Python(二)
1.垃圾回收机制
#1.引用计数
x=10 # 直接引用
print(id(x))
y=x
z=x
l=['a', 'b', x] # 间接引用
print(id(l[2]))
d = {'mmm': x}
print(id(d['mmm']))
# 2.标记清除
# 循环引用=》导致内存泄露
l1 = [111, ]
l2 = [222, ]
l1.append(l2) # l1=[值111的内存地址,l2列表的内存地址]
l2.append(l1) # l2=[值222的内存地址,l1列表的内存地址]
print(id(l1[1]))
print(id(l2))
print(id(l2[1]))
print(id(l1))
print(l2)
print(l1[1])
del l1
del l2
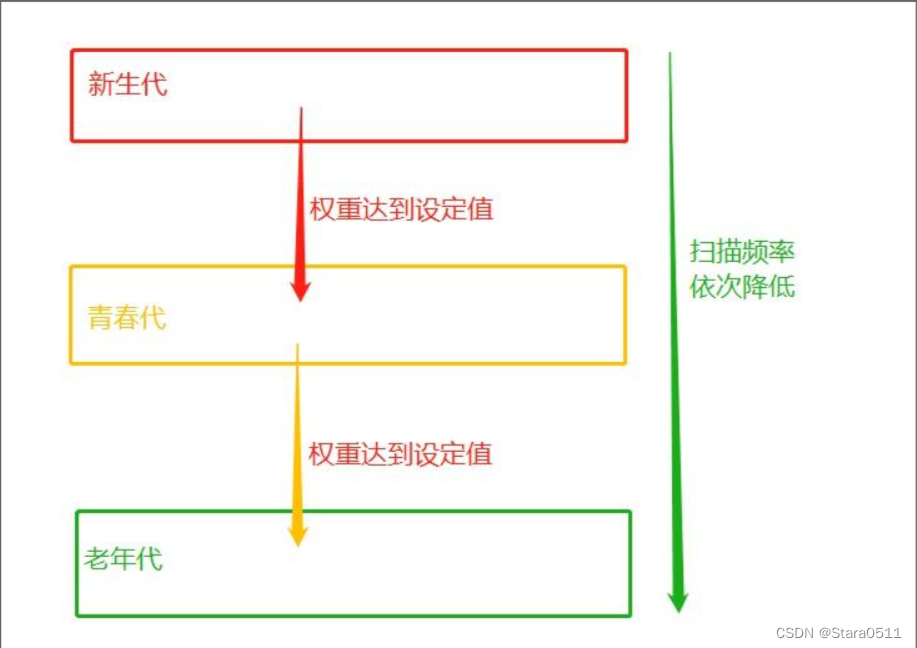
#3.分代回收
分代指的是根据存活时间来为变量划分不同等级(也就是不同的代)
新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,
如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一,
当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代,
青春代的gc扫描的频率低于新生代(扫描时间间隔更长),假设5分钟扫描青春代一次,
这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间,
接下来,青春代中的对象,也会以同样的方式被移动到老年代中。
也就是等级(代)越高,被垃圾回收机制扫描的频率越低
2.格式化输出
1.%号
# 1、格式的字符串(即%s)与被格式化的字符串(即传入的值)必须按照位置一一对应
# ps:当需格式化的字符串过多时,位置极容易搞混
print('%s asked %s to do something' % ('egon', 'lili')) # egon asked lili to do something
print('%s asked %s to do something' % ('lili', 'egon')) # lili asked egon to do something
# 2、可以通过字典方式格式化,打破了位置带来的限制与困扰
print('我的名字是 %(name)s, 我的年龄是 %(age)s.' % {'name': 'egon', 'age': 18})
kwargs={'name': 'egon', 'age': 18}
print('我的名字是 %(name)s, 我的年龄是 %(age)s.' % kwargs)
2.str.format
2.1 使用位置参数
# 按照位置一一对应
print('{} asked {} to do something'.format('egon', 'lili')) # egon asked lili to do something
print('{} asked {} to do something'.format('lili', 'egon')) # lili asked egon to do something
2.2 使用索引
# 使用索引取对应位置的值
print('{0}{0}{1}{0}'.format('x','y')) # xxyx
2.3 使用关键字参数or字典
# 可以通过关键字or字典方式的方式格式化,打破了位置带来的限制与困扰
print('我的名字是 {name}, 我的年龄是 {age}.'.format(age=18, name='egon'))
kwargs = {'name': 'egon', 'age': 18}
print('我的名字是 {name}, 我的年龄是 {age}.'.format(**kwargs)) # 使用**进行解包操作
2.4 填充与格式化
# 先取到值,然后在冒号后设定填充格式:[填充字符][对齐方式][宽度]
# *<10:左对齐,总共10个字符,不够的用*号填充
print('{0:*<10}'.format('开始执行')) # 开始执行******
