【NLP】挑战Transformer,华为诺亚新架构盘古π来了,已有1B、7B模型
机器之心编辑部
5 年前,Transformer 在国际神经信息处理大会 NeurIPS 2017 发表,后续其作为核心网络架构被广泛用于自然语言处理和计算机视觉等领域。
1 年前,一项重大的创新引起了人们的广泛关注,那就是 ChatGPT。这个模型不仅能够执行复杂的 NLP 任务,还能以人类对话的方式与人类进行互动,产生了深远的影响。
1 年以来,“百模大战” 在业界激烈开展,诞生了如 LLaMA、ChatGLM 和 Baichuan 等开源大模型,推动了 LLM 领域的快速发展。除了通用 LLM,为了支撑更多行业的应用和商业变现,很多行业垂域大模型也涌现出来,特别是金融、法律和医疗等领域尤为活跃。
开发一个卓越的 LLM,就如同进行一项复杂的系统工程,其中包括数据准备、数据清理、模型架构设计、集群通信以及优化器的选择。在 2022-2023 年的最新项目中,大部分大模型都是基于标准的 Transformer 架构进行开发,主要在数据工程、训练策略上进行不同的优化。模型架构设计,作为其中至关重要的一环,决定了 LLM 的最大性能潜力,并没有在业界引起足够的重视。
近日,来自华为诺亚方舟实验室、北京大学等机构的研究者提出了盘古 π 的网络架构,尝试来构建更高效的大模型架构。

论文链接:http://dx.doi.org/10.13140/RG.2.2.34314.64966
在这篇工作中,作者发现特征坍塌问题影响着这些精心设计的 Transformer 架构的表达能力。以 LLaMA 为例,作者通过实证分析,在 Transformer 更深层中,特征的秩显著降低,导致所有 token 之间的相似性增加,这极大地降低了 LLM 的生成质量和多样性。作者还从理论上分析了 Transformer 架构中的特征坍塌问题和非线性的关系,发现非线性对 Transformer 模型的能力有重大影响。增强非线性可以有效地缓解特征坍塌的问题,并提高 Transformer 模型的表达能力。因而该工作从非线性的角度出发,构建更强大的 LLM 架构。
