逆向案例之X车网
逆向案例之X车网
***用到的知识点:
(1)requests模块和session模块,发起请求
- 什么是session对象?
- 该对象和requests模块用法几乎一致.
- 对于在请求过程中产生了cookie的请求
- 如果该请求是使用session发起的,则cookie会被自动存储到session中.
session = requests.Session()(2)headers头部伪装,随机UA伪装
# UA伪装之随机headers模块
from fake_useragent import UserAgent
headers = {'User-Agent': UserAgent().random,} # 这里的random方法不需要random模块支持(3)md5加密算法,加密数据
# md5加密模块
from hashlib import md5
# 如果需要十六进制的结果与二进制的结果之间的转换,需要的模块
import binascii
# 【1】准备数据
data = '你好' #这里是字符串类型
# 字符串转二进制数据方式一
encode_data = s.encode()
# 字符串转二进制数据方式二
encode_data = b'你好'
# 【2】数据加密
# 构建md5对象
md5_obj = md5()
# 将数据更新到md5算法中进行数据加密 (参数为二进制数据的明文数据)
#(方法一):直接在加密算法中进行转码
md5_obj.update("你好".encode("utf-8"))
md5_obj.update(data.encode("utf-8"))
#(方法二):先将明文数据进行转码,再传入到加密算法中
md5_obj.update(encode_data)
# 【3】数据提取
# 拿到加密字符串 # 十六进制的结果
result_16 = obj.hexdigest()
# 拿到加密字符串 # 二进制的结果
result_2 = obj.digest()
# 拿到加密字符串 # 十六进制的结果与二进制的结果之间的转换 (参数为result_16 或 result_2)
result_change = binascii.unhexlify(result_16)(4)json模块,序列化与反序列化
dataDict = json.loads(decrypt_data.decode())(5)json.dumps()参数之separators
# 是分隔符的意思
# 参数意思分别为不同dict项之间的分隔符和dict项内key和value之间的分隔符
# - 把:和,后面的空格都除去了。
import json
data = {"a": 1, "b": 2}
ret = json.dumps(data, separators=(',', ':'))
print(ret)
# {"a":1,"b":2}(6)URL编码和解码
- 编码
# -*-coding: Utf-8 -*-
# @File : URL编码 .py
# author: Chimengmeng
# blog_url : https://www.cnblogs.com/dream-ze/
# Time:2023/5/21
# 导入parse模块
from urllib import parse
# 构建查询字符串字典
query_string = {
'wd': '爬虫'
}
# 调用parse模块的urlencode()进行编码
result = parse.urlencode(query_string)
# 使用format函数格式化字符串,拼接url地址
url = 'http://www.baidu.com/s?{}'.format(result)
