【完结】囚生CYの备忘录(20231014~20231117)
序言
代有才人出,我们这一辈也已经老了。
邂逅花有重开日
断路人无再会时
月明林下寄旧诗
水佩风裳知不知?
罢了。
文章目录
20221014
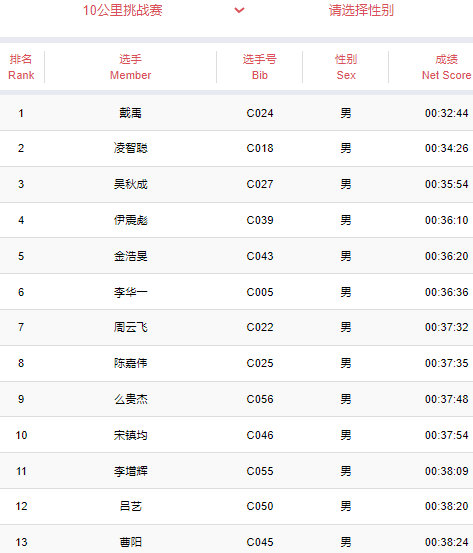
- 本以为下午怡宝的比赛至少是能跑到前三,结果连前五都没摸到,赛前都知道路线不可能有5km,因为即便是绕着主校区最外沿跑一圈也才4km出头,我估摸着是2500米,实际上只有1700米,所以就是全程冲刺,但因为急转弯太多,亏了太多力气,加上年纪大不中用了,实在是没能冲得过几个新生,嘉伟不到5分钟就杀死了比赛,新来的崔洲宸第二,宋镇均第三,退伍生第五,还有一个不认识的是第四,我最后快到终点前是第六,听到王炳杰在后面跟着我,我以为第六还是能拿到手环的(他特别想要),就在终点前把第六让给他了,用时5分40秒,结果都是三等奖,属实难蚌,难兄难弟,但好歹有一箱水和蓝牙跳绳,我也不是很需要手环。后面还有个周俊呈第九,他现在无氧水平也算是提升了不少,但还是力量太差,注定很难有很大突破。卢星雨和丁古丽分列女子前二,她俩确实跑得很勤快。
- 虽然一定程度上是因为距离太短,撞上无氧耐力的短板,但跑得确实笨重(这两天体重有点反弹,快71kg了,之前一直都是69kg上下),身体休息恢复得不好,怕再难以恢复到巅峰,而且今晚喉咙开始疼,大概是受凉了,下午跑的时候喉咙就痒的不停咳,明早的二工大的10km路跑赛很悬,准备跟着宋镇均混了,他这小子两周不跑还能这么快,B话是一句都不能信。
gradio@request
import gradio as gr
def echo(text, request: gr.Request):
if request:
print("Request headers dictionary:", request.headers)
print("IP address:", request.client.host)
print("Query parameters:", dict(request.query_params))
return text
io = gr.Interface(echo, "textbox", "textbox").launch()
import gradio as gr
def predict(text, request: gr.Request):
headers = request.headers
host = request.client.host
user_agent = request.headers["user-agent"]
return {
"ip": host,
"user_agent": user_agent,
"headers": headers,
}
gr.Interface(predict, "text", "json").queue().launch()
20231015
- Unirun 10K成绩38’26",均配4’07",实际上只有9300米多一些的距离,总体来说还是挺满意的,毕竟最近也没怎么认真练,又是连上七天班,但基本上持平了万米最佳的配速(虽然距离上略少一些,而且最后400米确实已经跑不动了),前程跟打了鸡血一样,5km分段用时20’20",因为大家一开始都贼猛,被迫跟着发疯,第一个1km只用了3’48",我就知道坏了,赶紧调整节奏,后程虽然掉的很厉害,但还是顺利完赛。嘉伟因为昨晚跟MBA测5000米,早上状态不好,最后是37分完赛,宋某人赛前口口声声跑不动,结果起跑就把我甩没影了,我本来想叫住他别那么快,结果直到6k以后我才慢慢赶上他,但一直有100米的差距,直到终点也追不上去,他38分整完赛。另外那个新生崔洲宸确实很强,不愧是刚入学就放言要校运会拿第一的家伙,确实有两把刷子,他接力的4000米分段配速达到了令人咋舌的3’30",两年来对嘉伟有威胁的人终于出现了。
- 中午李婷玉带队在三号湾干了一顿饭,发现三号湾那边真心物美价廉,五角场附近有这么便宜的店真不容易。
- 另外胡鑫宇今天在泰州半马(他的首半马)跑出1:34:59的好成绩,均配4’30",他水平跟我差不多,体能不错,但力量短板,不过运气确实好,首半马即发挥出真实水平,我在锡马跑了1小时42分,因为人太多前5000米都跑不开,泰州人少确实也好跑。下周他还有一场苏州的半马。AK则是去南京参加越野赛,拿到了25km男子组的第三名,AK真乃神人也。嘉伟通过怡宝的活动拿到了12月上马直通名额,全马对我们来说还是太困难了,但总有一天是要去跑的。
# -*- coding: utf-8 -*-
# @author : caoyang
# @email: caoyang@163.sufe.edu.cn
import os
import json
import pandas
from xml.etree import ElementTree
def yield_race_sample(race_path, types, difficulties, batch_size):
current_batch_size = 0
batch_data = list()
for type_ in types:
# train, dev, test
for difficulty in difficulties:
# high, middle
data_root = os.path.join(race_path, type_, difficulty)
for filename in os.listdir(data_root):
with open(os.path.join(data_root, filename), 'r', encoding="utf8") as f:
data = json.load(f)
article_id = data["id"]
article = data["article"]
questions = data["questions"]
options = data["options"]
answers = data["answers"]
# Ensure the number of questions, options and answers are the same
assert len(questions) == len(options) == len(answers), article_id
# Ensure id matches filename
assert article_id == difficulty + filename, article_id
for question_id, (question, option, answer) in enumerate(zip(questions, options, answers)):
# Ensure total option is 4
assert len(option) == 4, f"{article_id}-{question_id}"
# @yield article_id : "high1.txt"
# @yield question_id : 0
# @yield article : "My husband is a born shopper. He ..."
# @yield question : "The husband likes shopping because _ ."
# @yield options : ["he has much money.", "he likes the shops.", "he likes to compare the prices between the same items.", "he has nothing to do but shopping."]
# @yield answer : 'C'
batch_data.append({"article_id": article_id,
"question_id": question_id,
"article": article,
"question": question,
"options": option,
"answer": answer,
})
current_batch_size += 1
if current_batch_size == batch_size:
yield batch_data
current_batch_size = 0
batch_data = list()
if current_batch_size > 0:
yield batch_data
def yield_dream_sample(dream_path, types, batch_size):
current_batch_size = 0
batch_data = list()
for type_ in types:
# train, dev, test
with open(os.path.join(dream_path, f"{type_}.json"), 'r', encoding="utf8") as f:
data = json.load(f)
for article_sentences, questions, article_id in data:
article = '\n'.join(article_sentences)
for question_id, question_item in enumerate(questions):
question = question_item["question"]
options = question_item["choice"]
flag = False
assert len(options) == 3, f"{article_id}-{question_id}"
for i, option in enumerate(options):
if option == question_item["answer"]:
assert not flag, f"{article_id}-{question_id}"
answer = "ABC"[i]
flag = True
assert flag, f"{article_id}-{question_id}"
# @yield article_id : "4-199"
# @yield question_id : 0
# @yield article : "W: The movie next Tuesday ..."
# @yield question : "What can we conclude about the movie?"
# @yield options : ["They want to buy the tickets for the movie.", "The tickets for the movie were sold.", "The movie will not be shown."]
# @yield answer : 'C'
batch_data.append({"article_id": article_id,
"question_id": question_id,
"article": article,
"question": question,
"options": options,
"answer": answer,
})
current_batch_size += 1
if current_batch_size == batch_size:
yield batch_data
current_batch_size = 0
batch_data = list()
if current_batch_size > 0:
yield batch_data
# @param race_path: Str, e.g. D:\resource\data\RACE
# @param id_ : Str, e.g. high10001.txt
# @param type_ : Str, optional, e.g. train, dev, test
def load_race_sample(race_path, id_, type_=None):
if id_.startswith('high'):
difficulty = 'high'
elif id_.startswith('middle'):
difficulty = 'middle'
else:
raise Exception(f'Unknown RACE id: {id_}')
if type_ is None:
for candidate_type in ['train', 'dev', 'test']:
if os.path.exists(os.path.join(race_path, candidate_type, difficulty, id_[len(difficulty):])):
type_ = candidate_type
if type_ is None:
raise Exception(f'{id_} not found!')
file_path = os.path.join(race_path, type_, difficulty, id_[len(difficulty):])
with open(file_path, 'r', encoding="utf8") as f:
data = json.load(f)
return data
# @param dream_path : Str, e.g. D:\resource\data\dream\data
# @param id_ : Str, e.g. 4-199
# @param type_ : Str, optional, e.g. train, dev, test
def load_dream_sample(dream_path, id_, type_=None):
if type_ is None:
for candidate_type in ["train", "dev", "test"]:
with open(os.path.join(dream_path, f"{candidate_type}.json"), 'r', encoding="utf8") as f:
json_string = f.read()
if f"\"{id_}\"" in json_string:
type_ = candidate_type
data = json.loads(json_string)
break
if type_ is None:
raise Exception(f"{id_} not found!")
else:
with open(os.path.join(dream_path, f"{type_}.json"), 'r', encoding="utf8") as f:
data = json.load(f)
ids = list(map(lambda sample: sample[-1], data))
index = ids.index(id_)
return data[index]
def generate_dataloader(data_name, types, batch_size):
from settings import DATA_SUMMARY
data_path = DATA_SUMMARY[data_name]["path"]
if data_name == "RACE":
return yield_race_sample(race_path=data_path,
types=types,
difficulties=["high", "middle"],
batch_size=batch_size,
)
elif data_name == "DREAM":
return yield_dream_sample(dream_path=data_path,
types=types,
batch_size=batch_size,
)
else:
raise NotImplementedError(f"Unknown data: {data_name}")
def generate_dataloader(data_name, dtypes, batch_size):
from settings import DATA_SUMMARY
data_path = DATA_SUMMARY[data_name]["path"]
if data_name == "RACE":
return sadsd
20231016~20231017
- 昨晚回去加速跑了10圈,赛后大腿酸痛,简单维持一下状态。
- 今晚回来已经挺累了,本来只打算过去小跑一下,结果先是遇崔洲宸,我还从没和他过招,虽然知道跑不过他,但还是想探探这个新生的底,他每天早晚各一个5k,不到一个月就把5000米从22分跑到19分半(他是有基础的,暑假没练而已,他现在跑姿不太行,依然是后跟跑法,只要经过系统训练,就是下一个陈嘉伟),今晚是慢摇5000米的最后1k跟他冲了一下,不到3分半,对我来说很吃力。
- 然后我已经打算撤了,看到卢星雨过来,她正好下午组会延迟没赶上训练(这学期晚上没有碰到过,她一般都是晚饭前五六点跑),于是拿了块15kg的片来练了30个×8组的箭步走,后又陪着慢跑了七八圈,她慢跑比我还快,我一般都是5分配出头慢摇,她都能摇到5分以内,很久没有看过她全力跑的水平,我觉得她3k绝对还能进13分钟,只是不想参赛。
- 最后拉伸完真的准备走了,胡鑫宇又来,他正好半马回来后还没碰过面,凑合着陪他跑了一圈,聊了会儿,整个人都打开了,完全没有疲劳的感觉了。有时候一个人跑确实越跑越累,但是陪人一起跑确实舒服很多。
发现一个文件编码(确切的说是请求头Accept Encoding字段的坑)的坑,以前不知道这个点,然后碰巧在https://blog.csdn.net/YungGuo/article/details/110197818的评论里有人指出来的。
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import re
import time
import logging
import requests
from bs4 import BeautifulSoup
class BaseCrawler:
tag_regex = re.compile(r"<[^>]+>|\n|\t")
global_timeout = 60
global_interval = 300
def headers_to_dict(headers: str) -> dict:
lines = headers.splitlines()
headers_dict = {}
for line in lines:
key, value = line.strip().split(':', 1)
headers_dict[key.strip()] = value.strip()
return headers_dict
def easy_requests(self, method, url, **kwargs):
while True:
try:
response = requests.request(method, url, **kwargs)
break
except Exception as e:
logging.warning(f"Error {method} {url}, exception information: {e}")
logging.warning(f"Wait for {self.global_interval} seconds ...")
