【高阶系列二】数据清洗和准备——字符串操作
字符串处理是数据清洗中常见的操作。在python中有两种方式进行字符串操作,一种是内置的字符串方法,一种是正则表达式工具——re模块。
目录
一、Python内置的字符串方法
| 方法 | 说明 | 示例 |
| string.count(sub) | 返回子串sub在字符串string中的出现次数,其中,string\sub均为字符串str | string='a,bo,guido' [out]: <class 'str'> 2 |
| string.endswith(sub), string.startswith(sub) | 如果字符串string以某个后缀sub结尾(以某个前缀开头),则返回True | string='a,bo,guido' string.startswith('a') [out]:True |
| string.split(sub) | 通过指定的分隔符sub将字符串string分割成一组子串 | string='a,bo,guido' [out]:['a', 'bo', 'guido'] |
| sub.join(string) | 将sub插入到string的每个字符之间 | "-".join(pieces) [out]:'a-bo-guido' "1-2".join(pieces) [out]:'a1-2bo1-2guido' |
| string.index(sub) | 返回字符串string中子串sub首次出现的索引值,如果未找到sub,则返回ValueError | string.index('o') [out]:3 string.index('ao') [out]:ValueError |
| string.find(sub) | 返回字符串string中子串sub首次出现的索引值,如果未找到sub,则返回-1 | string.find('o') [out]:3 string.find('ao') [out]:-1 |
| string.find(sub) | 返回字符串string中子串sub最后出现的索引值,如果未找到,则返回-1 | string.rfind('o') [out]:9 |
| string.replace(subold,subnew) | 在string中,用subnew替换subold生成新的字符串 | string.replace('a','-') [out]:'-,bo,guido' |
| string.strip() string.lstrip() string.rstrip() | 去除空白符,常与split连用 | pieces2=[x.strip() for x in string.split(',')] [out]:['a', 'bo', 'guido'] |
| string.lower() string.upper() | 将string的字符全部转换为小写(大写) | string.upper() [out]:'A,BO,GUIDO' |
| string.title() | 将string的每个单词的首字母大写 | string.title() [out]:'A,Bo,Guido' |
| string.ljust(width, fillchar=' ', /) string.rjust(width, fillchar=' ', /) | 返回指定长度width的字符串,左侧(右侧)以空格(默认)填充 | string.rjust(15) [out]:' a,bo,guido' |
二、正则表达式(Regular Expression)
正则表达式(Regular Expression)是一种字符串匹配模式(Pattern Objects),由普通字符(自身值)+元字符(匹配规则)构成。
2.1 普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符,包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。如:
| 大小写字母 | 如:a-z;A-Z |
| 数字 | 如:0-9 |
| 标点符号 | 如:单引号' ' |
| 非打印字符 | 如:换页符\f,换行符\n,制表符\t |
2.2 元字符(特殊字符)
元字符表示一种匹配规则,主要种类如下:
2.2.1 单个字符匹配
| 语法 | 说明 | regex实例 | 可Match对象 |
| . | 匹配除换行符'\n'外的任意一个字符;在DOTALL模式中,可匹配换行符 | a.c | abc acc a\c等 |
| [...] | 表示一个字符集,也称为字符类; 被匹配文本可以是这个字符集中的任意字符。[...]中的字符可以单个列出,也可以给出一个范围。 | a[1-3bcd]z | a1z abz等 |
| [a-z] | a、b等 | ||
| [a-zA-Z] | a、A等 | ||
| [1-9a-zA-Z] | 1、a、A等 | ||
| [^...] | 表示匹配除该等字符集合外的其它任意一个字符,^在括号[ ]内表示取反 | a[^1-3bcd]z | a4z、aez等 |