print(url)
# http://www.baidu.com/s?wd=%E7%88%AC%E8%99%AB# -*-coding: Utf-8 -*-
# @File : URL编码 .py
# author: Chimengmeng
# blog_url : https://www.cnblogs.com/dream-ze/
# Time:2023/5/21
from urllib import parse
# 注意url的书写格式,和 urlencode存在不同
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入要搜索的内容:')
# quote()只能对字符串进行编码
query_string = parse.quote(word)
print(url.format(query_string))
# 请输入要搜索的内容:爬虫
# http://www.baidu.com/s?wd=%E7%88%AC%E8%99%AB- 解码
# -*-coding: Utf-8 -*-
# @File : URL编码 .py
# author: Chimengmeng
# blog_url : https://www.cnblogs.com/dream-ze/
# Time:2023/5/21
from urllib import parse
string = '%E7%88%AC%E8%99%AB'
result = parse.unquote(string)
print(result)
# 爬虫【一】分析网站

-
从网址可以看出,这是一个介绍汽车参数的网址
-
那我们逆向它,也就是为了它的参数数据
-
首先我们还是打开开发者工具进行抓包
- 从抓到的包的数量来看,数量有很多,而我们在不尝试的情况下也不知道数据到底在那个包
- 我们逐个包进行分析
- 发现我们想要的数据正是在
config_new_param?......这个包里 - 这个包返回的信息正是我们想要的信息
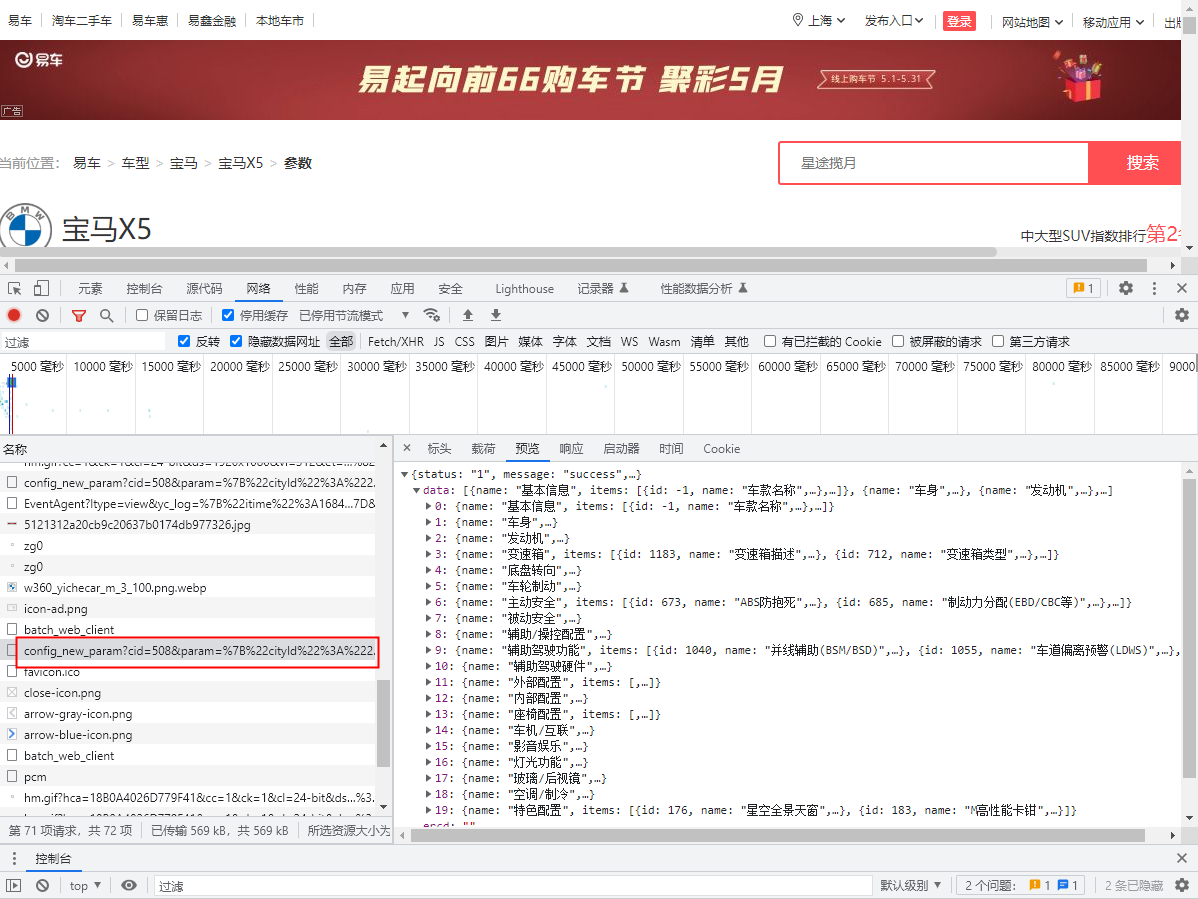
-
按照惯例我们检查这个包的请求头和载荷
-
通过观察我们发现这个请求是 get 请求,而get请求的请求参数一般都是直接拼在url末尾的
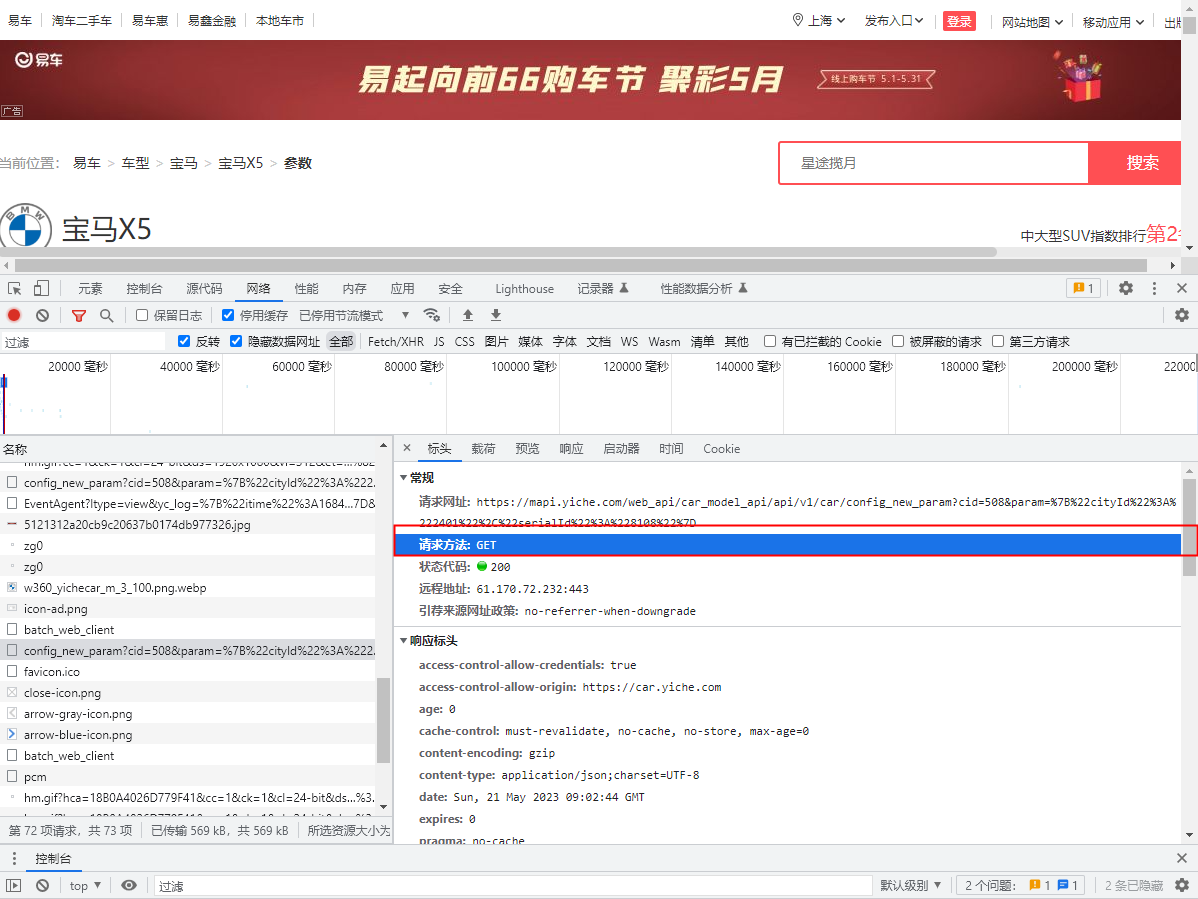
- 我们再观察他的请求头
:authority: mapi.yiche.com
:method: GET
:path: /web_api/car_model_api/api/v1/car/config_new_param?cid=508¶m=%7B%22cityId%22%3A%222401%22%2C%22serialId%22%3A%228108%22%7D
:scheme: https
accept: */*
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9
cache-control: no-cache
content-type: application/json;charset=UTF-8
cookie: CIGUID=93f5a6aa4597abac03dde7ab96b3e3c9; isWebP=true; locatecity=310100; bitauto_ipregion=180.164.67.62%3A%E4%B8%8A%E6%B5%B7%E5%B8%82%3B2401%2C%E4%B8%8A%E6%B5%B7%2Cshanghai; auto_id=044e8069776834cba1d5d72375d6423c; UserGuid=93f5a6aa4597abac03dde7ab96b3e3c9; Hm_lvt_610fee5a506c80c9e1a46aa9a2de2e44=1684637884; selectcity=310100; selectcityid=2401; selectcityName=%E4%B8%8A%E6%B5%B7; Hm_lpvt_610fee5a506c80c9e1a46aa9a2de2e44=1684659764