time.sleep(self.global_interval)
return response
class DxsbbCrawler(BaseCrawler):
host_url = "https://www.dxsbb.com/"
headers = """Host: www.dxsbb.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/118.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Cookie: acw_tc=b6284e9216974488936938256e5b60c9f3bc9bb94890ea21751e528cb8; ASPSESSIONIDQWAARSQD=FMMFAGCCLOHLIFKCFMMIFPGO; Hm_lvt_0fde2fa52b98e38f3c994a6100b45558=1697448894; Hm_lpvt_0fde2fa52b98e38f3c994a6100b45558=1697448894
Upgrade-Insecure-Requests: 1
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: none
Sec-Fetch-User: ?1
TE: trailers"""
def __init__(self):
super(DxsbbCrawler, self).__init__()
def parse_table(self, url, save_path=None):
response = self.easy_requests("GET", url, headers=BaseCrawler.headers_to_dict(headers=self.headers))
encoding = response.encoding if response.encoding is not None else response.apparent_encoding
print(html)
print(html.encode("iso8859-1").decode("utf8"))
soup = BeautifulSoup(html, "lxml")
if save_path is None:
save_path = f"{soup.find('title').string}.csv"
table = soup.find("table")
write_string = str()
for tr in table.find_all("tr"):
for td in tr.find_all("td"):
write_string += f"{td.string}\t"
write_string = write_string[-1] + '\n'
with open(save_path, 'w', encoding="utf8") as f:
f.write(write_string)
def run_dxsbb():
crawler = DxsbbCrawler()
url = "https://www.dxsbb.com/news/95119.html"
# url = "https://www.dxsbb.com/news/111477.html"
crawler.parse_table(url)
if __name__ == "__main__":
run_dxsbb()
这是一段爬取大学生必备网页面表格的脚本,以前爬虫经常会有返回的源代码是乱码的情况,不过那时候一般只要html.encode("iso8859-1").decode("utf8")就能解决,或者不放心查看一下response.encoding和response.apparent_encoding,确保是iso8859-1的编码。但是这次一直都报错,就是不能正确编解码(加入参数errors="ignore"也不行)。
于是我用了最笨的方法,就是遍历所有的编解码组合,看看到底哪一组能编解乱码:
root = r"C:\Users\caoyang\Anaconda3\pkgs\python-3.7.0-hea74fb7_0\Lib\encodings"
string = r"é>Ä™™™ÍˇûóSå7@g÷°“MmY*="
string = r"é>Ä™™™ÍˇûóSå7@g÷°“MmY*=|¶g`f†ÁPs*˜å.˜òpÀ™ €1‹£¬=*"
string = r"é>Ä™™™ÍˇûóSå7@g÷°“MmY*=|¶g`f†ÁPs*˜å.˜òpÀ™ €1‹£¬=*w7wss3s7fl,‹7w3u7è åƨå HØ㜨˨à¥Ãflwbˇù£T"
import os
encodings = list()
for filename in os.listdir(root):
if filename.endswith(".py") and (not filename.startswith("__init__")):
encoding = filename.split('.')[0]
encodings.append(encoding)
with open("d:/log.txt", 'w', encoding="utf8") as f: pass
for encode_by in encodings:
for decode_by in encodings:
try:
res = string.encode(encode_by, errors="ignore").decode(decode_by, errors="ignore")
with open("d:/log.txt", 'a', encoding="utf8") as f:
f.write(f"{encode_by} - {decode_by} - {res}\n")
except Exception as e:
with open("d:/log.txt", 'a', encoding="utf8") as f:
f.write(f"{encode_by} - {decode_by} - ERROR: {str(e)[:64]}\n")
很不幸,唯一编解拿到不是乱码的结果是用utf7编码,然后各种常规解码都可以,但结果完全不是HTML:
utf_7 - iso8859_3 - +AAUA6Q>+AMQhIiEiISIAzQLHAPsA8w-S+AOU-7@g+APcAsCAc-MmY*=|+ALY-g+AAY`f+ICAAwQ-P+AAM-s*++P8ADALcAOX4/w.+AA8C3ADy-p+AMAhIg +IKw-1+IDkAowCs=*+ABY-w7ws+AAs-s3s7++wI,+IDkAFg-7w3u7+AOg +AOUAxgCoAOU H+ANgAAgDjABgBUwCoAMsAqADgAKUAwwAI+wI-wb+AscA+QCj-T+ABU-
utf_7 - iso8859_4 - +AAUA6Q>+AMQhIiEiISIAzQLHAPsA8w-S+AOU-7@g+APcAsCAc-MmY*=|+ALY-g+AAY`f+ICAAwQ-P+AAM-s*++P8ADALcAOX4/w.+AA8C3ADy-p+AMAhIg +IKw-1+IDkAowCs=*+ABY-w7ws+AAs-s3s7++wI,+IDkAFg-7w3u7+AOg +AOUAxgCoAOU H+ANgAAgDjABgBUwCoAMsAqADgAKUAwwAI+wI-wb+AscA+QCj-T+ABU-
utf_7 - iso8859_5 - +AAUA6Q>+AMQhIiEiISIAzQLHAPsA8w-S+AOU-7@g+APcAsCAc-MmY*=|+ALY-g+AAY`f+ICAAwQ-P+AAM-s*++P8ADALcAOX4/w.+AA8C3ADy-p+AMAhIg +IKw-1+IDkAowCs=*+ABY-w7ws+AAs-s3s7++wI,+IDkAFg-7w3u7+AOg +AOUAxgCoAOU H+ANgAAgDjABgBUwCoAMsAqADgAKUAwwAI+wI-wb+AscA+QCj-T+ABU-
python内置的编码方式有120多种,这就很纳闷了,所有的编解码组合有15000多种,愣是一组都解不出来,最后才知道,问题出在请求头里:
"""User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/118.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Cookie: acw_tc=b6284e9216974488936938256e5b60c9f3bc9bb94890ea21751e528cb8; ASPSESSIONIDQWAARSQD=FMMFAGCCLOHLIFKCFMMIFPGO; Hm_lvt_0fde2fa52b98e38f3c994a6100b45558=1697448894; Hm_lpvt_0fde2fa52b98e38f3c994a6100b45558=1697448894
Upgrade-Insecure-Requests: 1
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: none
Sec-Fetch-User: ?1
TE: trailers"""
一般来说Accept-Encoding都是gzip,这里多了一个br,这个是压缩的方式,只要把br去掉就行了。
如果一定要带着br请求,可以考虑:https://blog.csdn.net/qq_37952113/article/details/120625794
浏览器支持的编码类型。一般有gzip,deflate,br 等等。
python的requests里,有response.text 和 response.content,一般解码byte和str类型。所以如果遇到br类型就会解码得到一堆乱码。
br是brotli,一种新的数据格式。在网页右键‘检查’,‘Network’里面,可以查看网页的压缩模式:
content-encoding:br
content-type:text/html; charset=utf-8
解决方案:
在python中导入brotli包(安装:pip install brptli):
import brotli
并将‘br’添加到headers的Accept_encoding中:
'Accept-Encoding': 'br,gizp,defale'
另外BeautifulSoup解析库,lxml容易解析不全,对于纯HTML5文本,html5lib最准但最慢,html.parser快且准,lxml最快但最不准(烦,被这个bug整了半天,不知道为什么会解析不全)。
20231018~20231019
- 周二练完力量,休两日,今天是最疼的一天。昨天卢星雨一共干了15km,5’20"的配速,这丫头是真的可怕,跟硕士新生李昊然和周俊呈(他们两个都是国教的,但水平一般,卢星雨如果全力跑,他俩都未必是对手)。九点半回校去操场摇了5圈,还能碰到崔洲宸和嘉伟在练,现在有崔洲宸在,嘉伟也是有点压力,期待他5k能突破17分的一天。
- 周日的UniRun成绩公示,嘉伟第8,宋镇均第10,我第13(好可惜,前12是有证书和奖品的,就是这个同济的吕艺,穿个红裤衩,前两圈都跟着我,我第三圈好不容易把他甩了,后面一直没看到他,结果最后进田径场200米冲刺把我反超,不过我进田径场的时候也倒霉方向跑反了,折了一段,然后冲刺拼不过这些年轻人)。嘉伟显然发挥太失常,只比我快了49秒,宋某人这B就不谈了,说好一起跑,结果只是一起起跑(确切的说,跑前我跟他讲,我准备跑410的配速,你快就我跟你,我快就你跟我,结果起跑就是3分整配速冲刺,甩得人都没影)。不过就这个成绩而言,我已无不满。这场高手很少,不如市运会甲组,虽然冠军实力断层碾压,但嘉伟状态好是有希望争前三。
- 下半年最后两场,月底31号的校运会5000米,争取第三站个台,主要对手还是宋镇均,嘉伟和崔洲宸确实比我强。11月中旬高百(之前说是28号场地4000米接力,那个太无聊了),现在最新消息是11月中旬线下,16人(至少2女)×10km路跑接力,我点了一下人头,只靠在校生还是很难凑出16人的阵容,女生是够的,但男生水平够用的太少,除了AK35分台,嘉伟37分台,李乐康、宋镇均、退伍兵和我算40分台,其他人45分钟都够呛,如果能凑出全部sub40的阵容,也能跟同济交大海医海事上体五强正面对抗)。
招聘信息结构化
def extract_metadata(self, document, index, save_path):
# 编写正则表达式
# regex_sal = re.compile("[^a-zA-Z\d][1-9]\d{1,2}00[^\d号年届]") # 其实这个更好,但是这个在匹配形如“工资4000-6000元/月”的句式时只能匹配到4000,而忽略6000
regex_sal = re.compile("([1-9]\d{1,2}00)[^\d号年届]") # 这个避免了上面的问题,但可能匹配到不合适的结果
regex_edu_raw = '('
for edu in self.education_1s + self.education_2s + self.education_3s:
regex_edu_raw += f"{edu}|"
regex_edu_raw = regex_edu_raw[:-1] + ')'
regex_edu_raw += "(研究生)?(学历)?(以?及)?(以[上内下])?(学历)?"