# *>10:右对齐,总共10个字符,不够的用*号填充
print('{0:*>10}'.format('开始执行')) # ******开始执行
# *^10:居中显示,总共10个字符,不够的用*号填充
print('{0:*^10}'.format('开始执行')) # ***开始执行***
2.5 精度与进制
print('{salary:.3f}'.format(salary=1232132.12351)) #精确到小数点后3位,四舍五入,结果为:1232132.124
print('{0:b}'.format(123)) # 转成二进制,结果为:1111011
print('{0:o}'.format(9)) # 转成八进制,结果为:11
print('{0:x}'.format(15)) # 转成十六进制,结果为:f
print('{0:,}'.format(99812939393931)) # 千分位格式化,结果为:99,812,939,393,931
3.f-Strings
3.1 {}中可以是变量名
name = 'egon'
age = 18
print(f'{name} {age}') # egon 18
print(F'{age} {name}') # 18 egon
3.2 {}中可以是表达式
# 可以在{}中放置任意合法的Python表达式,会在运行时计算
# 比如:数学表达式
print(f'{3*3/2}') # 4.5
# 比如:函数的调用
def foo(n):
print('foo say hello')
return n
print(f'{foo(10)}') # 会调用foo(10),然后打印其返回值
# 比如:调用对象的方法
name='EGON'
print(f'{name.lower()}') # egon
3.3 在类中的使用
>>> class Person(object):
... def __init__(self, name, age):
... self.name = name
... self.age = age
... def __str__(self):
... return f'{self.name}:{self.age}'
... def __repr__(self):
... return f'===>{self.name}:{self.age}<==='
...
>>>
>>> obj=Person('egon',18)
>>> print(obj) # 触发__str__
egon:18
>>> obj # 触发__repr__
===>egon:18<===
>>>
>>> # 在f-Strings中的使用
>>> f'{obj}' # 触发__str__
'egon:18'
>>> f'{obj!r}' # 触发__repr__
'===>egon:18<==='
3.4 多行f-Stings
# 当格式化字符串过长时,如下列表info
name = 'Egon'
age = 18
gender = 'male'
hobbie1='play'
hobbie2='music'
hobbie3='read'
info = [f'名字:{name}年龄:{age}性别:{gender}',f'第一个爱好:{hobbie1}第二个爱好:{hobbie2}第三个爱好:{hobbie3}']
# 我们可以回车分隔到多行,注意每行前都有一个f
info = [
# 第一个元素
f'名字:{name}'
f'年龄:{age}'
f'性别:{gender}',
# 第二个元素
f'第一个爱好:{hobbie1}'
f'第二个爱好:{hobbie2}'
f'第三个爱好:{hobbie3}'
]
print(info)
# ['名字:Egon年龄:18性别:male', '第一个爱好:play第二个爱好:music第三个爱好:read']
4.基本运算符
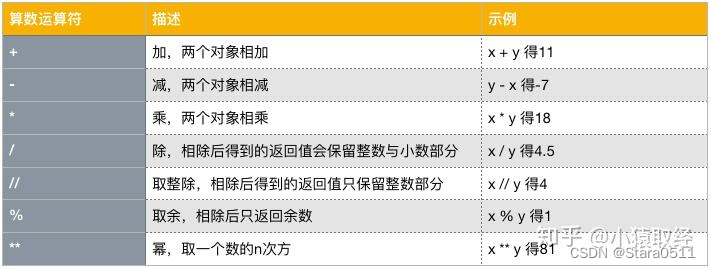
4.1 算术运算符
4.2比较运算符

