如何用趋动云GPU线上跑AI项目实践-部署最新的ChatGLM3-6B模型
学习教程
一.免费算力领取
Datawhale专属注册:
趋动云 https://growthdata.virtaicloud.com/t/vs
https://growthdata.virtaicloud.com/t/vs
二.部署最新的ChatGLM3-6B模型
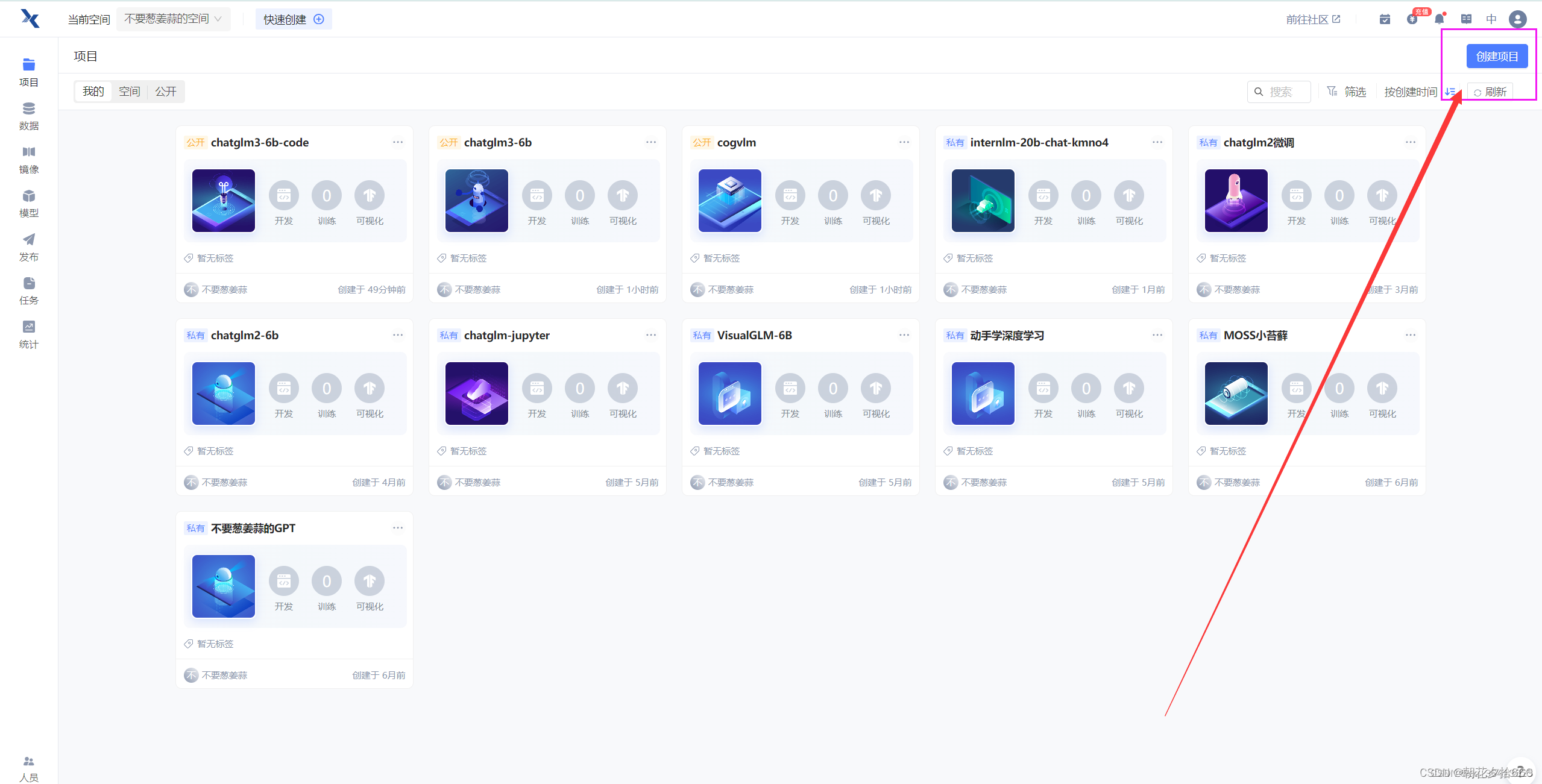
1.创建项目
创建好账号之后,进入自己的空间,点击右上角的创建项目。
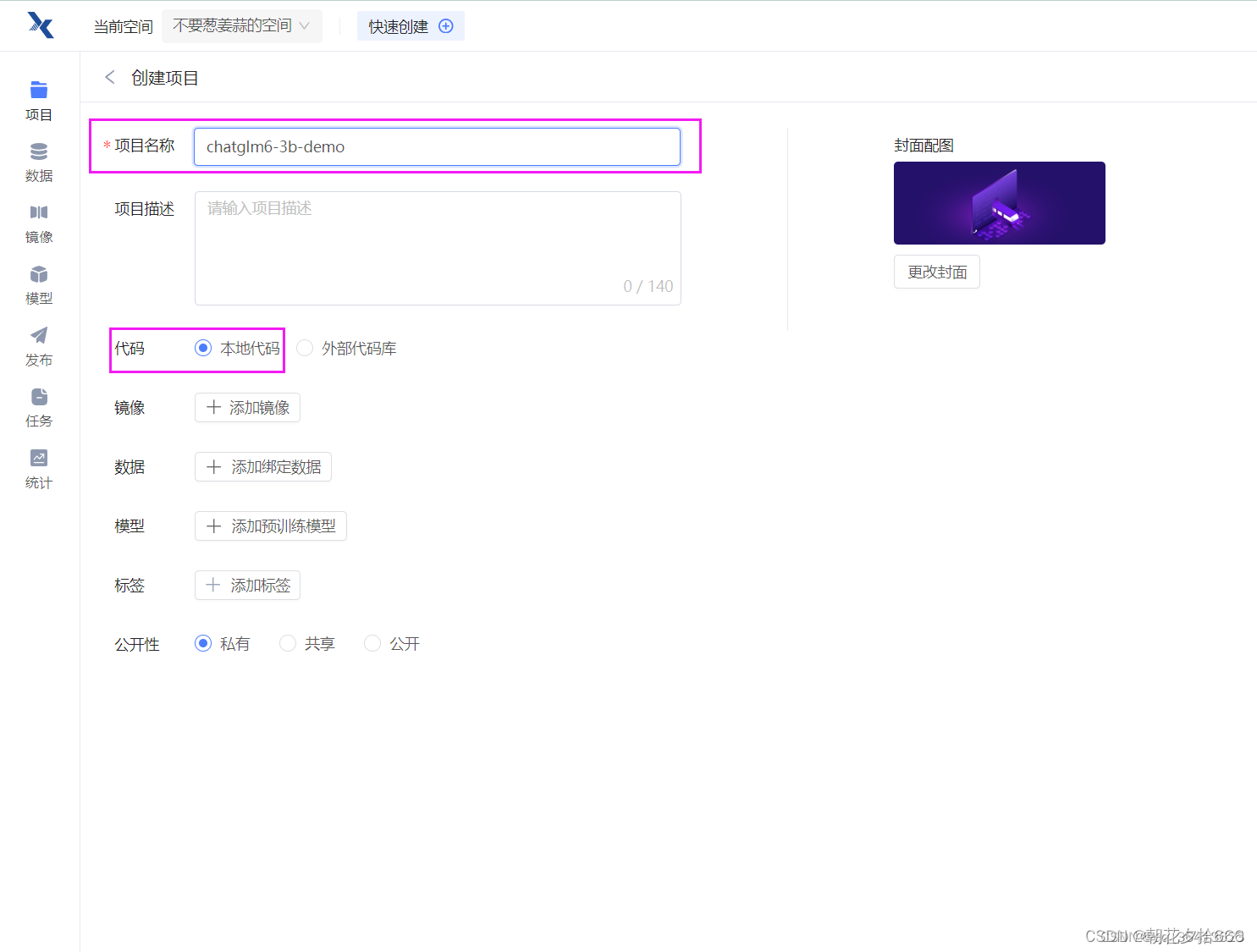
给项目起一个你喜欢的名称,选择本地代码
