Lambda表达式特性之延迟执行
一、为什么需要延迟执行
- 问题引出:有些场景的代码执行后,结果不一定会被使用,从而造成性能浪费。
- 如何解决:Lambda表达式是可以延迟执行的,这正好可以作为解决方案,提升性能。
二、延迟执行造成的性能浪费的案例
- 典型的场景:就是对参数进行有条件使用,例如对日志消息进行拼接后,在满足条件的情况下进行打印输出:
public class LoggerDemo { private static void log(int level, String msg) { //条件判断 if (level == 1) { System.out.println(msg); } } public static void main(String[] args) { String msgA = "Hello"; String msgB = "World"; String msgC = "Java"; //方法调用,必须提前拼接字符串造成性能浪费 log(1, msgA + msgB + msgC); } } - 问题说明:这段代码存在问题,无论级别level是否满足要求,log 方法的第二个参数,也就是**三个字符串(msgA + msgB + msgC)**无论如何一定先会被拼接,然后再传入方法内进行级别判断if (level == 1)。
- 问题进一步分类分析:
a.如果判断通过,那么好,这种情况不会对性能产生影响;
b.如果判断不通过,那么我们之前在传入参数时进行三个字符串 (msgA + msgB + msgC)的操作不就是白做了吗,因为又不需要打印,那么用在拼接字符串上的时间不就等于白白浪费了,也就造成了性能浪费。 - 问题解决:那么如何不浪费这些性能呢?于是lambda表达式挺身而出,来拯救这些不应该被浪费的性能。
三、使用lambda表达式进行优化(延迟执行)
-
情况一:未使用lambda表达式的情况
条件不通过,花费的时间展示public class LoggerDemo { private static void log(int level, String msg) { if (level == 1) { System.out.println(msg); } } public static void main(String[] args) { String msgA = "Hello"; String msgB = "World"; String msgC = "Java"; long start = System.currentTimeMillis(); //1.条件不通过情况 log(2, msgA + msgB + msgC); long end = System.currentTimeMillis(); System.out.println("未使用lambda表达式花费时间:"+(end-start)); } } 结果: 未使用lambda表达式花费时间:49
条件通过的情况public class LoggerDemo { private static void log(int level, String msg) { if (level == 1) { System.out.println(msg); } } public static void main(String[] args) { String msgA = "Hello"; String msgB = "World"; String msgC = "Java"; long start = System.currentTimeMillis(); //2.条件通过情况 log(2, msgA + msgB + msgC); long end = System.currentTimeMillis(); System.out.println("未使用lambda表达式花费时间:"+(end-start)); } } 结果: HelloWorldJava 未使用lambda表达式花费时间:48结果分析:两个没有使用lambda表达式的方法在条件判断不通过和通过的情况下花费的时间分别是48和49,那么可见时间上可以说是没什么区别。可见条件不通过的情况下字符串的拼接造成了性能浪费。
-
情况二:使用了lambda表达式的延迟特性代码
