java之JdbcTemplate技术
之前去连接一个数据库,我们注册驱动,得到连接对象,然后得到语句句柄,再来执行,这玩意有点麻烦,每次都要这样写一套,然后才能进行sql语句的查询和其他操作。
那么后来我们把连接对象与关闭对象这个工作给拿了出来,把需要里注册的数据库连接,用户名,密码,数据库名都放到一个properties的配置文件里面。
先来看这个配置文件utils.properties配置文件,这个文件直接放在了src目录下面
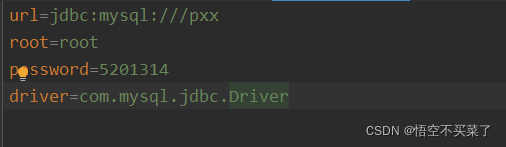
其实driver这个数据库驱动的注册完全可以省略,因为数据库管理接口在调用getConnection()的时候,就已经给我们注册了驱动,话不多说,看看单独抽离出来的JdbcUtils文件
package utils;
import java.io.IOException;
import java.io.InputStream;
import java.sql.*;
import java.util.Properties;
//工具类,我们要从配置文件中取数据
@SuppressWarnings("all")
public class JDBCUtils {
private static String url;
private static String root;
private static String password;
private static String driver;
//我们要初始化上面属性,然后在内部调用静态函数
static{
Properties properties = new Properties();
//找到资源文件,需要一个类加载器
ClassLoader classLoader = JDBCUtils.class.getClassLoader();
InputStream is = classLoader.getResourceAsStream("utils.properties");
try {
properties.load(is);//把字节流传入进来
//得到属性,给私有属性赋值
url = properties.getProperty("url");
root = properties.getProperty("root");
password = properties.getProperty("password");
driver = properties.getProperty("driver");
//把驱动注册
Class.forName(driver);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
//得到一个连接对象
public static Connection getConnection() throws SQLException {
Connection conn = DriverManager.getConnection(url,root,password);
return conn;
}
//关闭链接
public static void close(Connection conn,Statement stmt) {