| \ | 转义字符,用来匹配元字符的自身值 | a\[bcd\]\e | a[bcd]e 此时,[ ]经过转义表示自身值 |
说明:所有元字符在[ ]内都将失去原有的特殊含义,具体如下:
A. 被赋予新的特殊含义,如[^...]中^表示取反,[...^...]中^则表示其本身值^(变成普通字符);
B. 特殊字符变为普通字符,如 . * + ? $
C. 普通字符变为特殊字符,如[A-Z]中'-'表示区间;[-AZ]中'-'则表示普通字符;
D. [ ]中如果使用特殊字符的特殊含义,则在字符前面加上转义字符\。
2.2.2 预定义字符集
| 语法 | 说明 | regex实例 | 可Match对象 |
| \d | 表示数字集合,即[0-9] | a\dc | a0c、a9c等 |
| \D | 表示非数字字符集合,即[^0-9] | a\Dc | abc、a-c等 |
| \s | 表示空白字符集合,即[<空格>\t\n\r\f\v] | a\sc | a c等 |
| \S | 表示非空白字符集合,即[^\s] | a\Sc | abc、a1c等 |
| \w | 表示单词字符(字母、数字和下划线)集合,等价于[a-zA-Z0-9] | a\wc | abc、aBc、a\c等 |
| \W | 表示非单词字符(标点符号)集合,即[^a-zA-Z0-9] | a\Wc | a c、a&c、a#c等 |
2.2.3 字符次数匹配——量词
| 语法 | 说明 | regex实例 | 可Match对象 |
| ? | 表示匹配前面那个字符0次或1次 | ab?c | 只能匹配abc、ac |
| + | 表示匹配前面那个字符至少1次 | ab+c | abc、abbc等 |
| * | 表示匹配前面那个字符0次或者无限次 | ab*c | ac、abc、abbc等 |
| {m} | 表示匹配前面那个字符m次 | ab{3}c | 只能匹配abbbc |
| {m,n} | 表示匹配前面那个字符至少m次,至多n次 | ab{1,2}c | 只能匹配abc、abbc |
2.2.4 边界匹配
| 语法 | 说明 | regex实例 | 可Match对象 |
| ^ | 匹配字符串的开头 | ^abc | abc、abcde等 |
| $ | 匹配字符串末尾 | abc$ | abc、123abc等 |
| \A | 仅匹配字符串的开头 | \Aabc | abc、abcde等 |
| \Z | 仅匹配字符串的末尾 | abc\Z | abc、123abc等 |
| \b | 匹配\w和\W之间,单词的词首和词尾 | a\b!bc | a!bc |
| \B | 等价于[^\b] | a\Bbc | abc |
2.2.5 逻辑与分组
| 语法 | 说明 | regex实例 | 可Match对象 |
| | | 表示逻辑或,表示它左右两边的表达式会任意匹配一个。实际上,它总是先尝试匹配它左边的表达式,一旦匹配成功则跳过右边表达式的匹配。如果|没有出现在( )中,则它的有效范围是整个正则表达式。 | abc|def | 只能匹配abc和def |
| (...) | 表示一个分组,且有分组序号;(...)作为一个整体,后可接表示次数的字符。 | a(123|abc){2}e | 只能匹配a123123e、aabcabce |
| (?P<name>...) | 分组,用来给分组指定别名,match.group、regex.group可以看到 | a(?P<id>123|abc){2}e | 与上面表达式匹配内容相同,组的别名为id,可引用 |
| \<number> | 引用编号为<number>的分组所匹配的字符串 | (\d)abc\1 | 1abc1、5abc5等 |
| (?P=name) | 引用别名为name的分组所匹配的字符串 | (?P<id>\d)abc(?P=id) | 1abc1、2abc2等 |
2.2.6 特殊构造
| 语法 | 说明 | regex实例 | 可Match对象 |
| (?: ...) | (...)的不分组版本,用于使用|或后接数量词 | (?:abc){2} | abcabc |
| (?#...) | #后的内容为注释,将被忽略 | abc(?#flag)123 | abc123 |
| (?=...) | 表示后面的字符串匹配这个表达时,整个regex才算匹配 | a(?=\d) | 表示字母a加一个数字的字符串 |
| (?!=...) | 表示后面的字符串内容不匹配这个表达式时,整个regex才算匹配 | a(?!=\d) | 表示字母a加一个非数字的字符串 |
| (?<=...) | 表示前面的字符串内容匹配这个表达式时,整个regex才算匹配 | (?<=\d)a | 表示一个数字加字母a的字符串 |
| (?<!...) | 表示前面的字符串内容不匹配这个表达式时,整个regex才算匹配 | (?<!\d)a | 表示一个非数字加字母a的字符串 |
| (?(id/name)yes-pattern/no-pattern) | 如编号为id/name匹配到字符串,则匹配yes-pattern,否则匹配no-pattern | (\d)abc(?(1)\d|abc) | 1abc2、abcabc等 |
2.2.7 贪婪模式与非贪婪模式