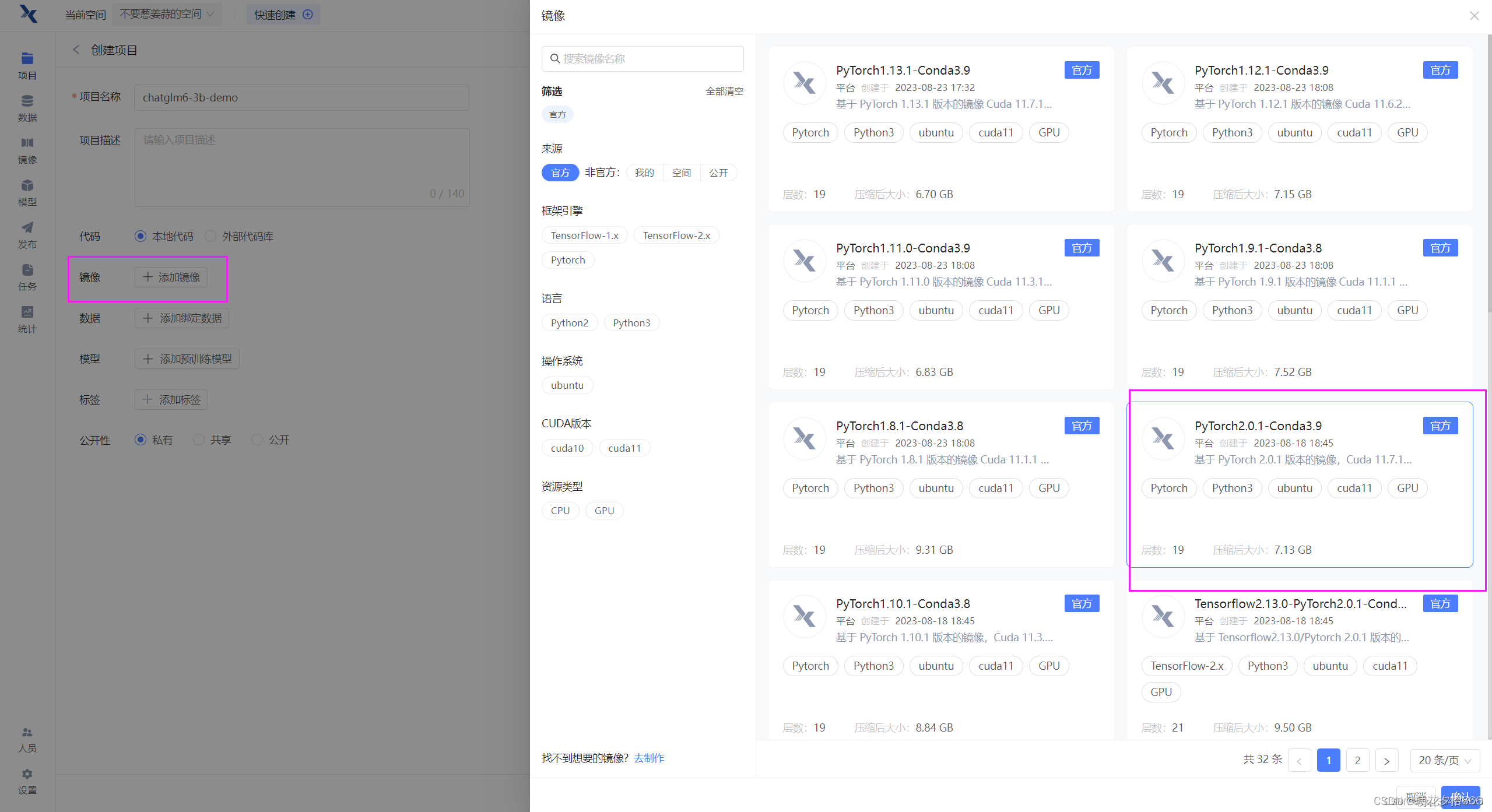
镜像选择pytorch2.0.1,python3.9
选择预训练模型,点击公开,选择不要葱姜蒜上传的这个ChtaGLM3-6B模型。
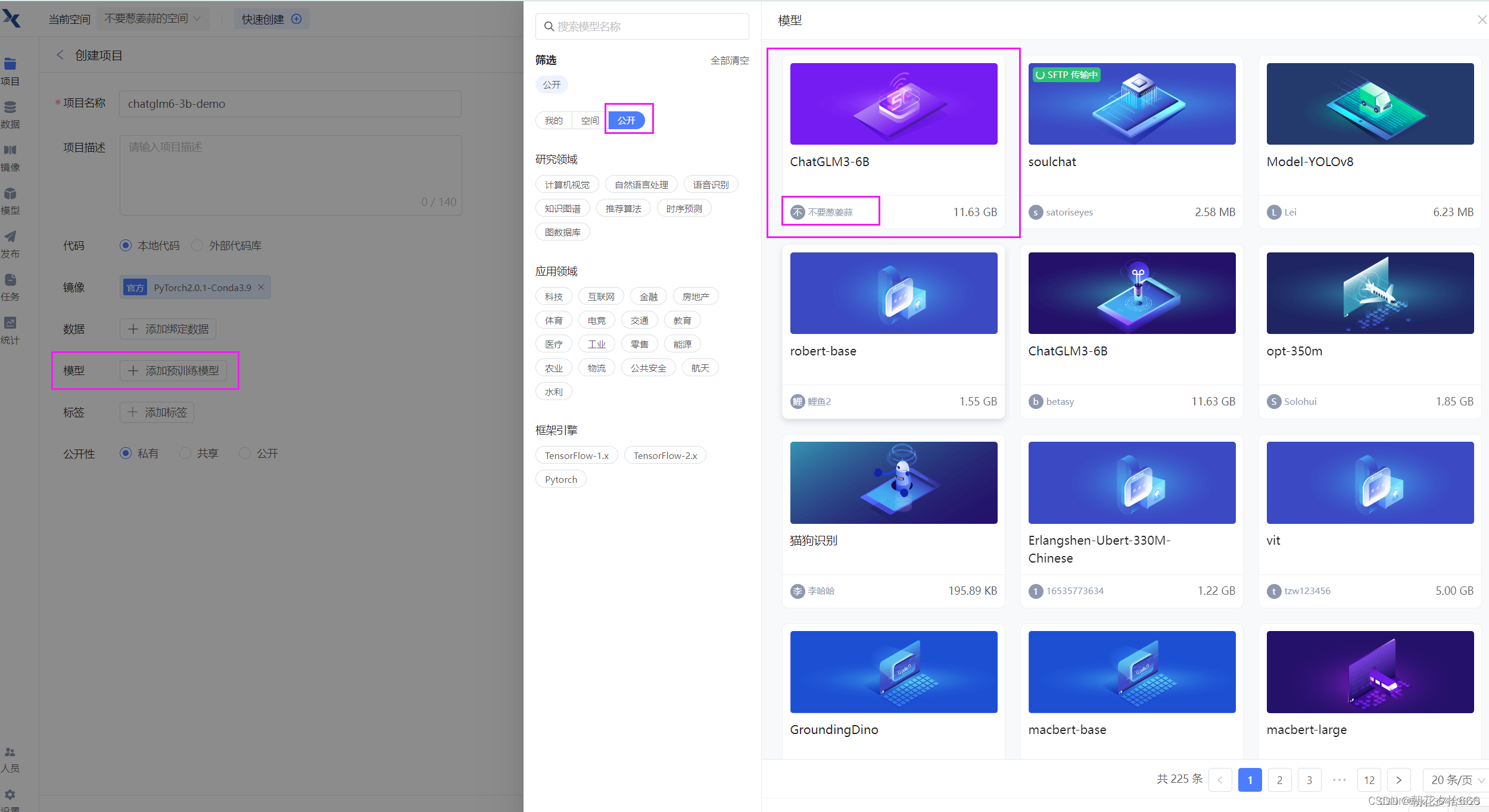
都选完之后,点击右下角的创建,代码选择暂不上传。待会直接clone代码。
点击运行代码
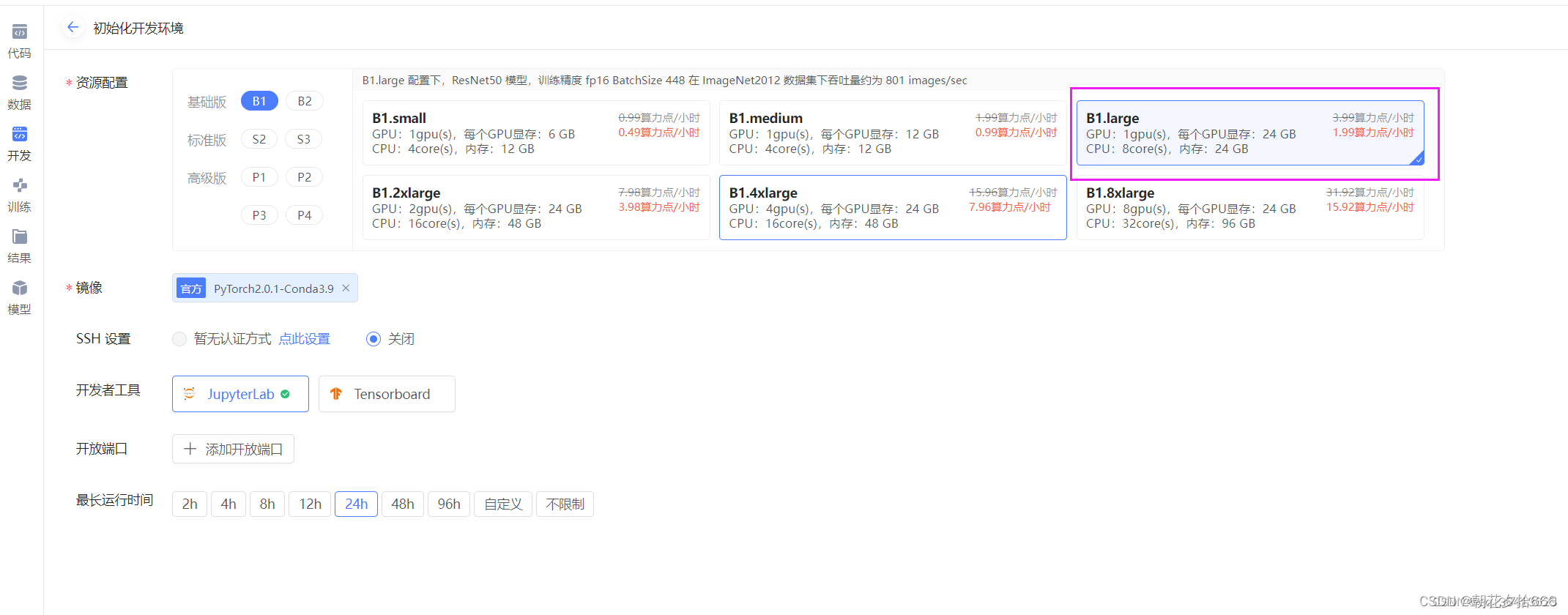
资源配置选择:B1.large, 24G的显存足够加载模型了。其他的不需要设置,然后点击右下角的开始运行。