if(conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
//重载关闭连接
public static void close(Connection conn, Statement stmt, ResultSet res) {
if(conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(res != null) {
try {
res.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
上面我们可以直接调用这个数据库操作的工具类,简化一些得到连接对象与关闭资源对象的一些操作。
然后人就是永远不会满足,所以才会不断的往前走,还不满足, 那就引入数据库连接池技术,这玩意牛逼不,看看啊,你看看我上面的写法,还要去得到什么url,root ,密码,多麻烦,数据库连接池就说了,不用专门去得到这些,直接把配置文件给老子加载进来,然后产生一个数据源对象,就可以用这个对象去调用数据库连接对象了。
在我们close()的时候,他也不会就是说马上关闭链接对象,他会把它放到一个类似于池子里面进行等待,来一个对象,再来进行连接,直到最后程序超时或者结束,然后连接池断开。
那么首先durid连接池需要一个配置文件,这个文件的名字就是druid.properties文件,内容也是我们写好了,如下
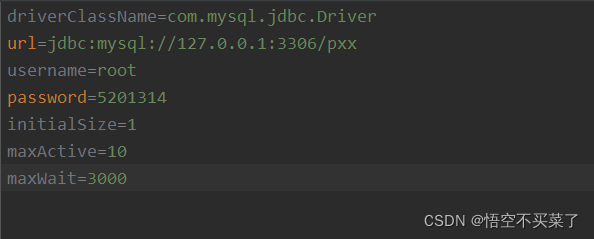
上面就是什么超时等待时间,最大活跃连接数,可以自行配置。
话不多说,上代码
package utils;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.IOException;
import java.io.InputStream;
import java.sql.*;
import java.util.Properties;
@SuppressWarnings("all")
public class JDBCUtils1 {
//数据库连接池接
private static DataSource dataSource;
static {
//druid工厂类要传入一个配置文件
Properties pro = new Properties();
//寻找配置文件
InputStream is = JDBCUtils1.class.getClassLoader().getResourceAsStream("druid.properties");
try {
pro.load(is);//加载配置文件
dataSource = DruidDataSourceFactory.createDataSource(pro);
} catch (Exception e) {
e.printStackTrace();
}
}
//获得一个连接对象
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
//归还连接对象,关闭流
public static void close(Connection conn, Statement stmt) {