贪婪模式与非贪婪模式的选择适用于含量词的情况。
贪婪模式:由多到少匹配,如[bcd]*,则先匹配bcd,如匹配不成功,则再匹配bc,如不成功,则再单个字符匹配
非贪婪模式:由少到多匹配,[bcd]*?,先匹配0次,如不匹配,再匹配b,依次增多进行匹配。
三、python正则表达式工具-re模块
在python中,通过re模块实现正则表达式的应用。
3.1 Re模块对象属性
3.1.1 re模块对象
re模块包含两类对象:
| Pattern Objects | 模式对象,由re.compile生成 |
| Match Objects | 匹配对象,由regex.match()、regex.fullmatch()、regex.search()三个函数生成 |
3.1.2 模式对象的方法和属性
用regex表示模式对象:
| 方法名/属性名 | 描述 |
| regex.match | 从字符串开始位置匹配正则表达式 |
| regex.fullmatch | 将整个字符串与regex匹配,相当于'^'和'$'精准匹配 |
| regex.search | 扫描整个字符串,查找regex可以匹配的字符串第一次出现的位置,并返回匹配对象 |
| regex.findall | 搜索字符串中与regex匹配的所有子串,以列表形式返回 |
| regex.finditer | 搜索字符串中与regex匹配的所有子串,以迭代器形式返回 |
| regex.sub | 替换字符串中与regex匹配的子串,返回新串 |
| regex.subn | 功能与regex.sub相同,同时返回替换次数 |
| regex.split | 将regex作为分隔符,对字符串进行分隔,生成分隔后的字符串列表 |
| regex.pattern | 属性,返回regex的pattern值 |
| regex.flags | 属性,返回regex的flags参数值 |
| regex.groups | 属性,返回regex中指定的“捕获组”的数量 |
| regex.groupindex | 属性,字典对象,存放“命名分组的分组名”与“该分组数量”的对应关系 |
3.1.3 匹配对象的方法和属性
| 方法名/属性名 | 描述 |
| match.group | 返回一个或多个指定捕获组所匹配的内容;group(0)代表整个匹配结果,group(1)代表第一个分组匹配部分,group(2)代表第二个分组匹配部分 |
| match.groups | 返回一个包含所有分组匹配内容的元组 |
| match.groupdict | 返回以别名的组名为键,以该组匹配内容为值的字典 |
| match.start([group]) | 返回group组的起始索引,default=0 |
| match.end([group]) | 返回group组的结尾索引 |
| match.span([group]) | 返回group组的起始索引和结尾索引,0代表group(0),1代表group(1),以此类推 |
| match.expand(template) | 将group值代入template中返回,template可以是\d或\g<id>或\g<name>引用分组 |
| match.re | 匹配时使用的Pattern对象,属性 |
| match.string | 匹配时使用的string文本,属性 |
| match.pos | 文本中正则表达式开始搜索的索引,值与Pattern.match()和Pattern.search()方法的同名参数相同,属性 |
| match.endpos | 文中正则表达式结束搜索的索引,同上,属性 |
| match.lastindex | 最后一个被捕获的组在string中的索引,属性 |
| match.lastgroup | 最后一个被捕获的分组的别名,属性 |
3.1.4 实例
(1)match.group()、match.groups()、match.span()
>> import re
>> match=re.search('(abc)(cba)(def)','abccbadef123')
>> match
[out]:<re.Match object; span=(0, 9), match='abccbadef'>
>> match.span(0)
[out]:(0, 9)
>> match.group(0)
[out]:'abccbadef'
>> match.group(1)
[out]:'abc'
>> match.span(1)
[out]:(0, 3)
>> match.groups()
[out]:('abc', 'cba', 'def')(2)match.groupdict
>> import re
>> match1=re.search('(?P<name>abc)(cba)(def)(?P<id>\d)','abccbadef1234')
>> match1
[out]:<re.Match object; span=(0, 10), match='abccbadef1'>
>> match1.groupdict()
[out]:{'name': 'abc', 'id': '1'}(3)match.expand