该工作中,作者带来了一项革新性的突破,引入了一种名为盘古 π 的全新 LLM 架构,来解决特征坍塌问题。这一架构通过在 FFN 和 MSA 模块中引入更多的非线性,从两个方面增强了模型的非线性,而不会显著增加模型的复杂性。首先,作者在 FFN 中引入了基于级数的激活函数,这一函数带有多个可学习的仿射变换,能有效地增强整个网络的非线性,同时计算量很小。然后,作者对每个 MSA 模块的主分支和增强型短路进行并行处理,以避免特征秩的坍塌。为了保持模型效率,作者还精心优化了增强型短路操作,使其更适合硬件实现。作者还证明了这两种操作的叠加可以增强非线性补偿。通过这两个新模块,可以在相同规模的参数下实现显著的效率提升。基于带有级数激活函数的 FFN 和短路增强的 MSA,该工作构建了盘古 π 架构。
作者构建了两个不同大小的盘古 π 大模型版本,即盘古 π-7B 和盘古 π-1B。通过在大规模语料库上进行训练, 盘古 π 大模型获得了在下游任务上的通用语言能力。在各种 NLP 任务上进行的大量实验显示,在模型大小相似的情况下,盘古 π 模型和之前的大模型相比,在准确性和效率方面都能取得更好的性能。
除了基础能力外,作者还将盘古 π-7B 部署在金融和法律这两个高价值领域,开发了一个专门的 LLM,名为云山大模型,在实际商业应用中发挥价值。在金融和法律基准的广泛评估也表明,云山大模型超过了其他具有相似规模的最先进大模型。
盘古 π 的模型架构
为了解决传统 Transformer 架构的非线性能力不足问题,研究者提出了针对注意力模块和 FFN 模块的两项改进。图中展示了作者提出的盘古 π 的整体结构。与原始 Transformer 相比,盘古 π 在前馈网络(FFN)中采用了级数激活函数,并且在多头自注意力(MSA)中集成了增强型快捷连接,这有效地为 Transformer 架构引入了更多的非线性。
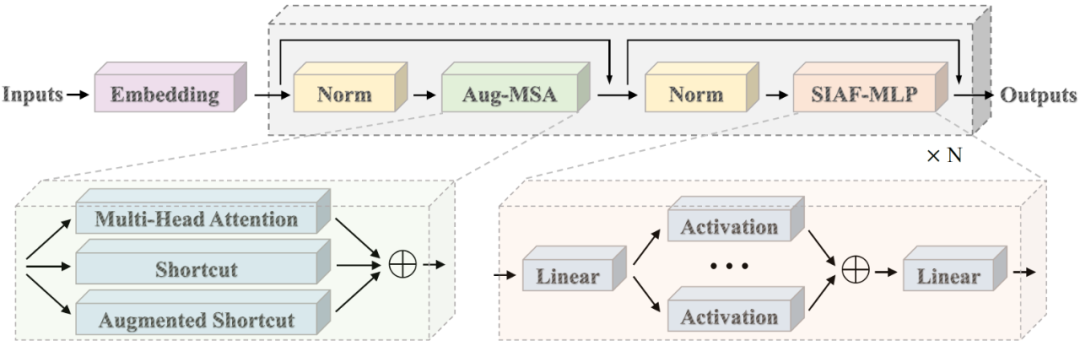
图:盘古 π 的整体架构
传统 Transformer 架构的问题
Transformer 架构的主要组成部分是 MSA 注意力模块和 FFN 前馈网络。作者首先使用子空间投影距离这一常用的度量,来衡量 Transformer 网络的表达能力。针对任意输出矩阵 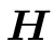 ,该度量可以被记为:
,该度量可以被记为:
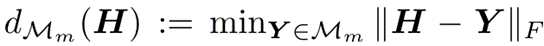
其中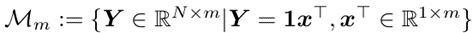 可以被看做一个任意子空间。
可以被看做一个任意子空间。
作者通过这一度量,计算了现有 Transformer 的架构输出的特征多样性:
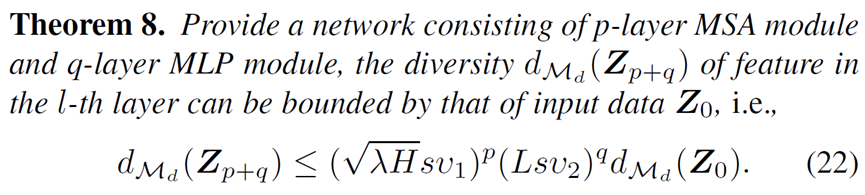
其中 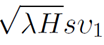 由自注意力计算的特征值有关,
由自注意力计算的特征值有关,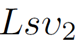 和 FFN 的激活函数有关,而在实际的 Transformer 架构中,这些值往往小于 1,这就导致了现有 Transformer 架构的非线性表达能力实际上受到了很大的限制,从而导致特征的坍塌。
和 FFN 的激活函数有关,而在实际的 Transformer 架构中,这些值往往小于 1,这就导致了现有 Transformer 架构的非线性表达能力实际上受到了很大的限制,从而导致特征的坍塌。
增广 Shortcut 模块
传统的注意力模块(MSA)会带来非线性能力有限导致的特征坍塌问题。一个典型的大语言模型 LLM 为每个注意力模块只配备了一条恒等映射的支路(Shortcut),将输入特征直接复制到输出。这种恒等映射的方式直接将输入特征复制到输出,导致表达能力受限。因此,本文提出增广 Shortcut(Augmented Shortcut)来缓解特征坍塌的问题,提高大语言模型的表达能力。
一般而言,增广 Shortcut 与自注意力模块、恒等映射支路并联,装配有增广 Shortcut 的 MSA 模块可以表述为:
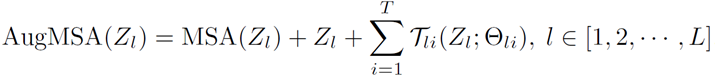
其中 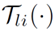 表示第 l 层的第 i 条增广 Shortcut,
表示第 l 层的第 i 条增广 Shortcut,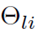 表示其参数。除了原来的恒等映射,增广 Shortcut 提供了更多的替代路径来绕过注意力机制。与恒等映射直接将输入块复制到相应的输出不同,参数化投影