if(conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
public static void close(Connection conn, Statement stmt, ResultSet res) {
if(conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(res != null) {
try {
res.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
//得到datasource对象
public static DataSource getDataSource() {
return dataSource;
}
}
上面就是连接池的一种用法。相对来说,又要简单一些,并且效率也提高了不少。
下面来说一下spring提供的JdbcTemplate模板
里面需要传入一个数据库连接池的数据源,这个模板里面就给我们提供了很多可用的关于数据库查询的方法
当然了其实不止有查询的方法,还有比如update方法,比如下面
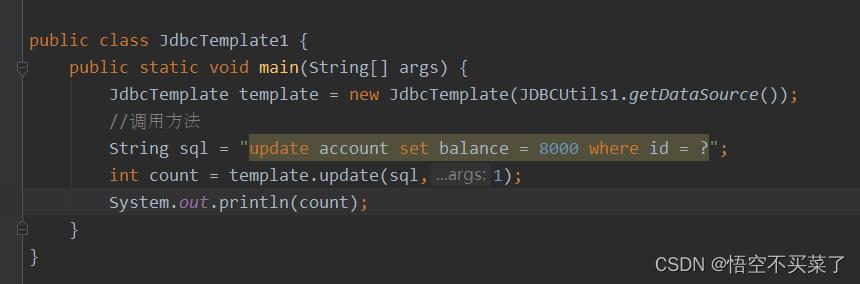
又比如insert方法
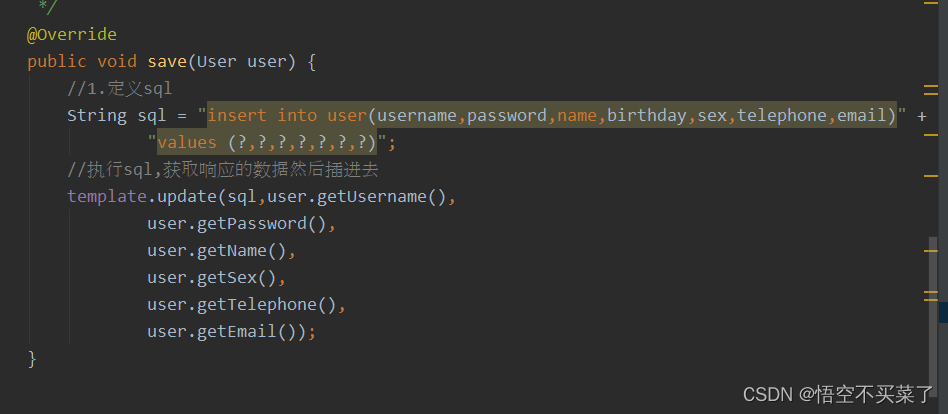 上面执行成功了之后就会返回一个1, 同时数据库中的数据也会更改
上面执行成功了之后就会返回一个1, 同时数据库中的数据也会更改
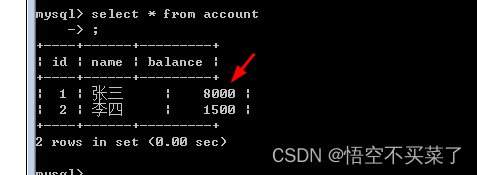
下面再来说一些查询的方法
1.queryForMap他可以把一个查询封装成一个Map集合,但是只能处理一条查询信息

上面这里主要是占位符是数字的查询,比如通过主键id来查询一条信息 ,然后把这个信息封装到map集合中去,其实这个占位符要根据你在数据库里面是什么类型就赋值上什么类型,同时这个方法呢还能进行就是说重载,也就是一次可以添加多个占位符,也就是多个形式参数,比如下面这个
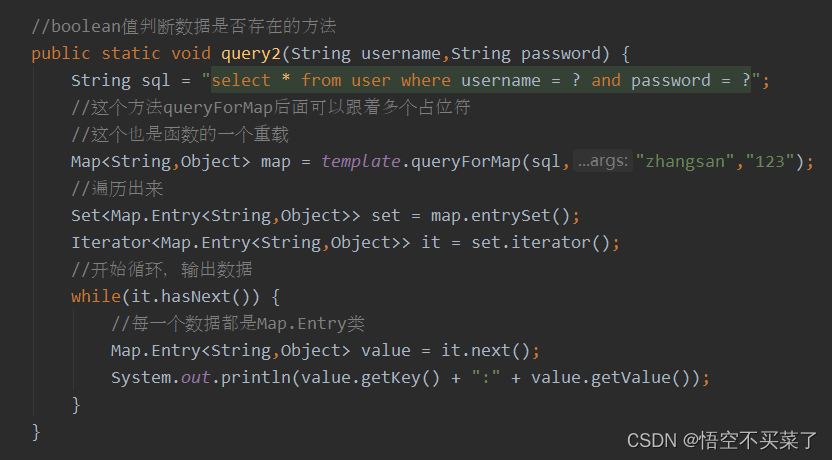
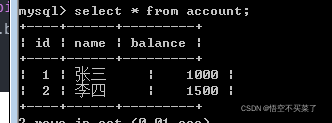
它的数据库内存查询就是如下:
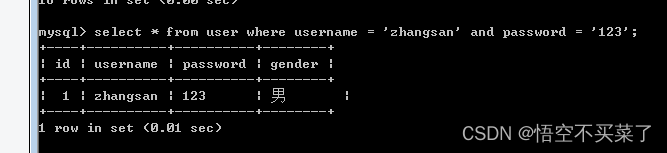
它的运行结果:
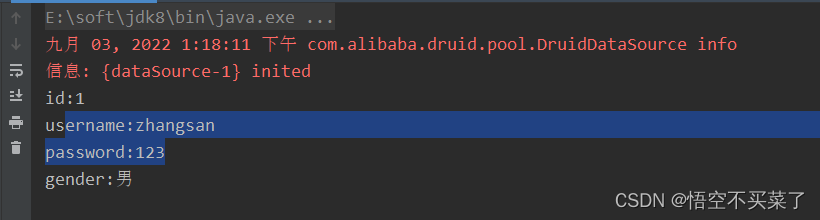
2.queryForList这个是把查询结果封装成一个List集合,里面值是Map集合 ,存放的是每一个字段对应的信息

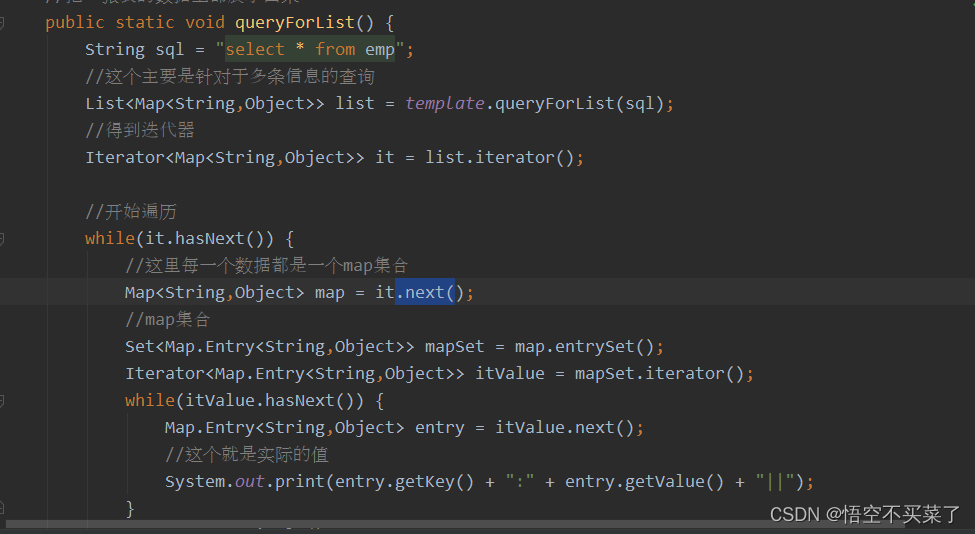
数据库中的查询结果: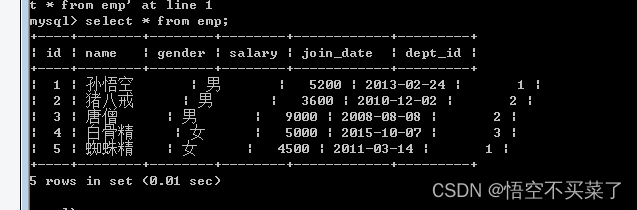
那么Idea的运行结果呢: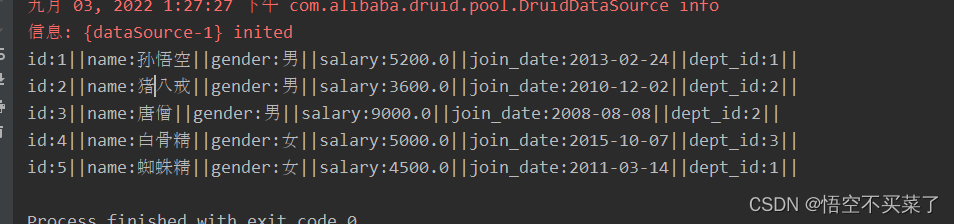
3.query
这个方法里面有很多的重载
 上面,直接有一个query方法,可以自动帮我们进行循环数据处理,把表中所有的数据取出来,封装到List集合里面。这个函数的第二个参数,是一个匿名内部类,我们自己去实现了这个接口的方法,里面是我们一些循环处理操作,这个的特点,我们可以手动定义每一条数据的循环操作语句