regex_edu = re.compile(regex_edu_raw)
# 生成
regex_maj_raw = '('
for major in self.major_1s + self.major_2s + self.major_3s:
regex_maj_raw += f"{major}|"
if major.endswith("大类"):
regex_maj_raw += f"{major[:-2]}|"
elif major.endswith("类"):
regex_maj_raw += f"{major[:-1]}|"
else:
continue
regex_maj_raw = regex_maj_raw[:-1] + ')'
regex_maj_raw += "(专业)?"
regex_maj = re.compile(regex_maj_raw)
# 解析招聘广告(非结构化->结构化数据)
res = {"id": list(),
"salary": list(),
"education": list(),
"major": list(),
}
def _resolve_job_ad( _ad_text):
_match_string_sal = '|'.join([_result for _result in regex_sal.findall(_ad_text)]) # 薪资
_match_string_edu = '|'.join([''.join(_result) for _result in regex_edu.findall(_ad_text)]) # 学历
_match_string_maj = '|'.join([''.join(_result) for _result in regex_maj.findall(_ad_text)]) # 专业
res["salary"].append(_match_string_sal)
res["education"].append(_match_string_edu)
res["major"].append(_match_string_maj)
# 统计数据并导出
count = -1
for i, ad_text in zip(index, document):
count += 1
if count % 10000 == 0:
logging.info(count)
res["id"].append(i)
_resolve_job_ad(_ad_text=ad_text)
res = pd.DataFrame(res, columns=list(res.keys()))
logging.info(f"Save to {save_path}")
res.to_csv(save_path, sep='\t', header=True, index=False)
20231020~20231021
- 昨天周五,回来已经困得头疼,本想直接就回去把论文投了就洗洗睡,但想还是去操场溜达一下,刚好碰到卢星雨打完球在放松慢跑,陪着跑了一下,慢慢带到430的配速,我试探性地问了一下是否吃力,似乎她还游刃有余,不过确实有人一起跑会轻松些,虽然我已经是疲劳驾驶,但也没觉得累。后来宋镇均到,我脱了外套让他带我冲了最后1500米,340配速。一共跑了5000米左右,跑完一下子就打开了。
- 跑完我问卢星雨为什么近两年都不跑校运会,她说要是参加就占了本科生的名次,影响她们奖学金加分,woc,顿时格局打开,我恍然大悟,我咋就达不到这种层次呢?
- 周末补觉,但现在连懒觉都睡不着,昨晚熬到两点多,今天不到九点就醒了,中午也只睡了一个小时多一些。晚上过去先陪嘉伟外道跑了5圈(他明早10km精英赛,今晚只是顺腿,但也带到了355的配速),然后崔洲宸来,我顺道就跟着跑了,发现这家伙真的NB,比我想象的还要快,他早上刚跑了8km,然后晚上一个3000米还能跑到11’12"的水平,把我甩了一根直道,完全跟不住,他现在月跑量有300km,太可怕了,正式比赛绝对是能跟上嘉伟,甚至我觉得给他三个月时间是能超越嘉伟的。(我查了一下他pyq,昨天8km均配是3’56",万米绝对能开40分钟,而且现在这些新生朋友圈发的真勤快,一天能发五六条,后浪来袭,我们真的老了)。最后陪退伍兵慢摇了5000米,445的配速,边跑边聊天,轻松惬意。
- 估算了一下校运会的对手,今年校运会的5000米极有可能是近5年水平最高的一次,除了嘉伟和洲宸T0之外(有望跑进18分钟),宋镇均、退伍兵、外加从800米转中长的徐瀚韬和我都算是T1(19分台),此外据说新生里还有不少水平极高的人,想必真的是一场腥风血雨了,想争前三几乎不太可能。
多轴作图:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import math
import numpy
import torch
from matplotlib import pyplot as plt
from mpl_toolkits.axisartist.parasite_axes import HostAxes, ParasiteAxes
# @param y_prob: torch.FloatTensor, (batch_size, n_option)
# @param y_true: torch.LongTensor, (batch_size, )
# Evaluate single-choice outputs
def evaluate_single_choice(y_prob, y_true):
y_pred = torch.max(y_prob, dim=-1)[1]
score = torch.sum((y_pred == y_true).long())
return {"accuracy": torch.true_divide(score, y_true.size(0)).item(),
"y_pred": y_pred,
"score": score.item(),
}
# @param model_name : str
# @param train_logging_dataframe : pandas.DataFrame[epoch, iteration, loss, accuracy]
# @param dev_logging_dataframe : pandas.DataFrame[epoch, accuracy]
# @param train_plot_export_path : str
# @param dev_plot_export_path : str
# Plot single-choice by logging
def plot_single_choice(model_name, train_log_dataframe, dev_log_dataframe, train_plot_path, dev_plot_path):
if train_log_dataframe is not None:
plt.rcParams["figure.figsize"] = (12., 9.)
epochs = train_log_dataframe["epoch"]
losses = train_log_dataframe["loss"]
accuracies = train_log_dataframe["accuracy"]
# aggregate_dataframe = train_logging_dataframe.groupby("epoch").mean()
# plt.plot(aggregate_dataframe.index, aggregate_dataframe["loss"], label="loss")
# plt.plot(aggregate_dataframe.index, aggregate_dataframe["accuracy"], label="accuracy")
# plt.xlabel("epoch")
# plt.ylabel("metric")
# plt.title(f"Train Plot for {model_name}")
# plt.legend()
# plt.show()
xs = numpy.linspace(0, epochs.max(), len(epochs))
figure = plt.figure(1)
host = HostAxes(figure, [0.15, 0.1, .65, 0.8])
par1 = ParasiteAxes(host, sharex=host)
host.parasites.append(par1)
host.set_ylabel("loss")
host.set_xlabel("epoch")
host.axis["right"].set_visible(False)
par1.axis["right"].set_visible(True)
par1.set_ylabel('accuracy')
par1.axis["right"].major_ticklabels.set_visible(True)
par1.axis["right"].label.set_visible(True)
figure.add_axes(host)
p1, = host.plot(xs, losses, label="loss")
p2, = par1.plot(xs, accuracies, label="accuracy")
par1.set_ylim(0, 1.2)
host.axis["left"].label.set_color(p1.get_color())
par1.axis["right"].label.set_color(p2.get_color())
host.set_xticks(list(range(max(epochs) + 1)))
host.legend()
plt.title(f"Train Plot for {model_name}")
if train_plot_path is None:
plt.show()
else:
plt.savefig(train_plot_path)
plt.close()
if dev_log_dataframe is not None:
epochs = dev_log_dataframe["epoch"]
accuracies = dev_log_dataframe["accuracy"]
plt.plot(epochs, accuracies, label="accuracy")
plt.xlabel("epoch")
plt.ylabel("metric")
plt.title(f"Valid Plot for {model_name}")
plt.legend()
if dev_plot_path is None:
plt.show()
else:
plt.savefig(dev_plot_path)
plt.close()
20231022
- 这是一个群星璀璨的时代!!!!!!!!!!!
- 嘉伟今早上马10k精英赛跑出令人咋舌的36’25",均配3’38",这比他上个月在129测的17’35"的5000米还要硬,要知道他之前的10k个人最佳还是在去年市运会前在跑步机上跑出来的37分半,去年的高百接力的10k也不过刚刚进39分,没想到不到一年又有如此恐怖的提升,完全看不到他的极限在哪里,我昨天跟崔洲宸跑完觉得嘉伟地位或受威胁,还是我太幼稚,一直以为嘉伟已经触及瓶颈,但进步的速度依然惊人,说不定哪一天5000米就破开17分钟直冲二级了。
- 另外今早AK的江阴半马净成绩1:16:58,均配3’38",比嘉伟还强,你宽哥还是你宽哥,虽然AK之前的PB是1小时13分,这个配速不过是他全马PB的配速而已;胡鑫宇的苏州太湖半马1:36:12,因为有隧道和山,发挥真的很稳定。
- AK一如既往的稳定发挥,他周六甚至还去环球金融中心参加了爬楼比赛(80层),而这周末他将前往浙江台州参加柴古唐斯越野赛,这场越野赛最低的组别是26km,爬升有800米,最高的组别是115km,将持续超过一天时间,爬升达到1300米+,不得不说AK真的是太猛了。
stata读excel表,按excel默认的编号,改名,删列
import excel "全国2023年第2季度原始数据.xlsx",clear firstrow
rename A loginName
rename B firmName
rename C firmOrg // 企业所属组织
rename D firmProvince
rename E firmIndustry
drop W FQl FQl RCEP RCEPFQl AA AB
20231023
- 晚上回来慢跑遇嘉伟,陪他散了会儿步,当然我说的是嘉伟在散步,我已经几近使出全力,最后是42分整的10km(对于社畜来说已经很努力了,如果不是遇到嘉伟我打算摇个10圈就溜了),嘉伟又补了五圈到12km,他现在定了课表在在认真按计划训练(一三五LSD堆跑量,周二周六队内训练,周四129团练,周日跑休练力量),备战十二月的上马,嘉伟是真的动真格了。
- 昨晚后来遇到徐瀚韬问他是否要比5000米,他似乎并无此意,依然是报了1500米,李乐康今天也跟我说不回来参加校运会了,因此主要对手仍然是宋镇均和叶赵志,这两人水平隐约在我之上,目前我全盛状态下预计5000米进19分半,10000米能进41分钟。
- 说句心里话,虽然这两年饮食睡眠都没有好好控制,训练也是三天打鱼、两天晒网,但总归感觉水平是比两年前最巅峰的时期要稍许强些,我的身体素质和身体条件都是相当一般,没有嘉伟那样瘦削的身材和超长的跟腱,从小体育无能,即便现在我每天都坚持睡前做核心腰腹训练,每周坚持一天力量训练,每天坚持一定的跑量,也注定达不到嘉伟的高度,嘉伟这两年平均配速提升了30多秒,我只提升了5秒不到,但是我现在也不希望真的瘦到嘉伟那种程度,70kg对我来说刚刚好,如果一定要减重的代价以获取更好的成绩,我宁可选择平庸,人生就是这样一个权衡得失的过程。
modelscope@pipeline,转载自https://modelscope.cn/docs/
from modelscope.pipelines import pipeline
word_segmentation = pipeline('word-segmentation')
input_str = '今天天气不错,适合出去游玩'
print(word_segmentation(input_str))
# 输出
{'output': '今天 天气 不错 , 适合 出去 游玩'}
inputs = ['今天天气不错,适合出去游玩','这本书很好,建议你看看']
print(word_segmentation(inputs))
# 输出
[{'output': ['今天', '天气', '不错', ',', '适合', '出去', '游玩']}, {'output': ['这', '本', '书', '很', '好', ',', '建议', '你', '看看']}]
inputs = ['今天天气不错,适合出去游玩','这本书很好,建议你看看']
# 指定batch_size参数来支持批量推理
print(word_segmentation(inputs, batch_size=2))
# 输出
[{'output': ['今天', '天气', '不错', ',', '适合', '出去', '游玩']}, {'output': ['这', '本', '书', '很', '好', ',', '建议', '你', '看看']}]
from modelscope.msdatasets import MsDataset
from modelscope.pipelines import pipeline
inputs = ['今天天气不错,适合出去游玩', '这本书很好,建议你看看']
dataset = MsDataset.load(inputs, target='sentence')
word_segmentation = pipeline('word-segmentation')
outputs = word_segmentation(dataset)
for o in outputs:
print(o)
# 输出
{'output': ['今天', '天气', '不错', ',', '适合', '出去', '游玩']}
{'output': ['这', '本', '书', '很', '好', ',', '建议', '你', '看看']}
from modelscope.models import Model