2.配置环境+修改代码
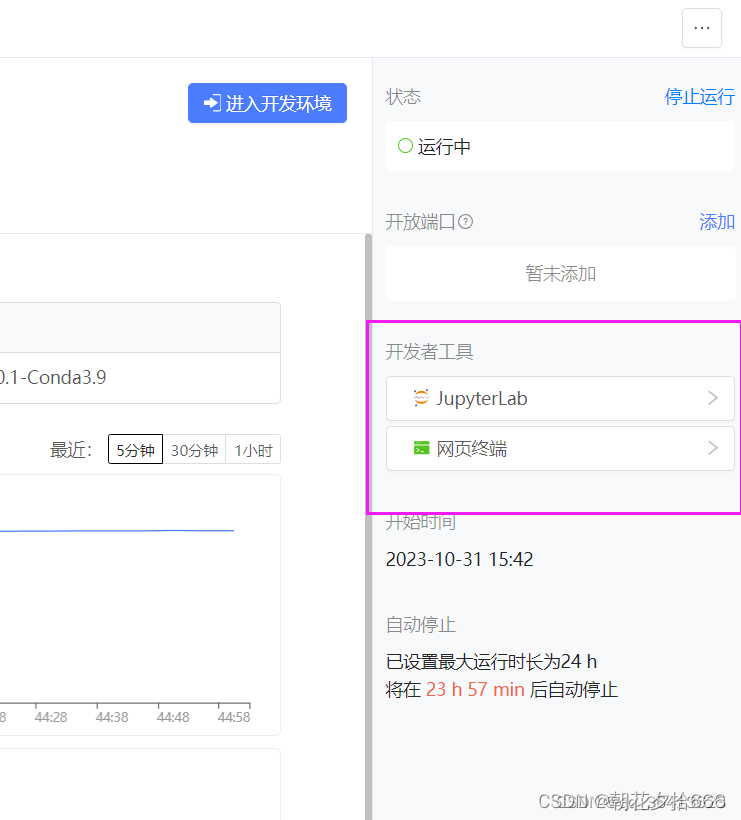
等右边两个工具全部加载完毕之后,再点击JupyterLab进入开发环境~
进入界面之后是这样的,然后点击这个小加号。
点击terminal,进入终端。
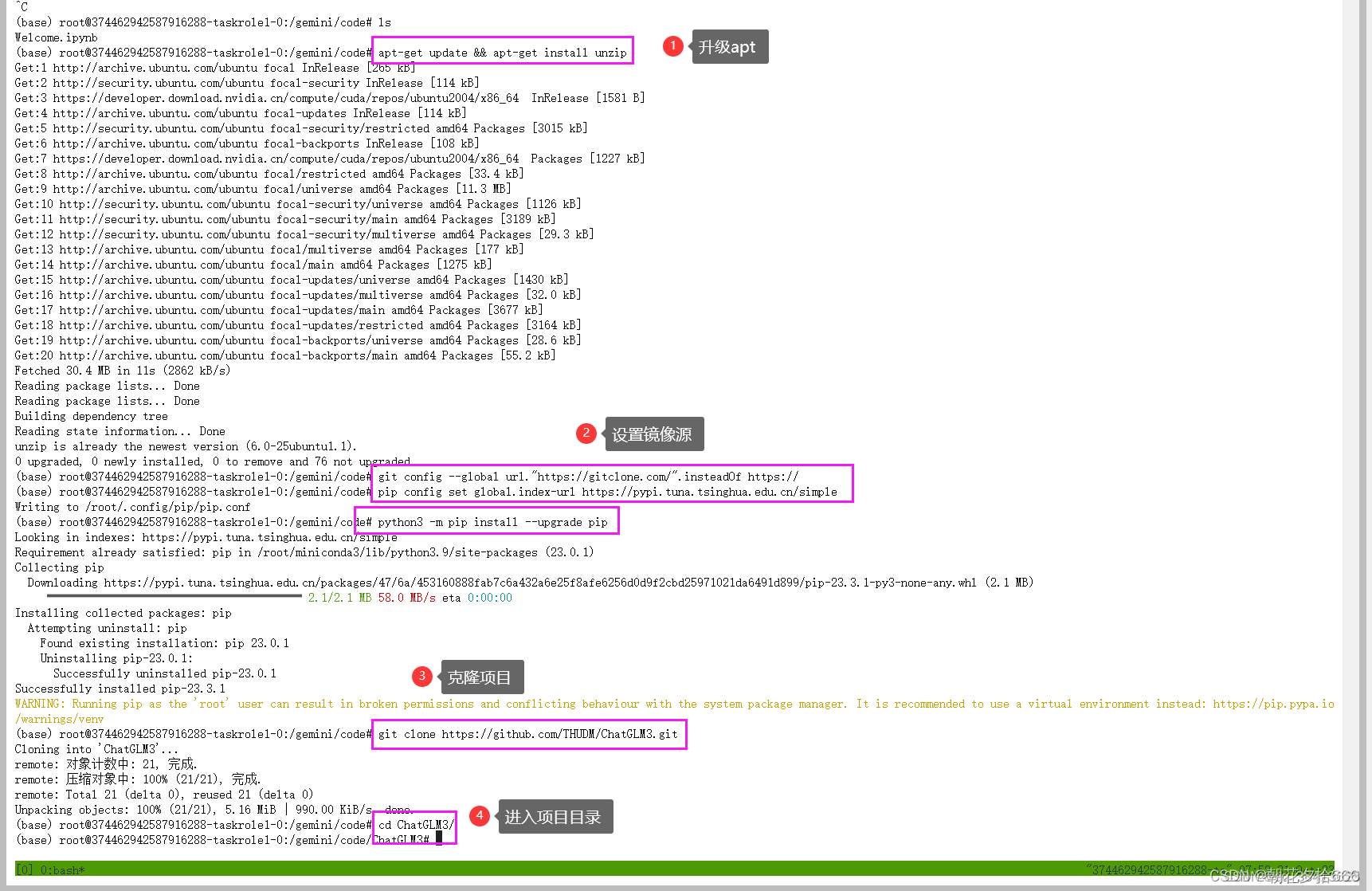
设置镜像源、克隆项目
首先在终端输入tmux,进入一个新的会话窗口。使用tmux可以保持终端的稳定性。
tmux升级apt,安装unzip
apt-get update && apt-get install unzip设置镜像源,升级pip