表示其参数。除了原来的恒等映射,增广 Shortcut 提供了更多的替代路径来绕过注意力机制。与恒等映射直接将输入块复制到相应的输出不同,参数化投影 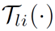 可以将输入特征转换为另一个特征空间。实际上,只要不同支路学到的权重矩阵
可以将输入特征转换为另一个特征空间。实际上,只要不同支路学到的权重矩阵 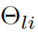 不同,投影
不同,投影 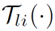 就会对输入特征进行不同的变换,因此并行更多的增广 Shortcut 可以丰富特征空间。
就会对输入特征进行不同的变换,因此并行更多的增广 Shortcut 可以丰富特征空间。
一个最简单的增广 Shortcut 可以采用线性变换 + 非线性激活的形式部署,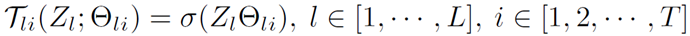
其中 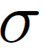 是非线性激活函数(比如 GELU)。映射
是非线性激活函数(比如 GELU)。映射 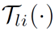 可以独立处理每个 Token 的特征并保留它们的差异性。在实际应用中,为了降低增广 Shortcut 的部署代价,也可以使用 bottleneck 结构来进行部署。
可以独立处理每个 Token 的特征并保留它们的差异性。在实际应用中,为了降低增广 Shortcut 的部署代价,也可以使用 bottleneck 结构来进行部署。
级数激活函数模块
除了自注意力模块以外,Transformer 架构中的另一重要组成部分是 FFN 模块,因此,作者继续研究如何增加 FFN 模块的非线性表达能力。FFN 的计算可以被写作:
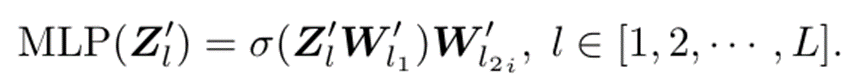
由两个线性映射层和激活函数层构成。因此,在 FFN 中非线性能力的来源其实是来自于激活函数。现有的研究工作提出了许多不同的激活函数,包括 ReLU、GeLU 和 Swish 等。