origin: https://car.yiche.com
pragma: no-cache
referer: https://car.yiche.com/baomax5-8108/peizhi/
sec-ch-ua: "Chromium";v="110", "Not A(Brand";v="24", "Google Chrome";v="110"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
sec-fetch-dest: empty
sec-fetch-mode: cors
sec-fetch-site: same-site
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36
x-city-id: 2401
x-ip-address: 180.164.67.62
x-platform: pc
x-sign: 5272f564ad0e326b85701320d17eb1bc
x-timestamp: 1684659763986
x-user-guid: 93f5a6aa4597abac03dde7ab96b3e3c9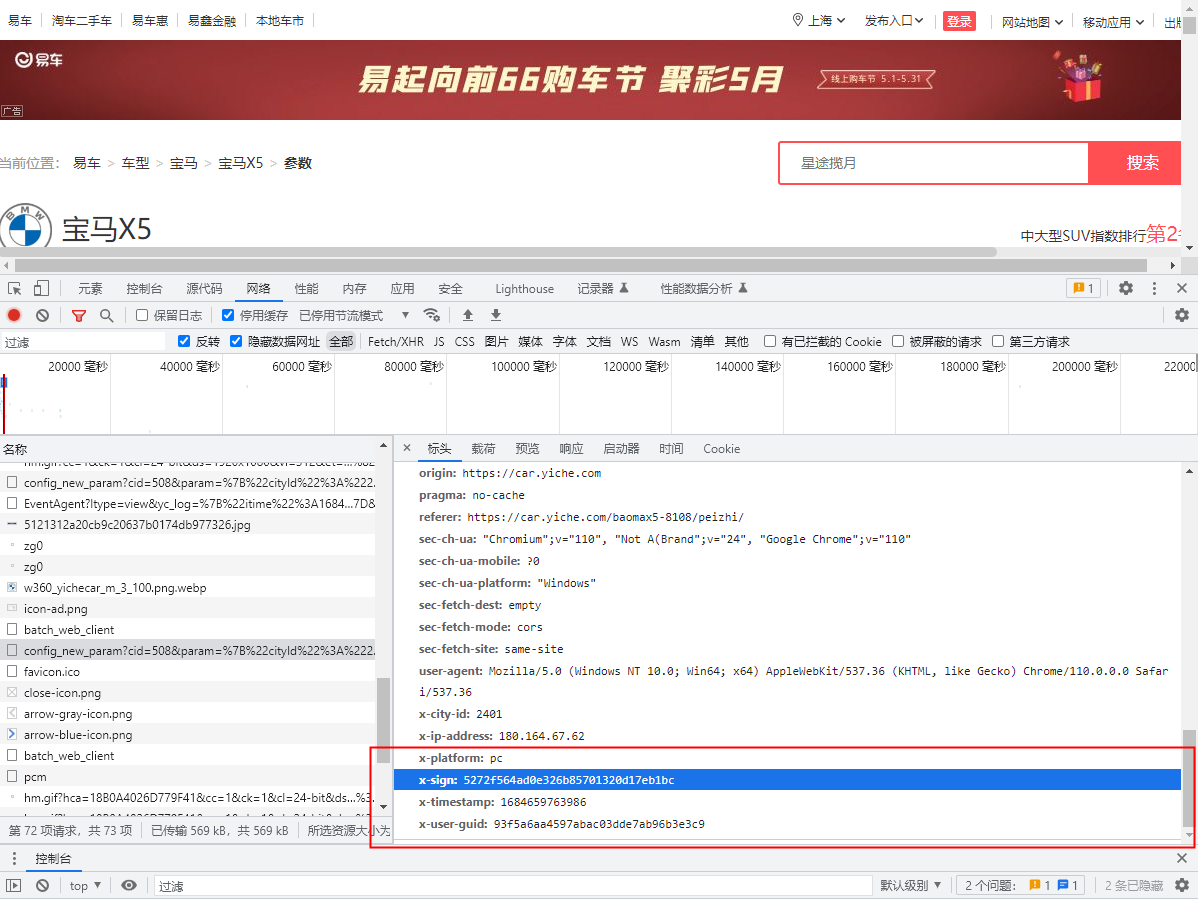
-
通过观察我们发现,他的请求头带着我们以前在post请求常见的 sign 值还有这个熟悉的 time 时间戳的值
-
我们再观察他的载荷数据
cid: 508
param: %7B%22cityId%22%3A%222401%22%2C%22serialId%22%3A%228108%22%7D
-
我们发现这是一堆数字,我们看不明白,但是不要紧
-
这是url进行编码的一种方法
- 目的是为了防止网址传输过程中因为参数携带特殊符号所导致的歧义
-
我们点击 查看源码旁边的视图已解码
cid: 508
param: {"cityId":"2401","serialId":"8108"}
- 这时我们就可以看到他携带的参数了
- 我们也可以通过两个地方的参数进行比较发现
- 他们都有一个共同的参数 2401
【二】逆向寻找参数
- 经过上面的分析,我们可以基本确定会发生变化的值就是我们请求头中的 x-sign 和 x-timestamp 两个参数
- 寻找这两个参数我们还是有两个办法
- 直接搜索关键字
- 通过启动器,一步步寻找调用生成数据的各个函数的方法
- 这里我们采用逆向退函数(启动器往回找)的方法
- 这个方法基本上是不会出错的,全局搜索对于简答的网站逆向是可以的,包括自己有一定经验的
- 我这次采用逆推的方法
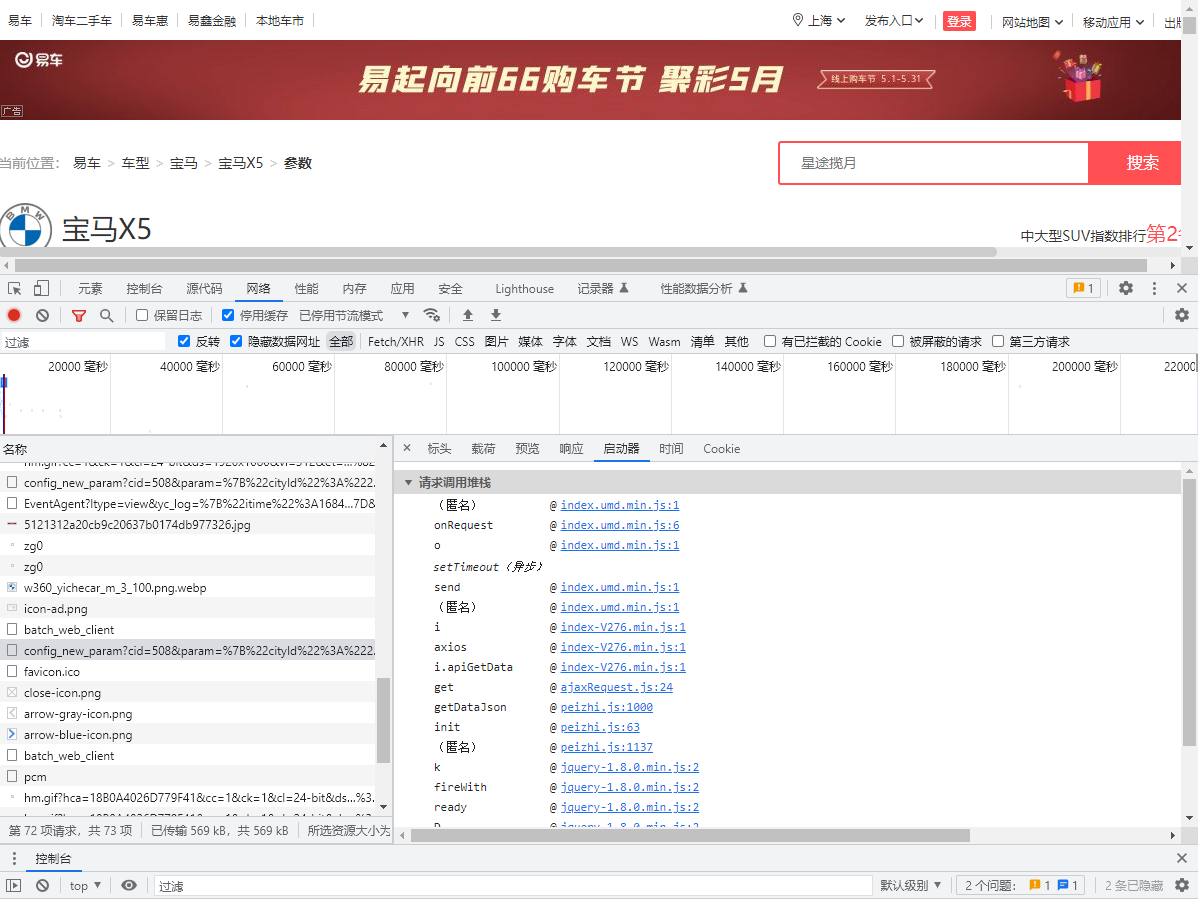
- 我们找到启动器,然后找到第一个函数,点进去找他的调用函数

- 也就是这个函数,我们对其打上断点
- 二次请求观察有没有断住

- 成功断住
- 在这里,我们要特别注意一件事,以往都是,直接定位url关键字从而定位相关的函数,但是这次有所不一样,我们会发现,每次请求过来的网址请求总是在不断的变化
- 那我们就要特别注意我们找到数据包的那个请求url
- 也就是
https://mapi.yiche,com/web api/car model api/api/v1/car/config ne param?