上面,直接有一个query方法,可以自动帮我们进行循环数据处理,把表中所有的数据取出来,封装到List集合里面。这个函数的第二个参数,是一个匿名内部类,我们自己去实现了这个接口的方法,里面是我们一些循环处理操作,这个的特点,我们可以手动定义每一条数据的循环操作语句
//把一张数据全部展示出来,另外一种方法
public static void query() {
String sql = "select * from account";
//这个方法会自动处理我的循环过程
List<Map<String,Object>> list = template.query(sql, new RowMapper<Map<String, Object>>() {
@Override
public Map<String, Object> mapRow(ResultSet resultSet, int i) throws SQLException {
Map<String,Object> map = new HashMap<String,Object>();
//注意一下这个ResultSet结果集已经有了
/*
*
* 先拿到连接对象Connection
* 再来得到一个资源对象Statement
* 在用资源对象来执行sql程序,然后返回一个结果集
* 上面也就是全部封装进去了,直接给了我们一个结果集
*
*
* */
int id = resultSet.getInt(1);
String name = resultSet.getString(2);
double balance = resultSet.getDouble(3);
//然后添加到map集合中
map.put("id",id);
map.put("name",name);
map.put("balance",balance);
return map;
}
});
//把这个装有map集合对象的list集合打印出来
for(Map<String,Object> data : list) {
System.out.println(data);//每一条数据都是map集合,肯定把数据拿出来做一个处理
}
}数据库内部的查询结果:

然后看一下IDEA的执行结果

4.query(这个方法相对来说简单一些)
我们还有另外一个方式,就是我们做一个和表相关的类

然后,spring帮我们做了一个实现类,内部只需要传入与表相关的类的字节码文件即可。应该也是利用了get与set方法
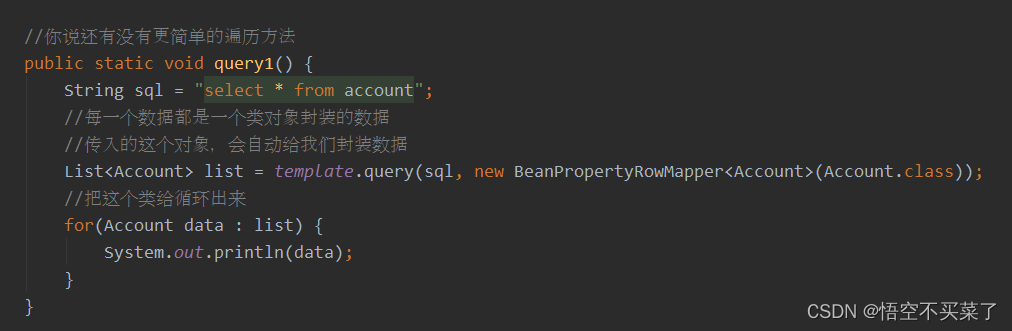
运行结果:
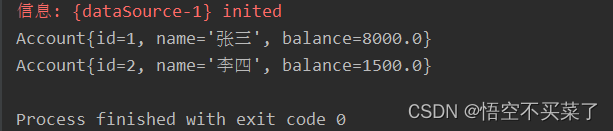
5.queryForObject

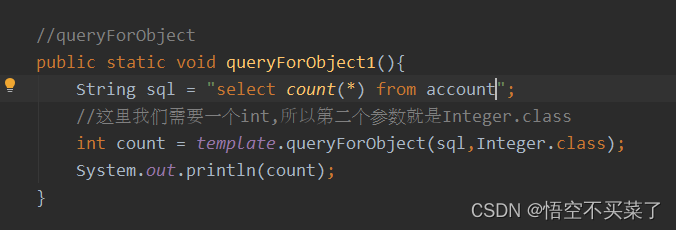
运行结果:
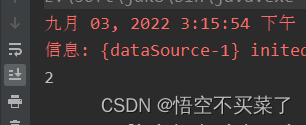
这里就是表示有两条信息
上面这种,就会直接给我们返回一个整型,基础类型,这里来说一下类型的返回,你想要什么类型,第二个参数就写上相应类型的内存class对象
再来看一个

上面这个方法后面跟几个参数都可以,根据参数类型传入相应的参数
