【科研建模】Industrial Accident Causal Analysis(Gold prize)
1 项目概况
项目详情
在该数据集中,巴西公司 IHM Stefanini 提供了 3 个国家 12 家制造工厂的事故信息。我们需要利用这个数据集来了解事故发生的原因,并发现减少事故悲剧的线索。
数据集列如下:
- 日期(Date):时间戳或时间/日期信息
- 国家(Countries):事故发生在哪个国家(匿名)
- 当地(Local):生产工厂所在城市(匿名)
- 行业(Industry sector):工厂所属的行业
- 事故等级(Accident level):从 I 到 VI,记录事故的严重程度(I 表示不严重,VI 表示非常严重)
- 潜在事故等级(Potential Accident level):根据事故等级,数据库还记录了事故可能的严重程度(由于事故涉及的其他因素)
- 性别(Genre):如果受伤者是男性或女性
- 雇员或第三方(Employee or Third Party):受伤者是雇员还是第三方
- 关键风险(Critical Risk):对事故所涉风险的一些描述
- 描述(Descrition): 详细描述事故是如何发生的
项目的目标
- 练习预处理技术
- 与时间相关的特征提取
- NLP 预处理(小写、词法化、词干化和删除停止词)
- 练习 EDA 技术
- 练习可视化技术(尤其是通过全景图使用虚化技术)
- 练习特征工程技术
- 时间相关特征
- NLP 特征(TF-IDF)
- 练习建模技术
- LightGBM(+绘制树状图)
- 因果分析技巧
2 模块库导入
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score
import os
from sklearn.feature_extraction.text import TfidfVectorizer
from nltk import tokenize,stem
import holoviews as hv
from holoviews import opts
hv.extension('bokeh')
import lightgbm as lgb
import nltk
from nltk.util import ngrams
nltk.download('vader_lexicon')
from nltk.sentiment.vader import SentimentIntensityAnalyzer
from wordcloud import WordCloud, STOPWORDS
import shap
shap.initjs()
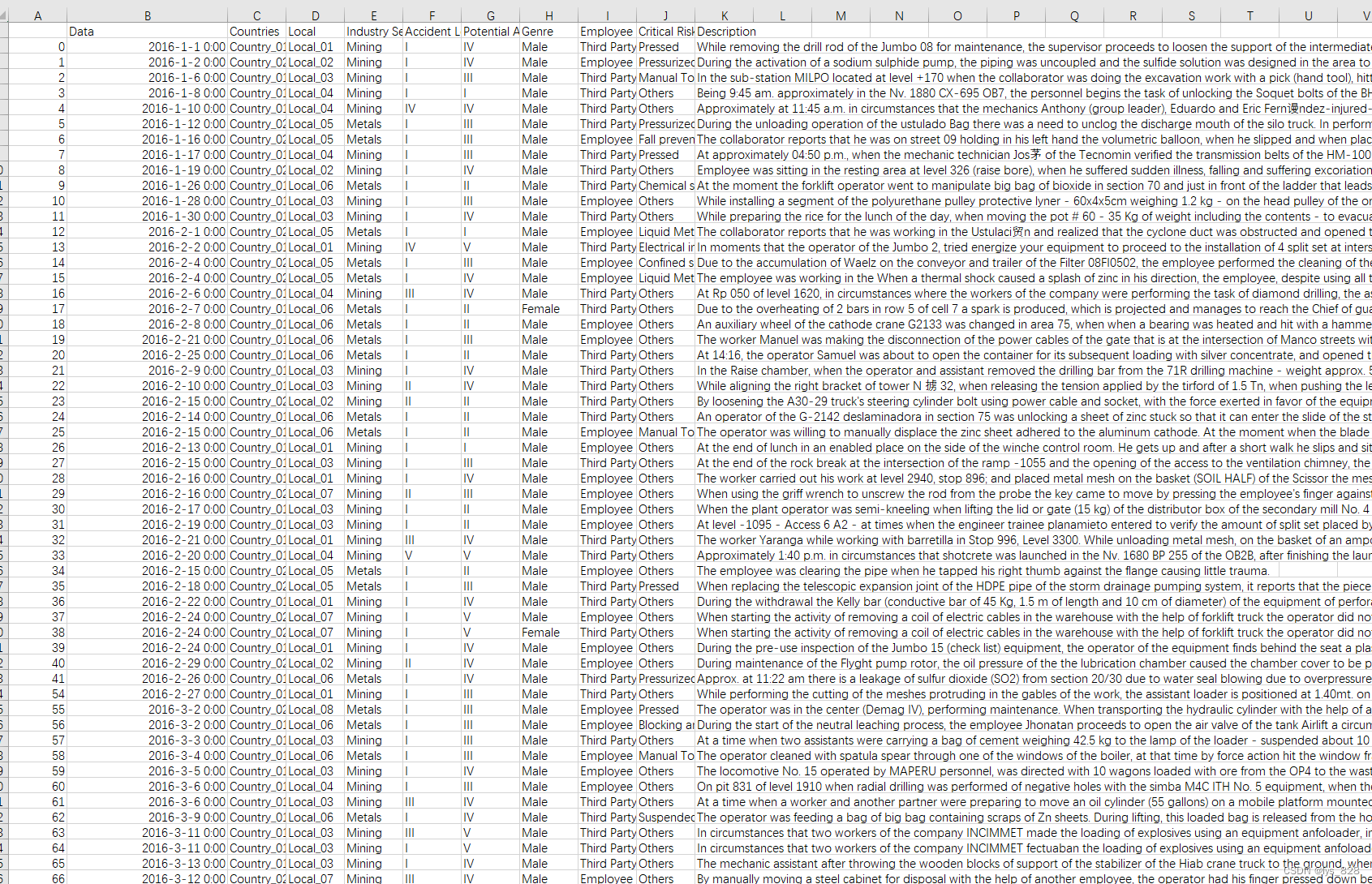
执行后输出结果如下(如果出现没有xxx no module,需要先进行安装,此外nltk的字典需要外网才能下载,正常运行是如下图所示)
3 加载数据集
首先获取数据集所在的路径地址,数据集都放在data文件夹中
for dirname, _, filenames in os.walk('data'):
for filename in filenames:
print(os.path.join(dirname, filename))
输出结果如下

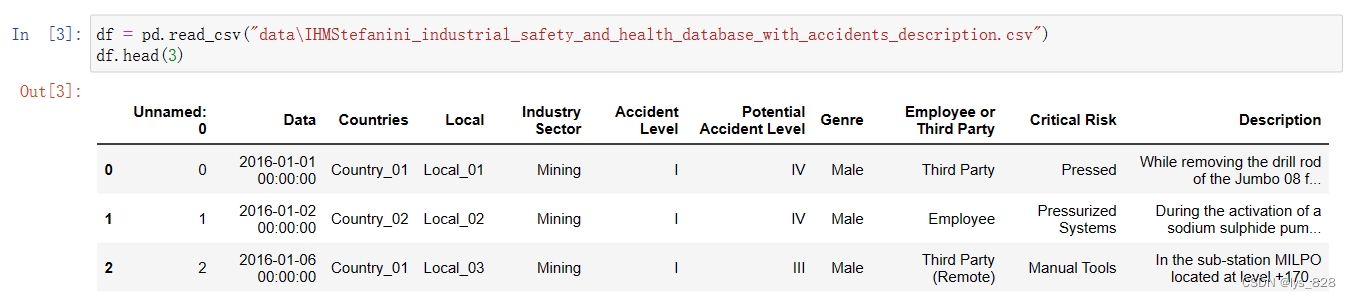
然后读取数据,并查看前3行,输出结果如下
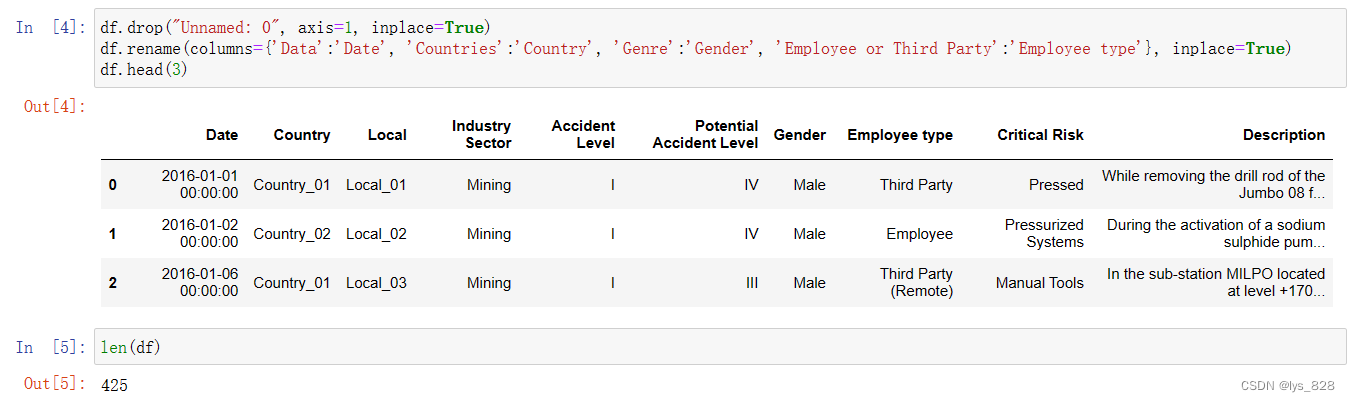
删除不必要的列,并对数据表中的字段名称进行重命名
df.drop("Unnamed: 0", axis=1, inplace=True)
df.rename(columns={'Data':'Date', 'Countries':'Country', 'Genre':'Gender', 'Employee or Third Party':'Employee type'}, inplace=True)
df.head(3)
执行后,输出结果如下(输出核实无误,顺带输出总的样本数量)
4 数据预处理
4.1 时间特征提取
事故在一年或一月中可能会增加或减少,因此我添加了日期时间功能,如年、月和日。(探究事故的时间特征)
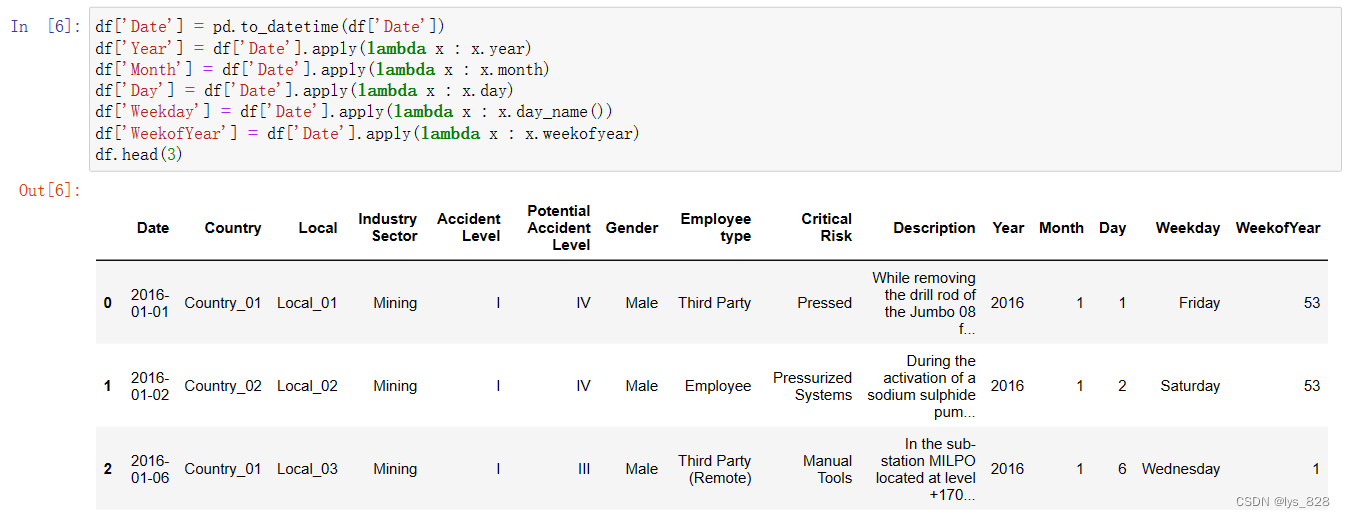
df['Date'] = pd.to_datetime(df['Date'])
df['Year'] = df['Date'].apply(lambda x : x.year)
df['Month'] = df['Date'].apply(lambda x : x.month)
df['Day'] = df['Date'].apply(lambda x : x.day)
df['Weekday'] = df['Date'].apply(lambda x : x.day_name())
df['WeekofYear'] = df['Date'].apply(lambda x : x.weekofyear)
df.head(3)
代码及输出结果如下
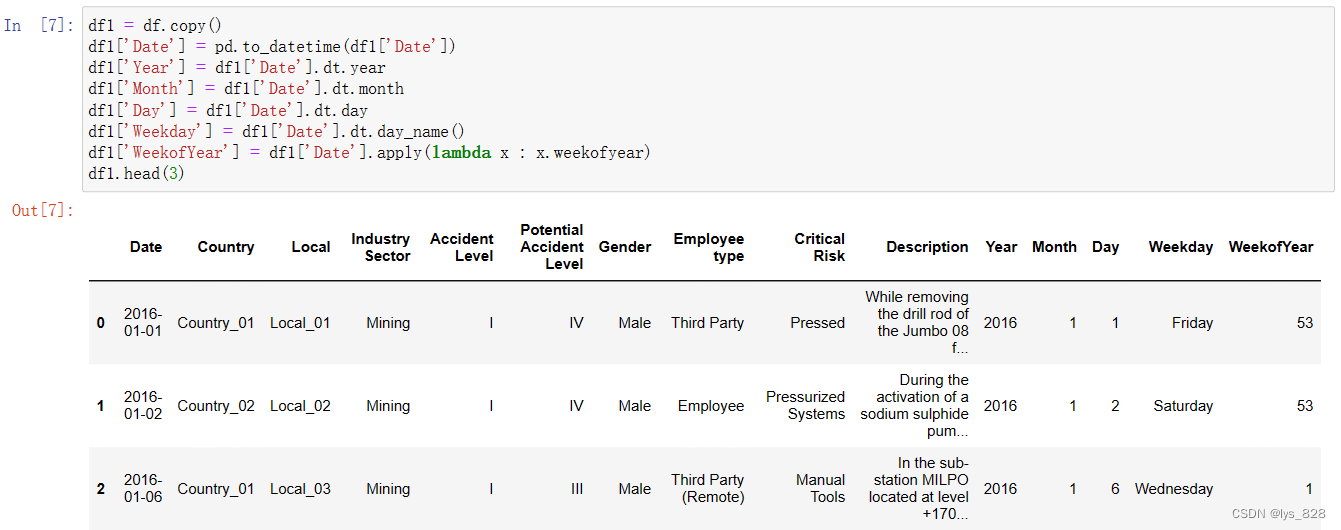
此外pandas中又专门对时间处理的快速方式,借助.dt方法,代码等同如下
df1 = df.copy()
df1['Date'] = pd.to_datetime(df1['Date'])
df1['Year'] = df1['Date'].dt.year
df1['Month'] = df1['Date'].dt.month
df1['Day'] = df1['Date'].dt.day
df1['Weekday'] = df1['Date'].dt.day_name()
df1['WeekofYear'] = df1['Date'].apply(lambda x : x.weekofyear)
df1.head(3)
测试输出结果与上面一致
进一步可以查看此方法下可以使用的时间转化方式,由于没有weekofyear(当前使用的版本中),还是采用原来的方式进行
代码示例: print(dir(df1['Date'].dt))

4.2 季节变量提取
数据集的收集国是匿名的,但它们都位于南美洲。因此,在本分析中,我们假设数据集是在巴西收集的。
巴西有以下四个气候季节:
春季:九月至十一月
夏季:十二月至次年二月
秋季:三月至五月
冬季:六月至八月
我们可以根据月份变量创建季节变量。
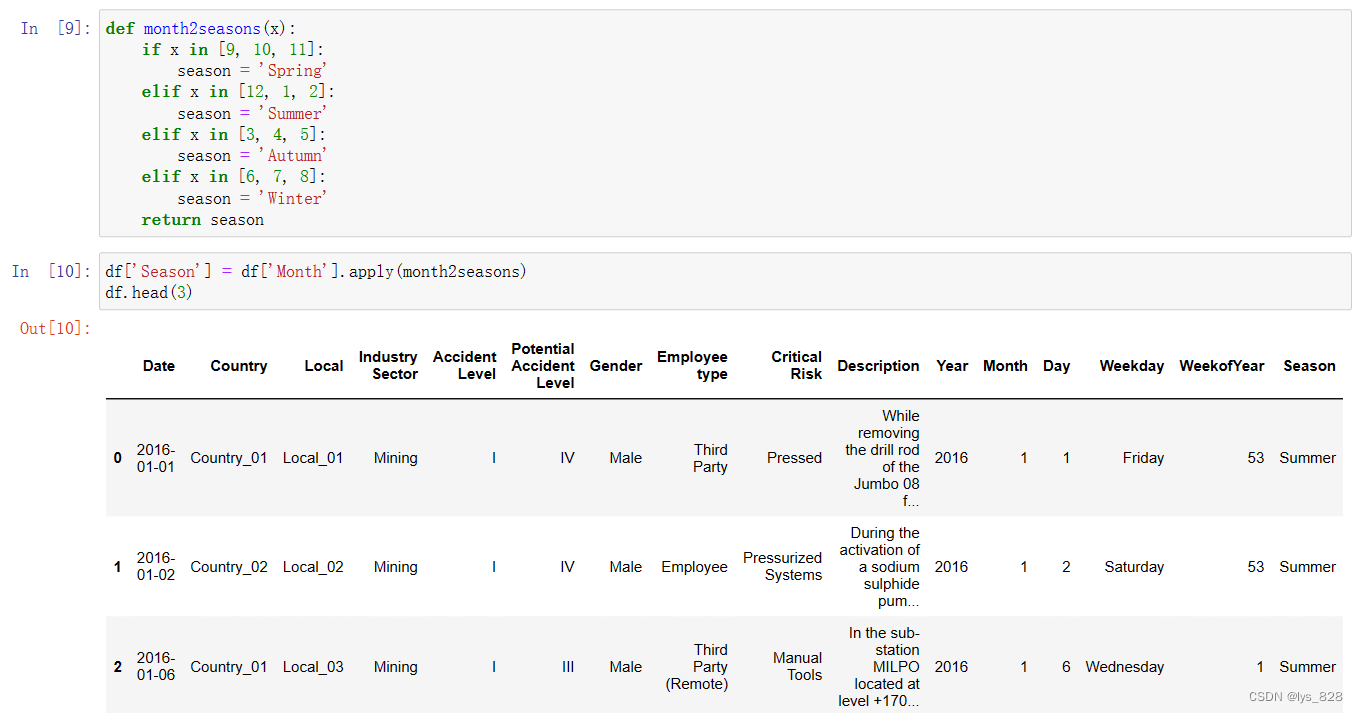
def month2seasons(x):
if x in [9, 10, 11]:
season = 'Spring'
elif x in [12, 1, 2]:
season = 'Summer'
elif x in [3, 4, 5]:
season = 'Autumn'
elif x in [6, 7, 8]:
season = 'Winter'
return season
df['Season'] = df['Month'].apply(month2seasons)
df.head(3)
运行输出结果如下
4.3 NLP预处理
描述栏包含事故发生原因的详细信息。因此,我尝试使用 NLP 技术利用这些重要信息添加新的特征。
除了 WORDCLOUD 中预设的停止词之外,我还通过检查 "描述 "栏中的文档定义了手工制作的停止词列表。
STOPWORDS.update(["cm", "kg", "mr", "wa" ,"nv", "ore", "da", "pm", "am", "cx"])
print(STOPWORDS)
输出结果如下

自然语言进行预处理的管道(流程),是有点复杂,所以我做了预处理功能。通过小写、标记化、词素化和词干化将文本转换为适用格式。
如果提示出现缺少nltk中的字典,直接复制报错提示进行下载安装,代码如下
import nltk
nltk.download('wordnet')
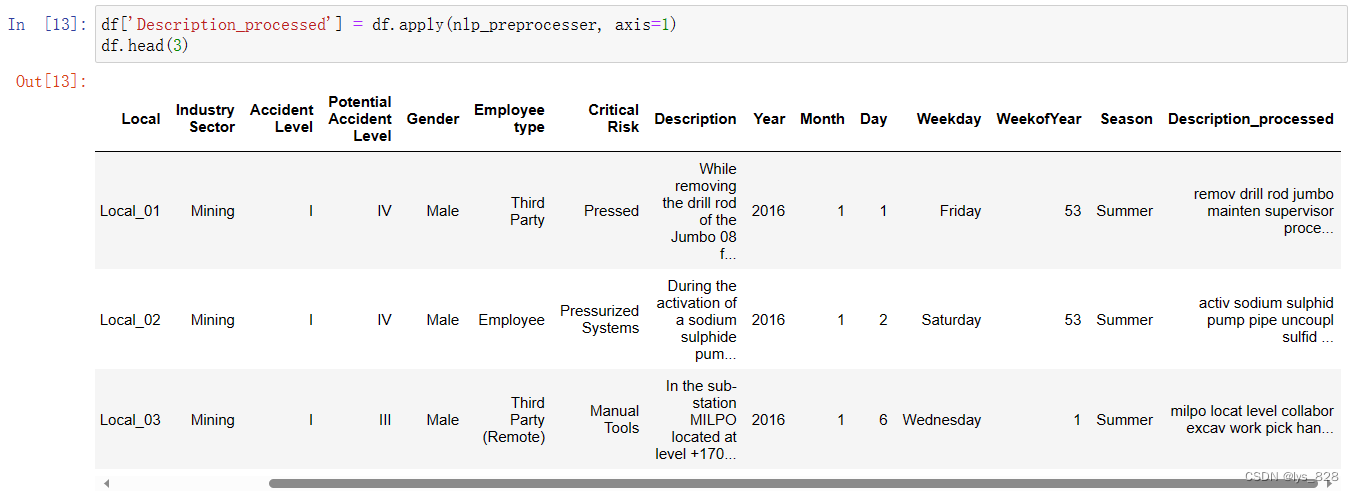
def nlp_preprocesser(row):
sentence = row.Description
#convert all characters to lowercase
lowered = sentence.lower()
tok = tokenize.word_tokenize(lowered)
#lemmatizing & stemming
lemmatizer = stem.WordNetLemmatizer()
lem = [lemmatizer.lemmatize(i) for i in tok if i not in STOPWORDS]
stemmer = stem.PorterStemmer()
stems = [stemmer.stem(i) for i in lem if i not in STOPWORDS]
#remove non-alphabetical characters like '(', '.' or '!'