-
通过不断点击让脚本继续执行,我们走到了我们想要的关键参数的这一步函数
-
那么我们就顺着这个请求,去寻找我们想要的参数
-
思路就是
- 我们想要逆向找到的加密参数一定是前后变化特别明显的
- 如果他是一个不变化的定值,那我们逆向他的意义也就不大了
-
顺着这个思路我们一步步向上切换调用堆栈
-
同时要注意在可以的函数之中打上断点,查看数据变化

- 我们逐级向上查看调用堆栈,发现这里有一个很可疑的地方,我们都知道网站会发送Ajax请求,然后返回拿到数据,那我们就先看看这个传过去的s到底是什么
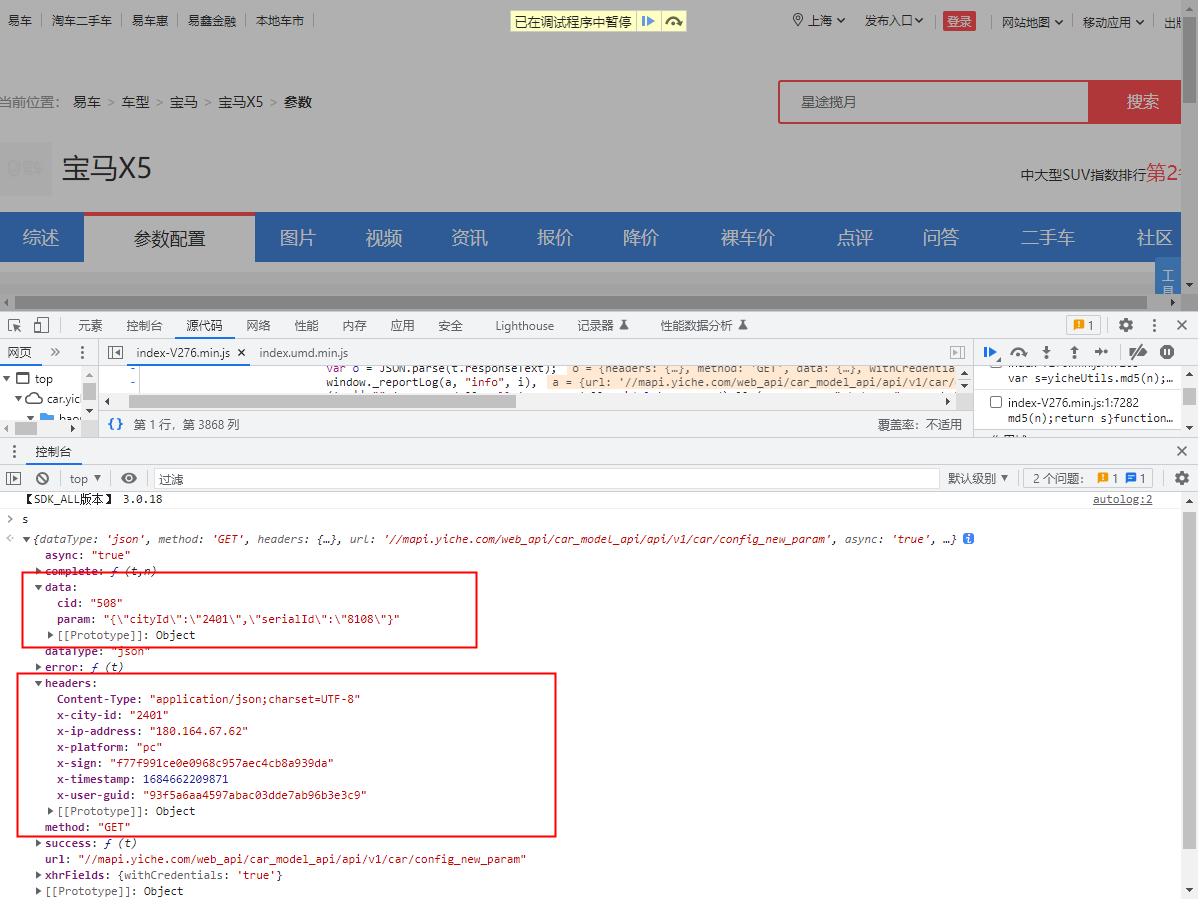
- 我们在控制台打印s可以发现,它是这样一串数据,其中我们要重点关注 data 和 headers 两个参数
- data 一般都是用来存数据的
- headers 是因为我们刚才发现,我们需要的请求参数正是在我们的请求头中的
- 我们打开headers发现里面已经携带了加密好的sign值
- 那我们再向前找一个调用函数,看看sign值是否变化
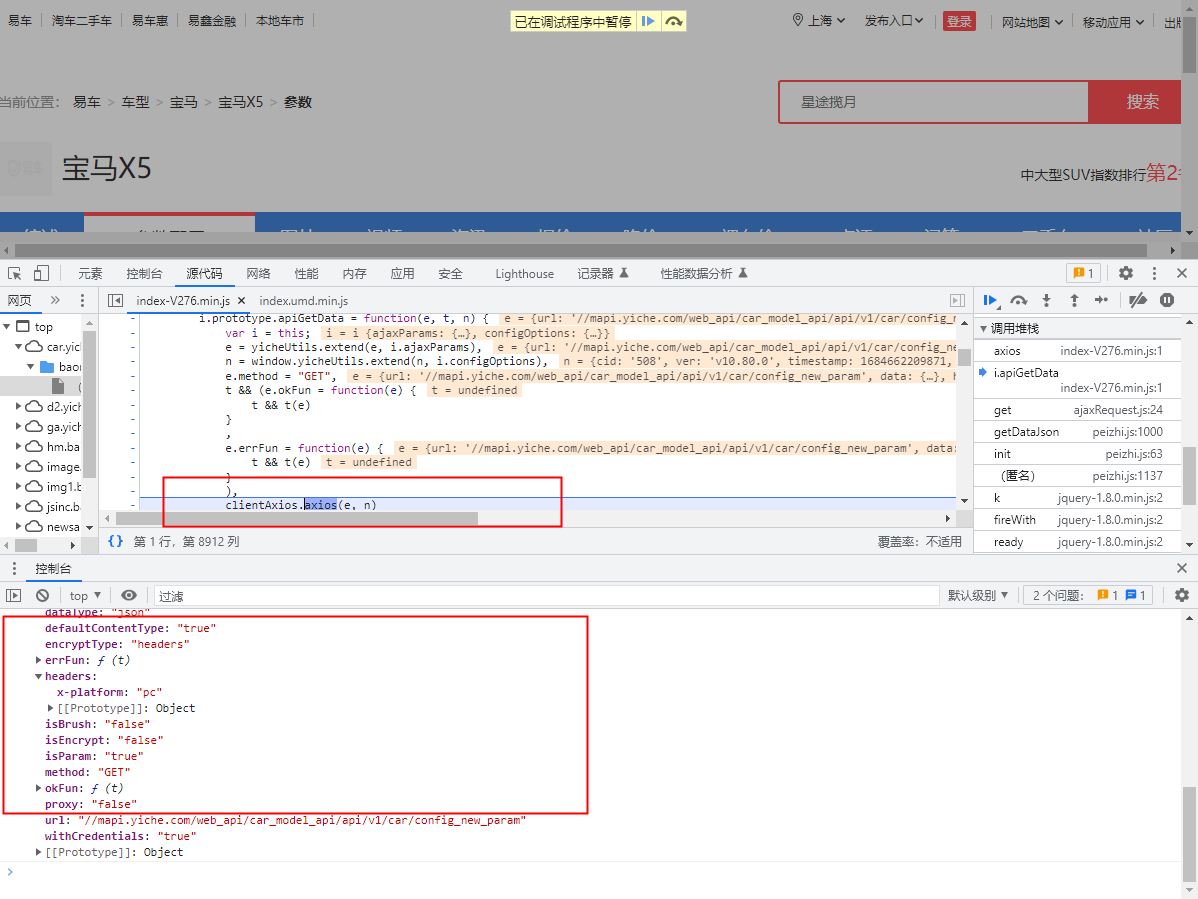
-
我们向前一个调用函数发现,其携带的参数中 sign 值已经发生了变化,那我们就有理由怀疑 这个
clientAxios.axios(e, n)函数就是将数据进行加密然后返回的的函数 -
我们进入到这个函数中
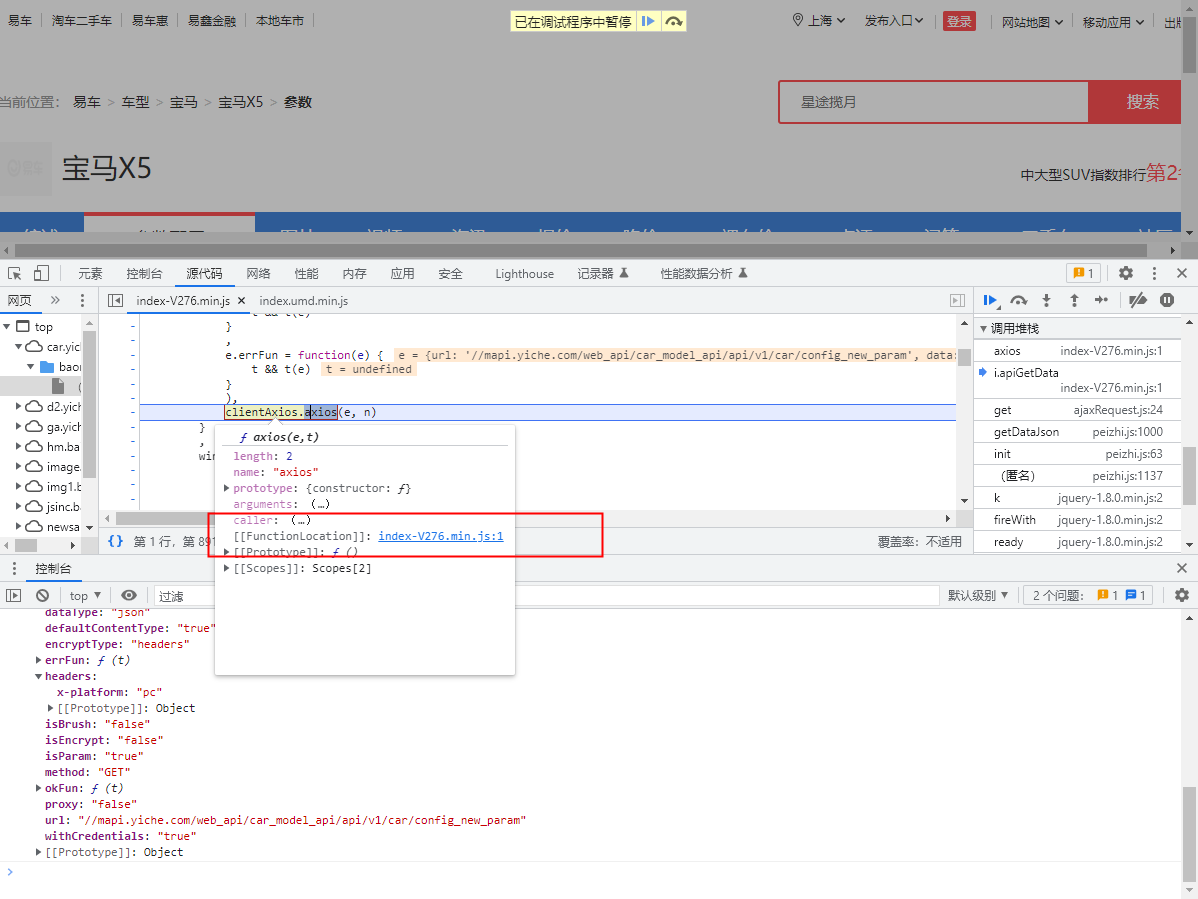
- 通过悬浮查看调用函数进入到这个函数中
function axios(e, t) {
var n, i = {
cid: "601",
ver: clientAxios.getVer(),
timestamp: (new Date).getTime()
};
t = window.yicheUtils.extend(t, i);
var o = (n = {
headers: {
"x-platform": "phone"
},
method: "GET",
data: {},
withCredentials: "true",
async: "true",
isParam: "true",
dataType: "json",
defaultContentType: "true",
okFun: function(e) {},
errFun: function(e) {},
encryptType: "headers",
isEncrypt: "false"
},
_defineProperty(n, "defaultContentType", "true"),
_defineProperty(n, "isBrush", "false"),
_defineProperty(n, "proxy", "false"),
n);
if (e = window.yicheUtils.extend(e, o),
!e.url)
return console.log("请求URL地址不能为空");
var r = new Date
, a = {
url: e.url,
lgin: e.data || "",
inbyte: e.data ? JSON.stringify(e.data).length : 0,
st: r.toLocaleString()
}
, s = {
dataType: e.dataType,
method: e.method,
headers: clientAxios.getHeaders(e, t),
url: "true" == e.proxy ? e.url : window.yicheUtils.urlDispose(e.url),
async: e.async,
xhrFields: {
withCredentials: e.withCredentials
},
data: clientAxios.getData(e, t),
success: function(t) {
return t && 1 == t.status ? e.okFun && e.okFun(t) : e.errFun && e.errFun(t)
},
error: function(t) {