然而,这些激活函数都没有针对非线性能力增强作深入的研究,因为现有的方案往往倾向于使用更深的网络来提升非线性,这会导致时延的急剧增加,这对于开发一个高效且有效的大型语言模型(LLM)来说是不可承受的。因此,作者引入了级数的思想,通过并行而非现有神经网络中串行堆叠的方式来构造出非线性更强的激活函数:
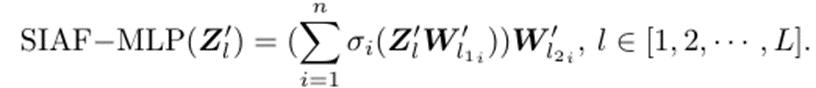
可以看到,随着 n 的增加,所提出的激活函数的非线性会不断上升,从而使得 FFN 的非线性能力得到增强。
最后,作者进行了理论分析,证明了提出的两个模块的有效性,使用两种提出模块得到的盘古 π 架构,相比原始的架构具有更强的非线性表达能力。

实验结果
为了充分展示盘古 π 架构的能力,研究团队构建了 7B 和 1B 两个量级的模型,并将模型和现有的 SOTA 模型进行对比。
7B 模型实验结果
在表 1 中,研究团队对盘古 π-7B 模型的性能进行了全面评估,测试数据集分为四大类:考试、知识、推理和理解,评估方式包括测试得分与推理速度。结果显示,盘古 π-7B 模型在平均分上取得了更好的结果,结果的一致性也更佳,在考试类任务上的表现较为亮眼,超过了除 Qwen 之外的对比模型。在处理速度上,通过对比 910A 上每个 token 的处理时间,盘古 π-7B 模型具有相比同体量模型更快速推理能力。
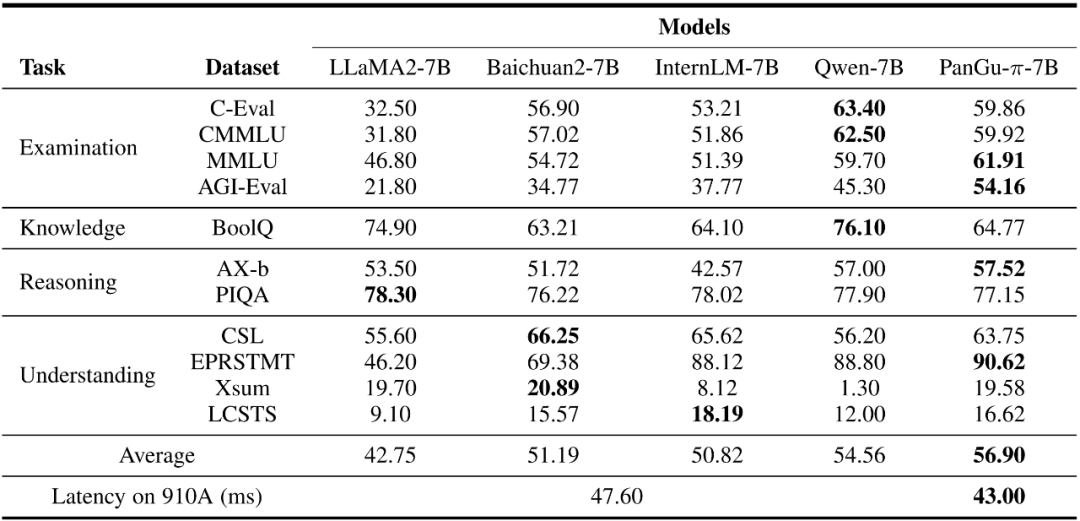
表 1:与开源 7B 模型的性能对比(粗体表示最好结果)
1B 模型实验结果
表 2 展示了盘古 π-1B 模型的性能。对比模型包括中文版 LLaMA2-1.3B、TinyLlama-1.1B 和 Sheared-LLaMA-1.3B。其中 Sheared-LLaMA-1.3B 最初是从较大的 LLaMA2-7B 模型中修剪出来的,然后使用 50B 标记的精简数据集进行训练。与 7B 模型的结果类似,盘古 π-1B 模型在测试得分具备较大优势。而在 1B 体量模型更为关注的速度性能评估结果中,盘古 π-1B 模型也以 13.8ms 的时延战胜了 LLaMA2-1B 15.4ms 的成绩。盘古 π-1B 模型更适用于对时间敏感的应用。
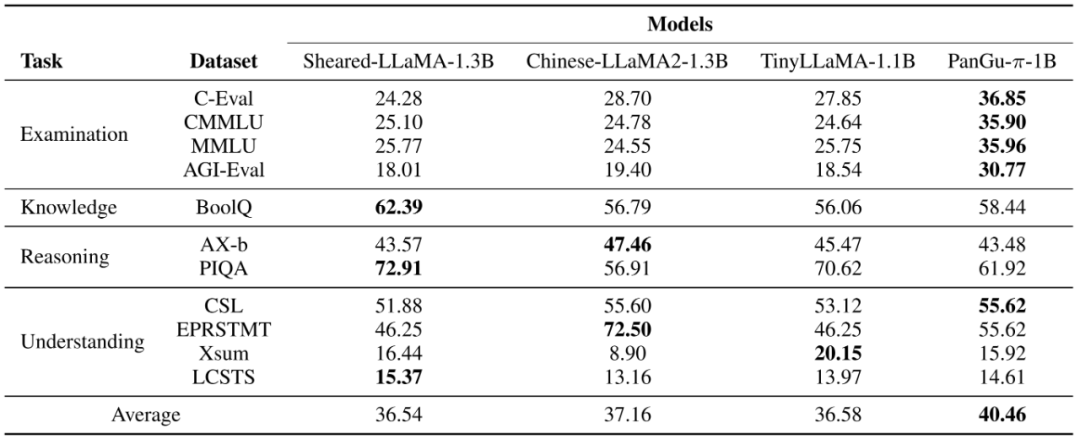
