大数据学习(30)-Spark Shuffle
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门
💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博主哦🤞
Spark Shuffle
Map 和 Reduce
在Shuffle过程中. 提供数据的称之为Map端(Shuffle Write) 接收数据的 称之为 Reduce端(Shuffle Read)
在Spark的两个阶段中, 总是前一个阶段产生 一批Map提供数据, 下一阶段产生一批Reduce接收数据。
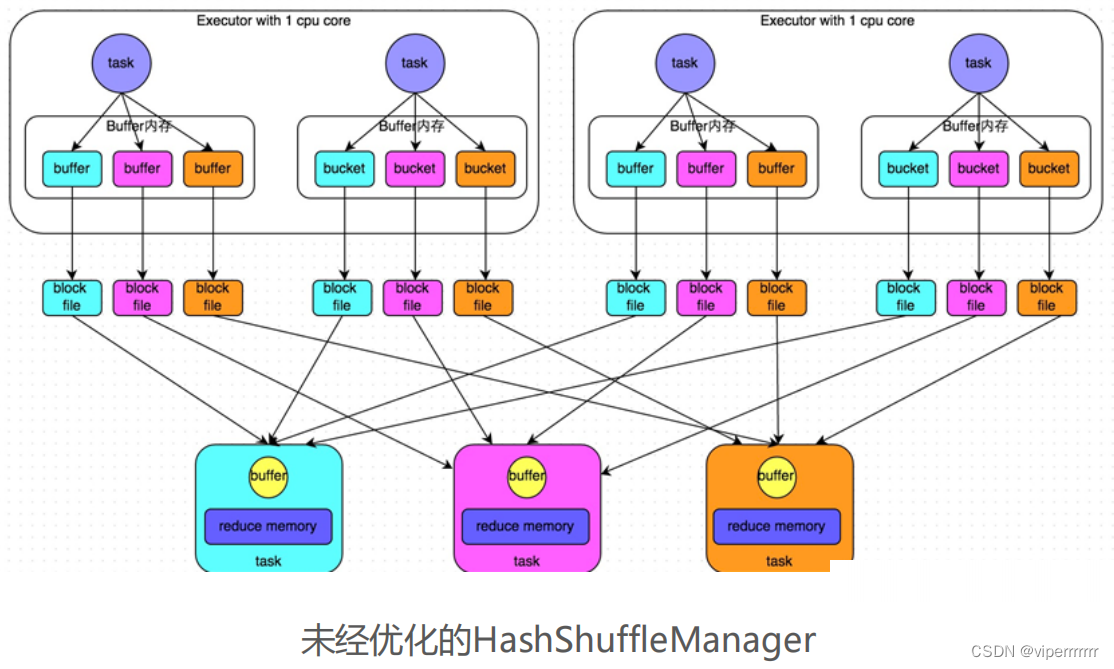
Spark 提供2种Shuffle管理器:
• HashShuffleManager
• SortShuffleManager
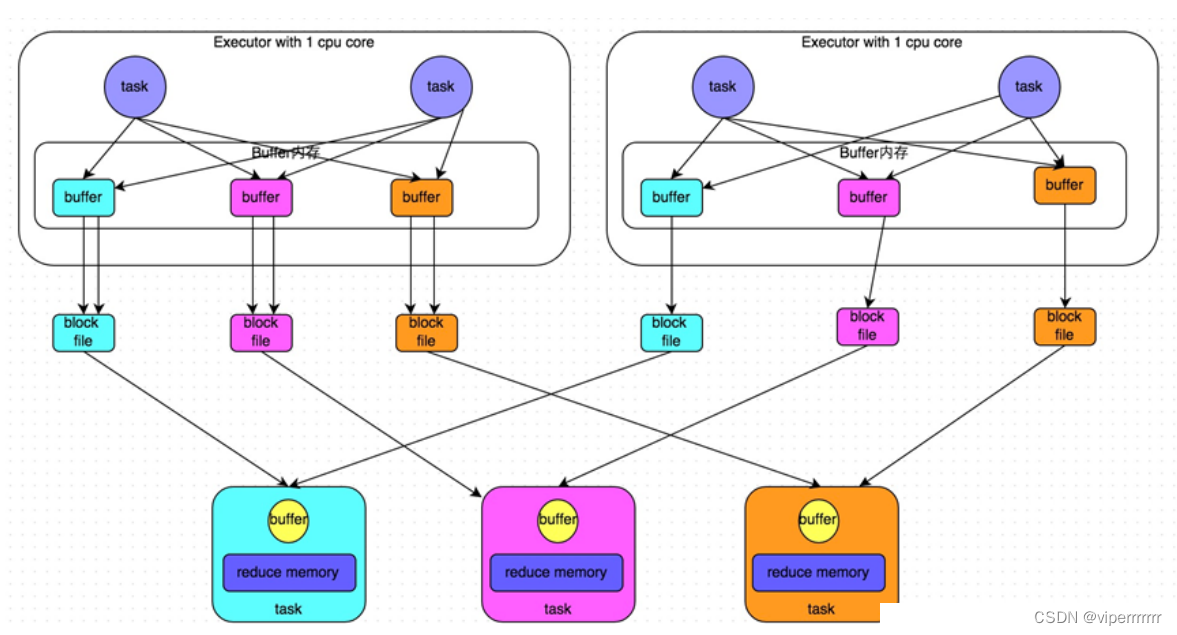
优化后
基本和未优化的一致,不同点在于
1. 在一个Executor内, 不同Task是共享Buffer缓冲区
2. 这样减少了缓冲区乃至写入磁盘文件的数量, 提高性能
SortShuffleManager
SortShuffleManager的运行机制主要分成两种,一种是普通运行机制,另一种是bypass运行机制。
