华科等提出TF-T2V:无文本标注视频的多用途生成方案,助力视频生成技术实现规模化突破...
关注公众号,发现CV技术之美
本篇分享论文A Recipe for Scaling up Text-to-Video Generation with Text-free Videos,提出无文本标注视频的多用途生成方案,助力视频生成技术实现规模化突破。
详细信息如下:

论文地址:https://arxiv.org/abs/2312.15770
项目主页:https://tf-t2v.github.io/
即将开源代码地址:https://github.com/ali-vilab/i2vgen-xl (VGen项目)
近年来,基于扩散模型的视频生成技术取得了显著进展,并开源了一系列优秀的视频生成工作,如VideoComposer、VideoCrafter、AnimateDiff、I2VGen-XL等。这些工作为视频生成社区的发展提供了良好的基准。虽然在过去一年里,文生视频任务取得了令人印象深刻的进展,但仍然落后于文生图像任务。例如,文生图模型Stable Diffusion和DALL-E 2等方法已经能够生成非常逼真的图片,而视频生成的结果仍存在生成质量差、时序连续性弱的问题。
其中一个重要原因是视频-文本(Video-text pairs)数据的标注困难,导致数据量相比图片文本(Image-text pairs)数据集如LAION-5B差了几个数量级(典型的文本视频对数据集WebVId10M只有大约10M数据规模)。为此,来自华中科技大学、阿里巴巴、浙江大学和蚂蚁集团的研究团队提出了TF-T2V方法,一个多用途视频生成框架。
TF-T2V方法的基本思路是利用大规模未标注的视频(Tiktok和YouTube平台包含大量数据源)进行数据扩充,有效丰富视频的动态多样性,使模型能够学习更丰富的运动信息,从而生成连续稳定且高质量的视频。为了显式约束生成的视频更具有时序连续性,研究团队还提出了一个时序一致性损失函数。
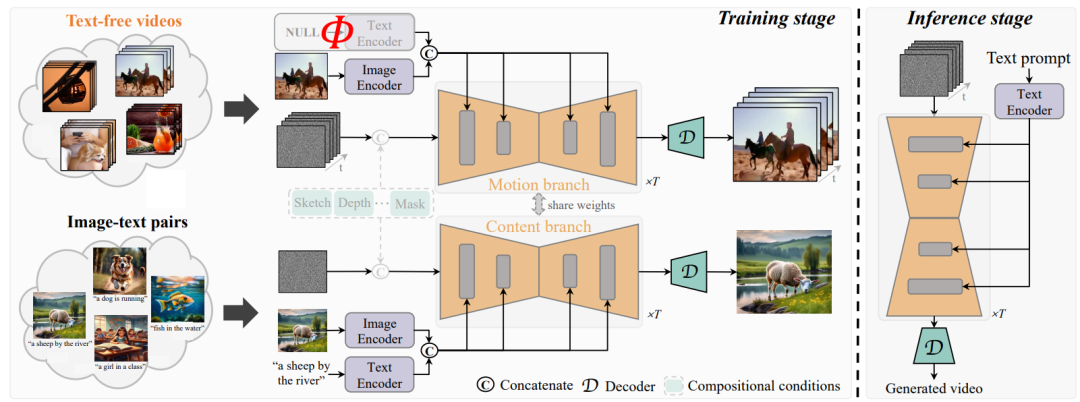
具体地,网络模型结构上图所示,整个模型分为两个分支,一个motion分支利用Text-free videos来学习运动动态,一个content分支利用大规模地image-text pairs来学习表观信息。
训练时,两个分支联合训练,motion分支可以专注于3D-UNet中运动模块的学习,而content分支则可以学习表观信息,提升视频生成质量。
在测试过程中,则可以直接利用文本作为引导,生成平滑高质量的视频,这是因为image-text中包含丰富的运动意图,这些运动意图信息通过3D-UNet模块中的时序模块注入运动动态后,就可以实现视频生成了。此外启发于视频帧间差通常包含运动信息,一个时序一致性损失也被提出,用于生成时序连续的视频。
特别地,TF-T2V还支持半监督设定:即其中包含一部分标注的视频数据和无标注的视频数据一起进行联合训练,可以提升模型对于运动文本输入的生成感知能力。
TF-T2V模型的特点:
相比于之前的文生视频模型,如ModelScopeT2V、VideoLDM。TF-T2V模型可以额外利用大量无标注视频数据,这些数据包含丰富运动动态,使得模型可以学习更多运动模式,生成的视频也更稳定。
相比于Make-A-Video这类两阶段模型,其包括text-to-image prior模型(约1B参数)和image-to-video模型。TF-T2V模型可以只需要一个统一的模型就可以进行视频生成,不需要复杂的两阶段模型。而且两阶段模型会带来额外的开销和误差累积。
TF-T2V模型具有通用性,TF-T2V模型既可以用于文生视频任务(text-to-video generation)又可以用于组合式视频生成任务(Compositional video generation)。
更广泛的运用场景。现有的视频-文本数据集WebVid10M是大约360P的有水印数据集,如果想生成高质量且高清(如720P)的视频,则需要额外收集大量高质量视频-文本对数据。而在TF-T2V中,只需要利用高清的无标注视频就可以实现高清视频生成。
实验结果1:利用无标注视频进行文生视频和组合式视频生成任务,生成的视频可以参考项目主页。