表 2:与开源 1B 模型的性能对比(粗体表示最好结果)
消融实验
为更好地理解所提出的架构,文章使用 1B 模型进行消融实验来调研每个组件对模型影响。在这一部分,研究团队分析了级数增强激活函数(SIAF)和增广 shortcut(AS)对模型整体架构的影响。
表 5 展示了对不同模型组件进行消融实验的结果,并与 WideNet 模型(一种同样用于提升 Transformer 架构非线性的方案)对比,通过实验证明,每个组件都有效地提高了模型架构的性能,证实了所提出方法的每个组件对于提升 Transformer 架构性能的有效性,并超越了 WideNet。
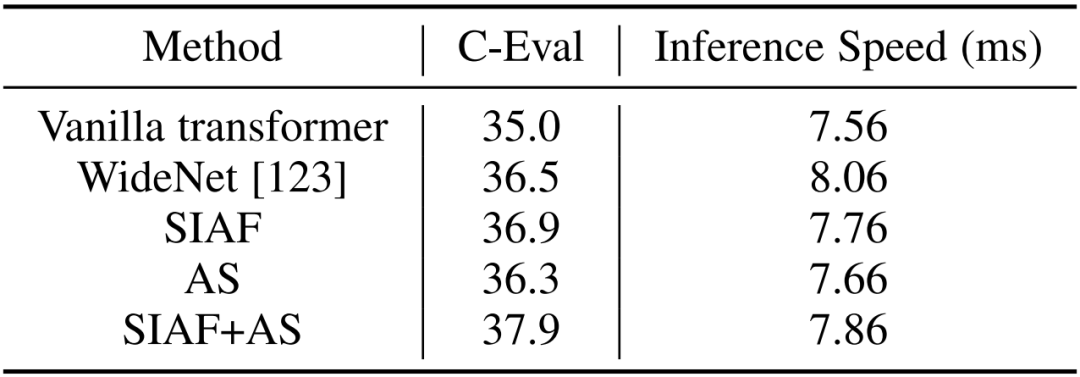
表 5:不同模块对模型影响的实验结果
可视化实验
为了验证盘古 π 架构的特征有效性,研究者还进行了丰富的可视化实验,首先对于各层特征的有效维度进行了分析。有效维度是一个基于主成分方差的分析指标,反应达到预设总方差(0.8)所需的特征维度数。更高的有效维度说明更多的特征通道对于语义表征是有意义的。经过计算,盘古 π 架构相比没有非线性增强的结构,在各层中表现出了一致更高的有效维度数,验证了架构设计的有效性。
研究者进一步对于各层特征的多样性进行了可视化。在可视化实验中,来自同一 token 在不同上下文下的特征通过主成分分析降维,在三维空间中表现出了明显的聚类现象。可以明显的发现,盘古 π 模型显示出了更强的多样性;并且,随着层数的加深,来自同一 token 的特征逐步形成了更加高维延展的聚类群,充分体现了对上下文语义的充分理解与融入。
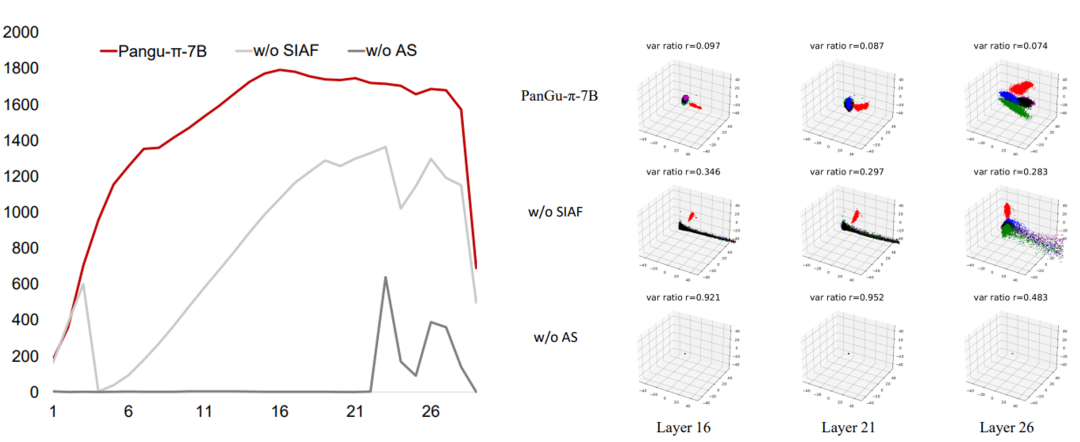
图:不同模型架构下,模型各层的有效特征和隐特征的可视化呈现.
同时,研究者在基于 LAMBDA 数据集的续写任务,对于各个模型的输入显著性进行了分析,在实验中,统计了最终输出结果在每个特征维度上的梯度绝对值,这反应了各 token 对于最终结果的影响程度。在下图所示的例子中,续写要求模型输出前中文提到的人名 chestor,可以看到,相比基线模型,盘古 π 模型正确捕捉到了上文的有效信息,最终能输出了正确结果。
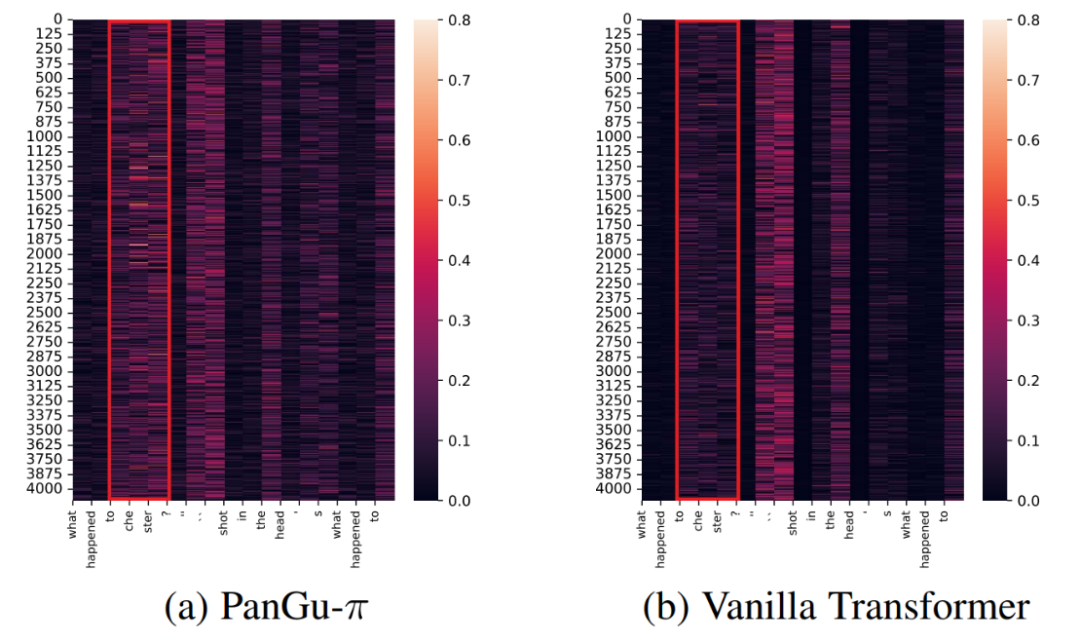
图:续写任务特征显著性分析.