git config --global url."https://gitclone.com/".insteadOf https://
pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple
python3 -m pip install --upgrade pip
克隆项目,并进入项目目录
git clone https://github.com/THUDM/ChatGLM3.git
cd ChatGLM3
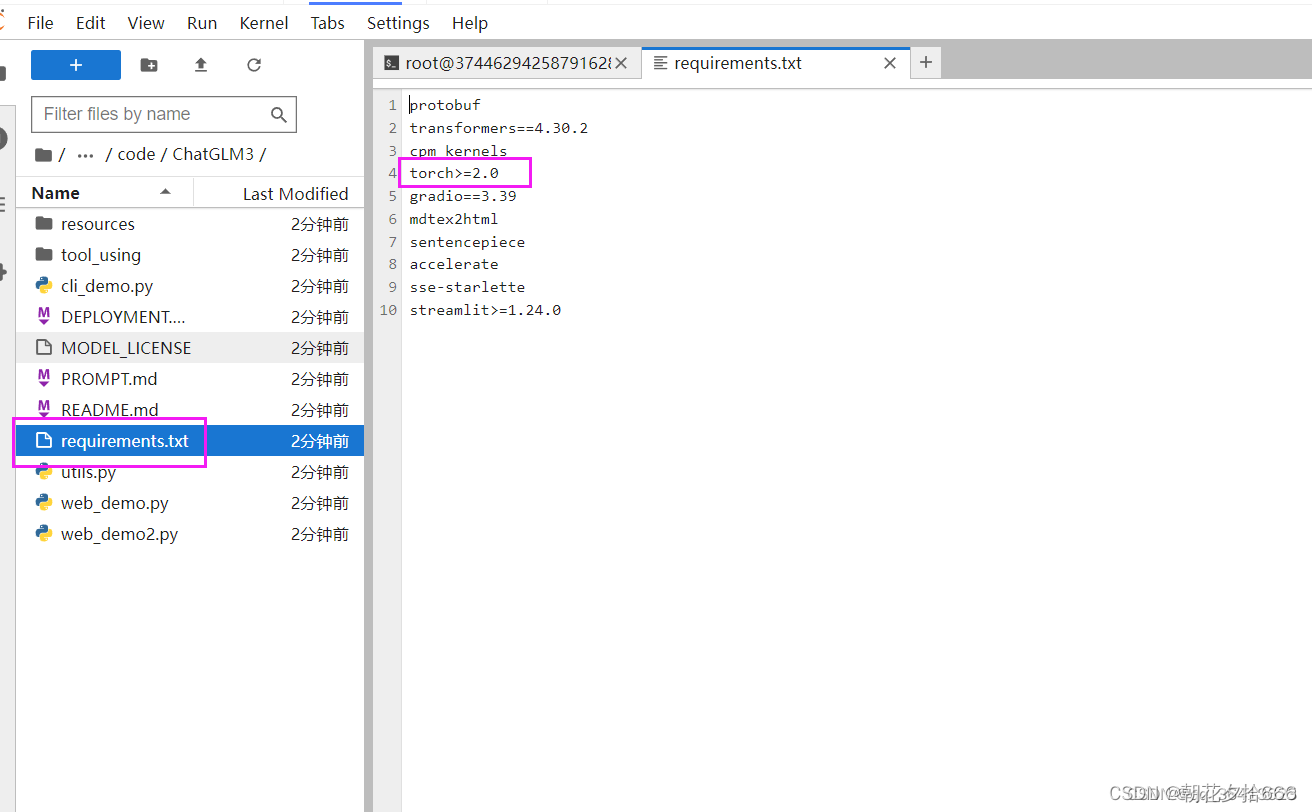
修改requirements