from modelscope.pipelines import pipeline
model = Model.from_pretrained('damo/nlp_structbert_word-segmentation_chinese-base')
word_segmentation = pipeline('word-segmentation', model=model)
input = '今天天气不错,适合出去游玩'
print(word_segmentation(input))
{'output': ['今天', '天气', '不错', ',', '适合', '出去', '游玩']}
from modelscope.models import Model
from modelscope.pipelines import pipeline
from modelscope.preprocessors import Preprocessor, TokenClassificationTransformersPreprocessor
model = Model.from_pretrained('damo/nlp_structbert_word-segmentation_chinese-base')
tokenizer = Preprocessor.from_pretrained(model.model_dir)
# Or call the constructor directly:
# tokenizer = TokenClassificationTransformersPreprocessor(model.model_dir)
word_segmentation = pipeline('word-segmentation', model=model, preprocessor=tokenizer)
input = '今天天气不错,适合出去游玩'
print(word_segmentation(input))
{'output': ['今天', '天气', '不错', ',', '适合', '出去', '游玩']}
20231024
matplotlib设置坐标轴标签
import matplotlib
from matplotlib import pyplot as plt
matplotlib.rc("font",family='MicroSoft YaHei',weight="bold") # 设置中文字体
%matplotlib inline
plt.plot(range(res.shape[0]), res["count"], label="count")
plt.plot(range(res.shape[0]), res["mean"], label="mean")
plt.xticks(ticks=range(res.shape[0]), labels=educations_by_level) # ticks是默认的第一个参数,可以不加keyword augment,但是如果要使用labels,必须带ticks,此时ticks和labels长度一致,且可以比实际数据的长度少
plt.legend()
plt.show()
简单插次坐标轴,以前用的是mpl_toolkits里的工具:
from matplotlib import pyplot as plt
from mpl_toolkits.axisartist.parasite_axes import HostAxes, ParasiteAxes
figure = plt.figure(1)
host = HostAxes(figure, [.15, .1, .65., .8]) # 主轴对象host
par1 = ParasiteAxes(host, sharex=host) # 与host共享x轴的par1
host.parasites.append(par1) # 主轴添加par1
host.set_ylabel("loss")
host.set_ylabel("epoch")
host.axis["right"].set_visible(False) # host不显示右侧坐标轴
par1.axis["right"].set_visible(True) # par1显示右侧坐标轴
par1.set_ylabel("accuracy")
par1.axis["right"].major_ticklabels.set_visible(True) # 显示par1右侧坐标轴主要的tick
par1.axis["right"].label.set_visible(True) # 显示par1右侧坐标轴的label
figure.add_axes(host)
p1, = host.plot(xs, losses, label="loss")
p2, = par1.plot(xs, accuracys, labels="accuracy")
par1.set_ylim(0, 1.2)
host.set_xticks(range(max(epochs) + 1))
host.legend()
plt.show()
发现可以直接用matplotlib自带的twinx函数:
import numpy as np
import matplotlib.pyplot as plt
# 构造数据
t = np.arange(0.01, 10.0, 0.01)
data1 = np.exp(t)
data2 = np.sin(2 * np.pi * t)
# 第一个子图
ax1 = plt.gca() # get current axis,拿到坐标轴
ax1.set_xlabel('time (s)') # 设置坐标轴
ax1.set_ylabel('exp', color='r') # 设置坐标轴
ax1.plot(t, data1, color='r') # 折线图y = exp(x)
ax1.tick_params(axis='y', labelcolor='r') # 设置x轴的tick属性
ax2 = ax1.twinx() # 创建与ax1共享x轴的第二个子图
ax2.set_ylabel('sin', color='b') # 折线图y = sin(x)
ax2.plot(t, data2, color='b')
ax2.tick_params(axis='y', labelcolor='b') # 设置x轴的tick属性
另外发现不知为何最新版pandas不接受直接创建空dataFrame了:
import pandas as pd
df = pd.DataFrame(np.full((10, 5), np.nan), columns=range(5), index=range(10)) # 会报错:object has no attribute dtype
报错原因大概是此时dataframe里的数据都是object类型,没有属性dtype
现在只能手动创建全部都是缺失值的dataframe了
import pandas as pd
import numpy as np
df = pd.DataFrame(np.full((10, 5), np.nan), columns=range(5), index=range(10))
20231025
- 晚上6000米+30个×8组负重箭步(15kg),本来很累只想5分配慢摇,但3000米被一个穿校队服的瘦猴超了,这我能忍?跟了他一段,就把他带崩了,这家伙不到3000米就下场了,均配410,属实拉垮,但应该是个新生,还是很有提升空间的,本想拉他进队,但估计应该是别的校队成员,就算了。跑完来了精神,补了力量训练,比较到位的一晚,现在15kg其实比较轻松,即便身体很疲劳也能坚持完8组,但换20kg又太吃力。
- 嘉伟已经成功中签上马,期望他首马破三。高百上海站接力赛已定于11月11日在海湾森林公园举行,形式是16人×10km路跑,那地方也没比滴水湖近多少,从学校过去贼费事,但我其实挺想去跑的,但是今年队里想去跑的人很多,虽然除了崔洲宸和嘉伟,其他人都远不如我,只是想去凑个热闹,主要看马协的态度,因为今年跟21年不同,21年下半年因为疫情根本没有马拉松赛可参加,所以马协的校友大佬都来跑高百了,今年每周末都有赛事,他们不一定来得了,到时候队里还是得出人补齐16个名额的。毕竟是线下赛,2021年疫情期间尚且办的很满意,今年还是挺值得期待的。
modelscope@train
from modelscope.msdatasets import MsDataset
# 载入训练数据,数据格式类似于{'sentence1': 'some content here', 'sentence2': 'other content here', 'label': 0}
train_dataset = MsDataset.load('clue', subset_name='afqmc', split='train')
# 载入评估数据
eval_dataset = MsDataset.load('clue', subset_name='afqmc', split='validation')
from modelscope.utils.hub import read_config
# 上面的model_id
config = read_config(model_id)
print(config.pretty_text)
# 使用该模型适配的预处理器sen-sim-tokenizer
cfg.preprocessor.type='sen-sim-tokenizer'
# 预处理器输入的dict中,句子1的key,参考上文加载数据集中的afqmc的格式
cfg.preprocessor.first_sequence = 'sentence1'
# 预处理器输入的dict中,句子2的key
cfg.preprocessor.second_sequence = 'sentence2'
# 预处理器输入的dict中,label的key
cfg.preprocessor.label = 'label'
# 预处理器需要的label和id的mapping
cfg.preprocessor.label2id = {'0': 0, '1': 1}
# num_labels是该模型分类数
cfg.model.num_labels = 2
# 修改task类型为'text-classification'
cfg.task = 'text-classification'
# 修改pipeline名称,用于后续推理
cfg.pipeline = {'type': 'text-classification'}
# 设置训练epoch
cfg.train.max_epochs = 5
# 工作目录
cfg.train.work_dir = '/tmp'
# 设置batch_size
cfg.train.dataloader.batch_size_per_gpu = 32
cfg.evaluation.dataloader.batch_size_per_gpu = 32
# 设置learning rate
cfg.train.optimizer.lr = 2e-5
# 设置LinearLR的total_iters,这项和数据集大小相关
cfg.train.lr_scheduler.total_iters = int(len(train_dataset) / cfg.train.dataloader.batch_size_per_gpu) * cfg.train.max_epochs
# 设置评估metric类
cfg.evaluation.metrics = 'seq-cls-metric'
# 这个方法在trainer读取configuration.json后立即执行,先于构造模型、预处理器等组件
def cfg_modify_fn(cfg):
cfg.preprocessor.type='sen-sim-tokenizer'
cfg.preprocessor.first_sequence = 'sentence1'
cfg.preprocessor.second_sequence = 'sentence2'
cfg.preprocessor.label = 'label'
cfg.preprocessor.label2id = {'0': 0, '1': 1}
cfg.model.num_labels = 2
cfg.task = 'text-classification'
cfg.pipeline = {'type': 'text-classification'}
cfg.train.max_epochs = 5
cfg.train.work_dir = '/tmp'
cfg.train.dataloader.batch_size_per_gpu = 32
cfg.evaluation.dataloader.batch_size_per_gpu = 32
cfg.train.dataloader.workers_per_gpu = 0
cfg.evaluation.dataloader.workers_per_gpu = 0
cfg.train.optimizer.lr = 2e-5
cfg.train.lr_scheduler.total_iters = int(len(train_dataset) / cfg.train.dataloader.batch_size_per_gpu) * cfg.train.max_epochs
cfg.evaluation.metrics = 'seq-cls-metric'
# 注意这里需要返回修改后的cfg
return cfg
from modelscope.trainers import build_trainer
# 配置参数
kwargs = dict(
model=model_id,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
cfg_modify_fn=cfg_modify_fn)
trainer = build_trainer(default_args=kwargs)
trainer.train()
from modelscope.msdatasets import MsDataset
# 载入评估数据
eval_dataset = MsDataset.load('clue', subset_name='afqmc', split='validation')
from modelscope.trainers import build_trainer
# 配置参数
kwargs = dict(
# 由于使用的模型训练后的目录,因此不需要传入cfg_modify_fn
model='/tmp/output',
eval_dataset=eval_dataset)
trainer = build_trainer(default_args=kwargs)
trainer.evaluate()
from modelscope.msdatasets import MsDataset
# 载入评估数据
eval_dataset = MsDataset.load('clue', subset_name='afqmc', split='validation')
from modelscope.trainers import build_trainer
# 配置参数
kwargs = dict(
# 由于使用的模型训练后的目录,因此不需要传入cfg_modify_fn
model='/tmp/output',
eval_dataset=eval_dataset)
trainer = build_trainer(default_args=kwargs)
trainer.evaluate()
20231026
- 晚上回来,计划是去蜀地源暴食一顿,但是之前我都要先练一会儿,以防负罪感太深。去操场想起今晚队里例训,果然人都在,东哥得知我饿着肚子,便赏了我块烧饼,让我带大一小朋友跑了12圈变速(嘉伟、宋某、崔洲宸都去了129,所以队里中长跑已经是我最强了),小朋友水平还是有待开发,连我这种下班穿着衬衫平底鞋来练的人都跟不上,而且为了照顾卢星雨和丁古丽,我快圈只带了1’30",慢圈2’30",他们有两个连卢星雨都跑不过,我仿佛看到了自己刚进队的样子。
- 后来又陪着练了俯身两头起和背部的力量训练,以及两组核心训练,最后陪卢星雨放松跑了3圈,结束已经8点50,比较到位的一晚,成功省了一顿饭钱。
- 说实话如果不是卢星雨在,我可能带完变速就去大快朵颐了,比队里大一大二的小朋友至少也大个六七岁,实在是没啥可谈,虽然跟她也交集也少,但是至少认知水平是相近的,说的东西也都能听得懂,而且跟女生跑不会累,边练边说会儿也开心些。白天我也都是跟宝玺姐一起吃饭行动,身边其他都是三十多岁的大哥大姐,有丁克、有刚婚假蜜月从欧洲回来的、有家人都移民的、还有一周五天在北上广深杭五个地方的,认知完全不在一个档次上,我觉得我说话会被觉得幼稚(还有一个关键就是我们的专业差太多,如果谈论技术,我还是有话可说,但是谈论金融就只能纸上谈兵,level差太多了)。所以我还是挺佩服卢星雨,每年新生入队她都能很快融入新生群体,今年入队的已经小她六岁了,对我来说六岁已经是很大的代沟了。
Firefox浏览器selenium配置(转载自https://blog.csdn.net/u010451638/article/details/109580906)
from selenium import webdriver
from selenium.webdriver.common.proxy import *
'''
#这种方法在py3好像有点问题隐藏了
# 代理
myProxy = '202.202.90.20:8080'
# 代理格式
proxy = Proxy({
'proxyType': ProxyType.MANUAL,
'httpProxy': myProxy,
'ftpProxy': myProxy,
'sslProxy': myProxy,
'noProxy': ''
})
profile = webdriver.FirefoxProfile()
profile = get_firefox_profile_with_proxy_set(profile, proxy)
'''
ip = '27.44.221.62:4213'
ip_ip = ip.split(":")[0]
ip_port = int(ip.split(":")[1])
profile = webdriver.FirefoxProfile()
profile.set_preference('network.proxy.type', 1) # 默认值0,就是直接连接;1就是手工配置代理。
profile.set_preference('network.proxy.http', ip_ip)
profile.set_preference('network.proxy.http_port', ip_port)
profile.set_preference('network.proxy.ssl', ip_ip)
profile.set_preference('network.proxy.ssl_port', ip_port)
profile.update_preferences()
driver = webdriver.Firefox(profile)
profile.set_preference("general.useragent.override", user_agent)
# firefox无头模式
options = webdriver.FirefoxOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('window-size=1200x600')
executable_path = os.path.abspath('geckodriver.exe')
driver=webdriver.Firefox(proxy=proxy, profile=profile,
options=options, executable_path=executable_path)
driver.get('https://www.baidu.com')
driver.quit()
options = webdriver.FirefoxOptions()
# 不加载图片,加快访问速度
#options.set_preference('permissions.default.image',2)
# 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium 火狐好像不用设置
#options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 添加本地代理
## 第二步:开启“手动设置代理”
options.set_preference('network.proxy.type', 1)
## 第三步:设置代理IP
options.set_preference('network.proxy.http', '221.180.170.104')
## 第四步:设置代理端口,注意端口是int类型,不是字符串
options.set_preference('network.proxy.http_port', 8080)
# 添加UA
#ua = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
#options.add_argument('user-agent=' + ua)
driver = webdriver.Firefox(options=options)
20231027~20231028
- 下午嘉伟4分配带LSD(实际3’57"),一共16km,带的非常稳,他新买了nike vapofly,现在价格已经跌倒七八百了。我跟了前5000米,19’34",后面实在是跟不住,基本上是跑两圈歇一圈,加起一共跟了26圈,非常极限,但嘉伟依然游刃有余,以他目前的水平,全马破三并不是很困难的事情,他现在半马有120的水平,对应全马是255,如果他最后一个月还能继续突破,甚至有可能首马打开250。
- 今天凌晨柴骨唐斯越野开赛,AK是55km组,中途有两座山要上下,一共爬升2200米,最后以41名完赛(1200人),129的查敏(人称五哥)跑了55km组第5名,用时5小时38分(大部分人这个时间平地上都跑不完55km,相当于1小时10km的速度连跑5个多小时,爬升2200米,这是多么恐怖的体能),AK用了6小时50分才跑完(第二座山跑崩),事实上就全马成绩,五哥不会比AK快超过20分钟,但是越野确实太吃策略和经验,我经常爬楼梯深有体会,可能前十层能一口气三级三级台阶冲上去,但是一旦到达心肺阈值,就只能一步一步往上走,很难保持匀速爬完几十层楼,更何况坡度起伏的越野赛,平地跑55km都不见得能跑完,何况55km的跑山。而柴古唐斯还有85km(爬升4000米+)和115km(爬升6000米+)两个组别,加起来的参赛人数也有近2000人,能参加的都是跑者中最精英的一批人,全马成绩至少都是250以内,另外有90人参加了26km(爬升800米)的组别,即便是最低的组别,对于我们这种业余跑者也极其困难。因此半马全马不过入门而已,能跑越野才是真正的登堂入室。
xpath如何取包含多个class属性
如果html结构是这样
<div class="demo"></div>
那么我知道可以写xpath //div[@class="demo"],但是如果我的html是
<div class="test demo"></div>
<div class="demo test"></div>
<div class="test demo2"></div>
我只想选出有demo这个class的对象,那应该怎么弄
要取多个class属性值的元素,应该如何办呢;
如:
<div class='a b'>test</div>
如果是用xpath(‘//div[@class=“a”]’) 会取不到这里面的值;
可以用如下的表达式:
xpath('//div[contains(@class,"a")]') #它会取得所有class为a的元素
或者
xpath('//div[contains(@class,"a") and contains(@class,"b")]') #它会取class同时有a和b的元素
如果没记错的话可以这么来:
//div[contains(@class, 'demo')]
如果是多个则可以:
//div[contains(@class, 'demo') and contains(@class, 'other')]
如果目标 class 不一定是第一个,那么:
//div[contains(concat(' ', @class, ' '), 'demo')]
20231030
- AK瘫了两天,但依然坚持周一上班,身残志坚,吾辈楷模。看了他分享的照片,真的是太燃了,柴古唐斯,这辈子我一定要去一次(但我们现在根本连报名的资格都没有)。
- 昨晚去散步陪MBA的人跑了六七公里,他们在跑LSD,比较慢,圈速1’57"上下,对我来说就是放松跑,穿个白衬衫和平底鞋也非常轻松。其实我并不在MBA的跑圈群里,但是他们有不少人都认识我,听到有人喊那个穿白衬衫的小哥哥很快的(我上周日陪花姐跑了一下,花姐是公认的上财MBA女子第一人,全马PB250,水平在我之上,但是我不好意思跟着女性跑,觉得丢人,所以我在外道隔了两根道陪她跑了十几圈,400配速,跑的我累死),也是沾了AK和嘉伟的光。
- 今晚田径场已经封场,跑休,明天就是校运会,看起来这次搞得还挺隆重。最后一次,嘉伟、宋某、炳杰都不在,嘉伟大概是想把机会留给新人,否则他来冠军就没悬念了(他今年一项都没有报,他从400~5000,报啥都是稳稳的冠军),炳杰出差来不了,宋镇均就是纯懒,我都不想谈,他要是明天出现在起跑线,我就把他嘴抽烂。如果没有黑马的话,这次很有机会冲击亚军(只输一手崔洲宸,年轻人太硬了),上半年毕竟赛前一周扭伤,停跑近十天,比赛只跑了20’56",太过遗憾,这次赛前一周的训练整体来说还是比较到位的,及格线是跑进20分钟,希望往19分冲一冲,2021年12月之后就再也没有刷新过任何PB,身体这么快就老了么?或许,谁知道呢。
一个小的冷僻点,dataframe[column].sum(),如果这一列是字符串类型的,求和的效果是把字段全部拼起来。
常用的xpath路径表达式:
| 表达式 | 描述 | 实例 |
|---|---|---|
| nodename | 选取nodename节点的所有子节点 | xpath('//div’) |
| 选取了div节点的所有子节点 | / | |
| 从根节点选取 xpath('/div’) 从根节点上选取div节点 | ||
| // | 选取所有的当前节点,不考虑他们的位置 | |
| xpath('//div’) | 选取所有的div节点 | |
| . | 选取当前节点 | xpath('./div’) |
| 选取当前节点下的div节点 | ||
| … | 选取当前节点的父节点 | |
| xpath('…’) | 回到上一个节点 | |
| @ | 选取属性 | xpath(’//@calss’) |
20231031
- 我还是老了。
- 其实我真的很兴奋,虽说是人生第二次参加校运会,但是第一次毕竟是带伤跑,那时只是不想错过,这次就算不是全盛状态,也至少有个九成五的状态了,才算是我真正第一次参赛。我早上就兴奋,中午睡不着,起跑前身上从手指麻到小腿,僵硬得不行,起跑时整个人都变形了,特别别扭,都不会跑步了,起手就被甩到第七名,1km用时3’37"上升到第六,我很纳闷这届年轻人这么猛的吗?2km用时7’35",此时我已经上升到第五,但感觉已经崩了,不过其他人比我更崩,3km分段11分30秒,4km结束我被崔洲辰套圈,此时我上升到第三,且完全不知道谁是第二(因为我也套了很多人圈),胡鑫宇跟我说第三应该稳的,我实在太累就放了一些到5分配缓了一下(后来查表发现自己那段心率最高达到了196,已经突破了我现在的最大心率220-26=194,当时就觉得完全不可能再顶得下去,必须降速走一段了),最后300米我听到背后一声咆哮,叶赵志终于超上来了,他在最后200米追上了我,但我们约定最后都不冲刺,携手通过终点线。
- 一个原因是今天太热,十月底居然有28度艳阳直晒,体感肯定是30度以上,我号码牌都被汗淋湿得掉色了。第二个原因是前面冲太猛,导致后面跑崩,以至于我最后一圈都提不了速度冲刺。如果最后能第三拿块牌子就好了,但叶赵志确实是让了我一手,我是肯定冲不过他的。
- 后来晚上遇到嘉伟在堆跑量,12.8km(3’57"/km)+1.6km(3’30"/km)+6.4km(4’08"/km)+1.6km(3’47"/km)+1.6(5’08"/km),量太大了,我跟了大概有3~4km,嘉伟今天一天都没到校运会现场,其实肯定是有隐情的,大概率是感情问题,人之常情,也不便多问。
- 主要成绩记录:李婷玉跳远冠军(4.12米,她是真的NB,身高不到1米6,而且还是女博士,爆发力这么恐怖,但是100米这次她没跑进决赛),男子1500米群英荟萃,三人跑进4’50",徐瀚韬4’44"拿下冠军,崔洲宸4’48"季军,女子3000米丁古丽第三13’14",黄懿嘉冠军13’13"(咬得很紧),胡鑫宇1500米5’16"第六,非常不错了。5000米成绩因为有人有异议今天没有公布。
Xpath谓语:
谓语被嵌在方括号内,用来查找某个特定的节点或包含某个制定的值的节点
实例:
表达式 结果
xpath(‘/body/div[1]’)
选取body下的第一个div节点
xpath(’/body/div[last()]’)
选取body下最后一个div节点
xpath(‘/body/div[last()-1]’) 选取body下倒数第二个div节点
xpath(’/body/div[positon()❤️]’) 选取body下前两个div节点
xpath(‘/body/div[@class]’) 选取body下带有class属性的div节点
xpath(’/body/div[@class=“main”]’) 选取body下class属性为main的div节点
xpath('/body/div[price>35.00]’) 选取body下price元素值大于35的div节点
20231101~20231103
- 这三天特别累,步执突然开始很上心项目,让我有点措手不及。周三休整,去小姨家补了口血,周四回来头都疼了,但还是跑了21圈(4’49"配速诚信有氧,真的完全不累),今天回来头更疼,不得不早睡,但还是补了14圈,4’47"配速,太累太累,眼睛都快睁不开了。
- 崔洲宸这个小伙子,自从校运会5000米冠军后,见人就要吹,已经在高百群、上财马协群、129跑营群里都说了,也没人问他,他就是想炫耀一下,每次都是我校运会18分10秒,还要刻意强调一下套了第二名一圈,其实之前交流就发现,他这个人不太合群,我跟嘉伟经常约他跑,他都不理,后来我们也懒得找他。我水平差就算了,好歹也尊重一下嘉伟,水平至少目前还在他之上,又是他统计学院的学长,有点太目中无人,现在05后太拽,这次高百准备让他跑第一棒,让他好好见识一下长三角高手的水平,好好打磨打磨他,不可否认他的上限很高,将来很可能是会超越嘉伟,但是也得先学会做人。
- 下周末双十一,上海海湾森林公园,高校百英里接力赛上海站,我财今年水平远远超过21年滴水湖之战的水平,希望能拿下前六,剑指全国总决赛。
hotpotqa process script
def hotpotqa_to_dataframe(data_dir: str,
save_dir: str = None,
):
title_to_article = dict()
title_to_article_id = dict()
article_dict = {"id" : list(),
"title" : list(),
"sentences" : list(),
}
question_dict = {"id" : list(), # Str
"question" : list(), # Str
"context" : list(), # Str
"answer" : list(), # Str
"supporting_facts" : list(), # Str
"type" : list(), # Str
"level" : list(), # Str
"source" : list(), # Str: New columns indicating from which data file the sample comes
}
substitude = [(b'\xc2\xa0'.decode("utf8"), ' ')]
def _clean_string(_string):
for _raw, _new in substitude:
return _string.replace(_raw, _new)
article_id = -1
for file_name in os.listdir(data_dir):
if file_name.startswith("hotpot_") and file_name.endswith(".json"):
source = file_name[7:-5] # Extract xxx from hotpot_xxx.json
print(file_name, source)
data = json.load(open(os.path.join(data_dir, file_name)))
for item in data:
id_ = item["_id"] # Str
question = item["question"] # Str
context = item["context"] # List[Str, List[Str]]
answer = item.get("answer") # Str: Maynot in test dataset
supporting_facts = item.get("supporting_facts") # List[Str, Int]: Maynot in test dataset
type_ = item.get("type") # Str: Maynot in test dataset
level = item.get("level") # Str: Maynot in test dataset
for title, sentences in context:
sentences = list(map(_clean_string, sentences))
# It is proved that no '\n' exists in any article sentence, so we can concatenate sentences by '\n' without losing information
article = '\n'.join(sentences)
if not title in title_to_article:
# New title comes
article_id += 1
article_dict["id"].append(article_id)
article_dict["title"].append(article_id)
article_dict["sentences"].append(json.dumps(sentences))
title_to_article[title] = article
title_to_article_id[title] = article_id
else:
# Duplicate title comes
assert article == title_to_article[title], title
if len(context) == 0:
logging.info(id_)
context_easy = '|'.join(list(map(lambda _x: str(title_to_article_id[_x[0]]), context)))
supporting_facts_easy = None if supporting_facts is None else '|'.join(list(map(lambda _x: f"{title_to_article_id[_x[0]]}-{_x[1]}", supporting_facts)))
question_dict["id"].append(id_)
question_dict["question"].append(question)
question_dict["context"].append(context_easy)
question_dict["answer"].append(answer)
question_dict["supporting_facts"].append(supporting_facts_easy)
question_dict["type"].append(type_)
question_dict["level"].append(level)
question_dict["source"].append(source)
article_dataframe = pandas.DataFrame(article_dict, columns=list(article_dict.keys()))
question_dataframe = pandas.DataFrame(question_dict, columns=list(question_dict.keys()))
if save_dir is not None:
with open(os.path.join(save_dir, "hotpot_title_to_article.txt"), 'w', encoding="utf8") as f:
json.dump(title_to_article, f, indent=4)
article_dataframe.to_csv(os.path.join(save_dir, "hotpot_article.txt"), sep='\t', header=True, index=False)
question_dataframe.to_csv(os.path.join(save_dir, "hotpot_question.txt"), sep='\t', header=True, index=False)
return title_to_article, article_dataframe, question_dataframe
20231104~20231105
- 昨天跟队训练,400米×8的间歇,加沙坑箭步跳训练(沙坑弹性小,难度更大),我大概已经4个月没有跑过400米间歇了,第一组1’10",第二组1’14",然后大腿就已经酸麻得完全动不了了,我一共跑了6组,后面基本上是1’15"~1’20",实在顶不下去,宋镇均跑间歇确实猛,8组全部跑进1’10",崔洲宸显然没练过间歇,竟然跑着很吃力,后面的箭步做得也很吃力(这个其实不仅是腿部力量,更重要的核心,否则在沙坑里都站不稳,我就觉得很轻松),他力量上来之后,提升会非常大。
- 今晚嘉伟自测5000米,我为他计时及领跑(我每圈领跑200米,然后沿斜线返回终点线,可惜没有人给他带后200米),AK和李浩然为他录像拍照,胡鑫宇为他清理内道散步的人,第一个1000米用时3’14",3000米用时10’08"(均配3’22"),前9圈维持了1’24"以内的全速,10-12圈掉到1’25"-1’26",最后一圈1’16",最终5000米用时17’08",平均配速3’25"/km,平均心率182bpm,最大心率203bpm,艳压群芳,技惊四座!已经超越了AK巅峰期(强如AK,5000米也不曾打开17分钟,官方PB是大运会的17’10")!不到两个月时间,再次提升近30秒,太可怕太可怕,破开17分指日可待,财大现役中长跑无可争议第一人。
- 校运会5000米最终还是我拿了季军,胜之不武,虽赢但菜,总算是拿到了心心念念的奖牌和证书,可惜无法站台拍照留念,多少有些无奈,不知明年还能否有机会站上赛道。
chatglm3-6b @ https://github.com/THUDM/ChatGLM3
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True, device='cuda')
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好👋!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
>>> print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
20231106~20231108
- 高百备赛,期望可以跑进41分,在校生的出战阵容:陈嘉伟(PB 36’25"),崔洲辰(38分台),宋镇均、胡鑫宇、李乐康、我都是41分台,外带一个稍微差些的李浩然,如果能把李浩然换成AK,这阵容将是绝杀,可惜AK来不了,不然我财今年总决赛必有一席之位。
- 最近很忙,但每天回来精力还是很充沛,周一20圈5分配(前7km心率都压在150以内,最后1km冲了一下也没有突破160,心肺能力确有提升),周二给老板汇报回来的太晚,九点吃了两个鸡肉卷就去冲了两组2000米,配速4’05"和4’20",今晚是4’24"配速的8km,稍微上点强度,全程心率压在170以内。慢跑对我速度能力的提升已经没有太大助益,但可以维持状态,这样很好。
ideatalk自动化脚本
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import os
import time
import logging
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from src.base import BaseCrawler
class IdeaTalkCrawler(BaseCrawler):
urls = {"home": "https://idealab.alibaba-inc.com/chat", # Home URL
}
layout_xpaths = {"safe-alert-button" : "//div[@class=\"safe-introduce-dialog-body-button\"]", # XPath of the button appearing at safe alert box(not always)
"model-cards" : "//div[@class=\"next-slick-list\"]", # XPath of all model cards on home page
"input-box" : "//textarea[@id=\"inputValue\"]", # XPath of the input box for human
"send-button" : "//div[@class=\"send-button\"]", # XPath of the button to send text of input box
"chat-area" : "//div[@class=\"idea-talk-prompted\"]", # XPath of the chat area which contains all the talks (consist of several chat boxes)
"human-box" : "//div[@class=\"prompt-box\"]", # XPath of human chat box
"ai-box" : "//div[@class=\"ChatBox\"]", # XPath of AI chat box
"ai-box-text" : "//div[@class=\"ChatBox\"]//div[@class=\"ChatBox-contents-inner-box-text\"]", # XPath of the text contained in AI chat box
"create-new-button" : "//div[@class=\"idea-talk-record-list-add\"]", # XPath of create new talk
"like-or-dislike-area" : "//div[@class=\"like-or-dislike\"]", # XPath of div tag contains like and dislike icons
# "like-icon" : "//svg[@class=\"next-icon-remote like-icon\"]", # XPath of like icon under AI chat box
# "like-icon" : "//svg[contains(@class, \"like-icon\")]", # XPath of like icon under AI chat box
# "like-icon" : "//div[@class=\"like-or-dislike\"]//svg", # XPath of like icon under AI chat box
# "dislike-icon" : "//svg[@class=\"next-icon-remote dislike-icon\"]", # XPath of dislike icon under AI chat box
# "dislike-icon" : "//svg[contains(@class, \"dislike-icon\")]", # XPath of dislike icon under AI chat box
# "dislike-icon" : "//div[@class=\"like-or-dislike\"]//svg", # XPath of dislike icon under AI chat box
}
model_card_xpaths = {"chatgpt3.5" : "//div[@class=\"next-slick-list\"]//div[@data-index=\"0\"]", # XPath of the first model card (ChatGPT 3.5) on home page
"chatgpt3.5(16k)" : "//div[@class=\"next-slick-list\"]//div[@data-index=\"1\"]", # XPath of the second model card (ChatGLM2) on home page
"vertex" : "//div[@class=\"next-slick-list\"]//div[@data-index=\"2\"]", # XPath of the third model card (Vertex) on home page
"chatglm2" : "//div[@class=\"next-slick-list\"]//div[@data-index=\"3\"]", # XPath of the fourth model card (ChatGLM2) on home page
}
def __init__(self):
super(IdeaTalkCrawler, self).__init__()
# @param driver : WebDriver object
# @param prompt : The question you would like to ask AI
# @param model_name : One of the key in `model_card_xpath`, e.g. "chatgpt3.5(16k)"
def request(self, driver, prompt, model_name):
driver.get(self.urls["home"])
self.check_element_by_xpath(driver, xpath=self.layout_xpaths["model-cards"], timeout=15) # Check if model cards is rendered
self.check_element_by_xpath(driver, xpath=self.layout_xpaths["input-box"], timeout=15) # Check if input box is rendered
self.check_element_by_xpath(driver, xpath=self.layout_xpaths["send-button"], timeout=15) # Check if send button is rendered
try:
driver.find_element_by_xpath(self.layout_xpaths["safe-alert-button"]).click() # Check if alert box is existed
logging.info("Safe alerting!")
except:
logging.info("No safe alerting!")