alphas = [i for i in stems if i.isalpha() and (i not in STOPWORDS)]
return " ".join(alphas)
df['Description_processed'] = df.apply(nlp_preprocesser, axis=1)
df.head(3)
调用函数后,输出结果如下
4.4 情感得分
事故描述的积极性或消极性可能与事故的严重程度有关。
def sentiment2score(text):
analyzer = SentimentIntensityAnalyzer()
sent_score = analyzer.polarity_scores(text)["compound"]
return float(sent_score)
df['Description_sentiment_score'] = df['Description'].apply(lambda x: sentiment2score(x))
df.head(3)
函数调用后输出结果如下
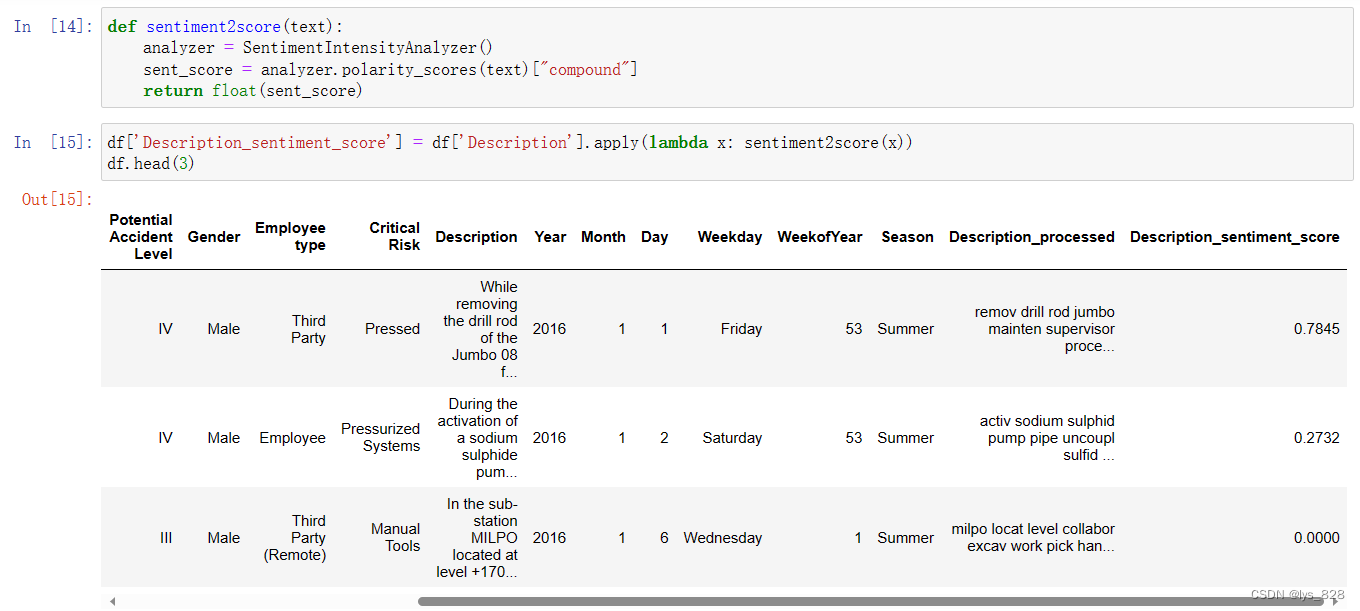
5 EDA
5.1 单变量分析
5.1.1 国家特征
country_cnt = np.round(df['Country'].value_counts(normalize=True) * 100)
hv.Bars(country_cnt).opts(title="Country Count", color="green", xlabel="Countries", ylabel="Percentage", yformatter='%d%%')\
.opts(opts.Bars(width=500, height=300,tools=['hover'],show_grid=True))\
* hv.Text('Country_01', 15, f"{int(country_cnt.loc['Country_01'])}%")\
* hv.Text('Country_02', 15, f"{int(country_cnt.loc['Country_02'])}%")\
* hv.Text('Country_03', 15, f"{int(country_cnt.loc['Country_03'])}%")
输出结果如下
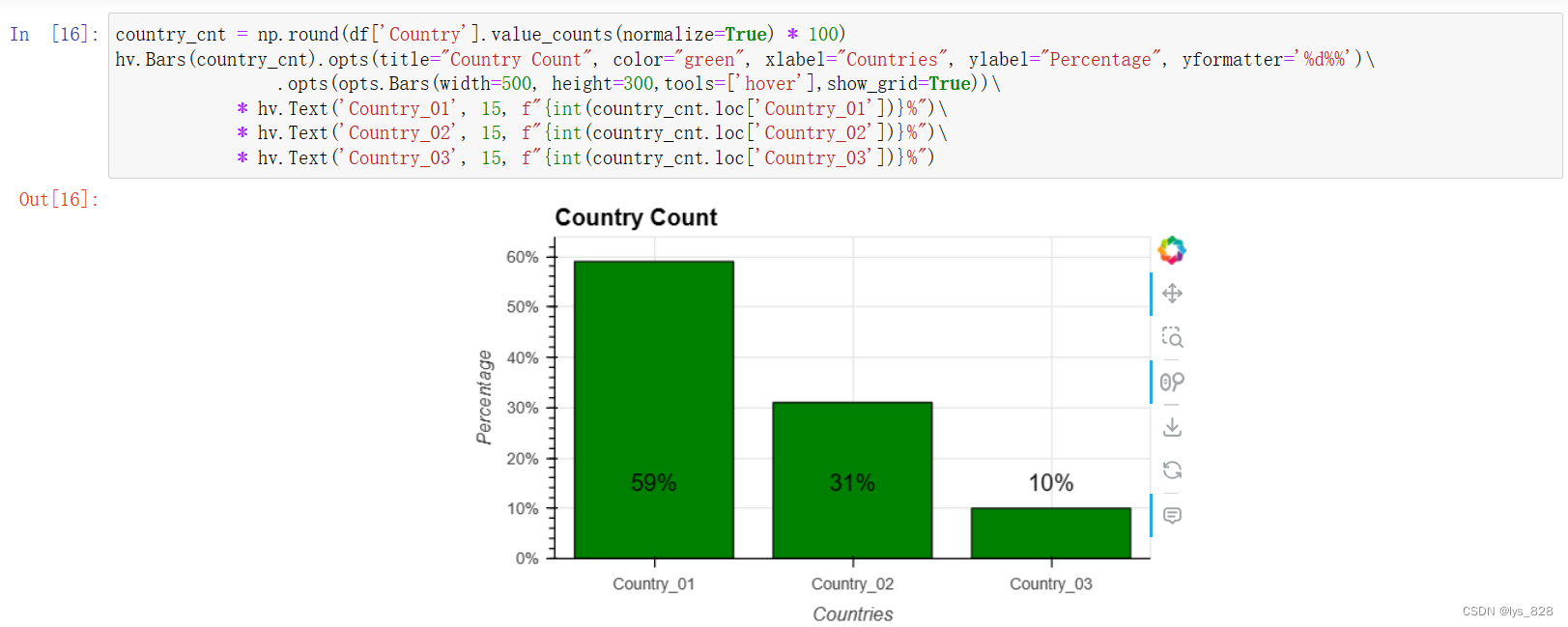
5.1.2 城市特征
local_cnt = np.round(df['Local'].value_counts(normalize=True) * 100)
hv.Bars(local_cnt).opts(title="Local Count", color="green", xlabel="Locals", ylabel="Percentage", yformatter='%d%%')\
.opts(opts.Bars(width=700, height=300,tools=['hover'],show_grid=True))
输出结果如下
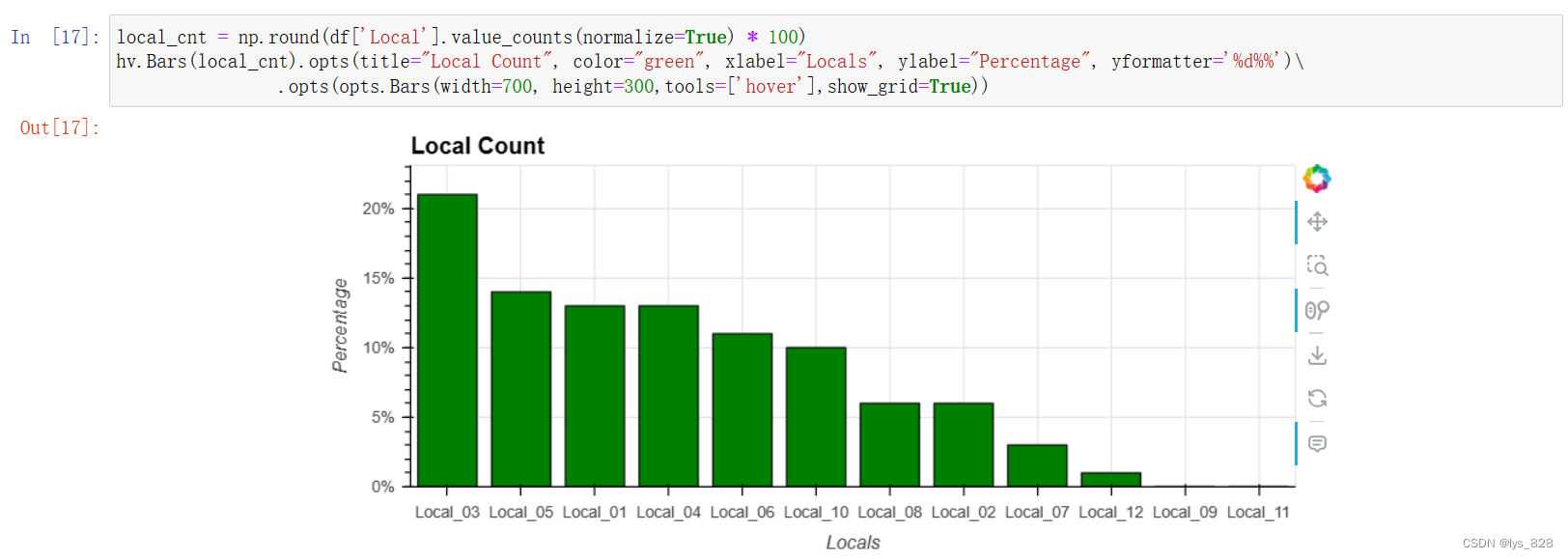
5.1.3 行业特征
sector_cnt = np.round(df['Industry Sector'].value_counts(normalize=True) * 100)
hv.Bars(sector_cnt).opts(title="Industry Sector Count", color="green", xlabel="Sectors", ylabel="Percentage", yformatter='%d%%')\
.opts(opts.Bars(width=500, height=300,tools=['hover'],show_grid=True))\
* hv.Text('Mining', 15, f"{int(sector_cnt.loc['Mining'])}%")\
* hv.Text('Metals', 15, f"{int(sector_cnt.loc['Metals'])}%")\
* hv.Text('Others', 15, f"{int(sector_cnt.loc['Others'])}%")
输出结果如下
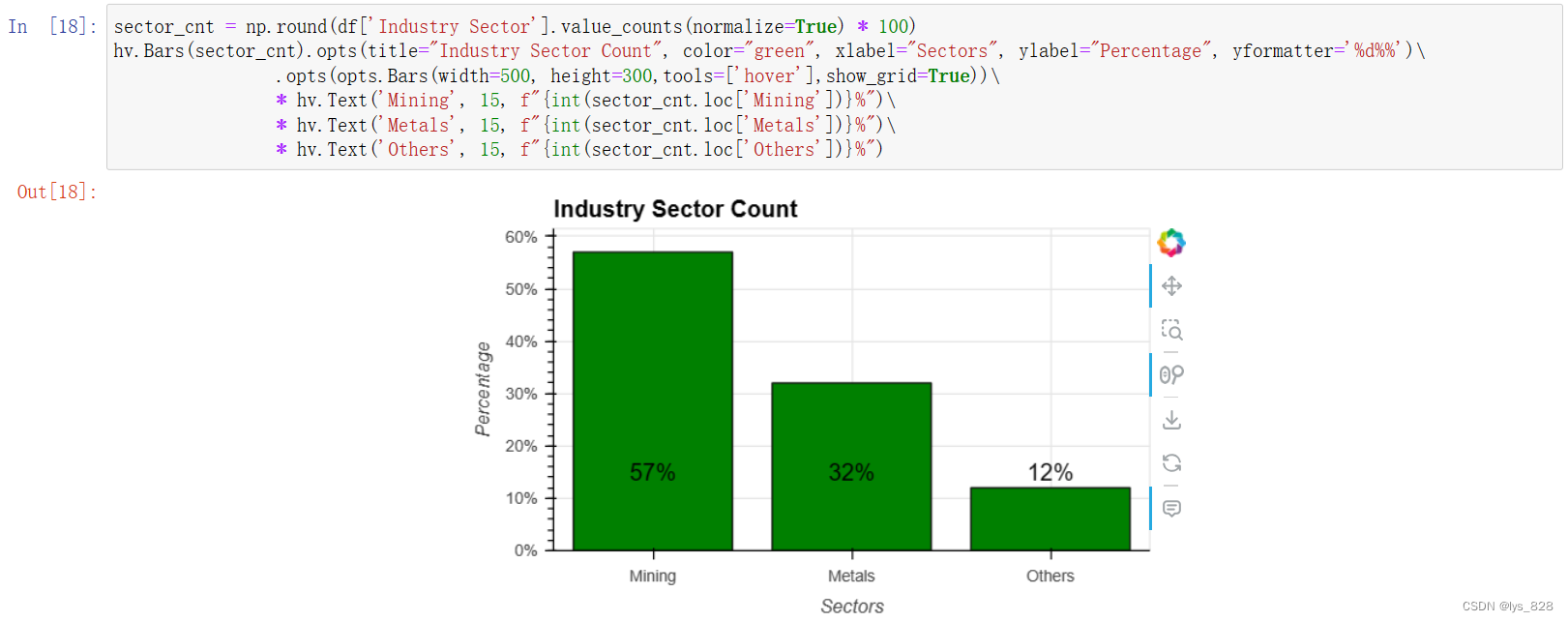
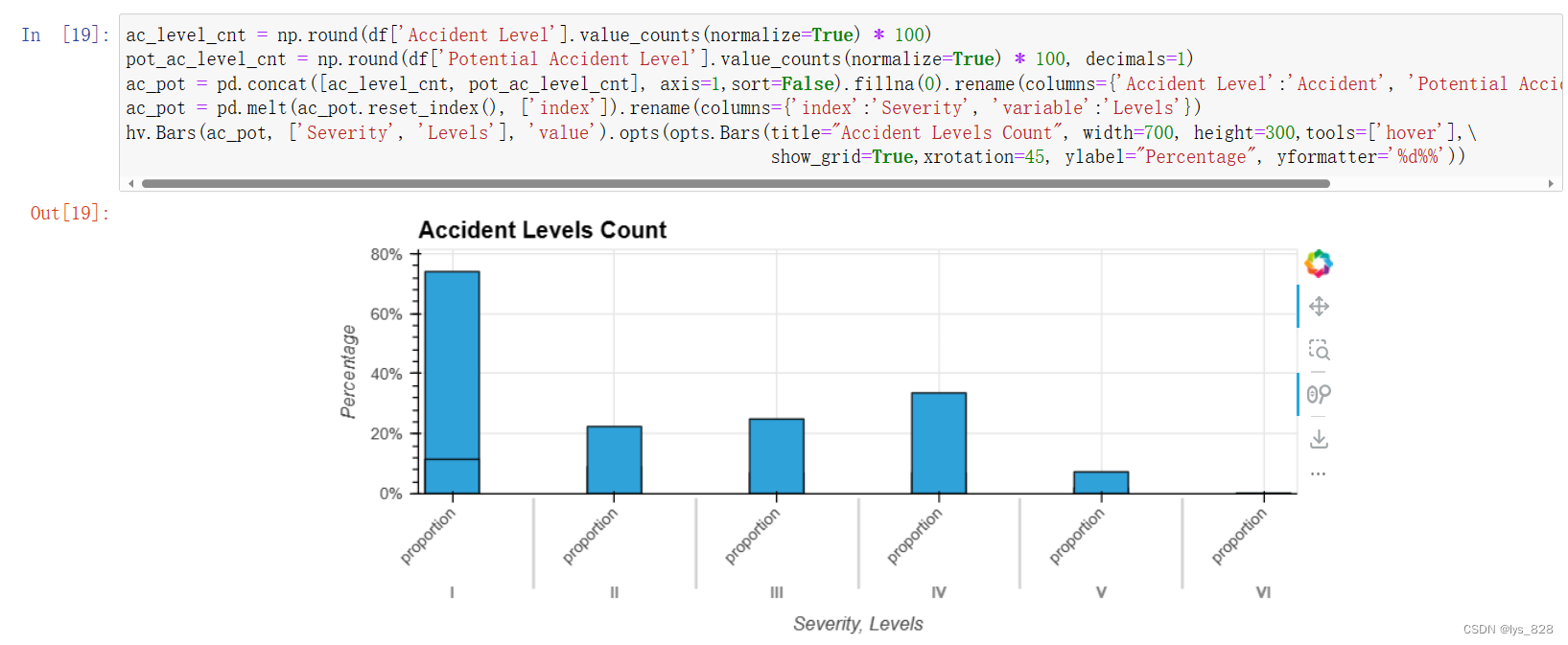
5.1.4 事故等级
ac_level_cnt = np.round(df['Accident Level'].value_counts(normalize=True) * 100)
pot_ac_level_cnt = np.round(df['Potential Accident Level'].value_counts(normalize=True) * 100, decimals=1)
ac_pot = pd.concat([ac_level_cnt, pot_ac_level_cnt], axis=1,sort=False).fillna(0).rename(columns={'Accident Level':'Accident', 'Potential Accident Level':'Potential'})
ac_pot = pd.melt(ac_pot.reset_index(), ['index']).rename(columns={'index':'Severity', 'variable':'Levels'})
hv.Bars(ac_pot, ['Severity', 'Levels'], 'value').opts(opts.Bars(title="Accident Levels Count", width=700, height=300,tools=['hover'],\
show_grid=True,xrotation=45, ylabel="Percentage", yformatter='%d%%'))
输出结果如下(事故数量随着事故等级的增加而减少。潜在事故等级越低,事故数量越多。)
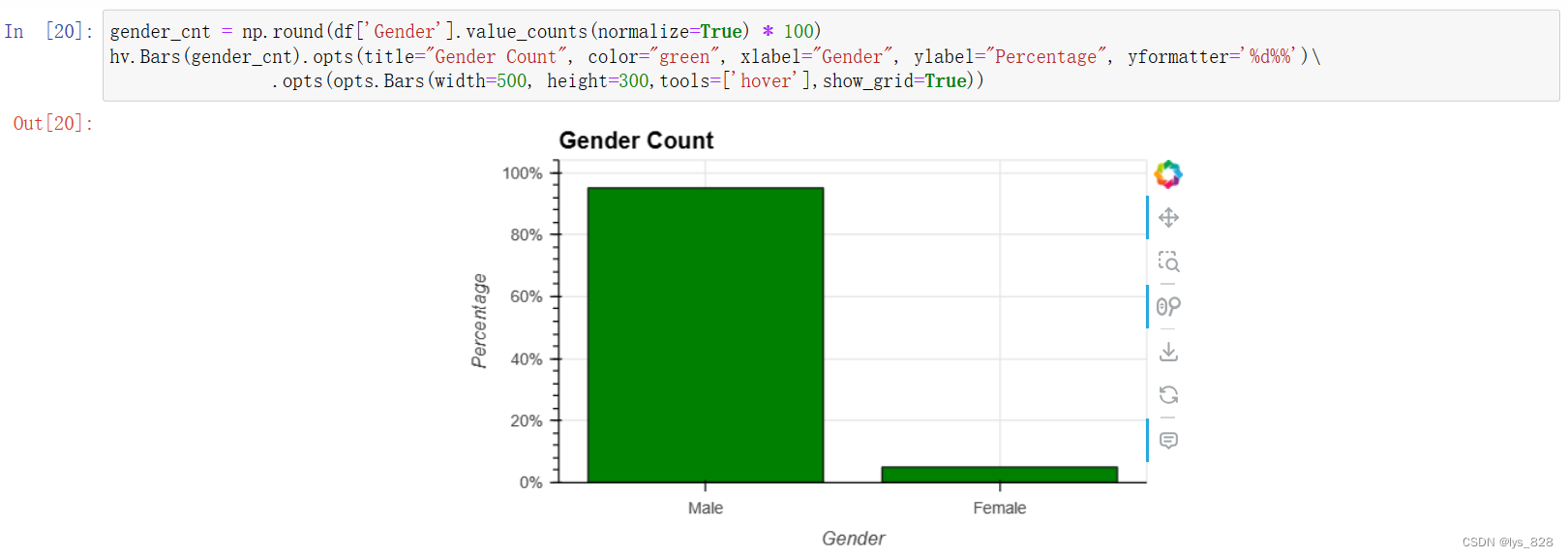
5.1.5 性别特征
gender_cnt = np.round(df['Gender'].value_counts(normalize=True) * 100)
hv.Bars(gender_cnt).opts(title="Gender Count", color="green", xlabel="Gender", ylabel="Percentage", yformatter='%d%%')\
.opts(opts.Bars(width=500, height=300,tools=['hover'],show_grid=True))
输出结果如下(作为该行业的一个特点,男性的比例占绝大多数。)
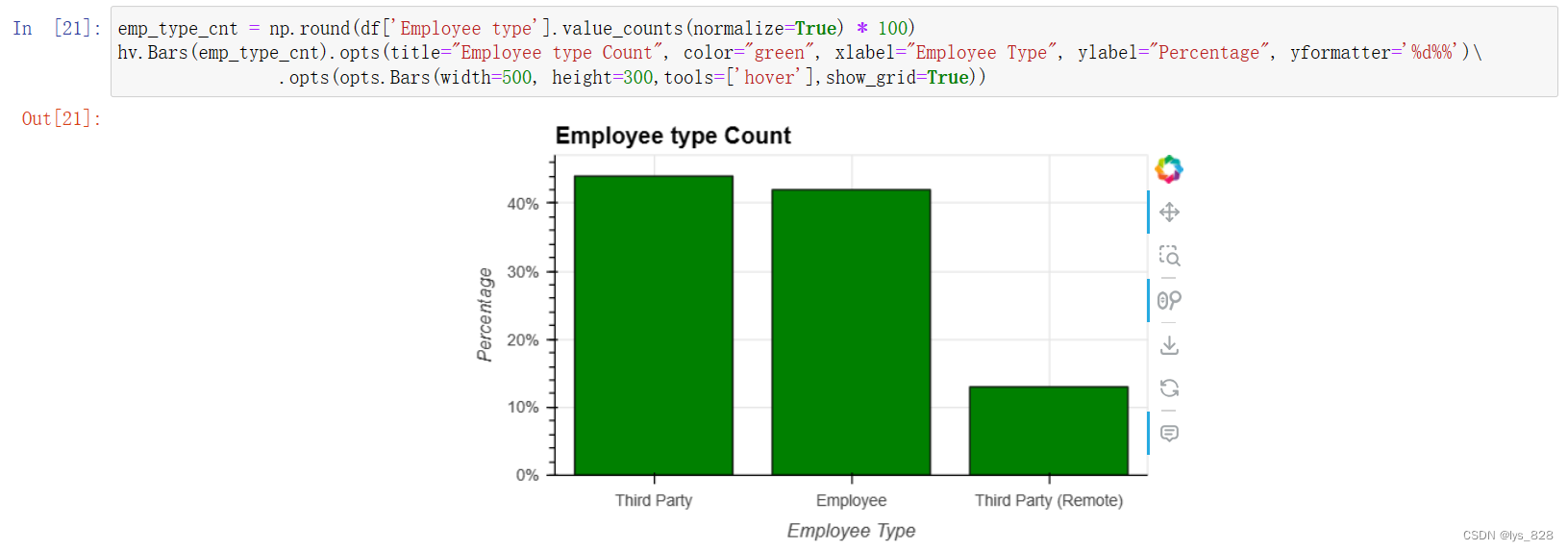
5.1.6 用工形式
emp_type_cnt = np.round(df['Employee type'].value_counts(normalize=True) * 100)
hv.Bars(emp_type_cnt).opts(title="Employee type Count", color="green", xlabel="Employee Type", ylabel="Percentage", yformatter='%d%%')\
.opts(opts.Bars(width=500, height=300,tools=['hover'],show_grid=True))
输出结果如下(说明性别或行业部门的雇员制度存在差异。)
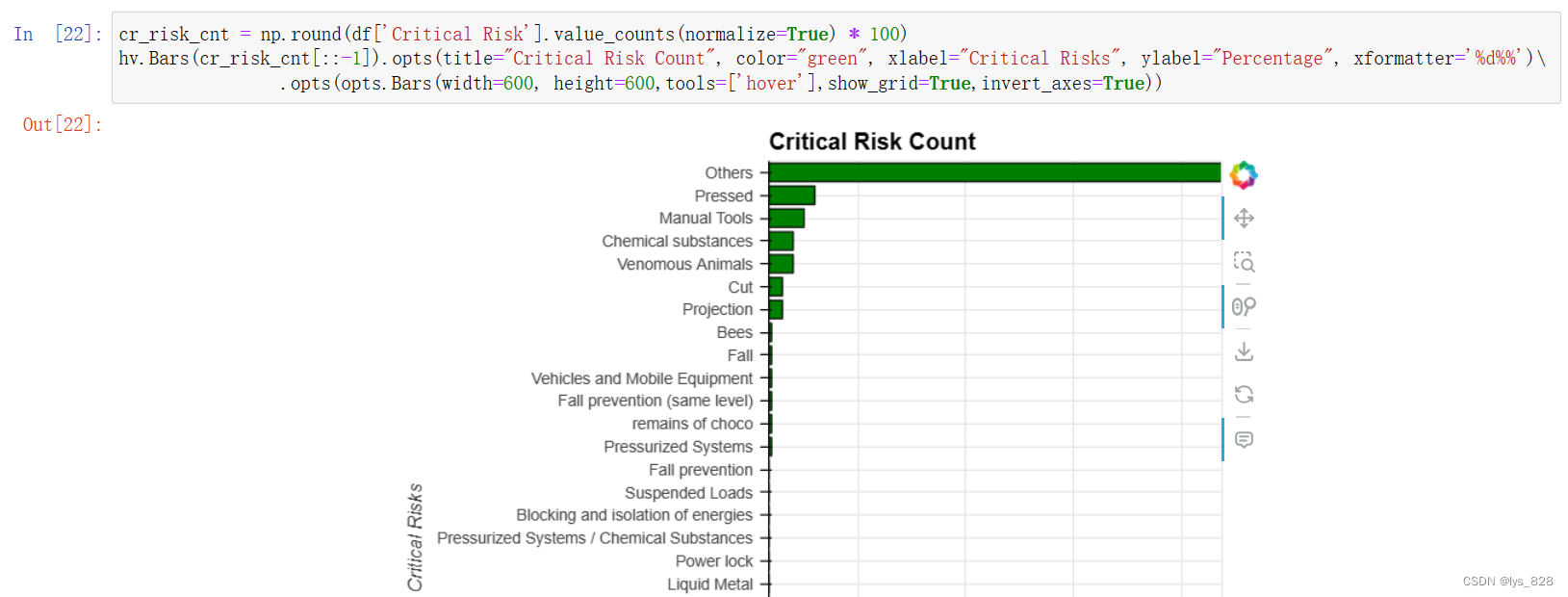
5.1.7 关键风险
cr_risk_cnt = np.round(df['Critical Risk'].value_counts(normalize=True) * 100)
hv.Bars(cr_risk_cnt[::-1]).opts(title="Critical Risk Count", color="green", xlabel="Critical Risks", ylabel="Percentage", xformatter='%d%%')\
.opts(opts.Bars(width=600, height=600,tools=['hover'],show_grid=True,invert_axes=True))
输出结果如下(由于大部分关键风险被归类为 “其他”,人们认为有太多的风险需要精确分类。还有人认为,分析风险和事故原因需要花费大量时间。),输出图形只截取部分。
5.1.8 时间特征
year_cnt = np.round(df['Year'].value_counts(normalize=True,sort=False) * 100)
y = hv.Bars(year_cnt).opts(title="Year Count", color="green", xlabel="Years")
month_cnt = np.round(df['Month'].value_counts(normalize=True,sort=False) * 100)
m = hv.Bars(month_cnt).opts(title="Month Count", color="skyblue", xlabel="Months") * hv.Curve(month_cnt).opts(color='red', line_width=3)
day_cnt = np.round(df['Day'].value_counts(normalize=True,sort=False) * 100)
d = hv.Bars(day_cnt).opts(title="Day Count", color="skyblue", xlabel="Days") * hv.Curve(day_cnt).opts(color='red', line_width=3)
weekday_cnt = pd.DataFrame(np.round(df['Weekday'].value_counts(normalize=True,sort=False) * 100))
weekday_cnt['week_num'] = [['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'].index(i) for i in weekday_cnt.index]
weekday_cnt.sort_values('week_num', inplace=True)
w = hv.Bars((weekday_cnt.index, weekday_cnt.proportion)).opts(title="Weekday Count", color="green", xlabel="Weekdays") * hv.Curve(weekday_cnt['proportion']).opts(color='red', line_width=3)
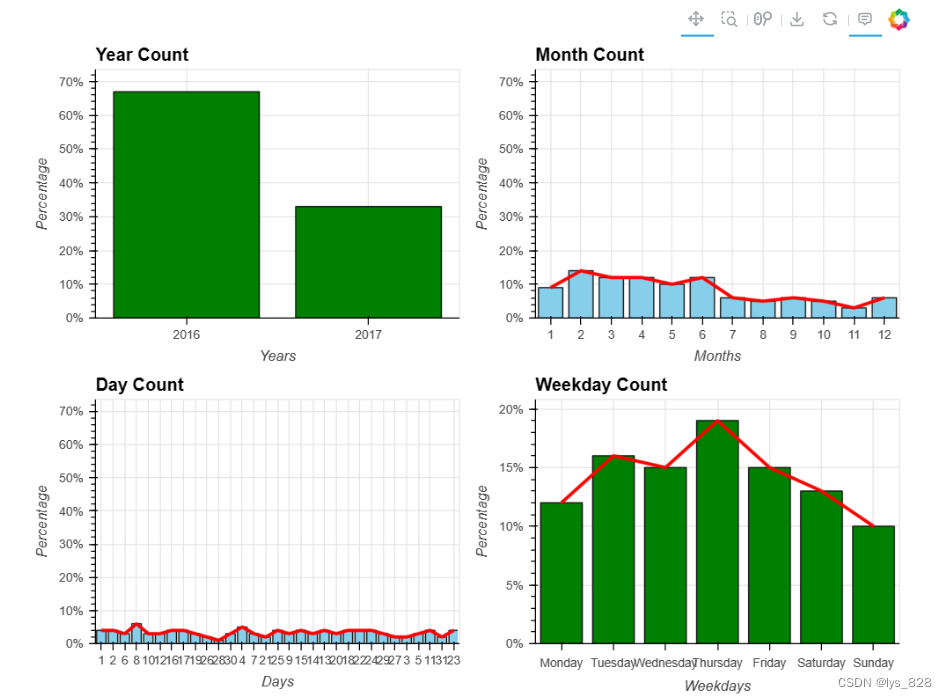
(y + m + d + w).opts(opts.Bars(width=400, height=300,tools=['hover'],show_grid=True, ylabel="Percentage", yformatter='%d%%')).cols(2)