双击左侧的requirements.txt文件,把其中的torch删掉,因为我们的环境中已经有torch了,避免重复下载浪费时间。
点击左上选项卡,重新返回终端,安装依赖
pip install -r requirements.txt
修改代码
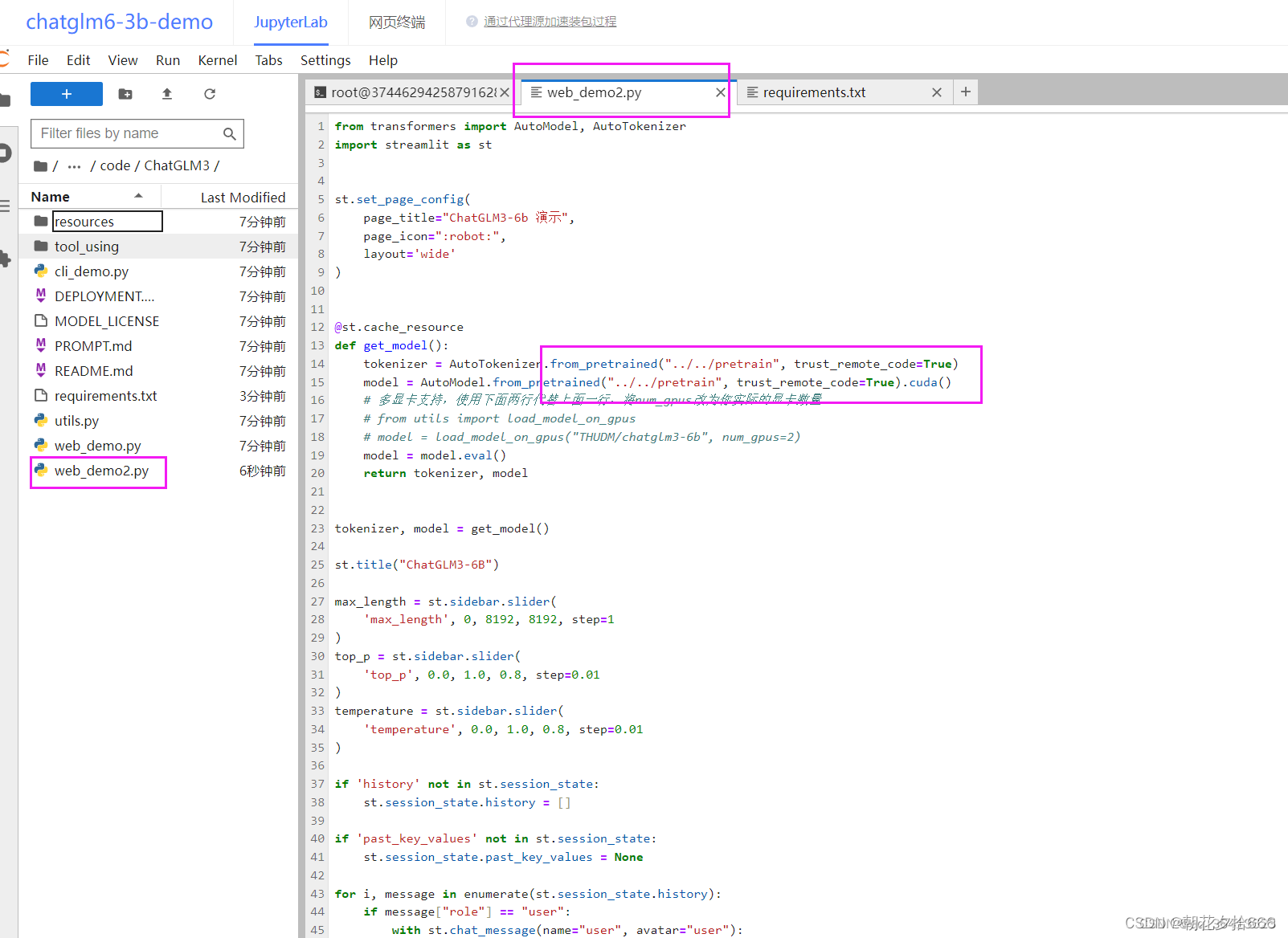
修改web_demo2.py
双击web_demo2.py,将加载模型的路径修改为:../../pretrain,如下图所示~
修改web_demo.py
和上面一样我们修改一下模型路径,不同的是,接下来还需要修改一段启动代码~
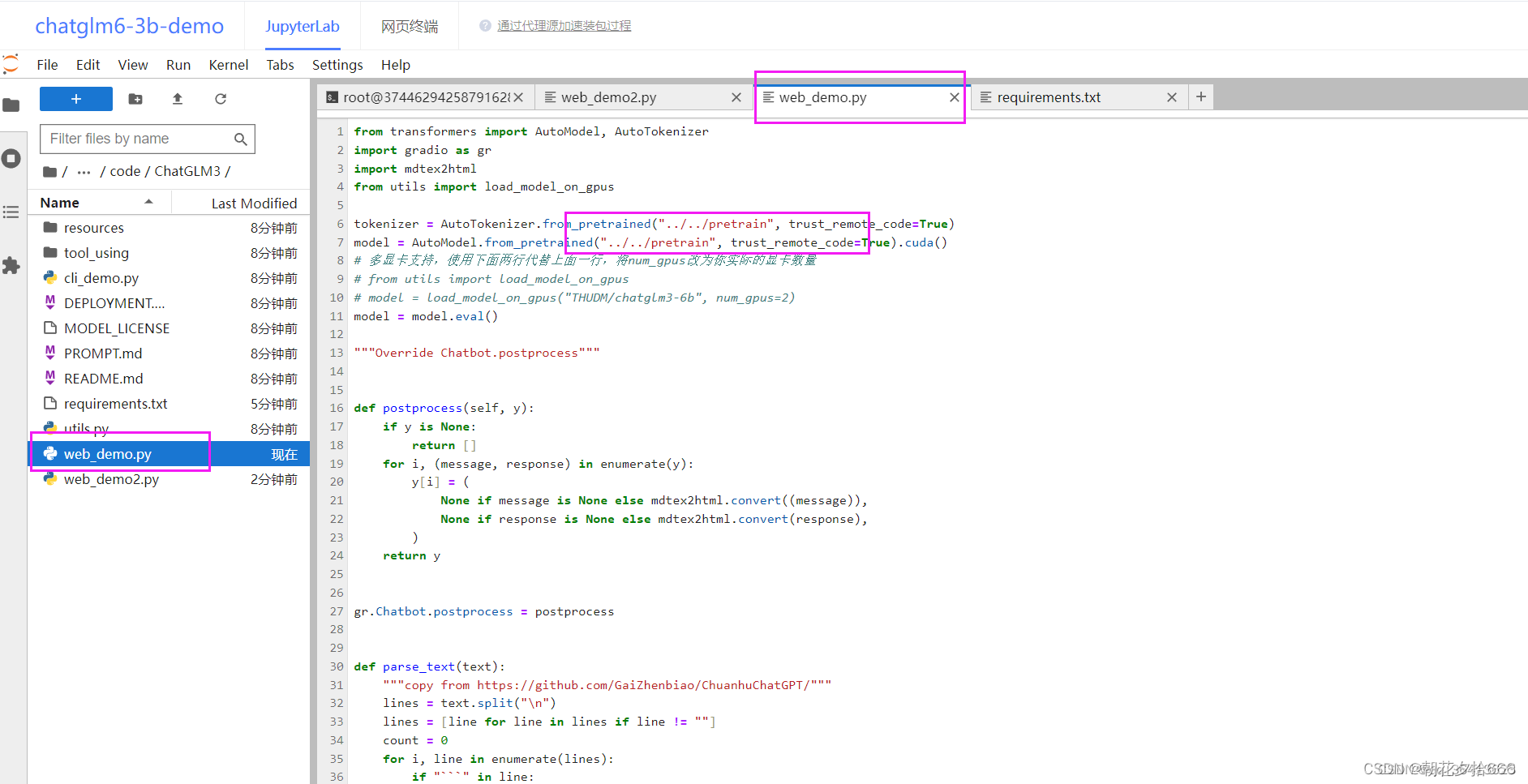