然后上测试代码
public static void queryForObject2(){
String sql = "select * from account where id = ?";
//这里我们需要返回一个account对象,那么就要传入account对象的class
//但是如果想要返回对象,就必须先传递系统已经给我们做好的一个对象new BeanPropertyRowMapper
Account account = template.queryForObject(sql,new BeanPropertyRowMapper<Account>(Account.class),1);
System.out.println(account);
}运行结果

这里我们需要注意的是,这个方法只能处理一个对象信息,也就是一条数据集。
还有一种写法,我们直接可以用数组来传递值
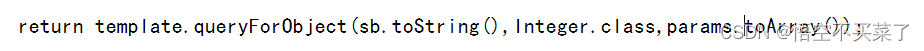
具体用法
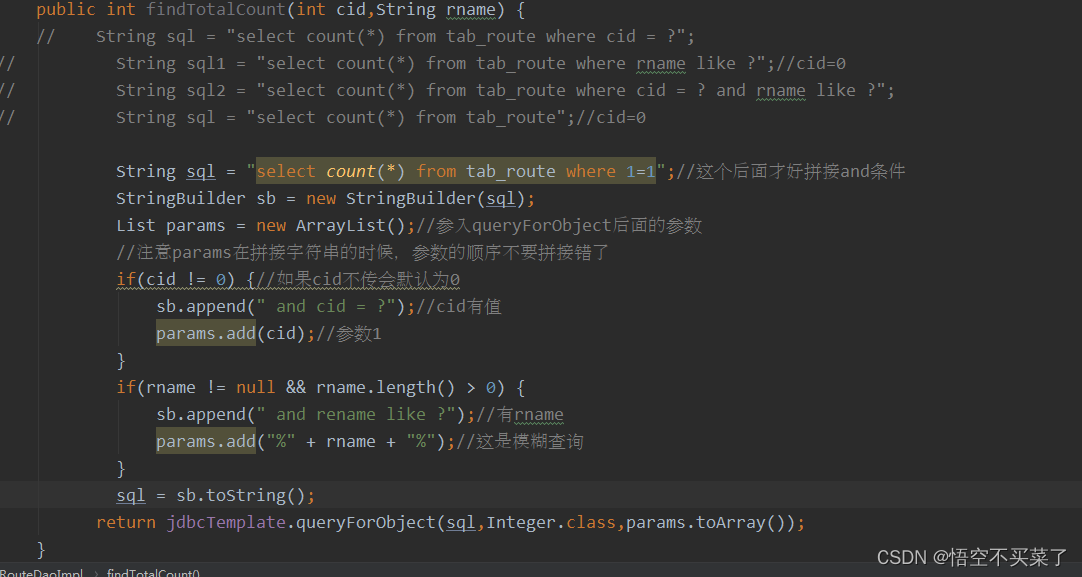
这样就会把数组的值与sql语句的值进行一一匹配
话不多说,上代码:
先来看一个类与一张数据库相关的表
Account
package domain;
public class Account {
private int id;
private String name;
private double balance;
@Override
public String toString() {
return "Account{" +
"id=" + id +
", name='" + name + '\'' +
", balance=" + balance +
'}';
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getBalance() {
return balance;
}
public void setBalance(double balance) {
this.balance = balance;
}
}
下面是各种方法查询的主体代码
package jdbctemplate;
import domain.Account;
import org.junit.Test;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.RowMapper;
import utils.JDBCUtils1;
import javax.sql.DataSource;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 需求:
* 1. 修改1号数据的 salary 为 10000
* 2. 添加一条记录
* 3. 删除刚才添加的记录
* 4. 查询id为1的记录,将其封装为Map集合
* 5. 查询所有记录,将其封装为List
* 6. 查询所有记录,将其封装为Emp对象的List集合
* 7. 查询总记录数
*/
@SuppressWarnings("all")
public class JdbcTemplate2 {