e.errFun && e.errFun({
status: 0,
message: "请求异常" + t,
data: null
})
},
complete: function(t, n) {
var i = e.headers;
if (window._reportLog)
if (a.dur = Date.now() - r.getTime(),
a.lgout = t.responseText || "",
a.outbyte = a.lgout.length,
"success" == n)
try {
var o = JSON.parse(t.responseText);
window._reportLog(a, "info", i),
(!o || "" !== o.ercd && null !== o.ercd && void 0 !== o.ercd) && (a.reason = "status: " + o.status,
window._reportLog(a, "err", i))
} catch (s) {
window._reportLog(a, "info", i),
a.reason = "responseText: " + t.responseText,
window._reportLog(a, "err", i)
}
else
window._reportLog(a, "info", i),
a.reason = n || "",
window._reportLog(a, "err", i)
}
};-
这一大串函数就是这么多
-
我们分析这段函数
-
前面都是正常的加一些请求参数,当我们读到这行代码时我们就需要特别注意了
headers: clientAxios.getHeaders(e, t), -
因为我们需要的请求参数正是在headers中,所以我们就要重点关注出现headers的地方
-
我们通过这段代码可以理解这行代码的意思就是从这个函数中拿到 headers 这个参数赋值 给headers 这个变量

- 我们可以在控制台打印输出这个函数,也可以全选中悬浮查看其数据
- 我们发现这个数据携带的正式我们的加密函数,那我们的目的也就明确了就是去这个函数中查看他是如何生成的
- 同样的方法我们进入到函数内部
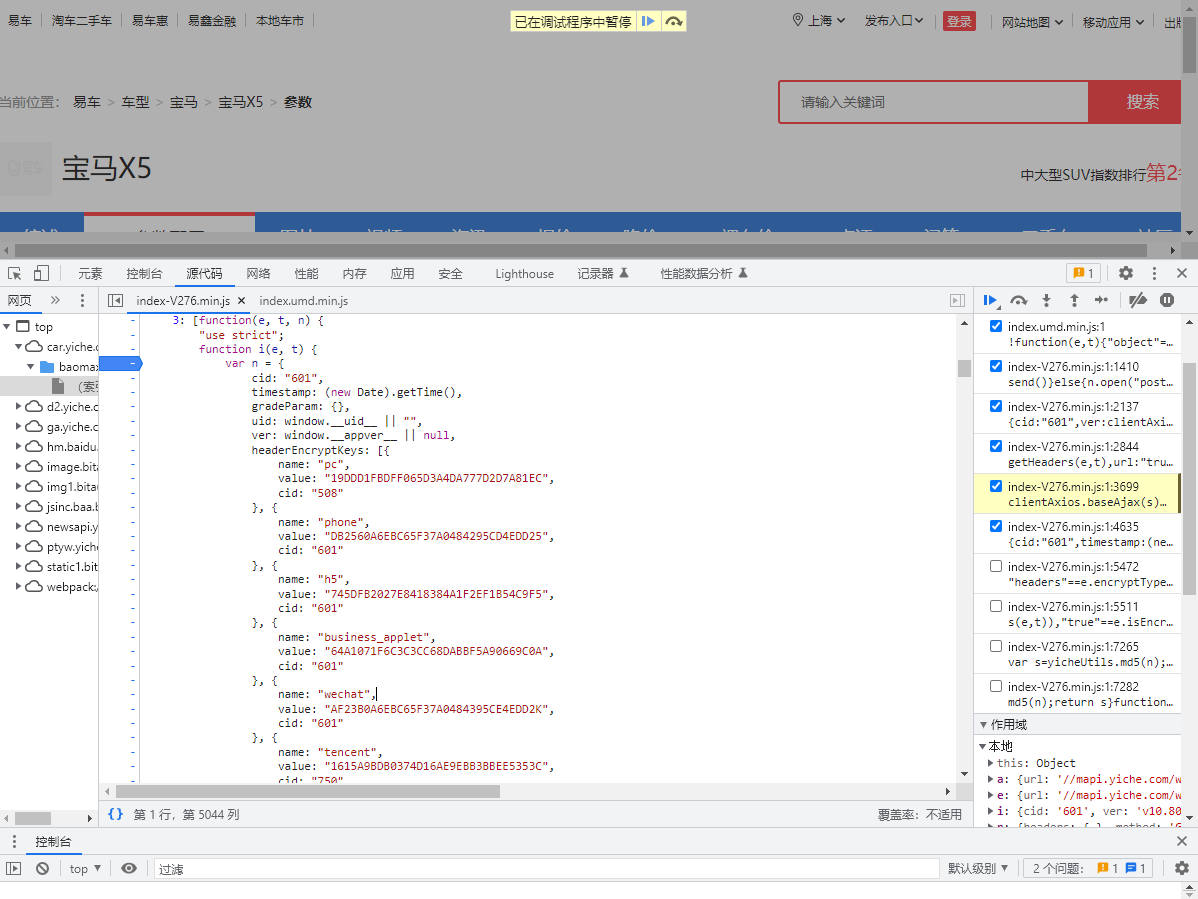
function i(e, t) {
var n = {
cid: "601",
timestamp: (new Date).getTime(),
gradeParam: {},
uid: window.__uid__ || "",
ver: window.__appver__ || null,
headerEncryptKeys: [{
name: "pc",
value: "19DDD1FBDFF065D3A4DA777D2D7A81EC",
cid: "508"
}, {
name: "phone",
value: "DB2560A6EBC65F37A0484295CD4EDD25",
cid: "601"
}, {
name: "h5",
value: "745DFB2027E8418384A1F2EF1B54C9F5",
cid: "601"
}, {
name: "business_applet",
value: "64A1071F6C3C3CC68DABBF5A90669C0A",
cid: "601"
}, {
name: "wechat",
value: "AF23B0A6EBC65F37A0484395CE4EDD2K",
cid: "601"
}, {
name: "tencent",
value: "1615A9BDB0374D16AE9EBB3BBEE5353C",
cid: "750"
}],
paramsKey: "f48aa2d0-31e0-42a6-a7a0-64ba148262f0"
};
t = window.yicheUtils.extend(t, n),
t.cid = f(e, t),
t.timestamp = (new Date).getTime();