输出结果如下(事故数量似乎在年/月下旬有所减少。事故数量在周中增加,从周中开始下降。),这是一个模板,后续直接可以使用。
季节特征
season_cnt = pd.DataFrame(np.round(df['Season'].value_counts(normalize=True,sort=False) * 100).reset_index())
season_cnt['season_order'] = season_cnt['Season'].apply(lambda x: ['Spring','Summer','Autumn','Winter'].index(x))
season_cnt.sort_values('season_order', inplace=True)
season_cnt.index = season_cnt['Season']
season_cnt.drop(['Season','season_order'], axis=1, inplace=True)
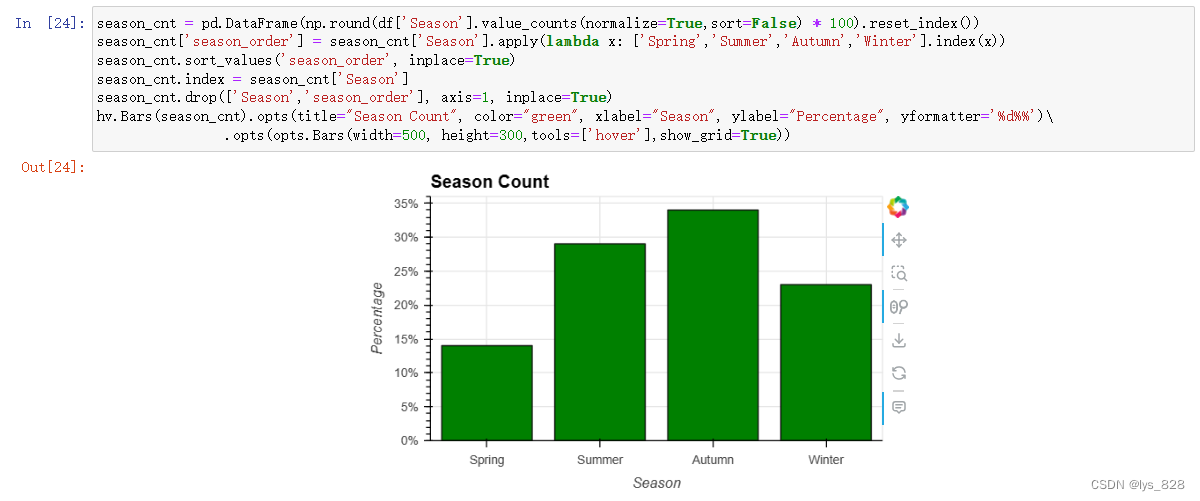
hv.Bars(season_cnt).opts(title="Season Count", color="green", xlabel="Season", ylabel="Percentage", yformatter='%d%%')\
.opts(opts.Bars(width=500, height=300,tools=['hover'],show_grid=True))
输出结果如下(事故数量在夏季和秋季有所增加。人们认为,事故的发生与气候(尤其是温度)有关。)
5.2 多变量分析
5.2.1 国家与行业
f = lambda x : np.round(x/x.sum() * 100)
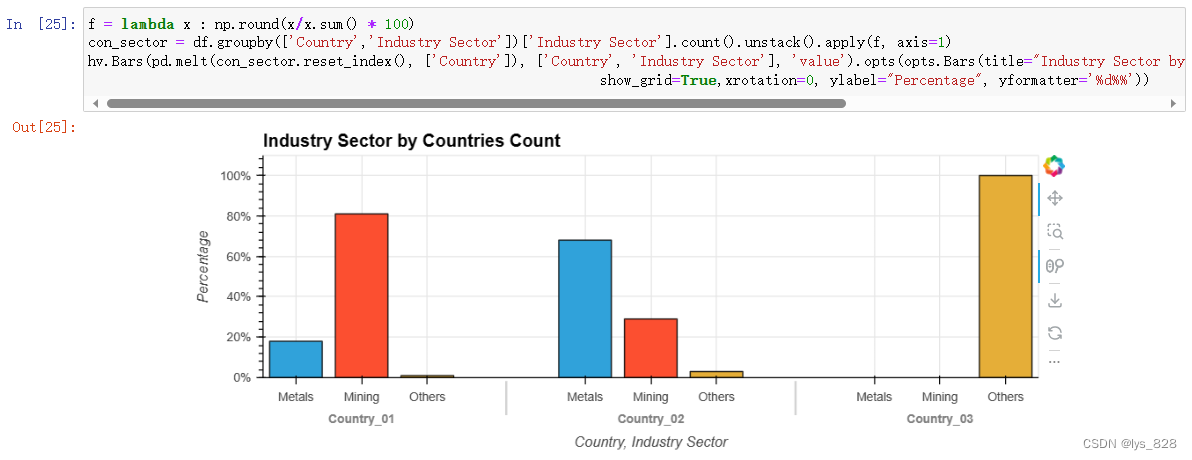
con_sector = df.groupby(['Country','Industry Sector'])['Industry Sector'].count().unstack().apply(f, axis=1)
hv.Bars(pd.melt(con_sector.reset_index(), ['Country']), ['Country', 'Industry Sector'], 'value').opts(opts.Bars(title="Industry Sector by Countries Count", width=800, height=300,tools=['hover'],\
show_grid=True,xrotation=0, ylabel="Percentage", yformatter='%d%%'))
输出结果如下
5.2.2 用工形式和性别
f = lambda x : np.round(x/x.sum() * 100)
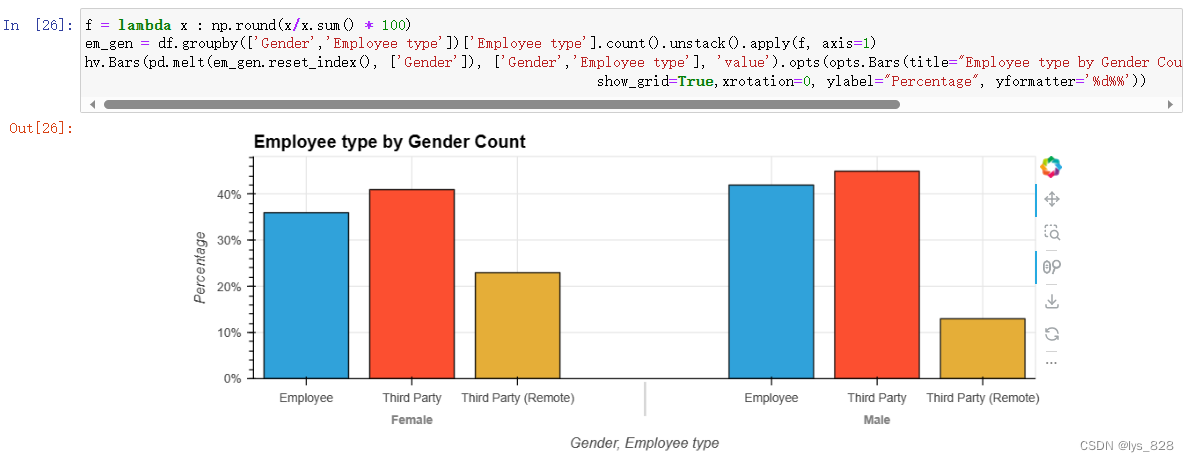
em_gen = df.groupby(['Gender','Employee type'])['Employee type'].count().unstack().apply(f, axis=1)
hv.Bars(pd.melt(em_gen.reset_index(), ['Gender']), ['Gender','Employee type'], 'value').opts(opts.Bars(title="Employee type by Gender Count", width=800, height=300,tools=['hover'],\
show_grid=True,xrotation=0, ylabel="Percentage", yformatter='%d%%'))
输出结果如下(不同性别的员工类型比例没有差异。女性使用第三方(远程)的比例略高于男性。据认为,这是因为男性有更多的现场工作,而女性通常在远离相对安全的地点工作。)
5.2.3 性别与行业
f = lambda x : np.round(x/x.sum() * 100)
em_gen = df.groupby(['Gender','Industry Sector'])['Industry Sector'].count().unstack().apply(f, axis=1)
hv.Bars(pd.melt(em_gen.reset_index(), ['Gender']), ['Gender','Industry Sector'], 'value').opts(opts.Bars(title="Industry Sector by Gender Count", width=800, height=300,tools=['hover'],\
show_grid=True,xrotation=0, ylabel="Percentage", yformatter='%d%%'))
输出结果如下(男性和女性之间的差异主要体现在金属和采矿方面。与上述员工类型相同,我们认为这是由于行业部门的安全水平不同所致。)
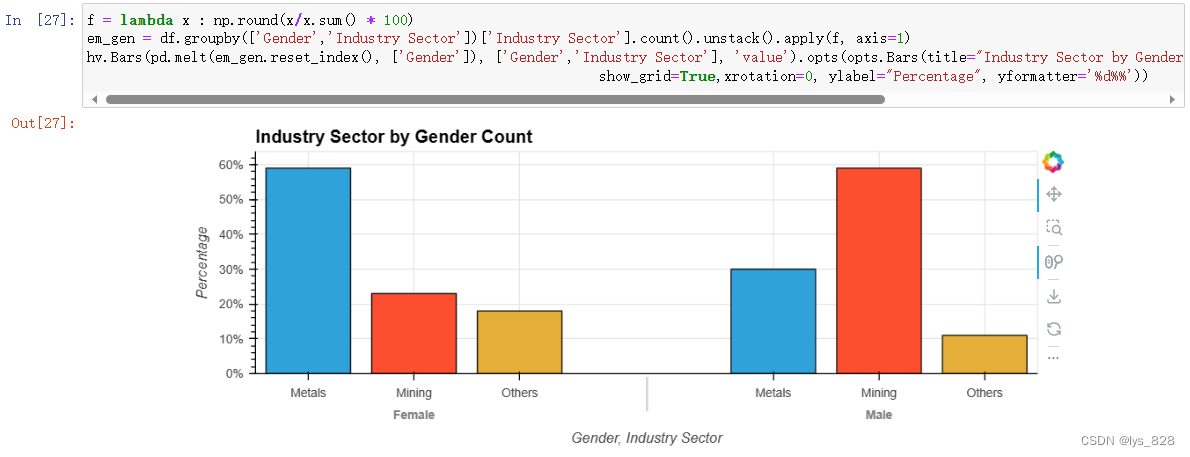
5.2.4 事故等级与性别
f = lambda x : np.round(x/x.sum() * 100)
ac_gen = df.groupby(['Gender','Accident Level'])['Accident Level'].count().unstack().apply(f, axis=1)
ac = hv.Bars(pd.melt(ac_gen.reset_index(), ['Gender']), ['Gender','Accident Level'], 'value').opts(opts.Bars(title="Accident Level by Gender Count"))
pot_ac_gen = df.groupby(['Gender','Potential Accident Level'])['Potential Accident Level'].count().unstack().apply(f, axis=1)
pot_ac = hv.Bars(pd.melt(pot_ac_gen.reset_index(), ['Gender']), ['Gender','Potential Accident Level'], 'value').opts(opts.Bars(title="Potential Accident Level by Gender Count"))
(ac + pot_ac).opts(opts.Bars(width=400, height=300,tools=['hover'],show_grid=True,xrotation=0, ylabel="Percentage", yformatter='%d%%'))
输出结果如下(从事故级别来看,一般事故级别的轻微风险很多,但潜在事故级别的严重风险也不少。 可以说,许多潜在的事故被忽视了,而潜在的高风险事故是可能发生的。在性别方面,总体趋势相同,但男性的事故水平高于女性。 与上述讨论相同,我们认为这是由于各行业部门的安全水平不同造成的。)
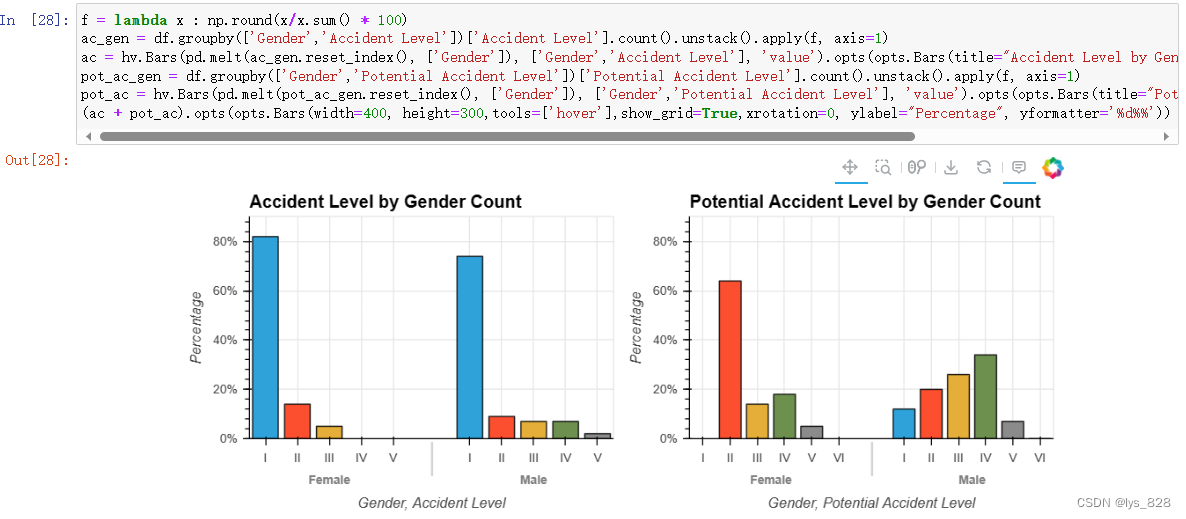
5.2.5 用工形式和事故等级
f = lambda x : np.round(x/x.sum() * 100)
ac_em = df.groupby(['Employee type','Accident Level'])['Accident Level'].count().unstack().apply(f, axis=1)
ac = hv.Bars(pd.melt(ac_em.reset_index(), ['Employee type']), ['Employee type','Accident Level'], 'value').opts(opts.Bars(title="Accident Level by Employee type Count"))
pot_ac_em = df.groupby(['Employee type','Potential Accident Level'])['Potential Accident Level'].count().unstack().apply(f, axis=1)
pot_ac = hv.Bars(pd.melt(pot_ac_em.reset_index(), ['Employee type']), ['Employee type','Potential Accident Level'], 'value').opts(opts.Bars(title="Potential Accident Level by Employee type Count"))
(ac + pot_ac).opts(opts.Bars(width=400, height=300,tools=['hover'],show_grid=True,xrotation=0, ylabel="Percentage", yformatter='%d%%',fontsize={'title':9}))
输出结果如下(在两种事故等级中,事故等级低时雇员的发生率较高,但事故等级高时第三方的发生率似乎略高。)
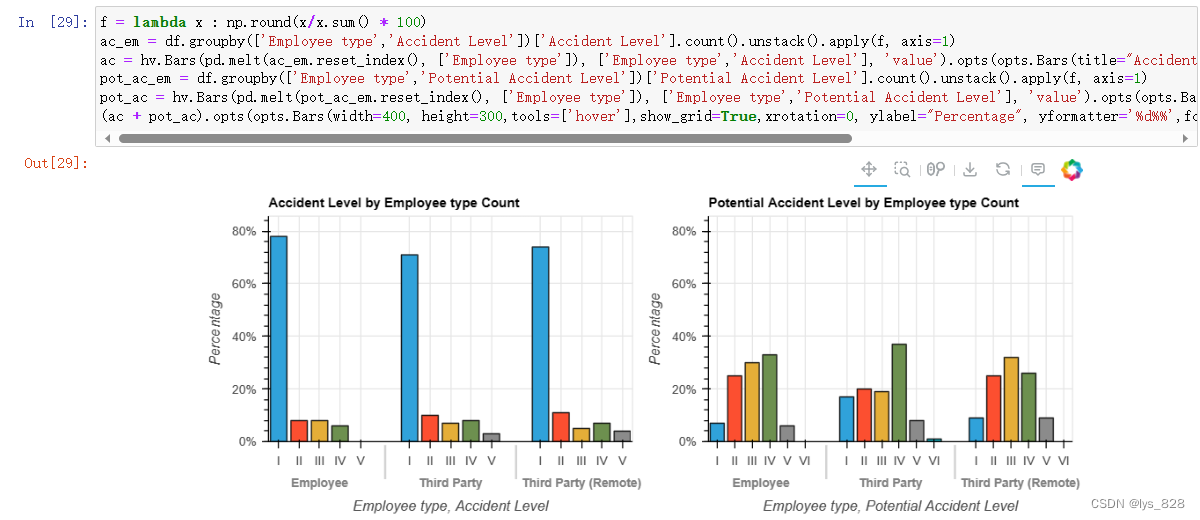
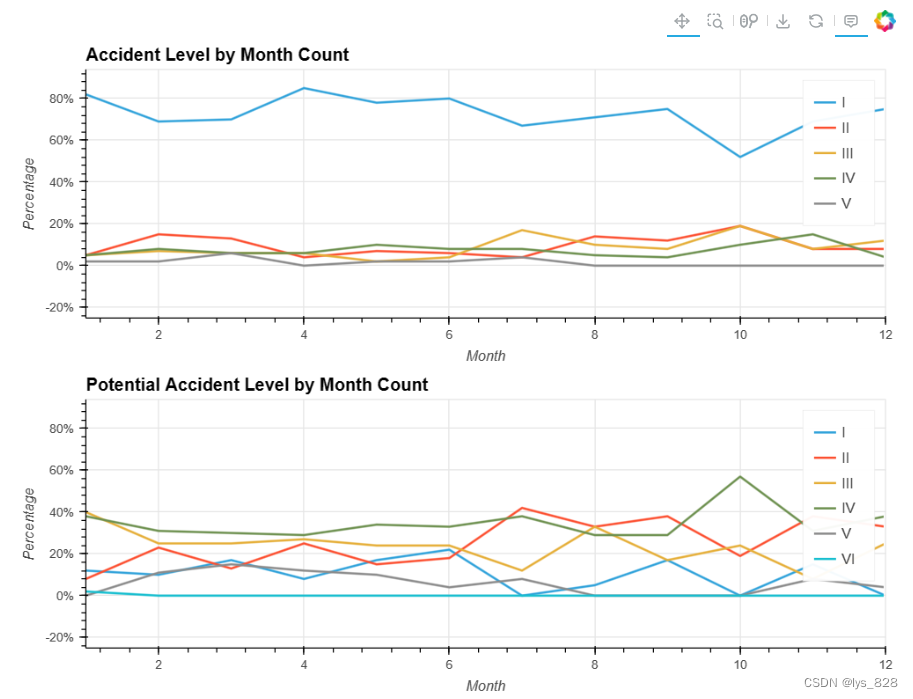
5.2.6 事故类别与月份
f = lambda x : np.round(x/x.sum() * 100)
ac_mo = df.groupby(['Month','Accident Level'])['Accident Level'].count().unstack().apply(f, axis=1).fillna(0)
ac = hv.Curve(ac_mo['I'], label='I') * hv.Curve(ac_mo['II'], label='II') * hv.Curve(ac_mo['III'], label='III') * hv.Curve(ac_mo['IV'], label='IV') * hv.Curve(ac_mo['V'], label='V')\
.opts(opts.Curve(title="Accident Level by Month Count"))
pot_ac_mo = df.groupby(['Month','Potential Accident Level'])['Potential Accident Level'].count().unstack().apply(f, axis=1).fillna(0)
pot_ac = hv.Curve(pot_ac_mo['I'], label='I') * hv.Curve(pot_ac_mo['II'], label='II') * hv.Curve(pot_ac_mo['III'], label='III') * hv.Curve(pot_ac_mo['IV'], label='IV')\
* hv.Curve(pot_ac_mo['V'], label='V') * hv.Curve(pot_ac_mo['VI'], label='VI').opts(opts.Curve(title="Potential Accident Level by Month Count"))
(ac+pot_ac).opts(opts.Curve(width=800, height=300,tools=['hover'],show_grid=True, ylabel="Percentage", yformatter='%d%%')).cols(1)
输出结果如下(全年两起事故水平均呈现非重大事故有所下降的趋势,但重大事故变化不大,部分事故在下半年略有上升。上述事实似乎与员工的技能水平有关,他们的经验虽然可以减少小错误,但有时一不小心就会犯下严重错误。)
5.2.7 周与事故等级
f = lambda x : np.round(x/x.sum() * 100)
ac_weekday = df.groupby(['Weekday','Accident Level'])['Accident Level'].count().unstack().apply(f, axis=1).fillna(0)
ac_weekday['week_num'] = [['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'].index(i) for i in ac_weekday.index]
ac_weekday.sort_values('week_num', inplace=True)
ac_weekday.drop('week_num', axis=1, inplace=True)
ac = hv.Curve(ac_weekday['I'], label='I') * hv.Curve(ac_weekday['II'], label='II') * hv.Curve(ac_weekday['III'], label='III') * hv.Curve(ac_weekday['IV'], label='IV') * hv.Curve(ac_weekday['V'], label='V')\
.opts(opts.Curve(title="Accident Level by Weekday Count"))
pot_ac_weekday = df.groupby(['Weekday','Potential Accident Level'])['Potential Accident Level'].count().unstack().apply(f, axis=0).fillna(0)
pot_ac_weekday['week_num'] = [['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'].index(i) for i in pot_ac_weekday.index]
pot_ac_weekday.sort_values('week_num', inplace=True)
pot_ac_weekday.drop('week_num', axis=1, inplace=True)
pot_ac = hv.Curve(pot_ac_weekday['I'], label='I') * hv.Curve(pot_ac_weekday['II'], label='II') * hv.Curve(pot_ac_weekday['III'], label='III') * hv.Curve(pot_ac_weekday['IV'], label='IV')\
* hv.Curve(pot_ac_weekday['V'], label='V') * hv.Curve(pot_ac_weekday['VI'], label='VI').opts(opts.Curve(title="Potential Accident Level by Weekday Count"))
(ac+pot_ac).opts(opts.Curve(width=800, height=300,tools=['hover'],show_grid=True, ylabel="Percentage", yformatter='%d%%')).cols(1)
输出结果如下(两者的两个事故的水平被认为不严重的水平下降的第一个和最后一个星期,但严重的水平没有多大变化。可以说,员工的经验对工作可以减少小的错误。)
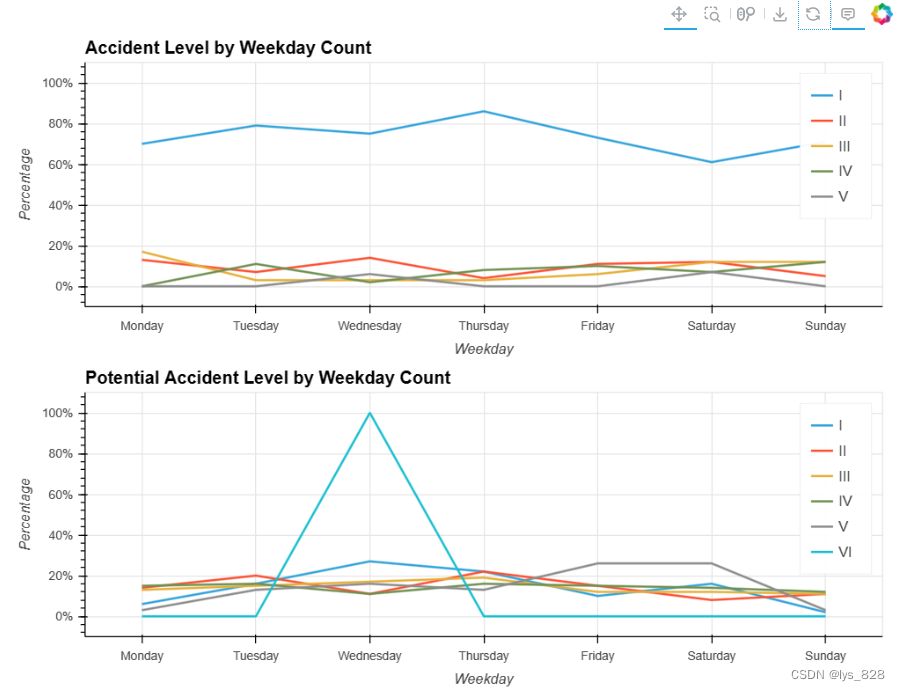
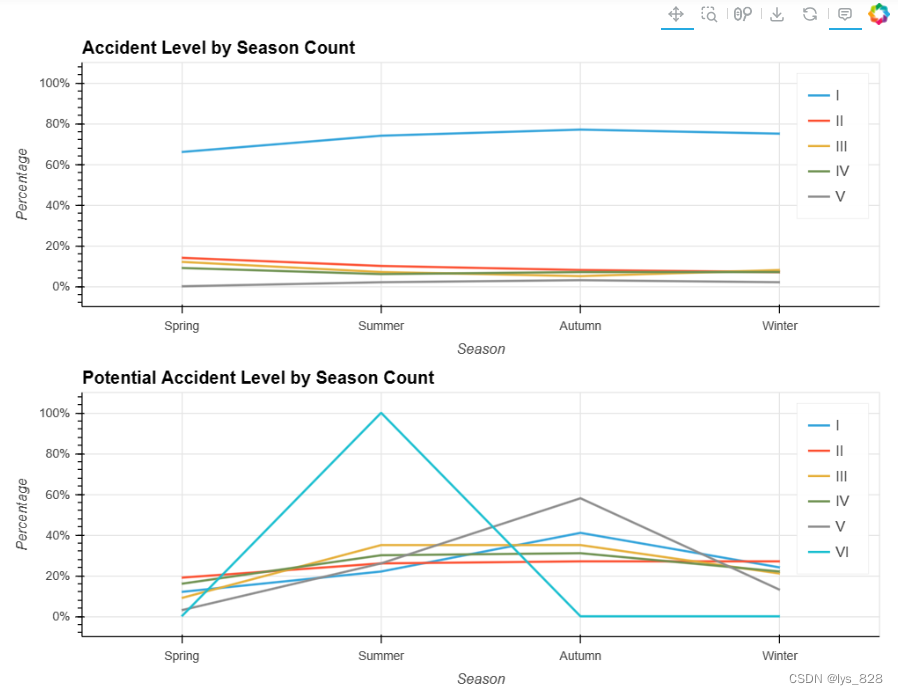
5.2.8 季节与事故等级
f = lambda x : np.round(x/x.sum() * 100)
ac_season = df.groupby(['Season','Accident Level'])['Accident Level'].count().unstack().apply(f, axis=1).fillna(0)
ac_season['season_num'] = [['Spring', 'Summer', 'Autumn', 'Winter'].index(i) for i in ac_season.index]
ac_season.sort_values('season_num', inplace=True)
ac_season.drop('season_num', axis=1, inplace=True)
ac = hv.Curve(ac_season['I'], label='I') * hv.Curve(ac_season['II'], label='II') * hv.Curve(ac_season['III'], label='III') * hv.Curve(ac_season['IV'], label='IV') * hv.Curve(ac_season['V'], label='V')\
.opts(opts.Curve(title="Accident Level by Season Count"))
pot_ac_season = df.groupby(['Season','Potential Accident Level'])['Potential Accident Level'].count().unstack().apply(f, axis=0).fillna(0)
pot_ac_season['season_num'] = [['Spring', 'Summer', 'Autumn', 'Winter'].index(i) for i in pot_ac_season.index]
pot_ac_season.sort_values('season_num', inplace=True)
pot_ac_season.drop('season_num', axis=1, inplace=True)
pot_ac = hv.Curve(pot_ac_season['I'], label='I') * hv.Curve(pot_ac_season['II'], label='II') * hv.Curve(pot_ac_season['III'], label='III') * hv.Curve(pot_ac_season['IV'], label='IV')\
* hv.Curve(pot_ac_season['V'], label='V') * hv.Curve(pot_ac_season['VI'], label='VI').opts(opts.Curve(title="Potential Accident Level by Season Count"))
(ac+pot_ac).opts(opts.Curve(width=800, height=300,tools=['hover'],show_grid=True, ylabel="Percentage", yformatter='%d%%')).cols(1)
输出结果如下(与各月事故等级一样,全年两次事故等级均呈现非重大事故等级下降的趋势,但重大事故等级变化不大,部分事故等级在下半年略有上升)
6 NLP分析
对事故的描述对于了解事故原因很重要,因此我们需要发现表明事故发生时情况的特征词或短语。
在多种条件下计算 ngram 的函数
def ngram_func(ngram, trg='', trg_value=''):
#trg_value is list-object
if (trg == '') or (trg_value == ''):
string_filterd = df['Description_processed'].sum().split()
else:
string_filterd = df[df[trg].isin(trg_value)]['Description_processed'].sum().split()
dic = nltk.FreqDist(nltk.ngrams(string_filterd, ngram)).most_common(30)
ngram_df = pd.DataFrame(dic, columns=['ngram','count'])
ngram_df.index = [' '.join(i) for i in ngram_df.ngram]
ngram_df.drop('ngram',axis=1, inplace=True)
return ngram_df
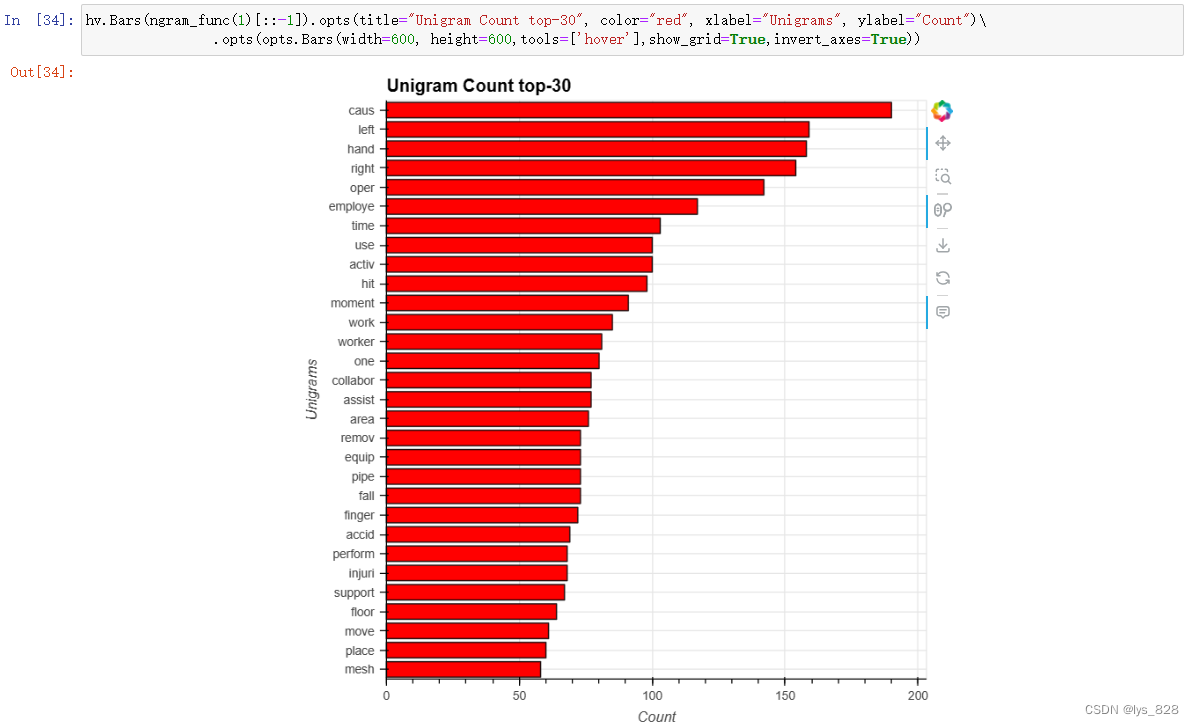
6.1 单-gram
hv.Bars(ngram_func(1)[::-1]).opts(title="Unigram Count top-30", color="red", xlabel="Unigrams", ylabel="Count")\
.opts(opts.Bars(width=600, height=600,tools=['hover'],show_grid=True,invert_axes=True))
输出结果如下(有几个词与手有关。例如左手、右手、手指。此外,还有几个词与某物的运动有关。例如击打、移除、掉落和移动。)
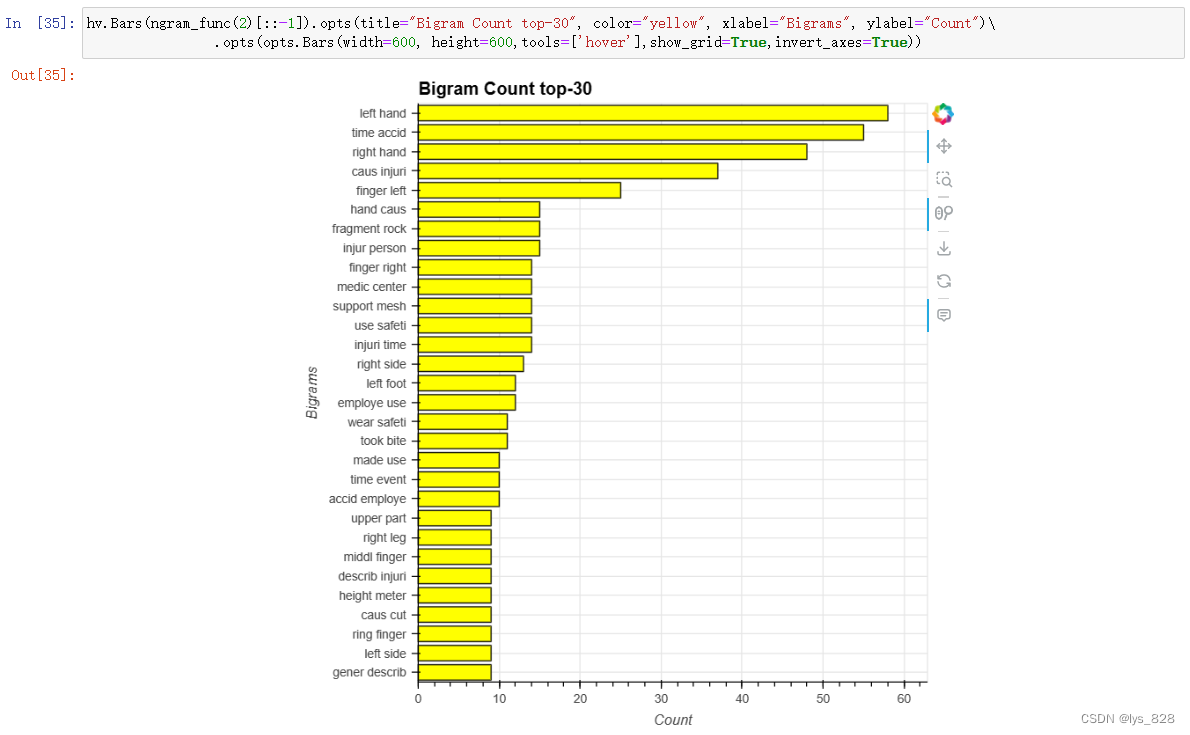
6.2 双-gram
hv.Bars(ngram_func(2)[::-1]).opts(title="Bigram Count top-30", color="yellow", xlabel="Bigrams", ylabel="Count")\
.opts(opts.Bars(width=600, height=600,tools=['hover'],show_grid=True,invert_axes=True))
输出结果如下(与手有关的短语有很多。例如左手、右手、左手指、右手指、中指和无名指。还有一些与身体其他部位相关的短语。例如左脚和右脚。)
6.3 三-gram
hv.Bars(ngram_func(3)[::-1]).opts(title="Trigram Count top-30", color="blue", xlabel="Trigrams", ylabel="Count")\
.opts(opts.Bars(width=600, height=600,tools=['hover'],show_grid=True,invert_axes=True))
输出结果如下(与 Unigram 和 Bigram 一样,也有许多短语与手或其他身体部位有关,但具体程度似乎有所增加。例如,one hand glove(一只手的手套)、left arm uniform(左臂制服)和 wear safeti uniform(穿安全制服))
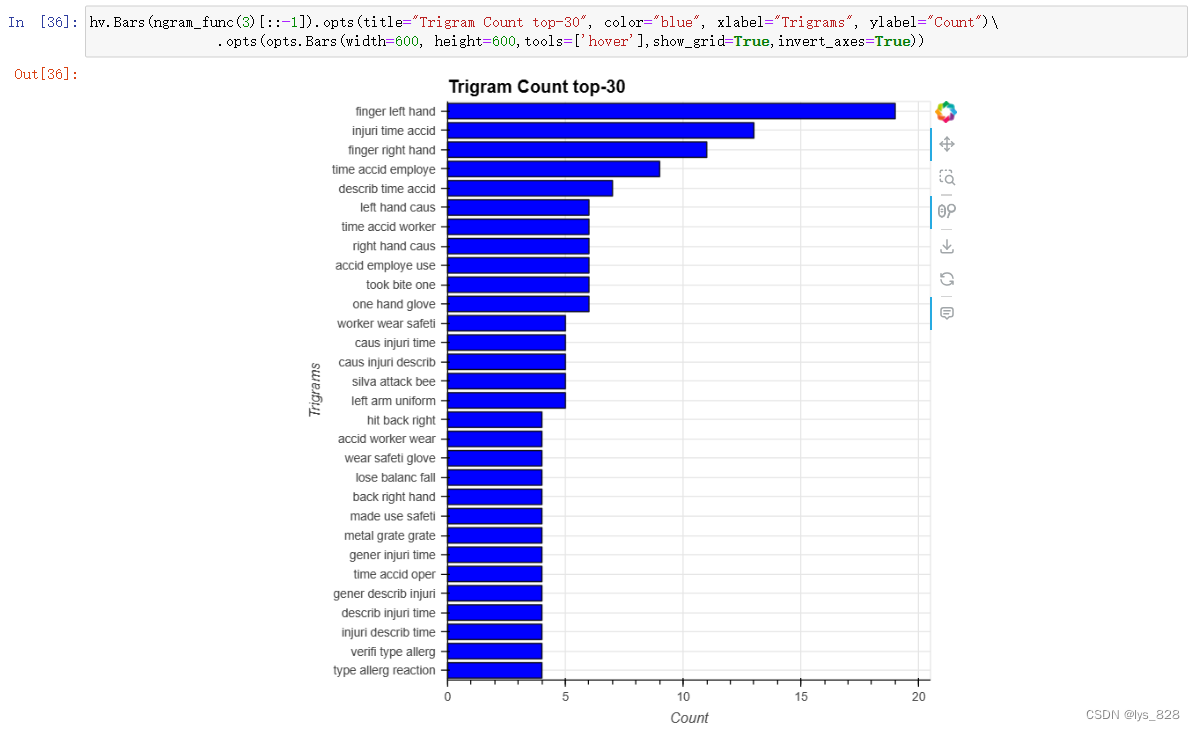
6.4 性别与N-gram
uni_ma=hv.Bars(ngram_func(1, 'Gender', ['Male'])[0:15][::-1]).opts(title="Unigram with Male", color="red", xlabel="Unigrams", ylabel="Count")
uni_fe=hv.Bars(ngram_func(1, 'Gender', ['Female'])[0:15][::-1]).opts(title="Unigram with Female", color="red", xlabel="Unigrams", ylabel="Count")
bi_ma=hv.Bars(ngram_func(2, 'Gender', ['Male'])[0:15][::-1]).opts(title="Bigram with Male", color="yellow", xlabel="Bigrams", ylabel="Count")
bi_fe=hv.Bars(ngram_func(2, 'Gender', ['Female'])[0:15][::-1]).opts(title="Bigram with Female", color="yellow", xlabel="Bigrams", ylabel="Count")
tri_ma=hv.Bars(ngram_func(3, 'Gender', ['Male'])[0:15][::-1]).opts(title="Trigram with Male", color="blue", xlabel="Trigrams", ylabel="Count")
tri_fe=hv.Bars(ngram_func(3, 'Gender', ['Female'])[0:15][::-1]).opts(title="Trigram with Female", color="blue", xlabel="Trigrams", ylabel="Count")
(uni_ma + uni_fe + bi_ma + bi_fe + tri_ma + tri_fe).opts(opts.Bars(width=400, height=300,tools=['hover'],show_grid=True,invert_axes=True, shared_axes=False)).opts(shared_axes=False).cols(2)
输出结果如下
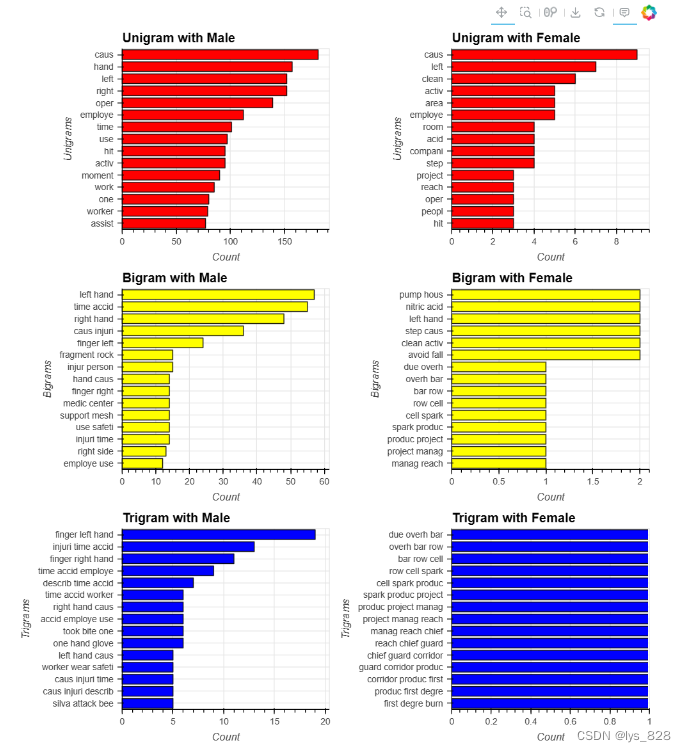
6.5 事故等级与N-gram
将事故等级分为低事故等级(I、II)和高事故等级(III、IV、V)两部分。
uni_ac_lo=hv.Bars(ngram_func(1, 'Accident Level', ['I','II'])[0:15][::-1]).opts(title="Unigram with High Accident Level", color="red", xlabel="Unigrams", ylabel="Count")
uni_ac_hi=hv.Bars(ngram_func(1, 'Accident Level', ['III','IV','V'])[0:15][::-1]).opts(title="Unigram with Low Accident Level", color="red", xlabel="Unigrams", ylabel="Count")
bi_ac_lo=hv.Bars(ngram_func(2, 'Accident Level', ['I','II'])[0:15][::-1]).opts(title="Bigram with High Accident Level", color="yellow", xlabel="Bigrams", ylabel="Count")
bi_ac_hi=hv.Bars(ngram_func(2, 'Accident Level', ['III','IV','V'])[0:15][::-1]).opts(title="Bigram with Low Accident Level", color="yellow", xlabel="Bigrams", ylabel="Count")
tri_ac_lo=hv.Bars(ngram_func(3, 'Accident Level', ['I','II'])[0:15][::-1]).opts(title="Trigram with High Accident Level", color="blue", xlabel="Trigrams", ylabel="Count")
tri_ac_hi=hv.Bars(ngram_func(3, 'Accident Level', ['III','IV','V'])[0:15][::-1]).opts(title="Trigram with Low Accident Level", color="blue", xlabel="Trigrams", ylabel="Count")
(uni_ac_lo + uni_ac_hi + bi_ac_lo + bi_ac_hi + tri_ac_lo + tri_ac_hi).opts(opts.Bars(width=400, height=300,tools=['hover'],show_grid=True,invert_axes=True, shared_axes=False)).opts(shared_axes=False).cols(2)
输出结果如下
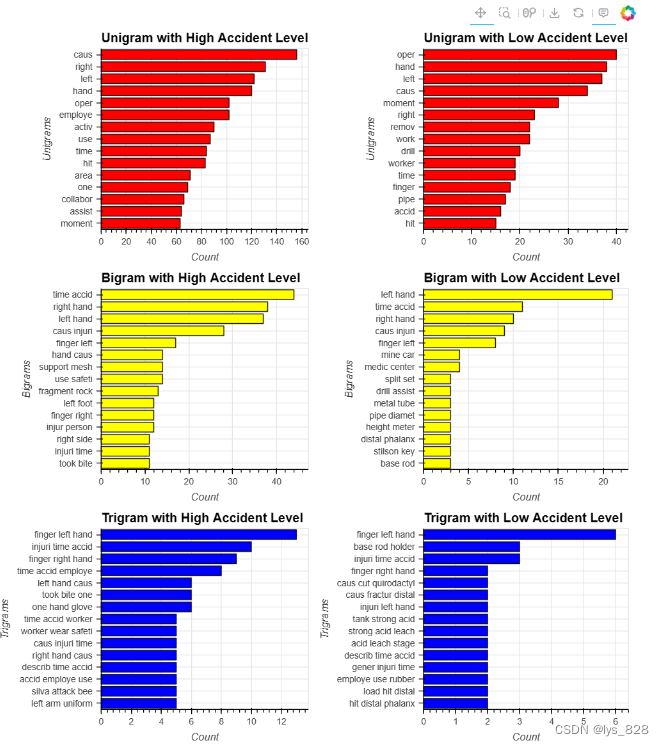
6.6 行业与N-gram
uni_mine=hv.Bars(ngram_func(1, 'Industry Sector', ['Mining'])[0:15][::-1]).opts(title="Unigram with Mining Sector", color="red", xlabel="Unigrams", ylabel="Count")
uni_metal=hv.Bars(ngram_func(1, 'Industry Sector', ['Metals'])[0:15][::-1]).opts(title="Unigram with Metal Sector", color="red", xlabel="Unigrams", ylabel="Count")
uni_others=hv.Bars(ngram_func(1, 'Industry Sector', ['Others'])[0:15][::-1]).opts(title="Unigram with Other Sector", color="red", xlabel="Unigrams", ylabel="Count")
bi_mine=hv.Bars(ngram_func(2, 'Industry Sector', ['Mining'])[0:15][::-1]).opts(title="Bigram with Mining Sector", color="yellow", xlabel="Bigrams", ylabel="Count")
bi_metal=hv.Bars(ngram_func(2, 'Industry Sector', ['Metals'])[0:15][::-1]).opts(title="Bigram with Metal Sector", color="yellow", xlabel="Bigrams", ylabel="Count")
bi_others=hv.Bars(ngram_func(2, 'Industry Sector', ['Others'])[0:15][::-1]).opts(title="Bigram with Other Sector", color="yellow", xlabel="Bigrams", ylabel="Count")
tri_mine=hv.Bars(ngram_func(3, 'Industry Sector', ['Mining'])[0:15][::-1]).opts(title="Trigram with Mining Sector", color="blue", xlabel="Trigrams", ylabel="Count")
tri_metal=hv.Bars(ngram_func(3, 'Industry Sector', ['Metals'])[0:15][::-1]).opts(title="Trigram with Metal Sector", color="blue", xlabel="Trigrams", ylabel="Count")
tri_others=hv.Bars(ngram_func(3, 'Industry Sector', ['Others'])[0:15][::-1]).opts(title="Trigram with Other Sector", color="blue", xlabel="Trigrams", ylabel="Count")
(uni_mine + uni_metal + uni_others + bi_mine + bi_metal + bi_others + tri_mine + tri_metal + tri_others)\
.opts(opts.Bars(width=265, height=300,tools=['hover'],show_grid=True,invert_axes=True, shared_axes=False,fontsize={'title':6.5,'labels':7,'yticks':8.5})).opts(shared_axes=False).cols(3)
输出结果如下
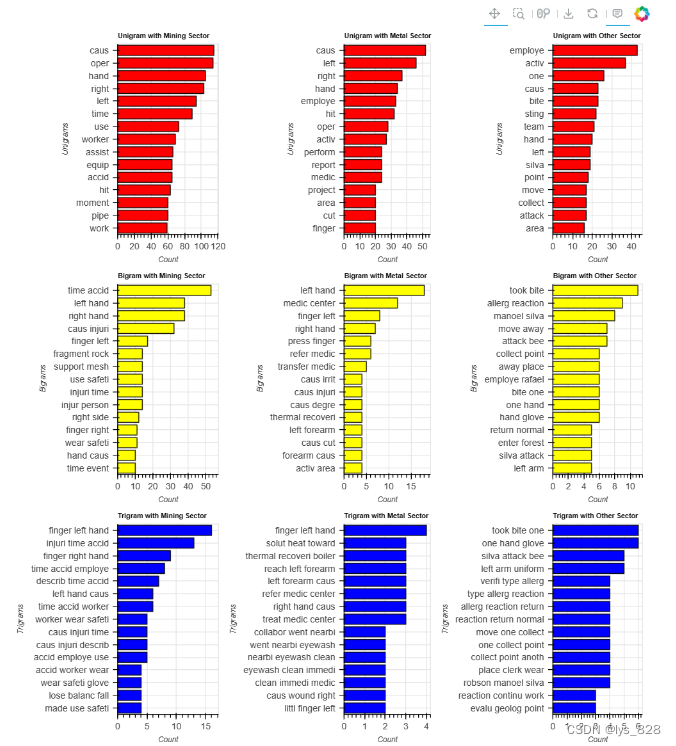
6.7 用工类型与N-gram
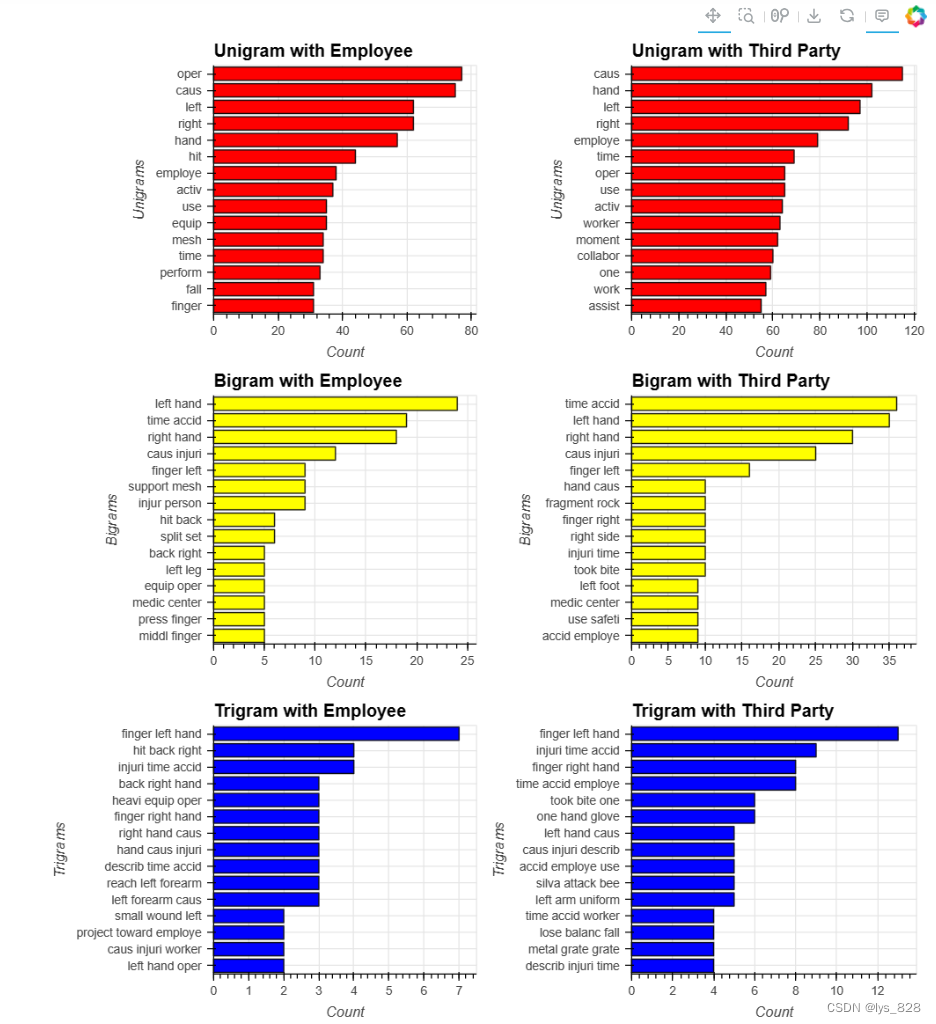
uni_emp=hv.Bars(ngram_func(1, 'Employee type', ['Employee'])[0:15][::-1]).opts(title="Unigram with Employee", color="red", xlabel="Unigrams", ylabel="Count")
uni_third=hv.Bars(ngram_func(1, 'Employee type', ['Third Party','Third Party (Remote)'])[0:15][::-1]).opts(title="Unigram with Third Party", color="red", xlabel="Unigrams", ylabel="Count")
bi_emp=hv.Bars(ngram_func(2, 'Employee type', ['Employee'])[0:15][::-1]).opts(title="Bigram with Employee", color="yellow", xlabel="Bigrams", ylabel="Count")
bi_third=hv.Bars(ngram_func(2, 'Employee type', ['Third Party','Third Party (Remote)'])[0:15][::-1]).opts(title="Bigram with Third Party", color="yellow", xlabel="Bigrams", ylabel="Count")
tri_emp=hv.Bars(ngram_func(3, 'Employee type', ['Employee'])[0:15][::-1]).opts(title="Trigram with Employee", color="blue", xlabel="Trigrams", ylabel="Count")
tri_third=hv.Bars(ngram_func(3, 'Employee type', ['Third Party','Third Party (Remote)'])[0:15][::-1]).opts(title="Trigram with Third Party", color="blue", xlabel="Trigrams", ylabel="Count")
(uni_emp + uni_third+ bi_emp + bi_third + tri_emp + tri_third).opts(opts.Bars(width=400, height=300,tools=['hover'],show_grid=True,invert_axes=True, shared_axes=False)).opts(shared_axes=False).cols(2)
输出结果如下
6.8 词云图
wordcloud = WordCloud(width = 1500, height = 800, random_state=0, background_color='black', colormap='rainbow', \
min_font_size=5, max_words=300, collocations=False, min_word_length=3, stopwords = STOPWORDS).generate(" ".join(df['Description_processed'].values))
plt.figure(figsize=(15,10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
输出结果如下(与上面的Ngram分析一样,有很多与手相关和与动作相关的单词。手相关:左手、右手、手、手指和手套。与运动相关的:跌倒、击打、搬运、举起和滑倒)

6.9 情感趋势
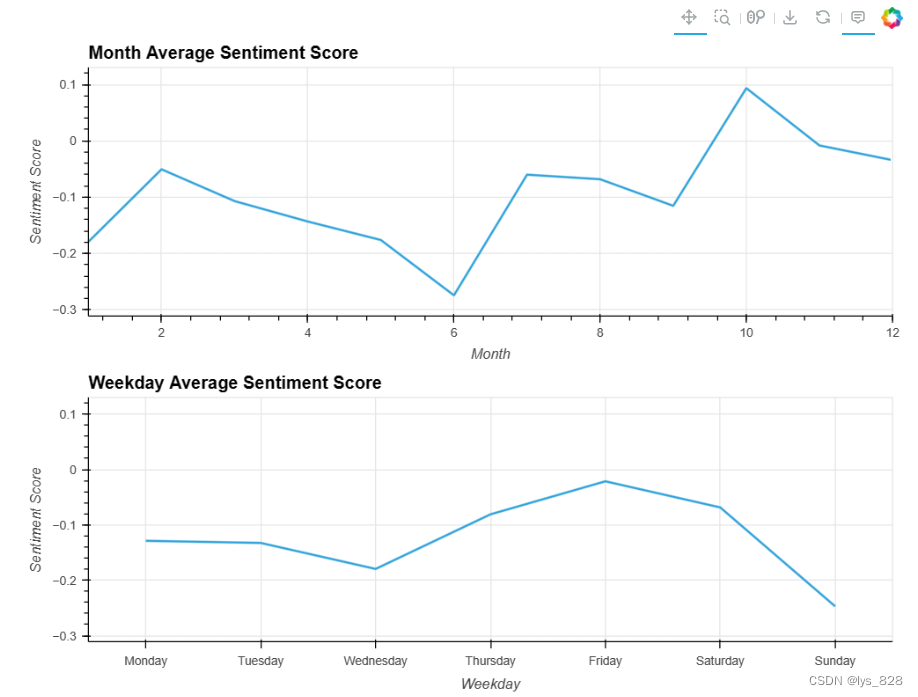
v1 = hv.Curve(df.groupby('Month')["Description_sentiment_score"].mean())\
.opts(opts.Curve(xlabel="Month", ylabel="Sentiment Score", width=800, height=300,tools=['hover'],show_grid=True,title='Month Average Sentiment Score'))
v2 = hv.Curve(df.groupby('Weekday')["Description_sentiment_score"].mean().reindex(index=['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']))\
.opts(opts.Curve(xlabel="Weekday", ylabel="Sentiment Score", width=800, height=300,tools=['hover'],show_grid=True,title='Weekday Average Sentiment Score'))
(v1 + v2).cols(1)
输出结果如下
7 数据建模
目标:
- 事故原因推定
- 调查增加事故严重程度的因素
建立事故严重程度分类模型,可以了解与事故因果关系相关的因素。 因此,根据以下案例建立了两个模型。
- 案例1:事故等级
- 案例2:潜在事故等级
7.1 特征工程
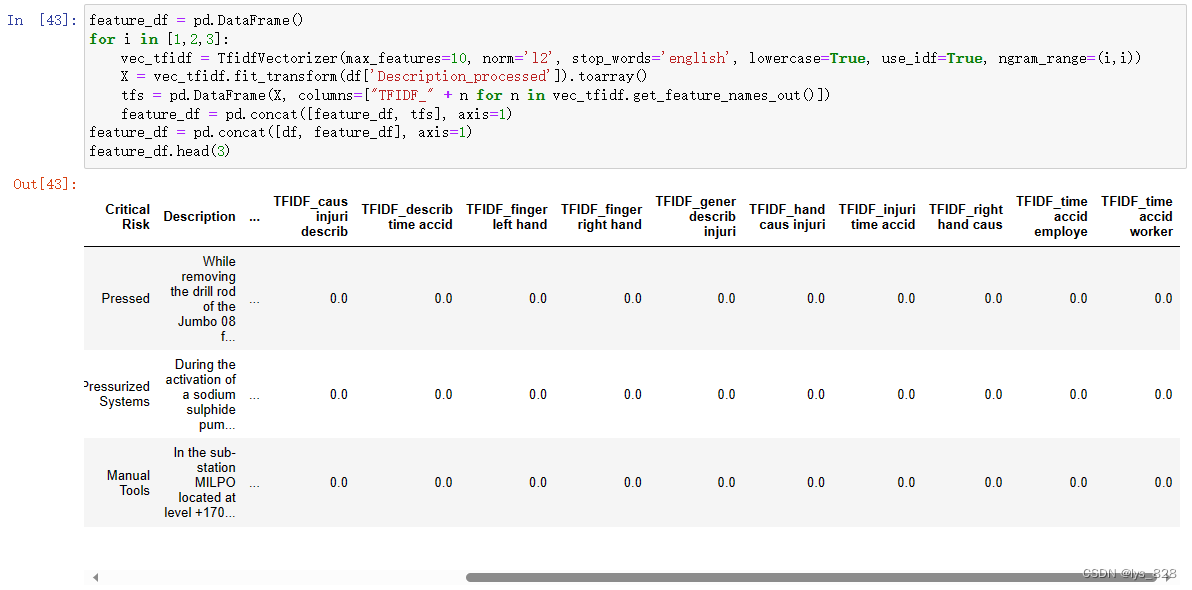
进行TF-IDF特征提取
feature_df = pd.DataFrame()
for i in [1,2,3]:
vec_tfidf = TfidfVectorizer(max_features=10, norm='l2', stop_words='english', lowercase=True, use_idf=True, ngram_range=(i,i))
X = vec_tfidf.fit_transform(df['Description_processed']).toarray()
tfs = pd.DataFrame(X, columns=["TFIDF_" + n for n in vec_tfidf.get_feature_names_out()])
feature_df = pd.concat([feature_df, tfs], axis=1)
feature_df = pd.concat([df, feature_df], axis=1)
feature_df.head(3)
输出结果如下
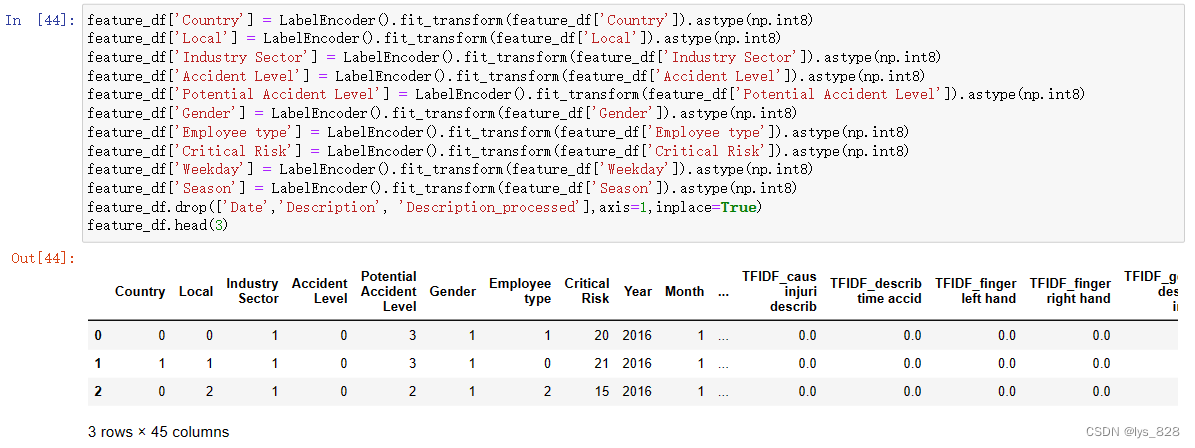
借助LabelEncoder()方法进行编码
feature_df['Country'] = LabelEncoder().fit_transform(feature_df['Country']).astype(np.int8)
feature_df['Local'] = LabelEncoder().fit_transform(feature_df['Local']).astype(np.int8)
feature_df['Industry Sector'] = LabelEncoder().fit_transform(feature_df['Industry Sector']).astype(np.int8)
feature_df['Accident Level'] = LabelEncoder().fit_transform(feature_df['Accident Level']).astype(np.int8)
feature_df['Potential Accident Level'] = LabelEncoder().fit_transform(feature_df['Potential Accident Level']).astype(np.int8)
feature_df['Gender'] = LabelEncoder().fit_transform(feature_df['Gender']).astype(np.int8)
feature_df['Employee type'] = LabelEncoder().fit_transform(feature_df['Employee type']).astype(np.int8)
feature_df['Critical Risk'] = LabelEncoder().fit_transform(feature_df['Critical Risk']).astype(np.int8)
feature_df['Weekday'] = LabelEncoder().fit_transform(feature_df['Weekday']).astype(np.int8)
feature_df['Season'] = LabelEncoder().fit_transform(feature_df['Season']).astype(np.int8)
feature_df.drop(['Date','Description', 'Description_processed'],axis=1,inplace=True)
feature_df.head(3)
输出结果如下
7.2 模型1
自变量x和因变量y指定,并进行数据集划分
y_series = feature_df['Accident Level']
x_df = feature_df.drop(['Accident Level','Potential Accident Level'], axis=1)
X_train, X_valid, Y_train, Y_valid = train_test_split(x_df, y_series, test_size=0.2, random_state=0, stratify=y_series)
lgb_train = lgb.Dataset(X_train, Y_train)
lgb_valid = lgb.Dataset(X_valid, Y_valid, reference=lgb_train)
模型参数设置和模型训练
params = {
'task' : 'train',
'boosting' : 'gbdt',
'objective': 'multiclass',
'num_class': 5,
'metric': 'multi_logloss',
'num_leaves': 200,
'feature_fraction': 1.0,
'bagging_fraction': 1.0,
'bagging_freq': 0,
'min_child_samples': 5
}
gbm_ac = lgb.train(params,
lgb_train,
num_boost_round=100,
valid_sets=lgb_valid,
early_stopping_rounds=100)
执行后输出结果如下
[1] valid_0's multi_logloss: 0.912095
Training until validation scores don't improve for 100 rounds
[2] valid_0's multi_logloss: 0.910376
[3] valid_0's multi_logloss: 0.903712
[4] valid_0's multi_logloss: 0.898231
[5] valid_0's multi_logloss: 0.887506
[6] valid_0's multi_logloss: 0.884693
[7] valid_0's multi_logloss: 0.887708
[8] valid_0's multi_logloss: 0.886078
[9] valid_0's multi_logloss: 0.878429
[10] valid_0's multi_logloss: 0.880784
[11] valid_0's multi_logloss: 0.87724
[12] valid_0's multi_logloss: 0.877685
[13] valid_0's multi_logloss: 0.879359
[14] valid_0's multi_logloss: 0.882408
[15] valid_0's multi_logloss: 0.887566
[16] valid_0's multi_logloss: 0.890385
[17] valid_0's multi_logloss: 0.889979
[18] valid_0's multi_logloss: 0.892999
[19] valid_0's multi_logloss: 0.897933
[20] valid_0's multi_logloss: 0.900157
[21] valid_0's multi_logloss: 0.903938
[22] valid_0's multi_logloss: 0.905301
[23] valid_0's multi_logloss: 0.911088
[24] valid_0's multi_logloss: 0.918347
[25] valid_0's multi_logloss: 0.925546
[26] valid_0's multi_logloss: 0.935013
[27] valid_0's multi_logloss: 0.943553
[28] valid_0's multi_logloss: 0.952987
[29] valid_0's multi_logloss: 0.96267
[30] valid_0's multi_logloss: 0.972972
[31] valid_0's multi_logloss: 0.980698
[32] valid_0's multi_logloss: 0.990955
[33] valid_0's multi_logloss: 1.00039
[34] valid_0's multi_logloss: 1.01087
[35] valid_0's multi_logloss: 1.02087
[36] valid_0's multi_logloss: 1.03035
[37] valid_0's multi_logloss: 1.03981
[38] valid_0's multi_logloss: 1.05052
[39] valid_0's multi_logloss: 1.06237
[40] valid_0's multi_logloss: 1.07026
[41] valid_0's multi_logloss: 1.08224
[42] valid_0's multi_logloss: 1.09309
[43] valid_0's multi_logloss: 1.10905
[44] valid_0's multi_logloss: 1.12296
[45] valid_0's multi_logloss: 1.1405
[46] valid_0's multi_logloss: 1.15419
[47] valid_0's multi_logloss: 1.16918
[48] valid_0's multi_logloss: 1.18282
[49] valid_0's multi_logloss: 1.1952
[50] valid_0's multi_logloss: 1.20876
[51] valid_0's multi_logloss: 1.22322
[52] valid_0's multi_logloss: 1.23938
[53] valid_0's multi_logloss: 1.25611
[54] valid_0's multi_logloss: 1.27279
[55] valid_0's multi_logloss: 1.28867
[56] valid_0's multi_logloss: 1.29769
[57] valid_0's multi_logloss: 1.30742
[58] valid_0's multi_logloss: 1.31998
[59] valid_0's multi_logloss: 1.33042
[60] valid_0's multi_logloss: 1.33836
[61] valid_0's multi_logloss: 1.35187
[62] valid_0's multi_logloss: 1.36289
[63] valid_0's multi_logloss: 1.37525
[64] valid_0's multi_logloss: 1.38617
[65] valid_0's multi_logloss: 1.39922
[66] valid_0's multi_logloss: 1.41223
[67] valid_0's multi_logloss: 1.42447
[68] valid_0's multi_logloss: 1.43529
[69] valid_0's multi_logloss: 1.44567
[70] valid_0's multi_logloss: 1.45696
[71] valid_0's multi_logloss: 1.4674
[72] valid_0's multi_logloss: 1.48043
[73] valid_0's multi_logloss: 1.48917
[74] valid_0's multi_logloss: 1.49977
[75] valid_0's multi_logloss: 1.51419
[76] valid_0's multi_logloss: 1.52558
[77] valid_0's multi_logloss: 1.53603
[78] valid_0's multi_logloss: 1.54743
[79] valid_0's multi_logloss: 1.55393
[80] valid_0's multi_logloss: 1.56039
[81] valid_0's multi_logloss: 1.56868
[82] valid_0's multi_logloss: 1.58254
[83] valid_0's multi_logloss: 1.59396
[84] valid_0's multi_logloss: 1.60636
[85] valid_0's multi_logloss: 1.61963
[86] valid_0's multi_logloss: 1.62537
[87] valid_0's multi_logloss: 1.63782
[88] valid_0's multi_logloss: 1.64857
[89] valid_0's multi_logloss: 1.65666
[90] valid_0's multi_logloss: 1.66944
[91] valid_0's multi_logloss: 1.68158
[92] valid_0's multi_logloss: 1.69245
[93] valid_0's multi_logloss: 1.70702
[94] valid_0's multi_logloss: 1.71733
[95] valid_0's multi_logloss: 1.72999
[96] valid_0's multi_logloss: 1.74404
[97] valid_0's multi_logloss: 1.75629
[98] valid_0's multi_logloss: 1.77261
[99] valid_0's multi_logloss: 1.78718
[100] valid_0's multi_logloss: 1.80042
Did not meet early stopping. Best iteration is:
[11] valid_0's multi_logloss: 0.87724
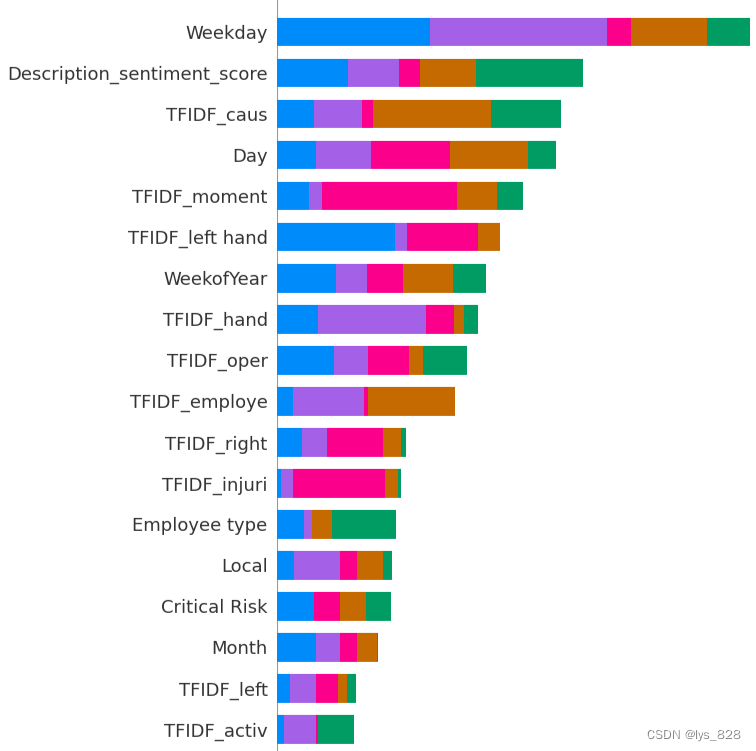
绘制重要特征图
ac_label = ['Accident Level : I','Accident Level : II','Accident Level : III','Accident Level : IV','Accident Level : V']
explainer = shap.TreeExplainer(model=gbm_ac)
shap_values_ac = explainer.shap_values(X=X_train)
shap.summary_plot(shap_values=shap_values_ac, features=X_train, feature_names=X_train.columns, plot_type="bar", max_display=30, class_names=ac_label)
输出结果如下(只截取部分)
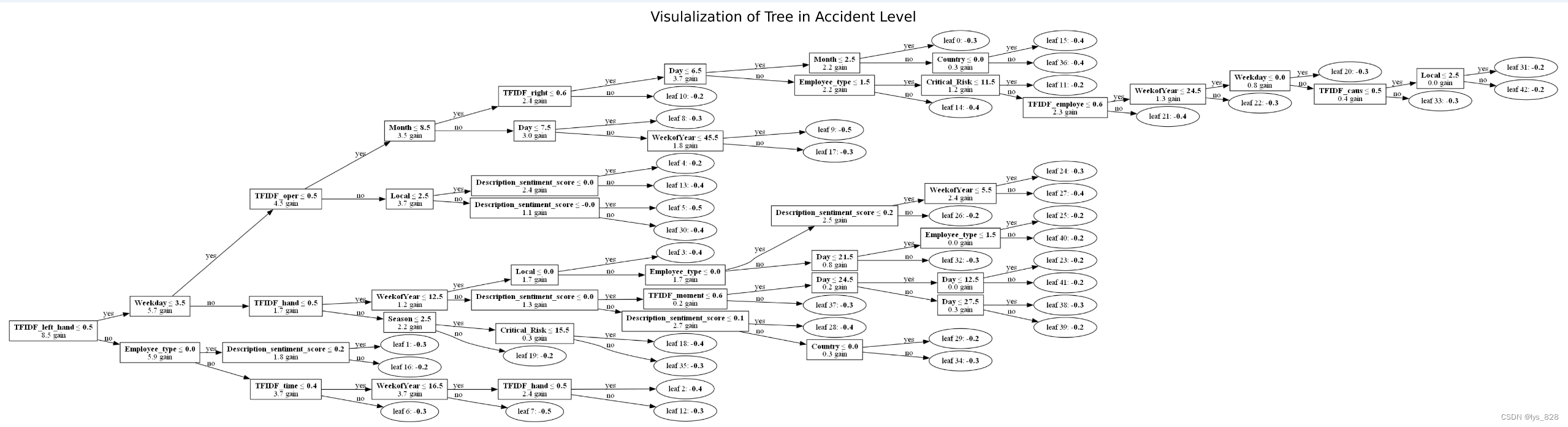
绘制决策树图
import os
os.environ['PATH'] = os.pathsep + r'D:\Program Files\Graphviz\bin'
t = lgb.plot_tree(gbm_ac, figsize=(24,16), precision=1, tree_index=0, show_info=['split_gain'])
plt.title('Visulalization of Tree in Accident Level')
plt.savefig('model_1.png',dpi=1000, bbox_inches='tight')
输出结果如下(保存的原图清晰度很高,但是上传的图片不是很清晰)
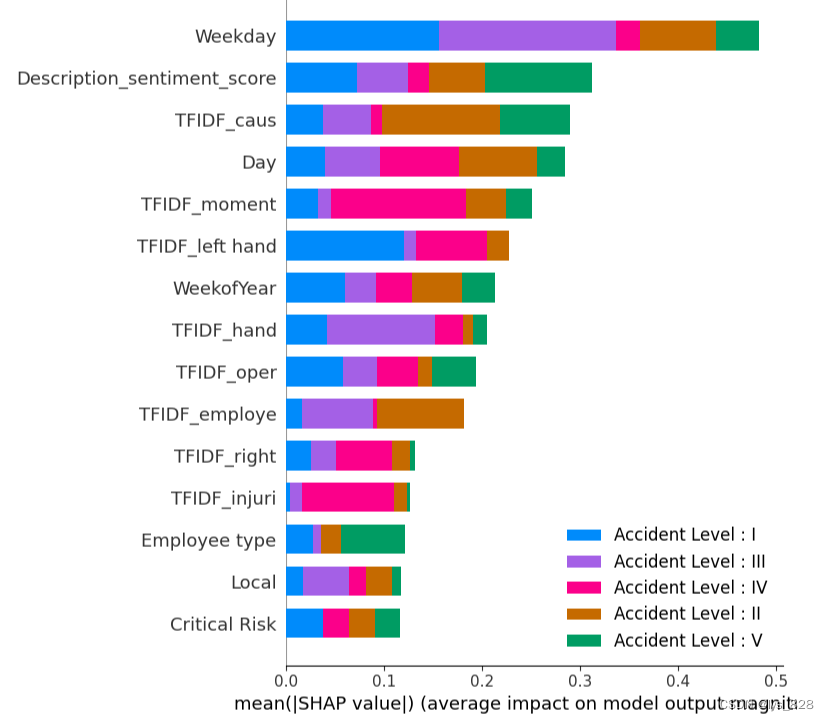
有许多重要的时间序列特征,如日、周和月,人们认为事故发生率和事故等级很容易随时间发生变化。
情感得分与事故等级有很大关系。情感得分是根据文本中的特定词语计算的,因此认为特定词语可能会增加事故等级的严重性。
由于有许多 TFIDF 特征与身体的某个部位相关,具有很高的重要性,特别是许多特征与手有关,如手、左手和右手,因此认为手工作业中的错误与事故的发生和严重程度有关。
7.3 模型2
_feature_df = feature_df[~feature_df['Potential Accident Level'].isin([5])]
y_series = _feature_df['Potential Accident Level']
x_df = _feature_df.drop(['Accident Level','Potential Accident Level'], axis=1)
X_train, X_valid, Y_train, Y_valid = train_test_split(x_df, y_series, test_size=0.2, random_state=0, stratify=y_series)
lgb_train = lgb.Dataset(X_train, Y_train)
lgb_valid = lgb.Dataset(X_valid, Y_valid, reference=lgb_train)
params = {
'task' : 'train',
'boosting' : 'gbdt',
'objective': 'multiclass',
'num_class': 5,
'metric': 'multi_logloss',
'num_leaves': 200,
'feature_fraction': 1.0,
'bagging_fraction': 1.0,
'bagging_freq': 0,
'min_child_samples': 5
}
gbm_pac = lgb.train(params,
lgb_train,
num_boost_round=100,
valid_sets=lgb_valid,
early_stopping_rounds=100)
训练模型输出结果如下
[1] valid_0's multi_logloss: 1.44132
Training until validation scores don't improve for 100 rounds
[2] valid_0's multi_logloss: 1.41426
[3] valid_0's multi_logloss: 1.39834
[4] valid_0's multi_logloss: 1.37333
[5] valid_0's multi_logloss: 1.36886
[6] valid_0's multi_logloss: 1.35867
[7] valid_0's multi_logloss: 1.35201
[8] valid_0's multi_logloss: 1.34547
[9] valid_0's multi_logloss: 1.34025
[10] valid_0's multi_logloss: 1.3417
[11] valid_0's multi_logloss: 1.34133
[12] valid_0's multi_logloss: 1.34079
[13] valid_0's multi_logloss: 1.34239
[14] valid_0's multi_logloss: 1.34311
[15] valid_0's multi_logloss: 1.34573
[16] valid_0's multi_logloss: 1.34068
[17] valid_0's multi_logloss: 1.33928
[18] valid_0's multi_logloss: 1.34338
[19] valid_0's multi_logloss: 1.34471
[20] valid_0's multi_logloss: 1.34776
[21] valid_0's multi_logloss: 1.34597
[22] valid_0's multi_logloss: 1.34877
[23] valid_0's multi_logloss: 1.34521
[24] valid_0's multi_logloss: 1.34417
[25] valid_0's multi_logloss: 1.34889
[26] valid_0's multi_logloss: 1.3547
[27] valid_0's multi_logloss: 1.35242
[28] valid_0's multi_logloss: 1.353
[29] valid_0's multi_logloss: 1.35771
[30] valid_0's multi_logloss: 1.36635
[31] valid_0's multi_logloss: 1.36549
[32] valid_0's multi_logloss: 1.36556
[33] valid_0's multi_logloss: 1.37343
[34] valid_0's multi_logloss: 1.38166
[35] valid_0's multi_logloss: 1.38691
[36] valid_0's multi_logloss: 1.39006
[37] valid_0's multi_logloss: 1.40296
[38] valid_0's multi_logloss: 1.41183
[39] valid_0's multi_logloss: 1.4175
[40] valid_0's multi_logloss: 1.42432
[41] valid_0's multi_logloss: 1.43035
[42] valid_0's multi_logloss: 1.43846
[43] valid_0's multi_logloss: 1.44752
[44] valid_0's multi_logloss: 1.46125
[45] valid_0's multi_logloss: 1.47077
[46] valid_0's multi_logloss: 1.48076
[47] valid_0's multi_logloss: 1.49192
[48] valid_0's multi_logloss: 1.50692
[49] valid_0's multi_logloss: 1.51483
[50] valid_0's multi_logloss: 1.52671
[51] valid_0's multi_logloss: 1.53959
[52] valid_0's multi_logloss: 1.54612
[53] valid_0's multi_logloss: 1.55982
[54] valid_0's multi_logloss: 1.57005
[55] valid_0's multi_logloss: 1.57809
[56] valid_0's multi_logloss: 1.59498
[57] valid_0's multi_logloss: 1.60583
[58] valid_0's multi_logloss: 1.61403
[59] valid_0's multi_logloss: 1.622
[60] valid_0's multi_logloss: 1.63188
[61] valid_0's multi_logloss: 1.63485
[62] valid_0's multi_logloss: 1.64637
[63] valid_0's multi_logloss: 1.65253
[64] valid_0's multi_logloss: 1.65666
[65] valid_0's multi_logloss: 1.66587
[66] valid_0's multi_logloss: 1.67005
[67] valid_0's multi_logloss: 1.67622
[68] valid_0's multi_logloss: 1.68616
[69] valid_0's multi_logloss: 1.69986
[70] valid_0's multi_logloss: 1.71661
[71] valid_0's multi_logloss: 1.72893
[72] valid_0's multi_logloss: 1.74515
[73] valid_0's multi_logloss: 1.75808
[74] valid_0's multi_logloss: 1.77302
[75] valid_0's multi_logloss: 1.77924
[76] valid_0's multi_logloss: 1.79578
[77] valid_0's multi_logloss: 1.81581
[78] valid_0's multi_logloss: 1.83469
[79] valid_0's multi_logloss: 1.83302
[80] valid_0's multi_logloss: 1.8477
[81] valid_0's multi_logloss: 1.8643
[82] valid_0's multi_logloss: 1.87201
[83] valid_0's multi_logloss: 1.88302
[84] valid_0's multi_logloss: 1.89645
[85] valid_0's multi_logloss: 1.90635
[86] valid_0's multi_logloss: 1.91808
[87] valid_0's multi_logloss: 1.9304
[88] valid_0's multi_logloss: 1.94378
[89] valid_0's multi_logloss: 1.95579
[90] valid_0's multi_logloss: 1.96997
[91] valid_0's multi_logloss: 1.9755
[92] valid_0's multi_logloss: 1.98292
[93] valid_0's multi_logloss: 1.99392
[94] valid_0's multi_logloss: 2.00249
[95] valid_0's multi_logloss: 2.01668
[96] valid_0's multi_logloss: 2.02537
[97] valid_0's multi_logloss: 2.03658
[98] valid_0's multi_logloss: 2.04821
[99] valid_0's multi_logloss: 2.05148
[100] valid_0's multi_logloss: 2.05743
Did not meet early stopping. Best iteration is:
[17] valid_0's multi_logloss: 1.33928
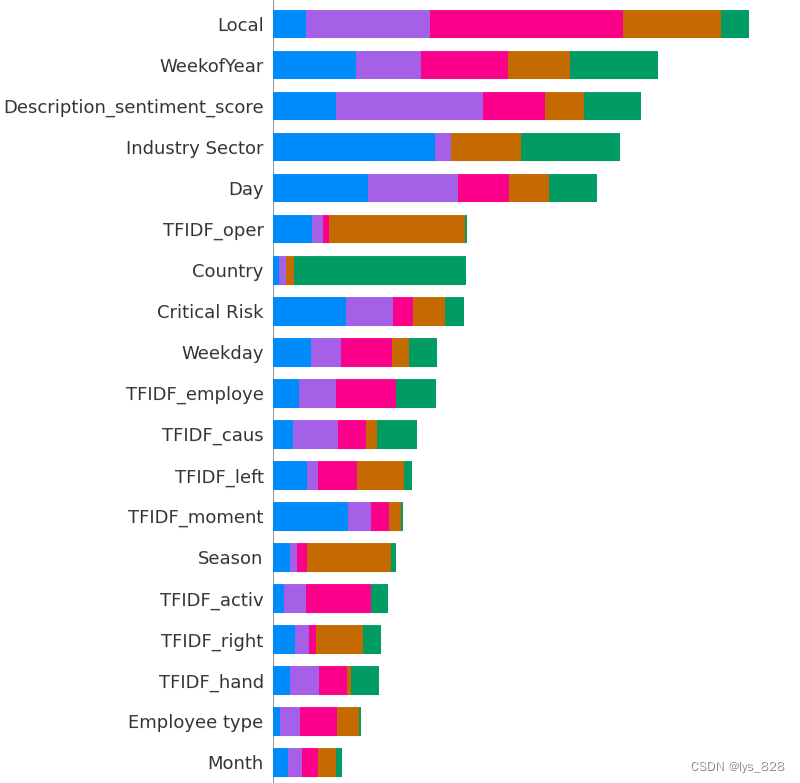
绘制重要特征图
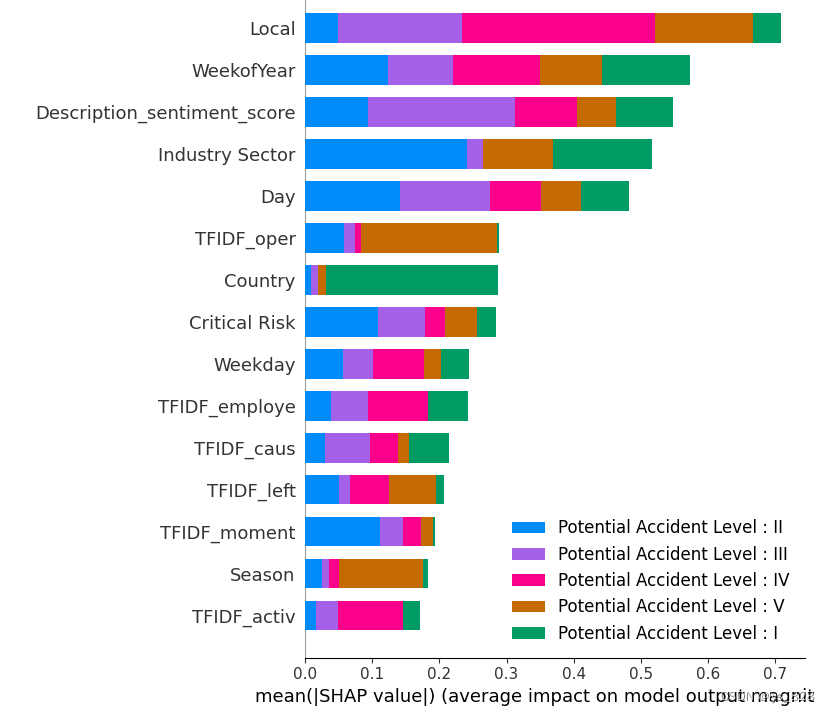
pac_label = ['Potential Accident Level : I','Potential Accident Level : II','Potential Accident Level : III','Potential Accident Level : IV','Potential Accident Level : V']
explainer = shap.TreeExplainer(model=gbm_pac)
shap_values_pac = explainer.shap_values(X=X_train)
shap.summary_plot(shap_values=shap_values_pac, features=X_train, feature_names=X_train.columns, plot_type="bar", max_display=30, class_names=pac_label)
输出结果如下(截取部分)
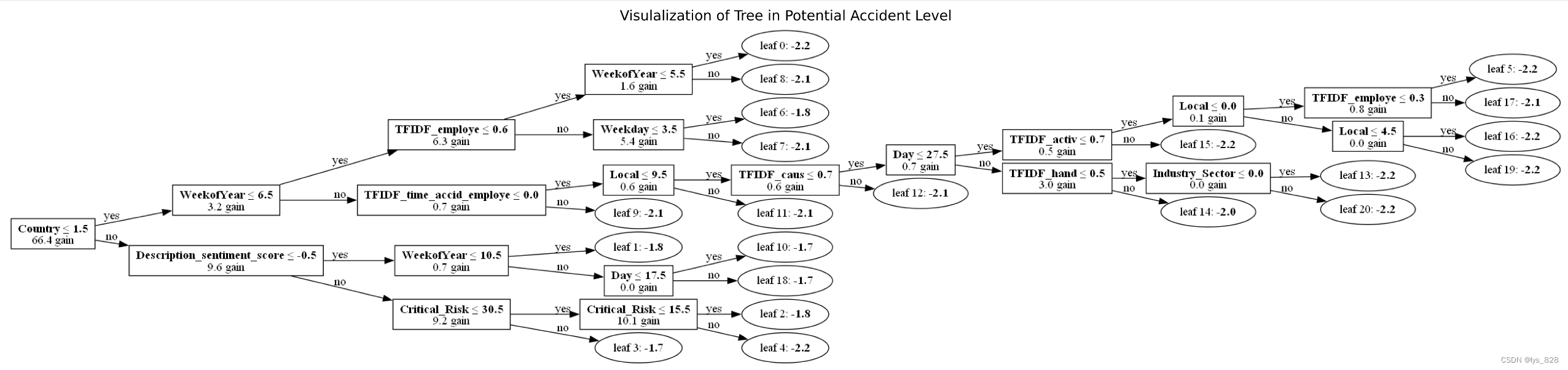
最后绘制决策树图
t = lgb.plot_tree(gbm_pac, figsize=(24, 16), precision=1, tree_index=0, show_info=['split_gain'])
plt.title('Visulalization of Tree in Potential Accident Level')
plt.savefig('model_2.png',dpi=1000, bbox_inches='tight')
输出结果如下
8 结论
在这个项目中,我们发现事故的主要原因是手工操作错误和时间因素。
为了减少事故的发生,在事故多发期,需要制定更严格的手动操作安全标准。
我意识到,"描述 "等事故详细信息对于分析事故原因非常有用。
有了更详细的信息,如工厂的加工数据(如 CNC、电流、电压)、天气信息、员工的个人数据(如年龄、行业经验、工作表现),我们就能更正确地阐明事故原因。
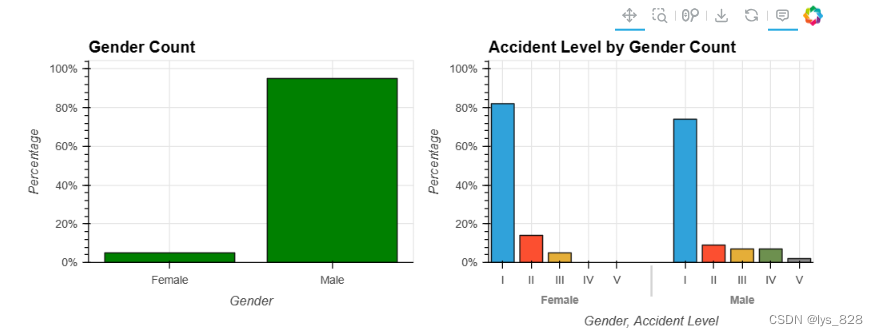
事故中的性别
在这项任务中,问题是 : 这些工厂的事故多与哪种性别有关?
答案 : 男性
虽然制造工厂的员工大多为男性,但 EDA 显示男性很可能参与事故(95%)。
与女性相比,男性发生事故的风险水平更高。
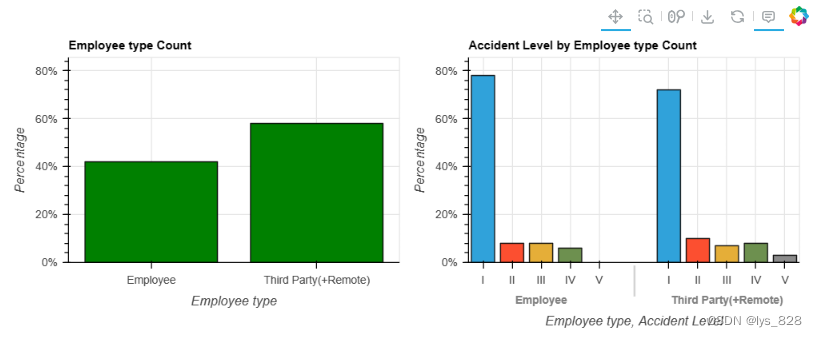
用工形式
在这项任务中,问题是 : 这些事故通常涉及第三方,还是主要涉及员工?
答:是的。第三方更容易卷入事故。
将员工的事故次数与第三方的事故次数进行比较,EDA 显示第三方很可能参与事故(58%)。
与雇员相比,第三方发生事故的风险略高。
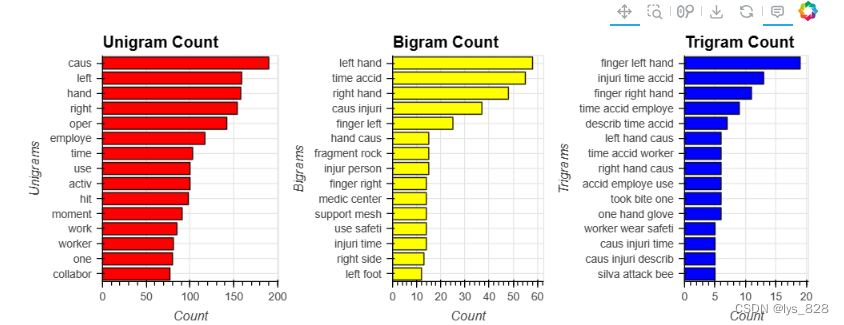
事故主要原因
在此任务中,问题是:通常是什么导致这些事故?
答:手部操作失误。
根据Ngram分析,可以说与手相关的操作是事故发生的主要原因。
根据事故等级分类建模表明,除了人为操作之外,时间相关特征也对事故的发生产生影响。
最后重要特征只显示前15个(分别对应模型1和模型2)
至此整个项目就梳理完毕,完结撒花✿✿ヽ(°▽°)ノ✿