# 在expand中,三种引用方式的结果相同
>> match1.expand(r'The name is \g<name>,the number is \g<id>')
[out]:'The name is abc,the number is 1'
>> match1.expand(r'The name is \g<1>,the number is \g<4>')
[out]:'The name is abc,the number is 1'
>> match1.expand(r'The name is \1,the number is \4')
[out]:'The name is abc,the number is 1'
3.2 re模块的函数
(1)re.compile
re.compile(pattern,flags=0) 将字符串形式的正则表达式编译为Pattern对象。
| 参数 | 简称 | 描述 |
| pattern | / | 字符串形式的正则表达式regex |
| re.IGNORECASE | re.I | 执行正则匹配时忽略大小写 |
| re.MULTILINE | re.M | ’^'和'$'可匹配每一行的行首和行尾 |
| re.LOCALE | re.L | 使\w、\W、\b、\B的匹配依赖当前语言环境 |
| re.DOTALL | re.S | ‘·’可匹配任意字符,包括换行符 |
| re.VERBOSE | re.X | 忽略空白字符和注释 |
>> import re
>> pattern=re.compile(r'hello')
>> m=pattern.match('hello world')
>> m
[out]:<re.Match object; span=(0, 5), match='hello'>(2)re.match
re.match(pattern,string,flags=0) 同regex.match
(3)re.fullmatch
re.fullmatch(pattern,string,flags=0) 同regex.fullmatch
(4)re.search
re.search(pattern,string,flags=0) 同regex.search
(5)re.findall
re.findall(pattern,string,flags=0) 同regex.findall
(6)re.finditer
re.finditer(pattern,string,flags=0) 同regex.finditer
(7)re.sub
re.sub(pattern,repl,string,count=0,flags=0) 同regex.sub
(8)re.subn
re.subn(pattern,repl,string,count=0,flags=0) 同regex.subn
示例一:利用python内置的字符串方法
>> text='pro---gram--files'
>> text.replace('-','') # 利用python内置的字符串方法
[out]:'programfiles'
示例二:利用re.sub函数,repl为一个字符串
>> re.sub(r'-+','',text) # 利用re.sub函数
[out]:'programfiles'
>> re.subn(r'-+','',text) # 利用re.subn函数
[out]:('programfiles', 2)示例三:利用re.sub函数,repl是一个自定义函数
def dashrepl(match_obj):
if match_obj.group()=='-':
return ''
else:
return ''
re.sub(r'-+',dashrepl,text)
[out]:'programfiles'示例四:resub的pattern和repl参数均为正则表达式
>> string='def myfunc(*args,**args)'
>> p=r'def\s+([a-zA-Z]\w*)\s*\((?P<param>.*)\)'
>> m=re.search(p,string)
>> m
[out]:<re.Match object; span=(0, 24), match='def myfunc(*args,**args)'>
>> m.group(0)
[out]:'def myfunc(*args,**args)'
>> m.group(1)
[out]:'myfunc'
>> m.group('param')
[out]:'*args,**args'
>> repl=r'def py_\1(\g<param>)'
>> re.sub(p,repl,string)
[out]:'def py_myfunc(*args,**args)'(9)re.split
re.split(pattern,string,maxsplit=0,flags=0) 同regex.split
四、向量化字符串函数
上述python内置的字符串方法及正则表达式为规范处理字符串提供了路径,但在数据处理中,一般需要处理DataFrame和Series形式的字符串序列,就涉及到向量化字符串函数。