拓展到财经和法律任务
除了通用任务,研究者还将他们的模型推广到财经和法律等垂域任务,并在语料、Tokenizer、训练过程等方面进行了精心的设计,训练后得到的模型被命名为 YunShan (云山)。基于 OpenCompass 测评框架,作者首先在财经的 FinancelQ 数据集上进行了评测。
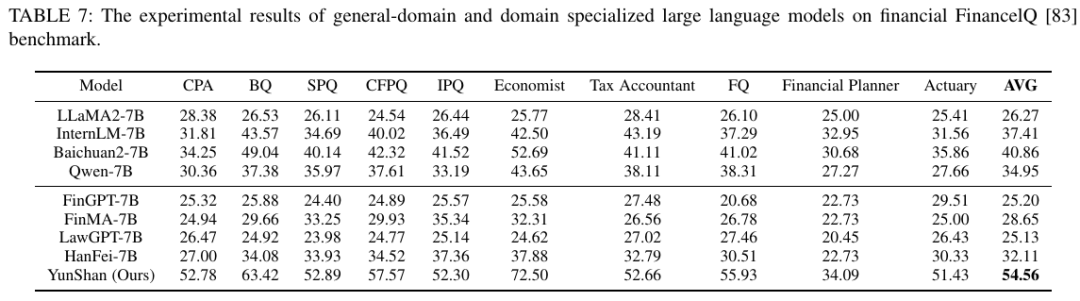
表 6:不同模型在财经 FinancelQ 数据集上的测评结果
从表 6 可以看出,相较于其它的通用基础模型、财经和法律垂域模型,YunShan 模型在注册会计师、银行从业资格等 10 个任务上均表现出明显的优势。作者还在财经的 FinEval 数据集上进行了评测。
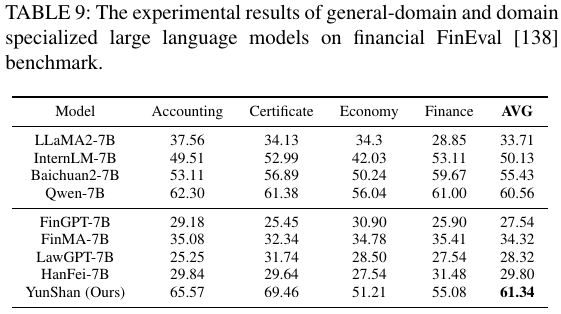
表 7:不同模型在财经 FinEval 数据集上的测评结果
从表 7 可以看出,相较于其它模型,YunShan 模型在会计学和资格证两个子任务上优势明显,并在加权后的平均分上取得了最高分。
此外,研究团队也在法律任务上的 LawBench 数据集上进行了评测。
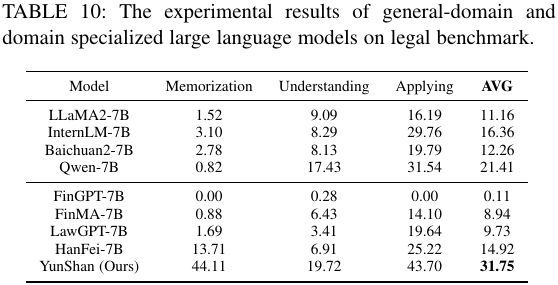
表 8:不同模型在法律 LawBench 数据集上的测评结果
在表 8 中,YunShan 模型在法律知识记忆、法律知识理解和法律知识应用三个子任务上均取得了更高的得分,这体现出作者所提方法的有效性。
更多研究细节,可参考原论文。
精彩回顾交流群
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)