条件不通过情况:public class LoggerDemo { private static void log(int level, MessageBuilder builder) { if (level == 1) { System.out.println(builder.buildMessage()); } } public static void main(String[] args) { String msgA = "Hello"; String msgB = "World"; String msgC = "Java"; long start = System.currentTimeMillis(); //1.条件不通过的情况 log(2, () -> { System.out.println("Lambda执行!"); return msgA + msgB + msgC; }); long end = System.currentTimeMillis(); System.out.println("未延迟执行花费时间:"+(end-start)); } } /== * 下面这个是函数式接口,方便lambda表达式的使用。 */ @FunctionalInterface interface MessageBuilder { String buildMessage(); } 结果: 未延迟执行花费时间:20条件通过的情况下:
public class LoggerDemo { private static void log(int level, MessageBuilder builder) { if (level == 1) { System.out.println(builder.buildMessage()); } } public static void main(String[] args) { String msgA = "Hello"; String msgB = "World"; String msgC = "Java"; long start = System.currentTimeMillis(); //1.条件通过的情况 log(1, () -> { System.out.println("Lambda执行!"); return msgA + msgB + msgC; }); long end = System.currentTimeMillis(); System.out.println("延迟执行花费时间:"+(end-start)); } } /== * 下面这个是函数式接口,方便lambda表达式的使用。 */ @FunctionalInterface interface MessageBuilder { String buildMessage(); } 结果: Lambda执行! HelloWorldJava 延迟执行花费时间:49结果分析:可见不通过和通过的时间分别是20和48,提升了一倍多的性能,。可见使用了lambda表达式的延迟特性之后,可以提高一定条件下代码的性能。
四、 分析lambda表达式为何能提升性能
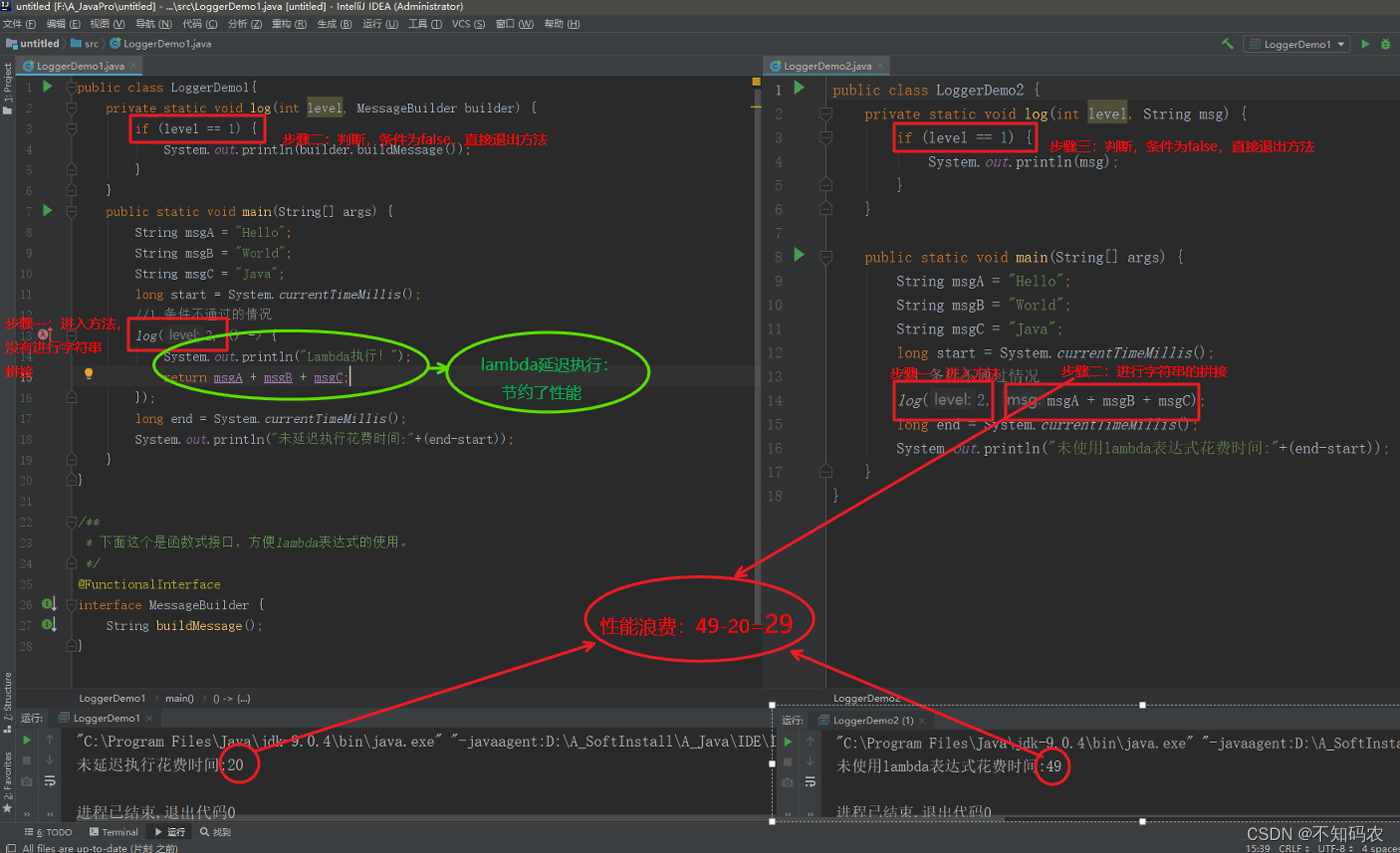
说明:根据上面这幅图可以看出来,lambda表达式的延迟执行特性带来的性能提升非常大。
但是需要函数式接口的支持,小伙伴有时候需要自己定义函数式接口来实现lambda
表达式的延时执行特性。
五、总结
1.lambda表达式具有延迟执行的特性,在特定的场合下使用lambda表达式,会让你的程序效率有不小的提升。
2.但是使用lambda表达式需要和函数式接口配合使用。例如Spring解决AOP时候的循环依赖问题,当使用AOP的时候,需要使用代理对象替换掉原始对象。但是代理对象的创建是在初始化过程的拓展阶段,而属性的赋值(populateBean())是在生成代理对象之前执行的,那么就需要在属性赋值的时候判断是否需要生成代理对象。那么为什么非要使用lambda表达式的机制来完成呢?因为对象什么时候被暴露出去或者什么时候被其他对象引用是没有办法提前确定好的。所以只有在调用的那一刻才可以进行原始对象还是代理对象的判断。使用lambda表达式类似于一种回调机制,不暴露的时候不需要调用执行,当需要被调用的时候,才正真执行lambda表达式,来判断返回的是原始对象还是代理对象。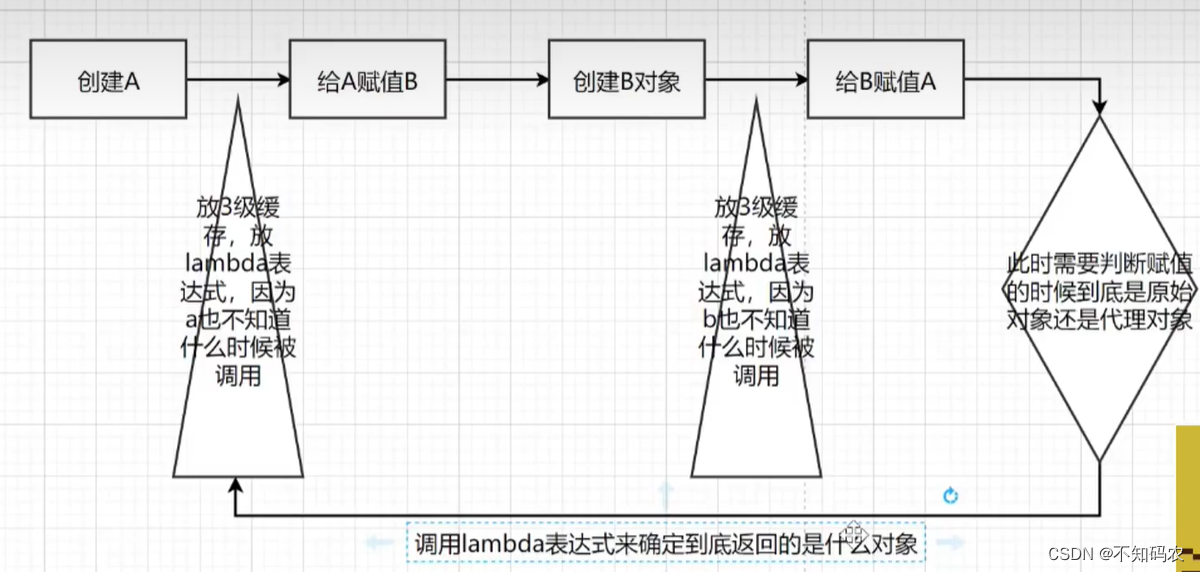
AbstractAutowireCapableBeanFactory -> doCreateBean
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
/**
* Add the given singleton factory for building the specified singleton
* if necessary.
* <p>To be called for eager registration of singletons, e.g. to be able to
* resolve circular references.
* @param beanName the name of the bean
* @param singletonFactory the factory for the singleton object
*/
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
@FunctionalInterface
public interface ObjectFactory<T> {
/**
* Return an instance (possibly shared or independent)
* of the object managed by this factory.
* @return the resulting instance
* @throws BeansException in case of creation errors
*/
T getObject() throws BeansException;
}
/**
* Obtain a reference for early access to the specified bean,
* typically for the purpose of resolving a circular reference.
* @param beanName the name of the bean (for error handling purposes)
* @param mbd the merged bean definition for the bean
* @param bean the raw bean instance
* @return the object to expose as bean reference
*/
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
//默认最终公开的对象是bean,通过类AbstractAutowireCapableBeanFactory中的方法createBeanInstance()创建出来普通对象
Object exposedObject = bean;
//mbd是systhetic属性:设置bean的定义是否是systhetic,一般是指只有AOP相关的pointCut配置或者Advice配置才会将原始对象替换成代理对象
//如果mbd不是systhetic且此工厂拥有InstantiationAwareBeanPostProcessor,有可能将代理对象替换成源是对象
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
//遍历工厂内所有的后置处理器
for (BeanPostProcessor bp : getBeanPostProcessors()) {
//如果bp是SmartInstantiationAwareBeanPostProcessor的实列
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
//让exposedObject经过每个SmartInstantiationAwareBeanPostProcessor的包装
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
//返回最终经过层次包装后的对象
return exposedObject;
}