将下方的启动代码修改为下方代码。
demo.queue().launch(share=False, server_name="0.0.0.0",server_port=7000)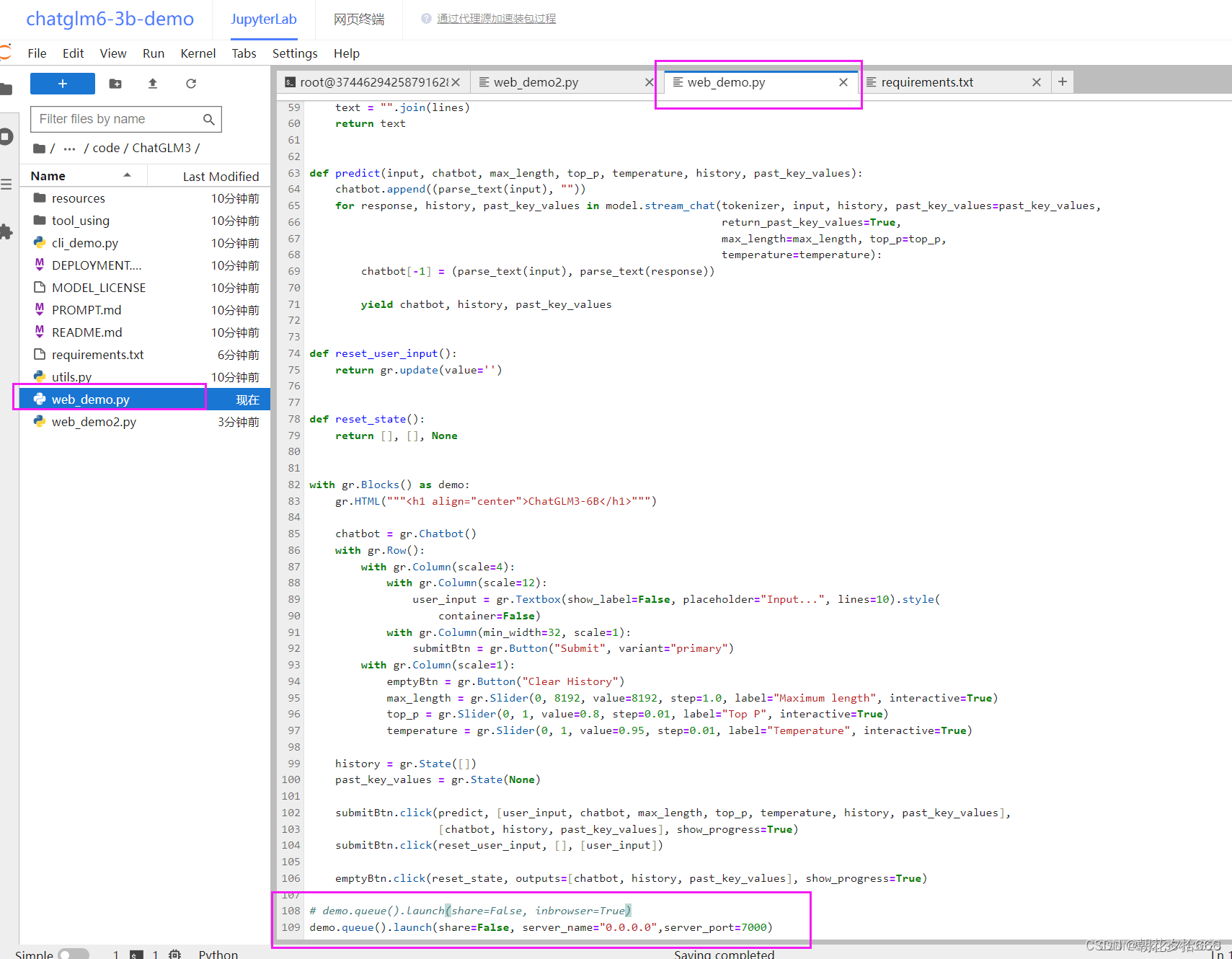
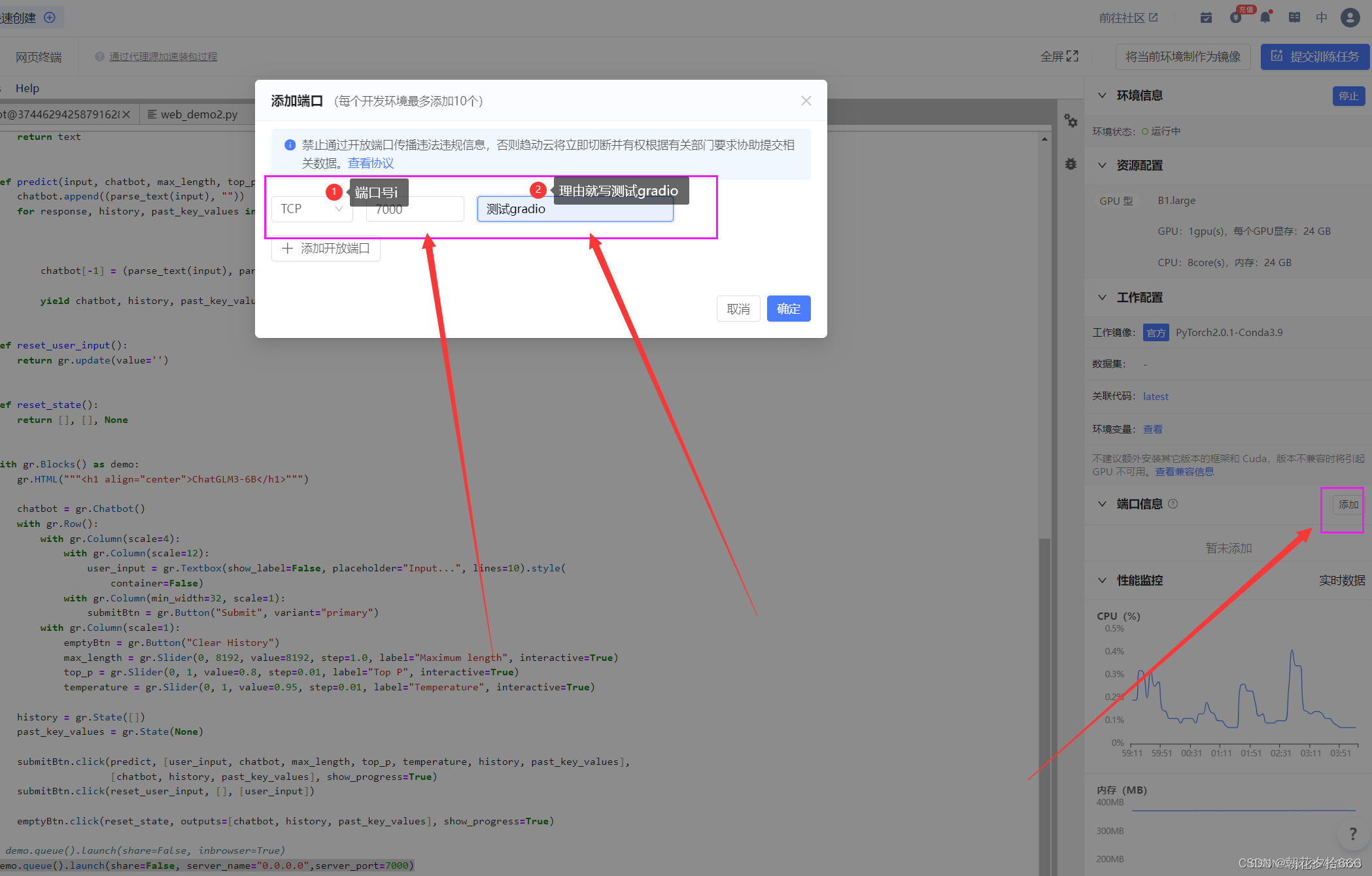
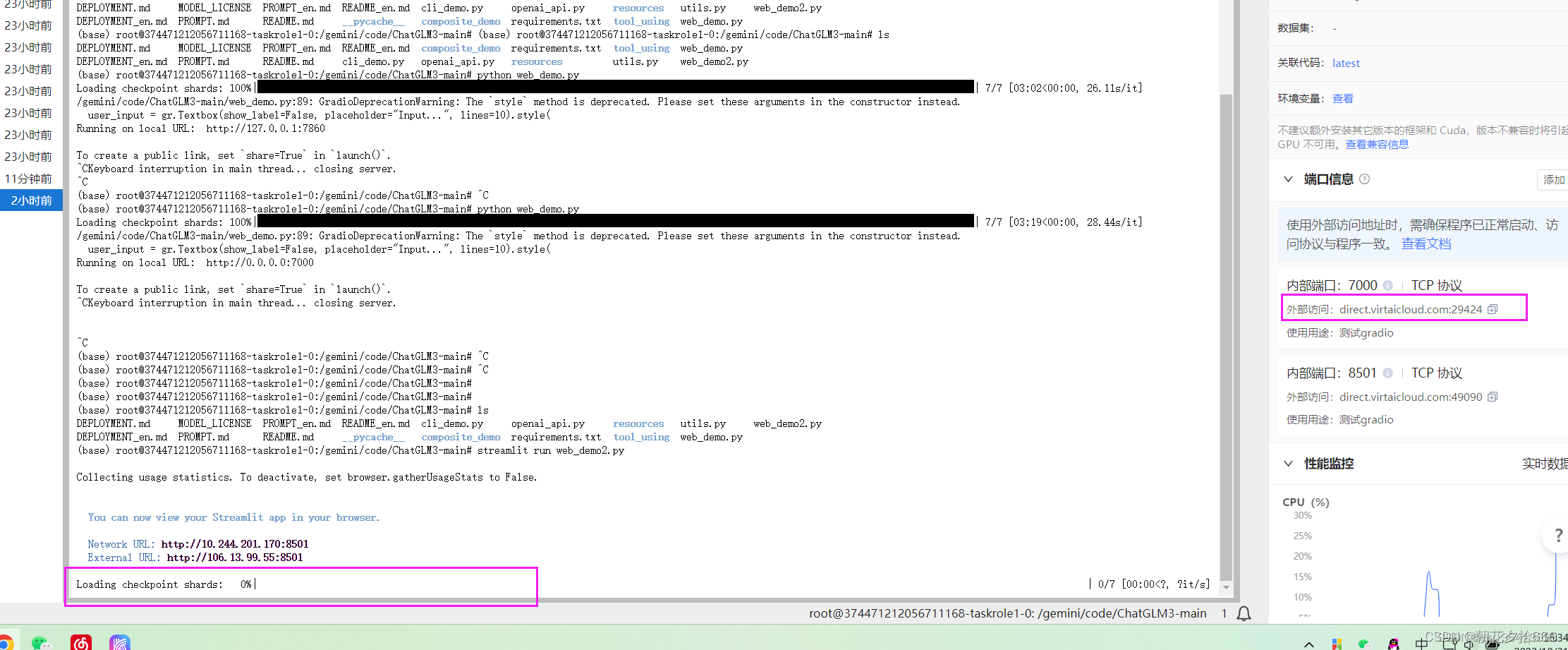
于此同时在界面的右边添加外部端口:7000
3.运行代码
运行gradio界面
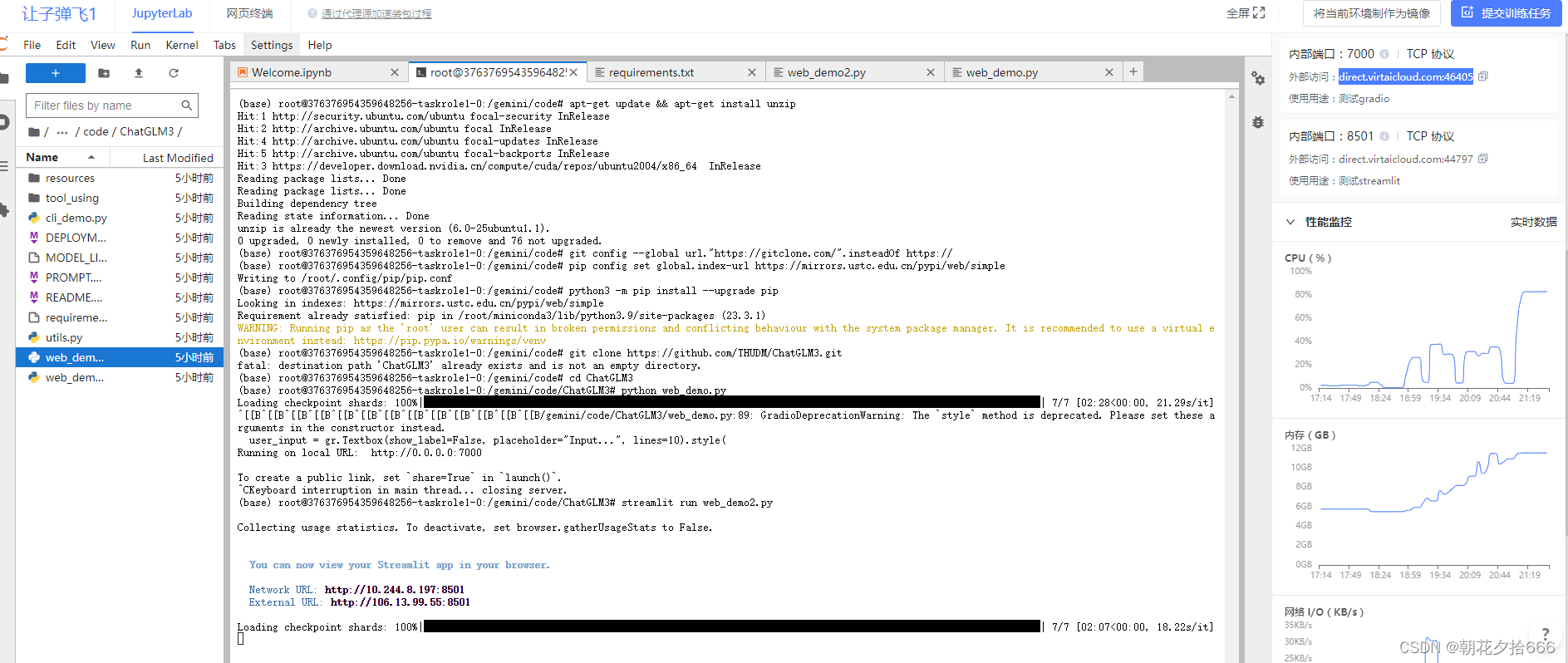