实验结果2:在半监督设定下,与其他一些开源方法的对比,TF-T2V可以保持对文本的精准控制,如“人从右往左跑”,生成的视频可以参考项目主页。

实验结果3:TF-T2V生成的视频在质量和连续性上由于现有的方法,生成的视频可以参考项目主页。

实验结果4:高分辨率生成视频,生成的视频可以参考项目主页。


TF-T2V方法为视频生成领域带来了全新的技术突破和研究思路,能够解决视频生成中的数据标注问题,为视频生成技术的发展提供有力的解决方案。未来,TF-T2V方法有望推动视频生成技术的规模化突破,使生成的视频更加逼真、连续且高质量。
通过TF-T2V方法,我们可以期待在无需依赖大量文本标注的情况下,实现更高效、更精准的视频生成。这将为电影制作、广告、娱乐、教育等领域提供更丰富多样的视频内容,同时也将为视频生成领域的研究者们带来更多的思路和突破口。让我们共同期待TF-T2V方法为视频生成技术带来的新起点和无限可能!
等等!还没有结束!
在TF-T2V基础上,作者团队还训练了VideoLCM模型(VideoLCM: Video Latent Consistency Model):
论文地址:https://arxiv.org/abs/2312.09109
项目主页:https://tf-t2v.github.io/
即将开源代码地址:https://github.com/ali-vilab/i2vgen-xl (VGen项目)

VideoLCM是一种基于视频潜在一致性模型的高效视频合成方法,该方法借鉴了图像生成领域中的一致性模型,旨在提高视频生成的效率和质量。VideoLCM框架基于现有的潜在视频扩散模型,并采用一致性蒸馏技术训练视频潜在一致性模型。
实验结果表明,VideoLCM在计算效率、保真度和时间一致性方面具有显著优势。特别地,VideoLCM仅需大约4个采样步骤即可实现高保真度、流畅的视频合成,展示出实时合成的潜力。此外,VideoLCM还可应用于文本到视频生成和组合视频合成任务。为后续研究提供了一个简化且有效的基准,有助于推动快速视频合成领域的发展。

在实验中,VideoLCM可以只需要大约4步去噪就可以生成效果稳定的视频,显著提升了视频生成效率(之前的视频生成方法通常需要50步DDIM去噪)。特别地,在组合式视频生成,如组合式草图到视频生成,VideoLCM需要的步数更少,可能1步就可以有不错的效果。

END
欢迎加入「视频生成」交流群👇备注:生成
