LoRA 是如何工作的?
概述
纯笔记
LoRA的原理
LoRA其实是对稳定扩散模型最关键的部分进行了微小的改变。
这个关键的部分叫:cross-attention layers – 交叉注意力层。
研究人员发现,对这关键部分进行微调就足以实现良好的训练。
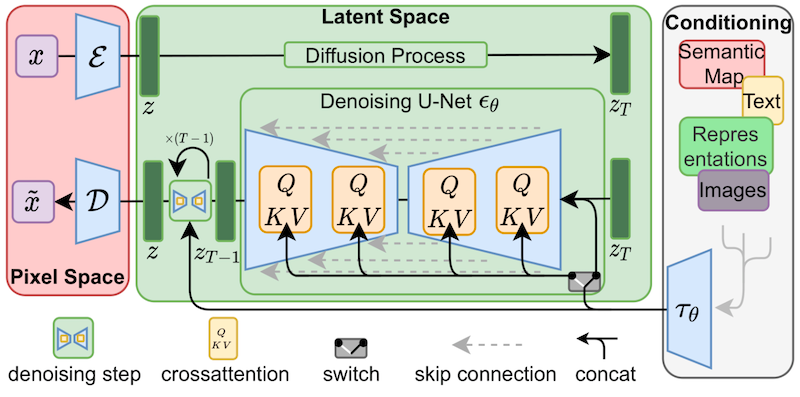
上面黄色部分,QKV 部分就是:交叉注意力层。
交叉注意力层里排列着权重,这些权重成矩阵的形式排列。就像Excel表格一样。
LoRA模型通过将权重添加到这些矩阵中来微调模型。
LoRA模型文件如何才能更小?
LoRA 的技巧是将矩阵分解为两个较小的(低秩)矩阵。通过这样做,它可以存储更少的数字。让我们用下面的例子来说明这一点:
假设该模型有一个包含 1000 行和 2000 列的矩阵。模型文件中需要存储 2,000,000 个数字 (1000 x 2000)。 LoRA 将矩阵分解为 1000×2 矩阵和 2×2000 矩阵。这只有 6,000 个数字 (1000 x 2 + 2 x 000),少了 333 倍。这就是 LoRA 文件小得多的原因。
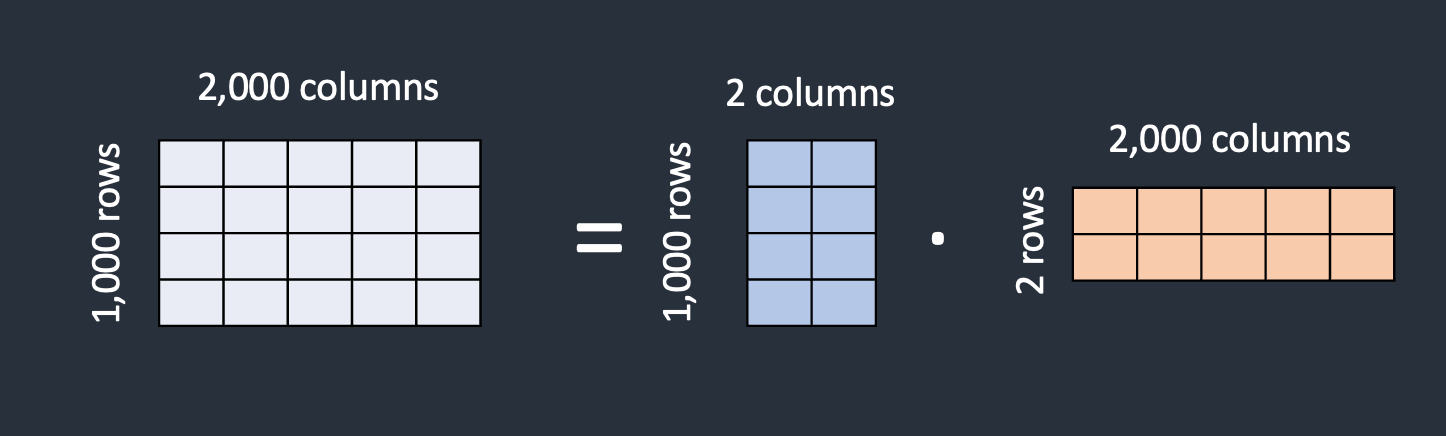
LoRA 将一个大矩阵分解为两个小的低秩矩阵。
在这个例子中,矩阵的秩为2。它比原始维度低得多,因此称为低秩矩阵。秩可以低至为1。
但这样的做有什么害处吗?研究人员发现,在交叉注意力层中这样做并不会影响微调的能力。所以没问题。
总结
- LoRA就是对
cross-attention layers– 交叉注意力层,进行了微调。 - 微调的关键点就是调整权重,并使用低秩矩阵替换原来的高秩矩阵。
参考地址: