梯度消失、梯度爆炸
以下内容默认读者知道什么是神经网络,反向传播
在神经网络训练模型中,一些简单的模型往往隐藏层(hidden layer)不会太多,并且可以训练出一些效果很好的模型。但是如果你在模型中加入了很多隐藏层,就可能会造成梯度消失和梯度爆炸的问题
梯度消失
原因:激活函数的选择
激活函数有很多种,比如 ReLu,sigmoid 等。如果在一个很复杂,层数很多的神经网络种,使用了 sigmoid 激活函数,是造成梯度消失的主要原因。
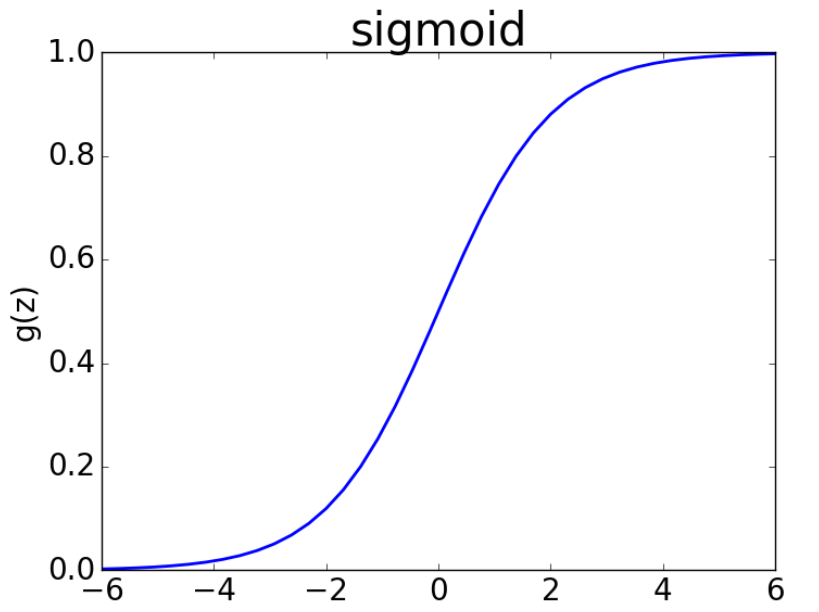
下图是 sigmoid 函数
- 首先,可以看出,当输入值越忘正负无穷靠近时,sigmoid 值会越接近0,此时梯度也会接近0。
- 其次,sigmoid 函数的梯度最大时 0.25,当神经网络层数很多的时候,使用反向传播计算梯度的时候,由于需要计算权重的偏导数,会连续乘上很多个 0.25,导致梯度值越来越小,最终接近 0,从而产生梯度消失的问题,而这些梯度接近 0 的权值,则基本不会在更新。
解决方法:使用其他激活函数,如 ReLu
梯度爆炸
原因:权值初始值太大
同样,在网络层比较多的模型下,如果权值初始化值太大,会导致前面的网络层比后面的网络层梯度变化更快,出现梯度爆炸的问题。所以一般情况下,权值的初始化都使用高斯分布随机产生
解决方案
- 激活函数
- 残差结构
- 高斯分布产生初始权值
- LSTM