python web_demo.py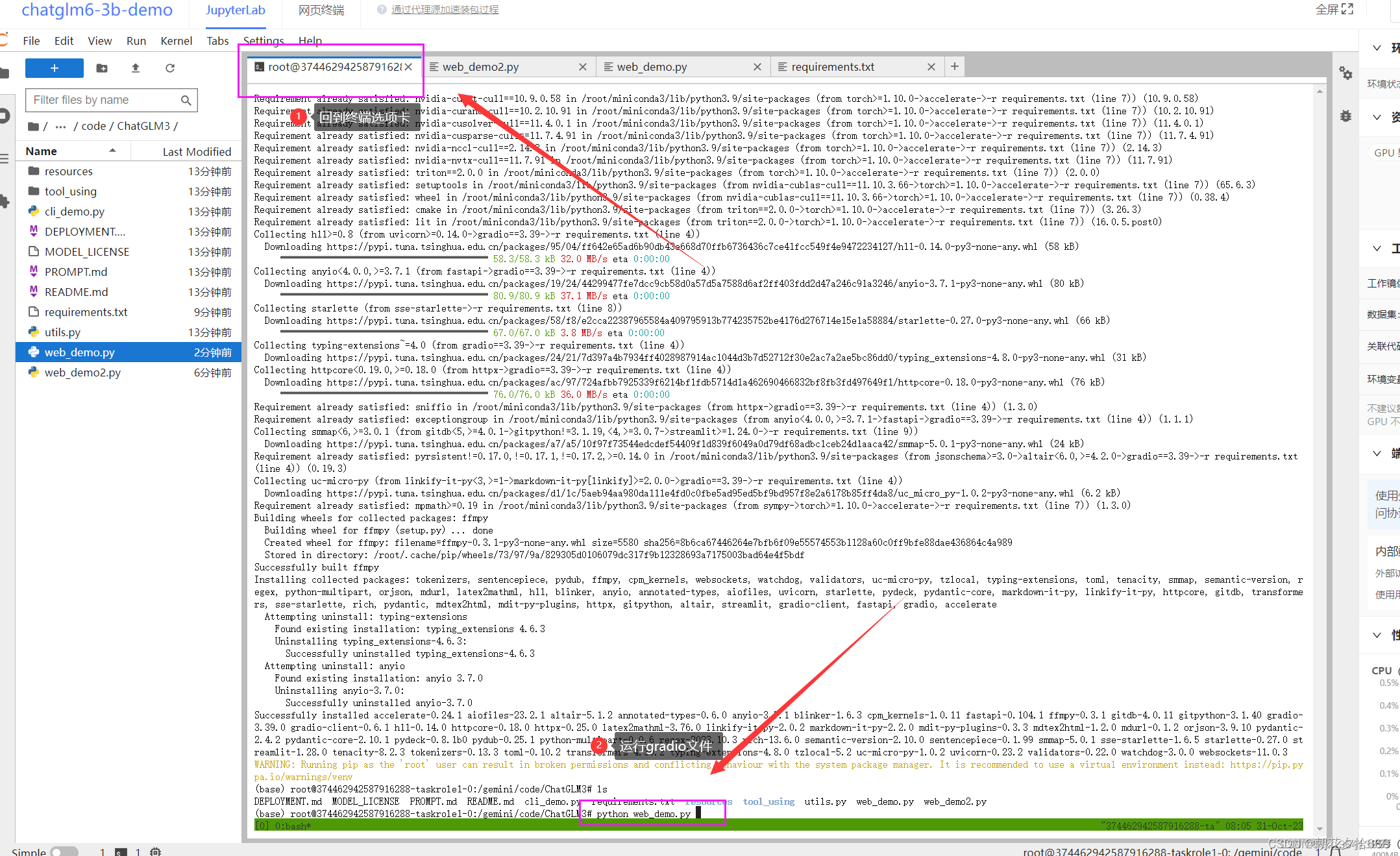 等待模型慢慢加载完毕,可能需要个五六分钟叭保持一点耐心 ~
等待模型慢慢加载完毕,可能需要个五六分钟叭保持一点耐心 ~
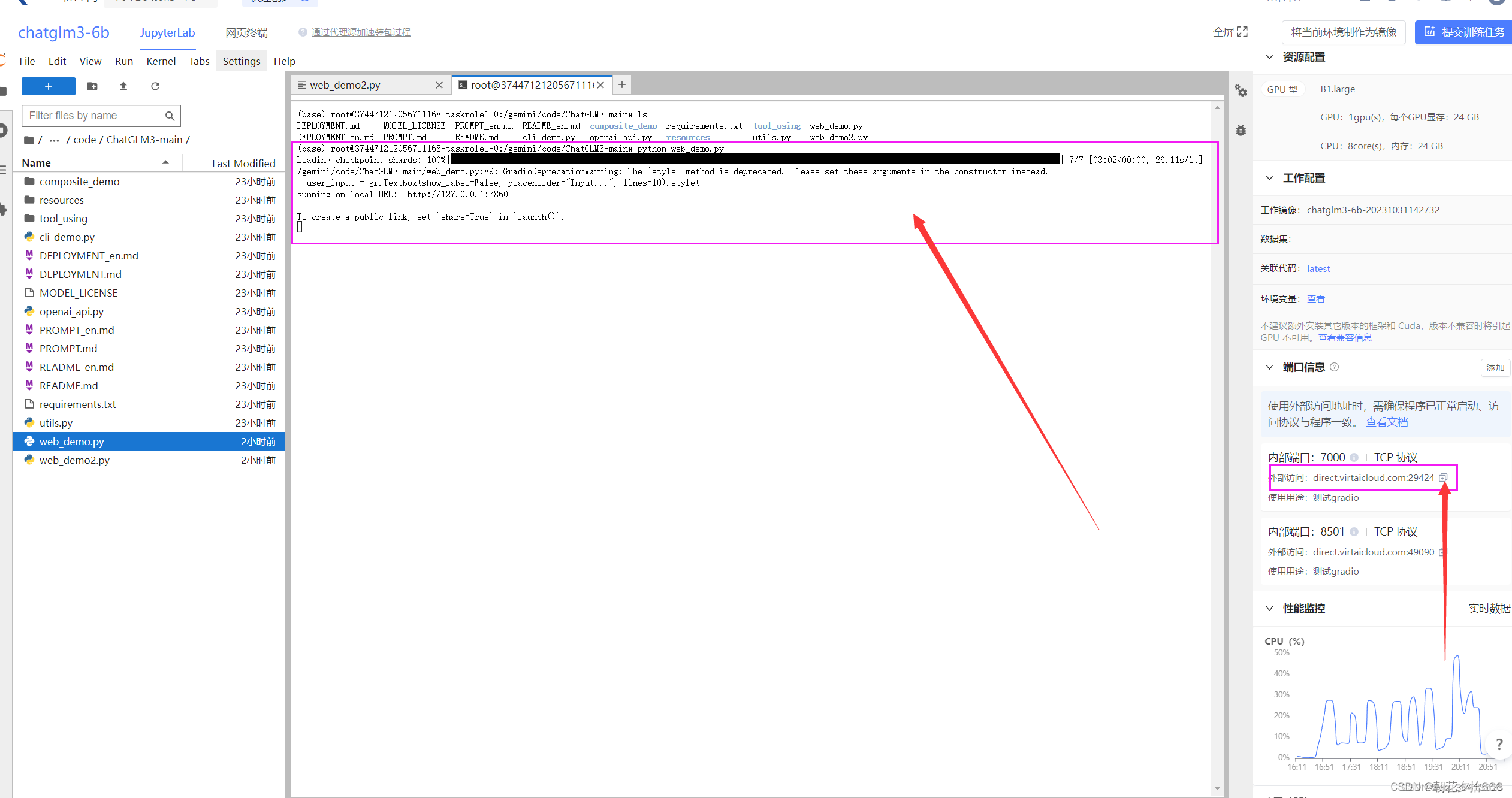
加载完毕之后,复制外部访问的连接,到浏览器打开
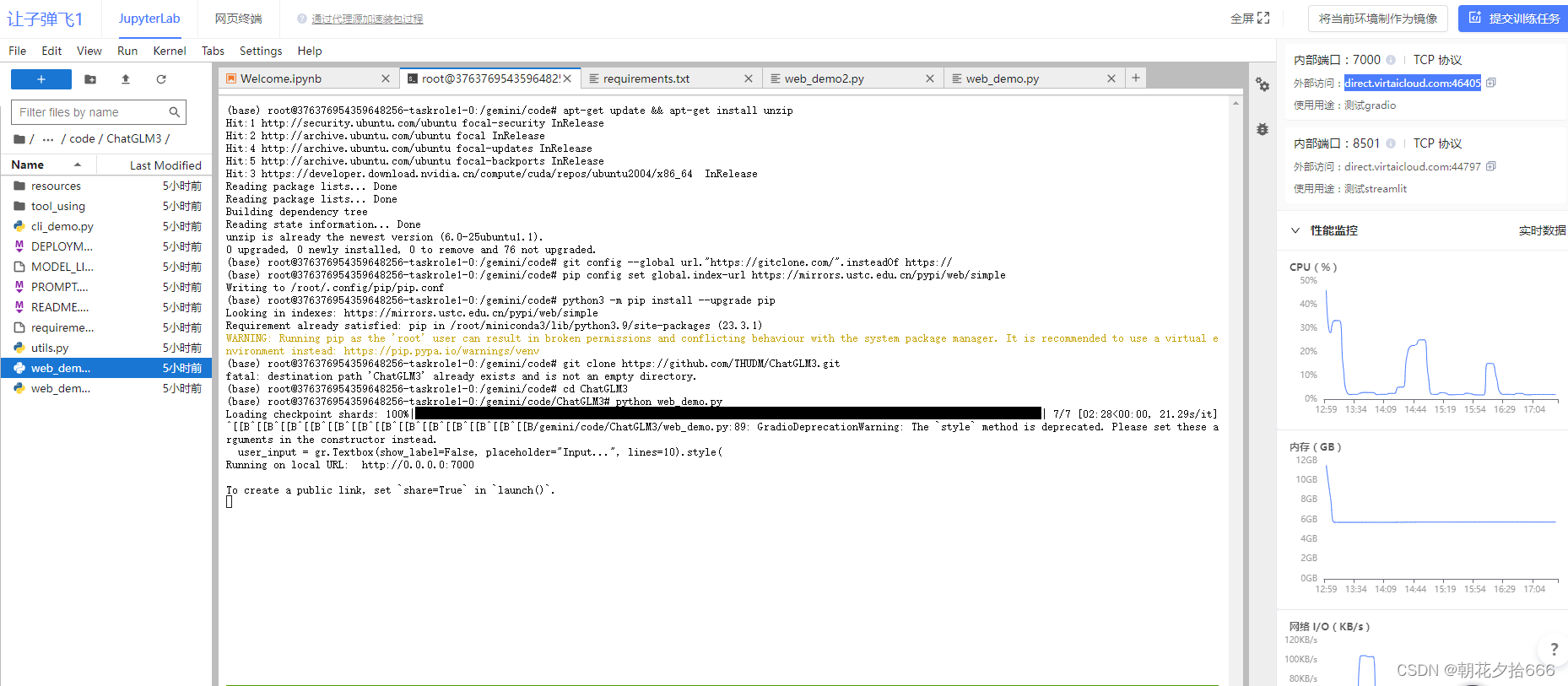
运行streamlit界面
如果你运行了gradio,需要先杀掉这个进程,不然内存不够。ctrl+C 可以杀掉进程~杀掉进程之后,显存不会立刻释放,可以观察右边的GPU内存占用,查看显存释放情况。