4.3赋值运算符
4.3.1 增量赋值

4.3.2 链式赋值
>>> z=10
>>> y=z
>>> x=y
>>> x,y,z
(10, 10, 10)
>>> x=y=z=10
>>> x,y,z
(10, 10, 10)
4.3.3交叉赋值
>>> m=10
>>> n=20
>>> temp=m
>>> m=n
>>> n=temp
>>> m,n
(20, 10)
>>> m=10
>>> n=20
>>> m,n=n,m # 交叉赋值
>>> m,n
(20, 10)
4.3.4解压赋值
>>> nums=[11,22,33,44,55]
>>>
>>> a=nums[0]
>>> b=nums[1]
>>> c=nums[2]
>>> d=nums[3]
>>> e=nums[4]
>>> a,b,c,d,e
(11, 22, 33, 44, 55)
>>> a,b,c,d,e=nums # nums包含多个值,就好比一个压缩包,解压赋值因此得名
>>> a,b,c,d,e
(11, 22, 33, 44, 55)
注意,上述解压赋值,等号左边的变量名个数必须与右面包含值的个数相同,否则会报错
#1、变量名少了
>>> a,b=nums
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: too many values to unpack (expected 2)
#2、变量名多了
>>> a,b,c,d,e,f=nums
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: not enough values to unpack (expected 6, got 5)
但如果我们只想取头尾的几个值,可以用*_匹配
>>> a,b,*_=nums
>>> a,b
(11, 22)
ps:字符串、字典、元组、集合类型都支持解压赋值
4.4逻辑运算符

4.4.1连续多个and
>>> 2 > 1 and 1 != 1 and True and 3 > 2 # 判断完第二个条件,就立即结束,得的最终结果为False
False
4.4.2连续多个or
>>> 2 > 1 or 1 != 1 or True or 3 > 2 # 判断完第一个条件,就立即结束,得的最终结果为True
True
4.4.3优先级not>and>or
#1、三者的优先级关系:not>and>or,同一优先级默认从左往右计算。
>>> 3>4 and not 4>3 or 1==3 and 'x' == 'x' or 3 >3
False
#2、最好使用括号来区别优先级,其实意义与上面的一样
'''
原理为:
(1) not的优先级最高,就是把紧跟其后的那个条件结果取反,所以not与紧跟其后的条件不可分割
(2) 如果语句中全部是用and连接,或者全部用or连接,那么按照从左到右的顺序依次计算即可
(3) 如果语句中既有and也有or,那么先用括号把and的左右两个条件给括起来,然后再进行运算
'''
>>> (3>4 and (not 4>3)) or (1==3 and 'x' == 'x') or 3 >3
False
#3、短路运算:逻辑运算的结果一旦可以确定,那么就以当前处计算到的值作为最终结果返回
>>> 10 and 0 or '' and 0 or 'abc' or 'egon' == 'dsb' and 333 or 10 > 4
我们用括号来明确一下优先级
>>> (10 and 0) or ('' and 0) or 'abc' or ('egon' == 'dsb' and 333) or 10 > 4
短路: 0 '' 'abc'
假 假 真
返回: 'abc'
#4、短路运算面试题:
>>> 1 or 3
1
>>> 1 and 3
3
>>> 0 and 2 and 1
0
>>> 0 and 2 or 1
1
>>> 0 and 2 or 1 or 4
1
>>> 0 or False and 1
False
4.5成员运算符

注意:虽然下述两种判断可以达到相同的效果,但我们推荐使用第二种格式,因为not in语义更加明确
>>> not 'lili' in ['jack','tom','robin']
True
>>> 'lili' not in ['jack','tom','robin']
True
4.6身份运算符

需要强调的是:==双等号比较的是value是否相等,而is比较的是id是否相等
#1. id相同,内存地址必定相同,意味着type和value必定相同
#2. value相同type肯定相同,但id可能不同,如下
>>> x='Info Tony:18'
>>> y='Info Tony:18'
>>> id(x),id(y) # x与y的id不同,但是二者的值相同
(4327422640, 4327422256)
>>> x == y # 等号比较的是value
True
>>> type(x),type(y) # 值相同type肯定相同
(<class 'str'>, <class 'str'>)
>>> x is y # is比较的是id,x与y的值相等但id可以不同
False