# Request
driver.find_element_by_xpath(self.model_card_xpaths[model_name]).click() # Click on the given model name
driver.find_element_by_xpath(self.layout_xpaths["input-box"]).send_keys(prompt) # Input the given prompt
driver.find_element_by_xpath(self.layout_xpaths["send-button"]).click() # Click on the button to send the prompt
# Wait for response
self.check_element_by_xpath(driver, xpath=self.layout_xpaths["chat-area"], timeout=30) # Check if chat area is rendered
self.check_element_by_xpath(driver, xpath=self.layout_xpaths["human-box"], timeout=30) # Check if human chat box is rendered
self.check_element_by_xpath(driver, xpath=self.layout_xpaths["ai-box"], timeout=30) # Check if AI chat box is rendered
finish_flag = True # Indicating if AI generation is finished
while finish_flag:
try:
driver.find_element_by_xpath(self.layout_xpaths["like-or-dislike-area"])
finish_flag = False
except:
ai_box_text = driver.find_element_by_xpath(self.layout_xpaths["ai-box-text"]) # Find AI response text element
ai_box_text_inner_html = ai_box_text.get_attribute("innerHTML") # Get inner HTML of the element
response = self.tag_regex.sub(str(), ai_box_text_inner_html).strip("\n\t ").replace('\n', '\\n') # Process response text
if "今天体验次数已用完" in response:
finish_flag = False
# Extract AI response text
ai_box_text = driver.find_element_by_xpath(self.layout_xpaths["ai-box-text"]) # Find AI response text element
ai_box_text_inner_html = ai_box_text.get_attribute("innerHTML") # Get inner HTML of the element
response = self.tag_regex.sub(str(), ai_box_text_inner_html).strip("\n\t ") # Process response text
return response
# @param data_path: EXCEL file of job descriptions
# @param save_path: file path for storing AI response
# @param model_name: defined in model_card_xpaths
def demo(self, model_name="chatgpt3.5(16k)"):
driver = self.initialize_driver(browser="chrome", headless=False, timeout=60)
prompt = "给我讲述一下《基督山伯爵》的故事,500字左右。"
response = self.request(driver, prompt, model_name)
with open(f"d:/answer-{model_name}.txt", 'w', encoding="utf8") as f:
f.write(response)
driver.quit()
20231109~20231110
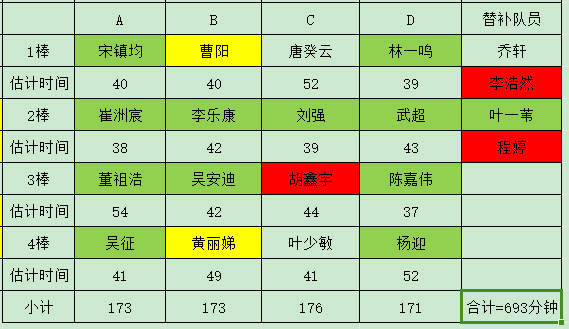
- 事情都是在节骨眼上出问题,胡鑫宇和李浩然大腿拉伤,力量训练太少,加上气温骤降,跑前热身不充分,光腿跑就拉伤了。替补本来就紧张,吴征也有点不近人情,非要胡鑫宇到场,胡哥也有点不高兴,我从中周旋才终于摆平。16个人一起出去旅游尚且丢三落四,何况是一起去跑步呢。想到强风吹拂里灰二凑齐10个人跑箱根是那么困难,当天也会有人出状况,但他们还是克服下来跑完了210km的接力。最后我们在校生出战高百的人是宋某、嘉伟、小崔和我,还有李乐康,我差点忘了这个拽小子。
- 但每个人对于跑步的情感是不同的。我是一个严肃跑者,校运会虽然最终跑进前三,但仍未PB,我5k,10k,半马的PB全部停留在21年12月,我渴望PB,渴望了太久太久,我知道以后真的工作、成家,我这样的条件再不能像那些MBA大佬一样花费大量时间在跑步上,所以我无比渴望在还年轻的时候,看到自己能10k开40分,全马破3的样子。我发现自己越来越不能在日常训练中顶住强度,我只能在赛场上才能找到久违的兴奋感。
- 这次我的状态依然是尚可,尽管每天搬砖,但下班回来都有保持训练量。周一周三有氧8k,周二两组全力2k,周四实验楼上下5组(75层),今天跑休。明天我与宋镇均将作为AB组的第一棒出发,宋某是我老兄弟,水平相近,知根知底,携带彼此再好不过。
- 我还年轻,我是不会放弃的。
chatglm浏览器访问脚本
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import os
import time
import logging
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from src.base import BaseCrawler
class ChatGLMCrawler(BaseCrawler):
urls = {"home": "https://chatglm.cn/", # Home URL
}
layout_xpaths = {# "input-box" : "//textarea[@class=\"scroll-display-none\"]", # XPath of the input box for human
"input-box" : "//div[@class=\"input-box-inner\"]", # XPath of the input box for human
"send-button-1" : "//div[@class=\"enter\"]", # XPath of the button to send text of input box
"send-button-2" : "//img[@class=\"enter_icon\"]", # XPath of the button to send text of input box
"chat-area" : "//div[@id=\"session-container\"]", # XPath of the chat area which contains all the talks (consist of several chat boxes)
"human-box" : "//div[@class=\"pr\"]", # XPath of human chat box
"ai-box" : "//div[@class=\"answer-content-wrap\"]", # XPath of AI chat box
"ai-box-text" : "//div[@class=\"markdown-body\"]", # XPath of the text contained in AI chat box
"create-new-button" : "//div[@class=\"new-session-button\"]", # XPath of create new talk
"like-or-dislike-area" : "//div[@class=\"interact-operate\"]", # XPath of div tag contains like and dislike icons
"delete-session" : "//span[@class=\"btn delete\"]", # XPath of button to delete old talk
}
forbidden_strings = []
def __init__(self):
super(ChatGLMCrawler, self).__init__()
# @param driver : WebDriver object
# @param prompt : The question you would like to ask AI
# @param model_name : One of the key in `model_card_xpath`, e.g. "chatgpt3.5(16k)"
def request(self, driver, prompt):
driver.get(self.urls["home"])
self.check_element_by_xpath(driver, xpath=self.layout_xpaths["input-box"], timeout=15) # Check if input box is rendered
self.check_element_by_xpath(driver, xpath=self.layout_xpaths["send-button-1"], timeout=15) # Check if send button is rendered
self.check_element_by_xpath(driver, xpath=self.layout_xpaths["send-button-2"], timeout=15) # Check if send button is rendered
# Delete old talk
try:
driver.find_element_by_xpath(self.layout_xpaths["send-button-1"]).click()
logging.info("Delete old talk ...")
except:
logging.info("No old talk found ...")
# Request
driver.find_element_by_xpath(self.layout_xpaths["input-box"]).send_keys(prompt) # Input the given prompt
while True:
# The button is dynamic and sometimes fail to click on
try:
driver.find_element_by_xpath(self.layout_xpaths["send-button-1"]).click() # Click on the button to send the prompt
logging.info("Use send button 1 ...")
break
except:
try:
driver.find_element_by_xpath(self.layout_xpaths["send-button-2"]).click() # Click on the button to send the prompt
logging.info("Use send button 2 ...")
break
except:
logging.info("Use send button error ...")
continue
# Wait for response
self.check_element_by_xpath(driver, xpath=self.layout_xpaths["chat-area"], timeout=30) # Check if chat area is rendered
self.check_element_by_xpath(driver, xpath=self.layout_xpaths["human-box"], timeout=30) # Check if human chat box is rendered
self.check_element_by_xpath(driver, xpath=self.layout_xpaths["ai-box"], timeout=30) # Check if AI chat box is rendered
finish_flag = True # Indicating if AI generation is finished
while finish_flag:
try:
# If like or dislike appear, then stop
driver.find_element_by_xpath(self.layout_xpaths["like-or-dislike-area"])
finish_flag = False
except:
ai_box_text = driver.find_element_by_xpath(self.layout_xpaths["ai-box-text"]) # Find AI response text element
# ai_box_text = driver.find_element_by_xpath(self.layout_xpaths["ai-box"]) # Find AI response text element
ai_box_text_inner_html = ai_box_text.get_attribute("innerHTML") # Get inner HTML of the element
response = self.tag_regex.sub(str(), ai_box_text_inner_html).strip("\n\t ").replace('\n', '\\n') # Process response text
forbidden_flags = [forbidden_string in response for forbidden_string in self.forbidden_strings]
if sum(forbidden_flags) > 0:
# It indicates that a forbidden string occurs
finish_flag = False
# Extract AI response text
ai_box_text = driver.find_element_by_xpath(self.layout_xpaths["ai-box-text"]) # Find AI response text element
ai_box_text_inner_html = ai_box_text.get_attribute("innerHTML") # Get inner HTML of the element
response = self.tag_regex.sub(str(), ai_box_text_inner_html).strip("\n\t ") # Process response text
return response
# @param data_path: EXCEL file of job descriptions
# @param save_path: file path for storing AI response
# @param model_name: defined in model_card_xpaths
def demo(self, model_name="chatgpt3.5(16k)"):
driver = self.initialize_driver(browser="chrome", headless=False, timeout=60)
prompt = "给我讲述一下《基督山伯爵》的故事,500字左右。"
response = self.request(driver, prompt)
with open(f"d:/answer-chatglm.txt", 'w', encoding="utf8") as f:
f.write(response)
time.sleep(5)
driver.quit()
20231111~20231112
- 高百净成绩40分12秒,一场等了两年的10km路跑PB
- 21年10月,那时我的场地万米只跑进过一次44分,10月1日自测万米时44分出头,10月3日临时被拉去参加高百,选拔赛即跑崩,46分都没跑进,发奋图强,分别在资格赛跑出21’02"的5000米和决赛43’15"(10km)的PB,此后一发不可收拾,11月参加荧光夜跑活动,跟一个骑自行车刷跑量的哥们儿怄气,连续一周每天一个10km(44分以内),12月份迎来了超级大爆发,先是月初队内测试赛场地5000米PB19’59",中旬自测万米跑出41’15"的PB,下旬操场53圈自测半马,1小时32分40秒,平均配速4’23",前15km均配都维持在4’20"以内,当时觉得太棒了,22年至少能万米打开40分,踏入业余精英的门槛。
- 可是天不遂人愿,疫情的冲击,跑步水平起起落落落落,直到今年暑假与AK、嘉伟坚持1个月强度夏训,才逐渐接近巅峰期,本来上个月底的校运会是奔着5000米PB去跑,希望能冲进19分半,结果前程跑崩连20分都没进,心灰意冷。
- 其实今年水平真的很高,路线是环湖两圈(每圈5km),每圈4座桥,还有一个W型坡,难度非常大,总距离略少于10km(少100米),但难度不会比场地万米简单。队里5人跑进40分,两个女生的成绩45分整和48分出头,总用时11小时7分远远超过21年,但别的学校更是出动了精英主力,交大用时9小时58分(平均每个人37分),都屈居第二,因此还是没能取得理想的名次。我在途中更是被浙大和扬大的女生拉爆,尤其是扬大的女生(谢严乐,我记住她的名字了),看起来很瘦弱,明显是很年轻的本科生,我毕竟也是土生土长的扬州人,没想到扬州也有这么强悍的女生,我跟她撕咬了接近2km,谁也超不过谁,最后竟然是我率先不支,败下阵来,她的成绩是39’37",女子排名第三。
- 我的成绩40’12"在最后512人(每个队16人还包括2个女生)中仅能排名245(有4个女生比我快,比21年好多了),强如嘉伟36’35"也排到72名,这次有接近一半的人都打开了40分大关,太可怕。崔洲宸37’56",宋镇均39’03"发挥出色,李乐康42’12"略微拉胯,另外23级金融专硕吴安迪(本科浙大,这次高百属于是浙大内鬼,才做了2个月上财人)40’55"也很强势,另一个大一新生董祖浩,高中练短跑,这次作为替补上场,10km即跑出47’29",值得鼓励。
关于selenium的expected_condition
- title_is,判断当前页面的标题是否等于预期,返回布尔值
- title_contains(),判断当前页面的标题是否包含预期字符串
- presence_of_element_located() 判断元素是否被加在DOM树里,并不代表该元素一定可见
- visibility_of_element_located() 判断元素是否可见(可见代表元素非隐藏,并且元素的宽和高都不等于0)
- visibility_of() 判断元素是否可见
- presence_of_all_element_located() 判断是否至少有一个元素存在DOM树中
- text_to_be_present_in_element() 判断某个元素中的text是否包含了预期的字符串
- text_to_be_present_in_element_value() 判断某个元素中的value属性是否包含了预期字符串
- frame_to_be_available_and_switch_to_it() 判断该表单是否可以切换进去,如果可以,返回True并switch进去,否则返回False
- invisibility_of_element_located()判断某个元素是否不存在与DOM树中或不可见
- element_to_be_clickable() 判断元素是否可见并是可以点击的,如果元素存在且可点击,则返回元素,如果元素存在但不可点击,则返回False
- staleness_of() 等到一个元素从DOM树中移除,传入element元素,可以判断页面是否刷新了
- element_to_be_selected() 判断某个元素是否被选中,一般用在下拉列表,传入element元素
- element_selection_state_to_be() 判断某个元素的选中状态是否符合预期,方法参数是element和 is_selected
- element_located_selection_state_to_be() 与element_selection_state_to_be()作用一样,只是方法参数不同,方法参数是located和 is_selected
- alert_is_present() 按断页面上是否存在alert警告
20231113~20231114
- 电脑突然变卡,可是才用了两年,检查了一大圈没发现问题,电脑除了微信钉钉,其他装的都是开源软件,而且是全固态硬盘,Legion系列买的时候还是花了7000多,不至于两年就卡成这样,最后觉得肯定硬件问题,拆壳给风扇去灰,CPU抹了点硅油,终于恢复如初。我发誓再也不买垃圾联想游戏本,反正现在PC机也跑不了什么东西,真不如超薄本商务本实在,DELL惠普的用个五六年都不卡,为了支持国货买了两台联想,除了散热好(可是DELL发热也正常用额),电池耐用,其他真心一般,价格也没啥优势。而且游戏本真的不如商务本好使,还贵辣么多。
- 寒冬将至,晚上下班回来冷得要死,都不太想跑(但还是每天晃个十几圈)。这两天发现这边一家哈尔滨老式麻辣烫很好吃,主要是量足,性价比感觉都要比学校麻辣烫高(学校已经从荤素不分23.8元/斤涨到25.8元/斤了,关键是根本没啥荤),但麻辣烫真的不健康,还是少吃了,之前一直都是吃小碗菜,今年比赛都结束了,这两天有点不太节制。
- 26号有空准备陪陈嘉伟去参加上马,给他路上补给,嘉伟高百一战,确实也是有点触动,没想到长三角高手这么多,他在上马10km精英赛以36’25"能排到108名(7000人),但高百36’35"仅排72名(512人),11人破34分钟(二级运动员),29人破35分钟,第一名是来自杭州电子科技大学的章侣楠31’21"(这个都快接近一级运动员水平了),要知道这个比赛是禁止注册运动员参赛,因此这些都是业余跑者,嘉伟在财大可以制霸中长跑,但跟其他学校相比还有很大差距,学校人少,跑步氛围也不够,这么看前年我们上海站第八拿奖纯属侥幸,甚至压了复旦一头,想要在高百赛场上有一席之地,要培养新鲜血液,任重道远。
Levenshtein库内存占用太大,小长度建议自己写带缓存的编辑距离函数算,可能大长度的串计算会快一点?