上面咱们已经修改过web_demo2.py的代码了,所以可以直接用streamlit运行。
streamlit run web_demo2.py
运行streamlit之后,终端会打印两个地址。在右边添加一个和终端上显示的一样的端口号
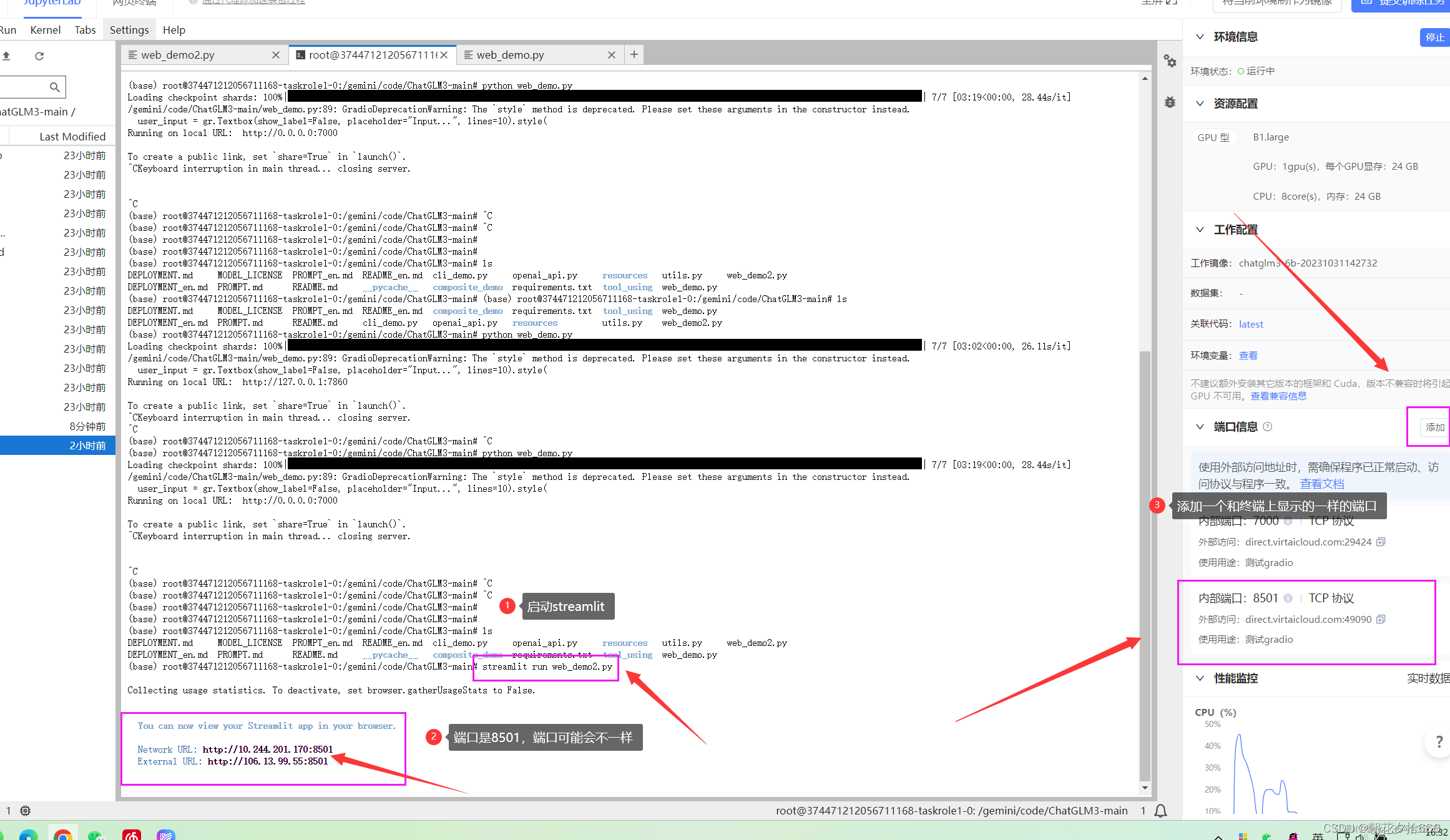
复制外部访问地址到浏览器打开,之后模型才会开始加载。等待模型记载完毕~
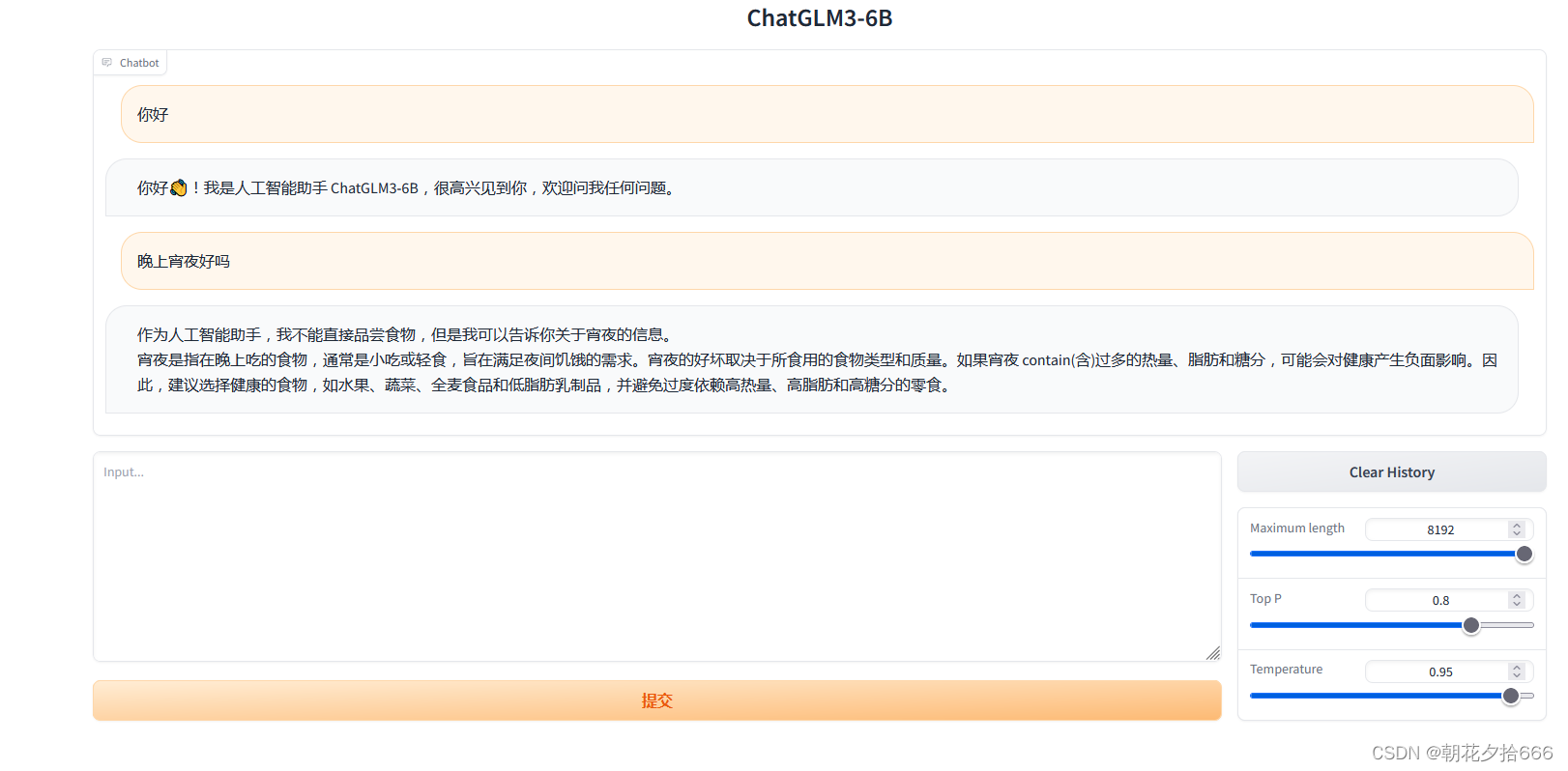
 okk,下面就是开始体验!
okk,下面就是开始体验!
试了一下,速度还是挺快的