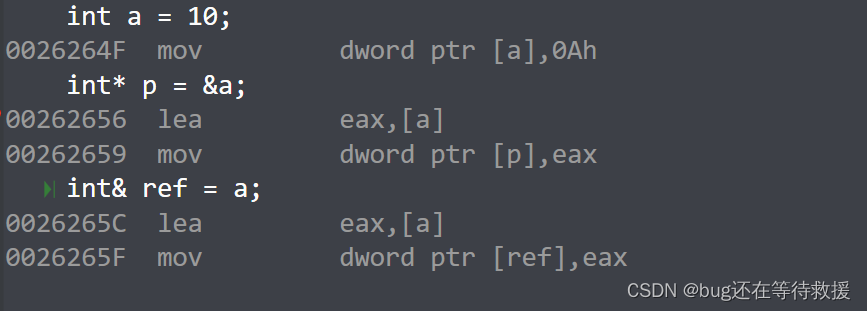
可以看到都是有取地址这个指令的,因此从底层来看引用是按照指针方式来实现的。但平时我们使用时,就当引用是没有独立空间的即可。
不同之处
1. 引用概念上是定义一个变量的别名,而指针则是存储一个变量的地址。
2. 引用在定义时必须初始化,而指针则没有这个要求,但需提防野指针问题。
3. 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
4. 没有NULL引用,但有NULL指针
5. 在 sizeof 中含义不同:引用的大小为引用类型的大小,而指针的大小始终是地址空间所占字节个数(32 位平台下通常是4个字节,64 位平台下通常是8个字节)
6. 引用自加会使引用的实体增加1,指针自加会使指针向后偏移一个类型的大小
7. 有多级指针,但是没有多级引用
8. 访问实体方式不同:指针需要显式解引用,而引用的访问由编译器自动处理
9. 相对而言,引用的使用更安全,前提是不要试图返回已销毁对象的引用。