# @param article_path: Data path saving article dataframe
# @param question_path: Data path saving question dataframe
# @param source: List or Str, using to filter question dataframe by column source
# @param batch_size: Batch size of samples at each yield
# @param shuffle: Whether to shuffle question dataframe
# @param use_corrected_context: Whether to use column `context_1`(otherwise `context`), some titles in supporting_facts do not exist in context, simply add them to `context` to get `context_1`
def yield_hotpotqa_batch(article_path: str,
question_path: str,
source: str = None,
batch_size: int = 1,
shuffle: bool = False,
use_corrected_context: bool = True,
):
context_column = "context_1" if use_corrected_context else "context"
# Load data and preprocess data
article_dataframe = pandas.read_csv(article_path, sep='\t', header=0)
article_dataframe["sentences"] = article_dataframe["sentences"].map(json.loads)
question_dataframe = pandas.read_csv(question_path, sep='\t', header=0)
if source is not None:
filter_flag = question_dataframe["source"].isin(source) if isinstance(source, list) else question_dataframe["source"] == source
question_dataframe = question_dataframe[filter_flag].reset_index(drop=True)
if shuffle:
question_dataframe = question_dataframe.sample(frac=1).reset_index(drop=True)
# Easy column value process
def _easy_process(_column, _value):
if _column in ["context", "context_1"]:
_context = list(map(int, _value.split('|')))
_result = list()
for _article_id in _context:
_result.append({"id" : _article_id,
"title" : article_dataframe.loc[_article_id, "title"],
"sentences" : article_dataframe.loc[_article_id, "sentences"],
})
return _result
if _column == "supporting_facts":
_supporting_facts = list(map(lambda _x: tuple(map(int, _x.split('-', 1))), _value.split('|')))
_result = list()
for _article_id, _sentence in _supporting_facts:
_result.append({"id" : _article_id,
"title" : article_dataframe.loc[_article_id, "title"],
"sentence" : _sentence,
})
return _result
assert False, _column
# Yield batch
current_batch_size = 0
batch_data = list()
for i in range(question_dataframe.shape[0]):
id_ = question_dataframe.loc[i, "id"]
question = question_dataframe.loc[i, "question"]
context = question_dataframe.loc[i, context_column]
answer = question_dataframe.loc[i, "answer"]
supporting_facts = question_dataframe.loc[i, "supporting_facts"]
type_ = question_dataframe.loc[i, "type"]
level = question_dataframe.loc[i, "level"]
source = question_dataframe.loc[i, "source"]
batch_data.append({"id" : id_,
"question" : question,
"context" : _easy_process(context_column, context),
"answer" : answer,
"supporting_facts" : _easy_process("supporting_facts", supporting_facts),
"type" : type_,
"level" : level,
"source" : source,
})
current_batch_size += 1
if current_batch_size == batch_size:
yield batch_data
current_batch_size = 0
batch_data = list()
if current_batch_size > 0:
# Final batch
yield batch_data
20231115~20231116
- 最近发现个有趣的问题,准备久违地写篇博客记录一下。
- 我好像终于要感冒了,这两天有点冻着,主要组里好多人一直感冒,感觉国庆回来后,好多人咳嗽就一直没好,之前我还是注意防范的,加上每天锻炼,所以一直没中招,但是最近一下子降到10℃以下,连续三天晚上在下面弄到太晚又不加衣服(主要是懒,就硬冻着),还是顶不太住。
- 年末没有比赛,这周下班回来都是长裤衬衫跑5000米出头,前天是4’38"的均配,昨天是4’19"的均配,外加200个沙坑箭步跳,今晚跟队少许练了会儿,卢星雨忙了半个月回来终于又参加训练了。前5圈都是穿外套5分配开外慢摇热身,5圈后脱外套提到4’05"~4’15",其实并没有什么区别,日常训练条件差些,更能提高水平,冬训本来也不追求速度,维持量即可,而且这个量对于下班回来的状态刚刚好,跑完精神得很,其实完全可以跑更远,但是不想太累了。
- 这周开始坚持每天吊1分钟杆,以提升背部力量(我吊着得时候很难想象我有力量能把自己拉高哪怕10公分),跑了快四年,对训练有些心得,对自己身体也更加了解,知道想要再有突破需要做什么训练。跑步生涯最后的四个梦想:
- 万米跑进40分钟(高百摸到40分钟的大门后,我坚信自己一定可以破开40分钟大关)
- 半马跑进90分钟(需要极好的状态,参加半马比赛的成绩都要比正常水平慢十几分钟,硬实力一定是可以进的)
- 全马跑进3小时(现在的跑量还不支持我完成全马,需要一段时间的跑量训练)
- 最后是跑一次越野或铁三(大铁或标铁,这个一辈子一次就足够了,身体吃不消,但很想要跑一次)。
- 突然被SXY trigger了一下pyq。毕业工作后,职场看到的东西更多,接触的人也更多,生活方式也不同了,以前我见识短,现在相比就更短了。说没有遗憾是假的,也想回到四年前,但人总是要向前看的。
错误记录:ChromeDriver only supports characters in the BMP
原因是send_keys的元素包含了非BMP字符,检查发现:
{"Cathedral of Petr\u00f3polis": "The Cathedral of Saint Peter of Alcantara (Portuguese: \"Catedral de S\u00e3o Pedro de Alc\u00e2ntara\" ), also known as the Cathedral of Petr\u00f3polis, is a Roman Catholic cathedral in Petr\u00f3polis, Brazil.\n The cathedral is dedicated to Saint Peter of Alcantara, the patron saint of Brazil.\n Is also home of the Imperial Mausoleum of the Brazilian Imperial Family."}
中的\u00e3和u00e2,应该是带变音符号的法语字母。
解决方案:使用firefox驱动,或者直接执行JS代码
# 将要执行的代码
JS_ADD_TEXT_TO_INPUT = """var elm = arguments[0], txt = arguments[1];
elm.value += txt;
elm.dispatchEvent(new Event('change'));"""
# 将要输入文本的元素(带有非BMP字符)
browser = webdriver.Chrome()
browser.get()
elem = browser.find_element_by_xxx()
text = "\u00e3\u00e2"
browser.execute(JS_ADD_TEXT_TO_INPUT, elem, text)
另外发现长文本输入会造成阻塞,以至于页面卡死,也是改为执行JS代码:
# driver.find_element_by_xpath(self.layout_xpaths["input-box"]).send_keys(prompt) # Input the given prompt
# When inputting long text, `element.send_keys` maybe blocked
# Use JavaScript or JQuery instead, e.g.
# JavaScript: `document.getElementByTagName(<tagName>).value = <value>`
# JavaScript: `document.getElementById(<idName>).value = <value>`
# JQuery: `$(<xpath>).val(<value>)`
js = f'document.getElementByTagName("textarea").value="{prompt}"'
dirver.execute_script(js)
logging.info(" - ok!")
20231117
- 后来昨晚跟队练蛙跳,陪嘉伟和卢星雨慢摇了会儿,最后发现吴安迪,他在拉25km(他中签上马,小伙子很帅气,浙大保过来的金专,现在中信实习,之前已经完赛过厦马,3小时48分,虽然高百成绩不如我,但是我也只是超常发挥,他硬实力或在我之上),陪他干了最后5k,边跑边聊,很健谈,畅快得很。我主要没换鞋子(因为我根本没打算训练),穿的是冬天的厚硬底鞋,太笨重,不好跑也不好蛙跳,导致我今天大腿酸痛得特别厉害,以至于今晚回来只能6分配速(这回真是养生跑了)摇了10圈。
- 今天是S空间建成纪念日,3~18层每层都有活动兑换奖品,可惜中午要睡觉只玩了自己这层的,换了一杯水果吃。明天陪嘉伟做上马最后一次长距离拉练(计划是4分半的30km,我估计跑不完,主要是怕他一个人跑太无聊,所以陪他练一次),预祝嘉伟成功破三。
EC的使用
# 结合显式等待和EC模块实现元素定位
bd_input = WebDriverWait(driver, 5).until(EC.presence_of_element_located(input_locator))
bd_button = WebDriverWait(driver, 5).until(EC.presence_of_element_located(button_loator))
# 5.操作元素
bd_input.send_keys("【心善渊&Selenium3.0基础】")
sleep(2)
bd_button.click()
字数多,写得太卡了,虽然才写了一个月。
结篇就不写了,更了一篇博客,想说的都写在后记里了。
(END)