var i = yicheUtils.deepClone(e.headers);
i["x-timestamp"] = t.timestamp,
o("Content-Type", e.headers) || "true" != e.defaultContentType || (i["Content-Type"] = "application/json;charset=UTF-8"),
"headers" == e.encryptType && (i["x-sign"] = s(e, t)),
"true" == e.isEncrypt && yicheUtils.switchEncrypt() && (i.encryptType = 2);
var r = l()
, a = c()
, d = u();
return o("x-city-id", e.headers) || (i["x-city-id"] = r),
o(" ", e.headers) || (i["x-ip-address"] = a),
o("x-user-guid", e.headers) || (i["x-user-guid"] = d),
window.__getAjaxHeader && (i = yicheUtils.extend(i, window.__getAjaxHeader())),
"true" == e.isBrush && (i = yicheUtils.setEncryptParams(i, t.timestamp)),
i
}- 这就是那个函数的所有方法
- 我们观察这个函数的调用方法,我们可以发现这么一串数据
headerEncryptKeys: [{
name: "pc",
value: "19DDD1FBDFF065D3A4DA777D2D7A81EC",
cid: "508"
}, {
name: "phone",
value: "DB2560A6EBC65F37A0484295CD4EDD25",
cid: "601"
}, {
name: "h5",
value: "745DFB2027E8418384A1F2EF1B54C9F5",
cid: "601"
}, {
name: "business_applet",
value: "64A1071F6C3C3CC68DABBF5A90669C0A",
cid: "601"
}, {
name: "wechat",
value: "AF23B0A6EBC65F37A0484395CE4EDD2K",
cid: "601"
}, {
name: "tencent",
value: "1615A9BDB0374D16AE9EBB3BBEE5353C",
cid: "750"
}],
paramsKey: "f48aa2d0-31e0-42a6-a7a0-64ba148262f0"
};- 对于这串数据我们很眼熟,其中的PC对应的相应数据我们需要特殊注意,它的作用大概是标识 设备标识的
name: "pc",
value: "19DDD1FBDFF065D3A4DA777D2D7A81EC",
cid: "508"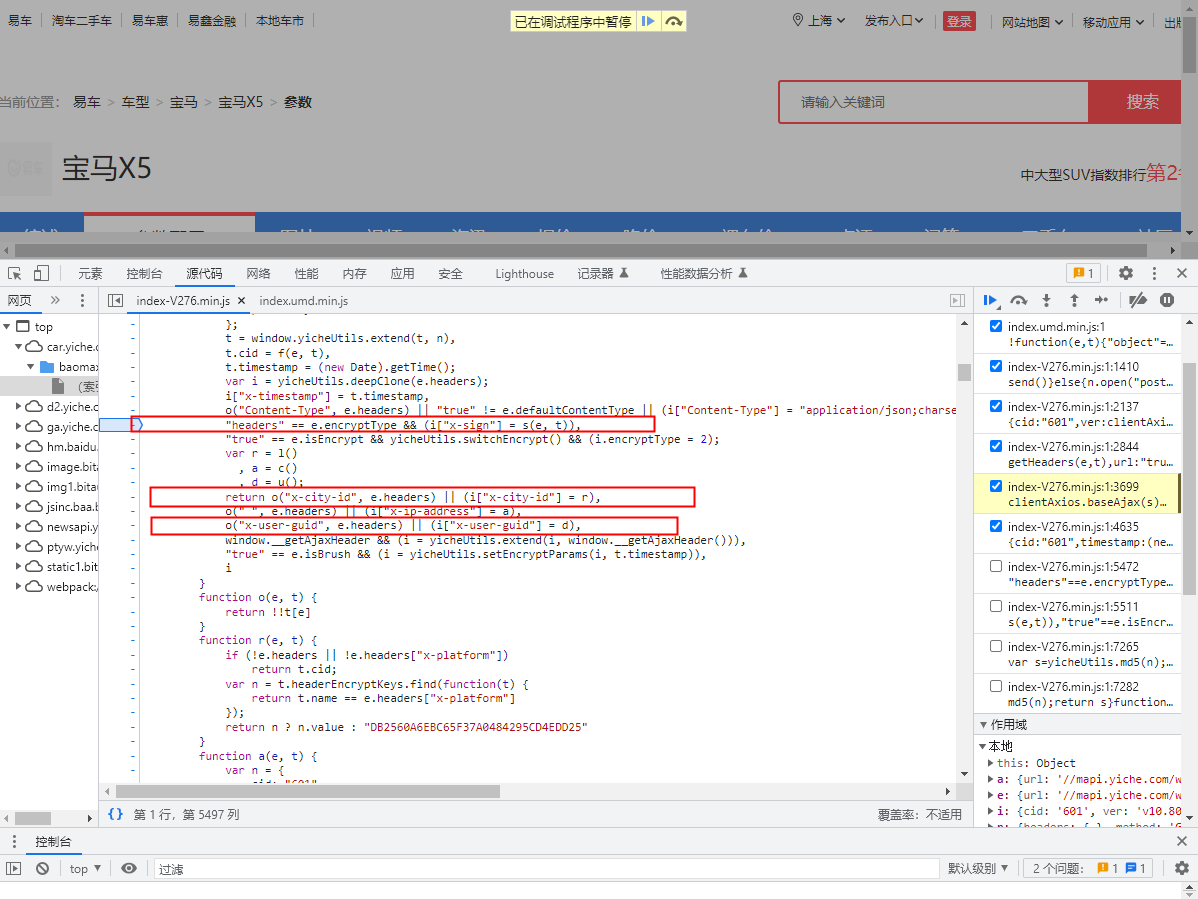
-
通过这些代码,我们可以发现这正是我们想要的数据的关键字
- x-sign
- 变化的sign值
- x-city-id
- 大概是城市ID
- x-ip-address
- 大概是IP地址
- x-user-guid
- 大概是有关用户登陆相关的
- x-sign
-
我们分析上面这些参数,我们需要特别注意的就是 变化的 sign值和这个登录的 参数是否发生变化
- 不用想,sign 一定会变化
- 那我们先看 x-user-guid
-
我们发现这个参数 = d 那我们就找到 d 是怎么来的
- 他其实就在我们上面 d = u()
- 我们查看 u 函数
function u() {
var e = yicheUtils.getCookie("UserGuid") || yicheUtils.getCookie("CIGUID");
if (e)
return e;
var t = window.yicheUtils.createGuid();