4.1 应用背景
观察下面的例子:
>> import numpy as np
>> import pandas as pd
>> from pandas import DataFrame,Series
>> import re
>> data = {'Dave': 'dave@google.com', 'Steve': 'steve@gmail.com',
>> .....: 'Rob': 'rob@gmail.com', 'Wes': np.nan}
>> data=pd.Series(data)
>> data
[out]:
Dave dave@google.com
Steve steve@gmail.com
Rob rob@gmail.com
Wes NaN
dtype: objectdata是含有缺失值的Series,按照惯常的方式,可以通过data.apply,所有字符串和正则表达式方法都能被应用于(传入lambda表达式或其他函数)各个值。
>> data.apply(lambda x:x.upper())
[out]:
AttributeError Traceback (most recent call last)
<ipython-input-29-6d48187fe861> in <module>()
----> 1 data.apply(lambda x:x.upper())
D:\ipython\lib\site-packages\pandas\core\series.py in apply(self, func, convert_dtype, args, **kwds)
3192 else:
3193 values = self.astype(object).values
-> 3194 mapped = lib.map_infer(values, f, convert=convert_dtype)
3195
3196 if len(mapped) and isinstance(mapped[0], Series):
pandas/_libs/src\inference.pyx in pandas._libs.lib.map_infer()
<ipython-input-29-6d48187fe861> in <lambda>(x)
----> 1 data.apply(lambda x:x.upper())
AttributeError: 'float' object has no attribute 'upper'可以看出,python会出现报错,主要原因是缺失数据NaN属于float类型,不适用于字符串的方法。
>> type(data['Wes'])
[out]:float如果data不含缺失数据,则data.apply不会报错:
>> data1={'Dave': 'dave@google.com', 'Steve': 'steve@gmail.com',
>> .....: 'Rob': 'rob@gmail.com'}
>> data1=pd.Series(data1)
>> data1
[out]:
Dave dave@google.com
Steve steve@gmail.com
Rob rob@gmail.com
dtype: object
>> data1.apply(lambda x:x.upper())
[out]:
Dave DAVE@GOOGLE.COM
Steve STEVE@GMAIL.COM
Rob ROB@GMAIL.COM
dtype: object
除去上述方法外,pandas还提供了一种更为直接的方法,即pd.Series.str方法,可更加有效的处理字符串序列。
4.2 pd.Series.str
Series的str方法,提供了一种既可以高效化处理字符串序列,又可以正确处理缺失值的方法。
>> help(pd.Series.str)
[out]:
class StringMethods(pandas.core.base.NoNewAttributesMixin)
| StringMethods(data)
|
| Vectorized string functions for Series and Index. NAs stay NA unless
| handled otherwise by a particular method. Patterned after Python's string
| methods, with some inspiration from R's stringr package.4.3 Series.str函数
用法:Series.str.func() func为函数名。
举例:
>> data
[out]:
Dave dave@google.com
Steve steve@gmail.com
Rob rob@gmail.com
Wes NaN
dtype: object4.3.1 大小写转换
| 函数/方法 | 说明 | 示例 |
| Series.str.capitalize() | 字符串首字母大写,其余字母小写 | >> data.str.capitalize() [out]: Dave Dave@google.com Steve Steve@gmail.com Rob Rob@gmail.com Wes NaN dtype: object |