private JdbcTemplate jdbcTemplate = new JdbcTemplate(JDBCUtils1.getDataSource());
//下面利用junit的测试注解来解释这个函数
//这个只能处理一条数据信息,多了处理不了
@Test
public void testQueryFormap() {
String sql = "select * from emp where id = ?";
Map<String,Object> map = jdbcTemplate.queryForMap(sql,1);
System.out.println(map);
}
@Test
public void testQueryForList() {
String sql = "select * from emp";
List<Map<String,Object>> list = jdbcTemplate.queryForList(sql);
//我们可以遍历这个list集合
System.out.println(list);
}
@Test
public void testQuery1() {
String sql = "select * from account";
List<Map<String,Object>> list = jdbcTemplate.query(sql, new RowMapper<Map<String,Object>>() {
@Override
public Map<String, Object> mapRow(ResultSet resultSet, int i) throws SQLException {
Map<String, Object> map = new HashMap<String, Object>();
//既然拿到了resultSet
//while(resultSet.next()) {这里的循环可以不用做,这个函数会自动循环,然后调取数据
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
double balance = resultSet.getDouble("balance");
//将一条数据插入到一条集合中
map.put("id", id);
map.put("name", name);
map.put("balance", balance);
return map;
}
});
//上面就会把数据库中的数据全部取出来
System.out.println(list);
}
//简化上面操作
@Test
public void testQuery2() {
String sql = "select * from account";
//下面他帮我们实现了mapRow方法,但是必须要传入一个类的字节码文件
List<Account> list = jdbcTemplate.query(sql,new BeanPropertyRowMapper<Account>(Account.class));
//下面我们直接来遍历一下list集合
for(Account data : list) {
System.out.println(data);
}
}
}
好了,大致就说到这。