return window.yicheUtils.setCookie("CIGUID", t, 43800, ".yiche.com"),
t
}-
我们分析这段代码可以发现,他有两个分支
- 一个是成立
- 返回一个参数
- 一个是失败
- 成立以后就会生成一个新的ID,染回将这个ID返回
- 一个是成立
-
那我们就猜测他就是标识用户有没有访问过这个网页的标识。访问过就做个标记,否则则为新用户创建一个新的标识
-
既然这个参数解决了,那我们就剩下最后一个参数 sign

- 我们进入到这个生成sign 的函数中
function s(e, t) {
var n = "";
if ("headers" == e.encryptType) {
var i = e.data ? JSON.stringify(e.data) : "{}"
, o = r(e, t);
n = "cid=" + t.cid + "¶m=" + i + o + t.timestamp
} else {
var a = [];
a.push("cid=" + t.cid),
a.push("uid=" + t.uid),
a.push("ver=" + t.ver),
a.push("devid=" + (e.deviceId || "")),
a.push("t=" + t.timestamp),
a.push("key=" + t.paramsKey),
n = a.join(";")
}
var s = yicheUtils.md5(n);
return s
}- 我们通过分析这段代码,有两个分支
- 如果这个头等于我们e中的头(其实是一个md5签名验证的操作)
- 那我们肯定走这个正确的让他给我们生成我们想要的数据
- 另一个就是签名验证失败走的
- 前面的就是一顿加加加
- 然后理他也没用
- 如果这个头等于我们e中的头(其实是一个md5签名验证的操作)
- 接下来我们就看下面的这个 s (因为他的返回值就是s)
- 他是一个md5加密的操作然后拿到他的加密值
- 我们需要明白这个加密的参数是什么
- 我们将函数走到这步看看 n 到底是什么

- 我们在控制台打印输出这个函数,或者分析上面条件成立后走的函数都可以发现
- 他其实就是一个字符串拼接操作
'cid=508¶m={"cityId":"2401","serialId":"8108"}19DDD1FBDFF065D3A4DA777D2D7A81EC1684663988312'- 其中前面的很明显就是我们携带的请求参数的一部分
- 至于后面这个其实就是我们在标识设备的那部分对应的value值
- 最后就是md5加密函数生成sign值了
【三】逆向代码
【1】时间戳的逆向
- 时间戳基本都是固定的写法
- 13位的时间戳
import time
x_timestamp = str(int(time.time() * 1000))【2】sign 参数的逆向
- 生成md5加密的参数
import time
import json
import hashlib
x_timestamp = str(int(time.time() * 1000))
# 里面的其中一个参数
p = {"cityId": "2401", "serialId": "8108"}
# 将字符串转为 json格式
p_str = json.dumps(p)
n = f'cid=508¶m={p_str}19DDD1FBDFF065D3A4DA777D2D7A81EC{x_timestamp}'
# 创建 md5 对象
mad5 = hashlib.md5()
# 这里传入的参数必须是二进制的数据
mad5.update(n.encode())
# 取md5加密值
sign = mad5.hexdigest()- 这有一个bug需要额外小心,就是你传到md5加密中的参数一定要和你携带的请求参数相同
- 如果不想等 md5 签名验证失败一样是请求不到数据的
- 做这个加密的作者,真是个人才,不注意可能还真的会被坑!
【3】完整的Python代码