bypass运行机制的触发条件如下:
1)shuffle map task
数量小于
spark.shuffle.sort.bypassMergeThre
shold=200
参数的值。
2)
不是聚合类的
shuffle
算子
(
比如
reduceByKey)
。
同普通机制基本类同
,
区别在于
,
写入磁盘临时文件的时候不会在内
存中进行排序
而是直接写
,
最终合并为一个
task
一个最终文件
所以和普通模式
IDE
区别在于
:
第一,磁盘写机制不同;
第二,不会进行排序。也就是说,启用该机制的最大好处在于,
shuffle write
过程中,不需要进行数据的排序操作,也就节省掉了
这部分的性能开销。
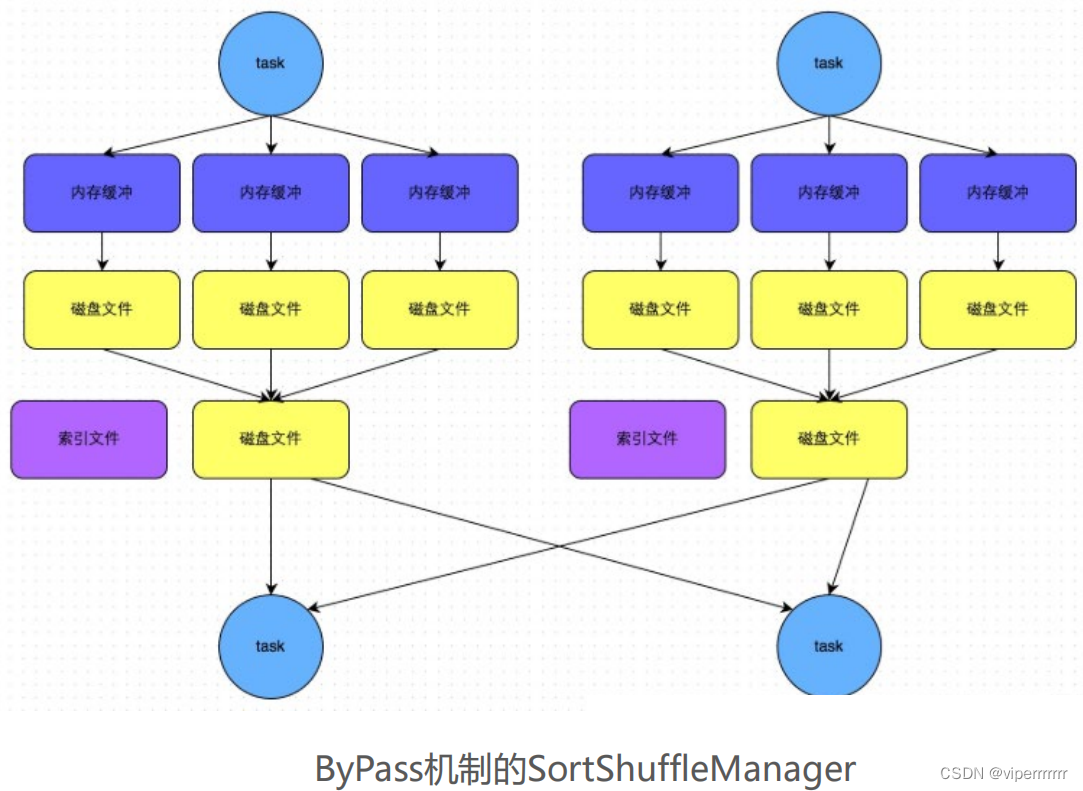
1. SortShuffle对比HashShuffle可以减少很多的磁盘 文件,以节省网络IO的开销
2. SortShuffle主要是对磁盘文件进行合并来进行文件 数量的减少, 同时两类Shuffle都需要经过内存缓冲区 溢写磁盘的场景。所以可以得知, 尽管Spark是内存迭 代计算框架, 但是内存迭代主要在窄依赖中. 在宽依赖(Shuffle)中磁盘交互还是一个无可避免的情况. 所 以, 我们要尽量减少Shuffle的出现, 不要进行无意义的Shuffle计算。