【halcon深度学习之那些封装好的库函数】read_dl_samples
函数分析
read_dl_samples 是一个用于从磁盘上读取先前保存的 DLSample 字典批量的过程。
签名:
read_dl_samples(DLDataset, SampleIndices, DLSampleBatch)
描述:
该过程通过 SampleIndices 参数确定要读取 DLDataset 中哪些样本的 DLSample 字典。
对于 DLDataset 中的每个样本,DLSample 字典的路径通过键 ‘dlsample_file_name’(在字典 ‘sample’ 中)和键 ‘dlsample_dir’(在字典 DLDataset 中)指定的目录确定。
请注意,如果对于某个样本不存在 ‘dlsample_file_name’ 键,该过程将自动生成该键。它使用带有后缀 ‘_dlsample.hdict’ 的图像 ID,并测试该文件是否存在于 ‘dlsample_dir’ 中。如果存在,则读取该文件并创建键 ‘dlsample_file_name’ 的条目。
参数:
DLDataset(输入):包含有关数据集的信息的字典。SampleIndices(输入):在字典 DLDataset 中的样本的索引,从中读取 DLSamples。DLSampleBatch(输出):从磁盘读取的 DLSample 字典或 DLSample 字典的元组。
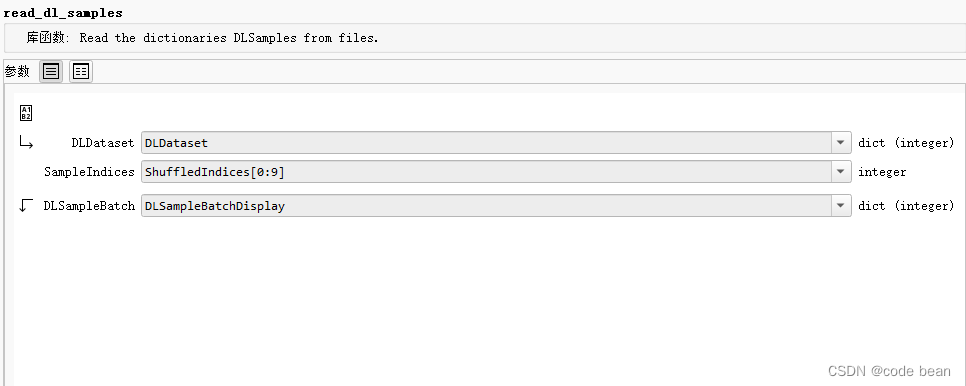
DLDataset 结构截图: ‘dlsample_file_name’ 键 可以再图中看到,注意这个字段是在 preprocess_dl_dataset这个函数执行之后才出现的字段。read_dl_samples 必然只能再数据预处理(preprocess_dl_dataset)完成之后才能执行!
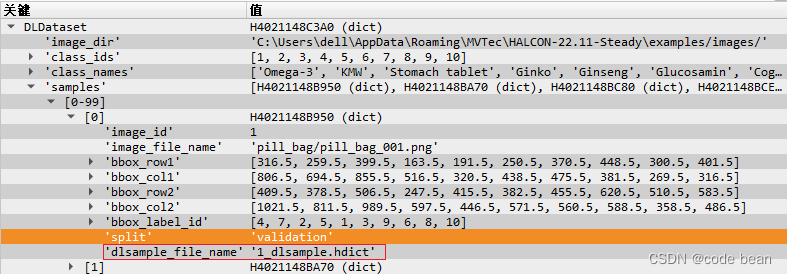
DLSampleBatch,输出参数,数据结构如下(和DLDataset 相比里面多了图片对象):
代码上下文
preprocess_dl_dataset (DLDataset, DataDirectory, DLPreprocessParam, GenParam, DLDatasetFilename)
* Display the DLSamples for 10 randomly selected train images.
find_dl_samples (DLDataset.samples, 'split', 'train', 'match', SampleIndices)
tuple_shuffle (SampleIndices, ShuffledIndices)
read_dl_samples (DLDataset, ShuffledIndices[0:9], DLSampleBatchDisplay)
小结
read_dl_samples 主要用于从数据集里,根据序号,随机抽取一些样本, 然后就可以进行查看这些样本!