# -*-coding: Utf-8 -*-
# @File : 01 .py
# author: Chimengmeng
# blog_url : https://www.cnblogs.com/dream-ze/
# Time:2023/5/21
import requests
import os
from fake_useragent import UserAgent
import time
import json
import hashlib
x_timestamp = str(int(time.time() * 1000))
# 'https://mapi.yiche.com/web_api/car_model_api/api/v1/car/config_new_param?cid=508¶m=%7B%22cityId%22%3A%222401%22%2C%22serialId%22%3A%228108%22%7D'
page_url = 'https://mapi.yiche.com/web_api/car_model_api/api/v1/car/config_new_param?'
p = {"cityId": "2401", "serialId": "8108"}
p_str = json.dumps(p)
n = f'cid=508¶m={p_str}19DDD1FBDFF065D3A4DA777D2D7A81EC{x_timestamp}'
mad5 = hashlib.md5()
mad5.update(n.encode())
sign = mad5.hexdigest()
params = {
'cid': '508',
'param': p_str,
}
headers = {
'cookie': 'CIGUID=93f5a6aa4597abac03dde7ab96b3e3c9; isWebP=true; locatecity=310100; bitauto_ipregion=180.164.67.62%3A%E4%B8%8A%E6%B5%B7%E5%B8%82%3B2401%2C%E4%B8%8A%E6%B5%B7%2Cshanghai; auto_id=044e8069776834cba1d5d72375d6423c; UserGuid=93f5a6aa4597abac03dde7ab96b3e3c9; Hm_lvt_610fee5a506c80c9e1a46aa9a2de2e44=1684637884; selectcity=310100; selectcityid=2401; selectcityName=%E4%B8%8A%E6%B5%B7; Hm_lpvt_610fee5a506c80c9e1a46aa9a2de2e44=1684637896',
'origin': 'https://car.yiche.com',
'referer': 'https://car.yiche.com/baomax5-8108/peizhi/',
'User-Agent': UserAgent().random,
'x-city-id': '2401',
'x-ip-address': '180.164.67.62',
'x-platform': 'pc',
'x-sign': sign,
'x-timestamp': x_timestamp,
'x-user-guid': '93f5a6aa4597abac03dde7ab96b3e3c9',
}
response = requests.get(page_url, params=params, headers=headers)
# 将返回的数据转为json格式方便取值
# 取到的是里面的data数据
data_list = json.loads(response.text)['data']
for data in data_list:
print('这是name', data['name'])
# print('--------------分割线data------------------')
items = data['items']
print('这是items', items)
for item in items:
print('这是item', items)- 有兴趣的自己往下一步步取值吧,我是懒得搞了,数据太多了而且一层层嵌套很麻烦