| Series.str.title() | 字符串中,所有单词的首字母大写 | >> data.str.title() [out]: Dave Dave@Google.Com Steve Steve@Gmail.Com Rob Rob@Gmail.Com Wes NaN dtype: object |
| Series.str.swapcase() | 字符串中,所有字母的大小写互换 | >> data.str.swapcase() [out]: Dave DAVE@GOOGLE.COM Steve STEVE@GMAIL.COM Rob ROB@GMAIL.COM Wes NaN dtype: object |
| Series.str.lower() | 字符串中,所有字母小写 | >> data.str.lower() [out]: Dave dave@google.com Steve steve@gmail.com Rob rob@gmail.com Wes NaN dtype: object |
| Series.str.upper() | 字符串中,所有字母大写 | >> data.str.upper() [out]: Dave DAVE@GOOGLE.COM Steve STEVE@GMAIL.COM Rob ROB@GMAIL.COM Wes NaN dtype: object |
4.3.2 字符串填充
| 函数/方法 | 说明 | 示例 |
Series.str.center( width, fillchar=' ') | 返回两边用fillchar填充的、长度为width的字符串 | >> data.str.center(15,'*') [out]: Dave dave@google.com Steve steve@gmail.com Rob *rob@gmail.com* Wes NaN dtype: object |
| Series.str.ljust( width, fillchar=' ') | 返回原字符左对齐,用fillchar填充,长度为width的字符串 | >> data.str.ljust(15,'*') [out]: Dave dave@google.com Steve steve@gmail.com Rob rob@gmail.com** Wes NaN dtype: object |
| Series.str.rjust( width, fillchar=' ') | 返回原字符右对齐,用fillchar填充的字符串 | >> data.str.rjust(15,'*') [out]: Dave dave@google.com Steve steve@gmail.com Rob **rob@gmail.com Wes NaN dtype: object |
| Series.str.zfill(width) | 原字符串右对齐,前面用0填充长度为width的字符串 | >> data.str.zfill(15) [out]: Dave dave@google.com Steve steve@gmail.com Rob 00rob@gmail.com Wes NaN dtype: object |
4.3.3. 字符串编码
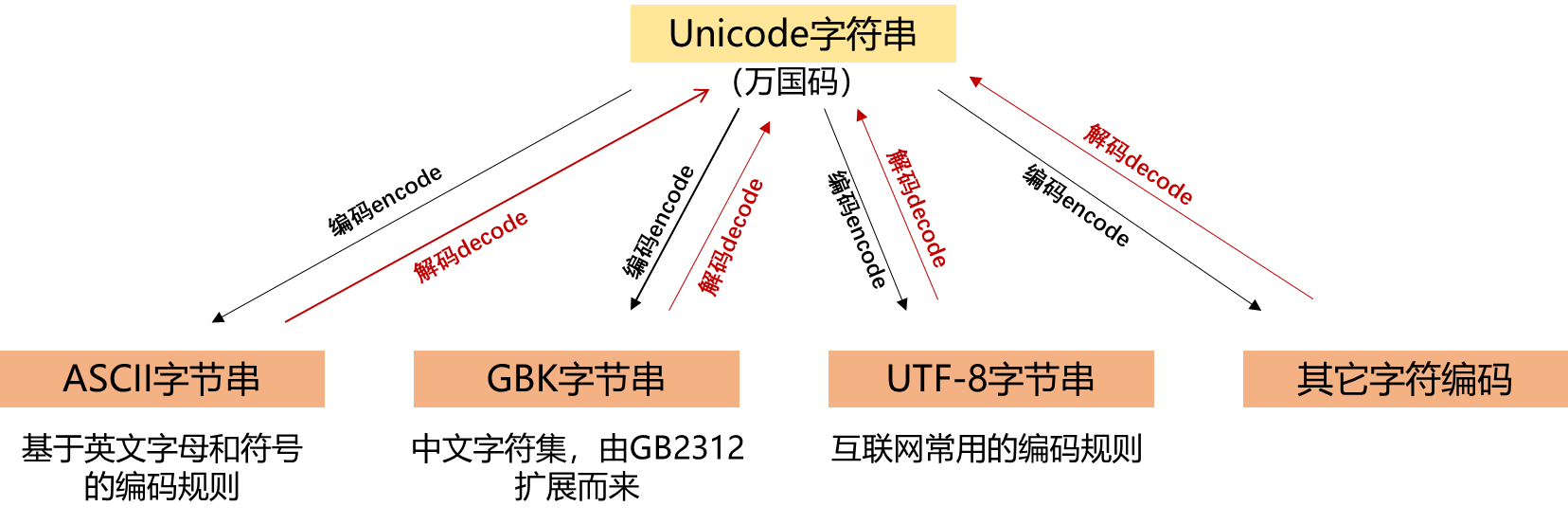
| 函数/方法 | 说明 | 示例 |
| Series.str.encode() | 编码(字符集——计算机数字代码) | >> data2=data.str.encode('UTF-8') [out]: Dave b'dave@google.com' Steve b'steve@gmail.com' Rob b'rob@gmail.com' Wes NaN dtype: object >> type(data2['Dave']) [out]:bytes |
| Series.str.decode() | 解码(计算机数字代码——字符集) | 略 |
4.3.4 字符串查找
| 函数/方法 | 说明 | 示例 |
| Series.str.find(sub, start=0, end=None) | 查找字符串中子字符串sub第一次出现的位置,若无则返回-1 | >> data.str.find('gmail') [out]: Dave -1.0 Steve 6.0 Rob 4.0 Wes NaN dtype: float64 |
| Series.str.rfind(sub, start=0, end=None) | 查找字符串中子字符串sub最后一次出现的位置,若无则返回-1 | >> data.str.rfind('o') [out]: Dave 13.0 Steve 13.0 Rob 11.0 Wes NaN dtype: float64 |
| Series.str.index(sub, start=0, end=None) | 同str.find,若无则会报错 | 略 |
| Series.str.rindex(sub,start=0,end=None) | 同str.rfind,若无则会报错 | 略 |
4.3.5 解决判断问题
| 函数/方法 | 说明 | 示例 |
| Series.str.endswith(pat, na=nan) pat : str Character sequence. Regular expressions are not accepted. | 判断字符串是否以指定字符或者子字符串结尾 | >>data.str.endswith('com') [out]: Dave True Steve True Rob True Wes NaN dtype: object |
| Series.str.startswith(pat, na=nan) pat : str Character sequence. Regular expressions are not accepted. | 判断字符串是否以指定字符或子字符串开头 | 略 |
| Series.str.isalnum() | alnum为(alphabet+number), 判断字符串是否由字母和数字组成 | >> data.str.isalnum() [out]: Dave False Steve False Rob False Wes NaN dtype: object |
| Series.str.isalpha() | 判断字符串是否只由字母组成 | >> data.str.isalnum() [out]: Dave False Steve False Rob False Wes NaN dtype: object |
| Series.str.isdecimal() | 判断字符串是否只包含十进制字符 | 略 |
| Series.str.isdigit() | 判断字符串是否只由数字组成 | 略 |
| Series.str.islower() | 判断字符串中的字符是否全部为小写字母 | >> data.str.islower() [out]: Dave True Steve True Rob True Wes NaN dtype: object |
| Series.str.isupper() | 判断字符串中的字母是否全部为大写字母 | 略 |
| Series.str.isnumeric() | 判断字符串是否只由数字组成 | 略 |
| Series.str.isspace() | 判断字符串是否只由空格组成 | 略 |
| Series.str.istitle() | 判断字符串中所有单词的首字母是否为大写 | 略 |
4.3.6 字符串修剪
| 函数/方法 | 说明 |
| Series.str.strip() | 去掉字符串开头和尾部指定的字符,默认为空格 |
| Series.str.lstrip() | 去掉开头的指定字符,默认空格 |
| Series.str.rstrip() | 去掉尾部的指定字符,默认空格 |
4.3.7 分割字符串
| 函数/方法 | 说明 | 示例 |
| Series.str.partition(pat=' ', expand=True) | 用指定分隔符将字符串分为三部分,第一部分为pat前段,第二部分为pat,第三部分为pat后段 | >> data.str.partition('@') [out]:
|
| Series.str.rpartition(pat=' ', expand=True) | 功能与partition相同,但是是从右边第一个pat分割字符串 | 略 |
| Series.str.split((pat=None, n=-1, expand=False) | 用指定分隔符sep分割字符串,返回分割后的字符串列表(list) | >> data.str.split('@') [out]:
|
| Series.str.join(sep) sep : str Delimiter to use between list entries. | 将指定字符插入字符串序列中生成新的字符串 | >> data.str.join('-') [out]:
|



4.3.8 字符串替换
| 函数/方法 | 说明 | 示例 |
| Series.str.replace(pat, repl, n=-1, case=None, flags=0, regex=True) pat : string or compiled regex String can be a character sequence or regular expression. repl : string or callable Replacement string or a callable. | 将pat子字符串替换为repl子字符串,替换次数为count次 | >> data.str.replace('google','gmail') [out]:
|

4.3.9 统计字符函数
| 函数/方法 | 说明 | 示例 |
| Series.str.count(pat, flags=0, **kwargs) pat : str Valid regular expression. | 统计字符串中pat子字符串出现的次数 | >> data.str.count('gmail') [out]:
|
