数据库——底层原理
数据库
1.底层数据结构
B树是树的衍生,所以我打算从树开始讲起。
树我们都不陌生,有一个根节点,从根结点出发有他的孩子节点。但是简单的一棵树并没有什么特点,可能很难被实际应用。
之后出现了二叉树,这种树的每个节点最多只有两个孩子,这样一来,通过二叉树来实现二叉查找很大的提高了查找的速度。但是又有一个新问题出现了,除非二叉树被事先给出,否则二叉树可能会退化为链表。
再后来,为了解决退化问题,平衡二叉树被设计了出来,能够自动的根据树的高度来调节结点,使树上的节点分布均匀。再后来,不止对平衡二叉树进行查询操作,增加和删除结点效率的要求也提高了,因为如果要进行删除和增加节点,就需要维护这个二叉树保持原来的特点。
最后,为了解决增加和删除结点的效率,红黑树又出现了,在查询效率上,二者可能差不多,但是在修改结点的效率上,存在很大的差异。
随着大数据时代的到来,动辄就是千百万的数据量,使用二叉树来组织数据根本行不通,因为根据满二叉树的计算n = Log(2,N),查询时间还是不理想。
B树
关于B树的特点都已经展示在图中。为了降低二叉树的层数,在B书中,每个“结点”不止存放一个数据,目的就是为了增大每个结点所能容纳的数据量,降低树的层数。
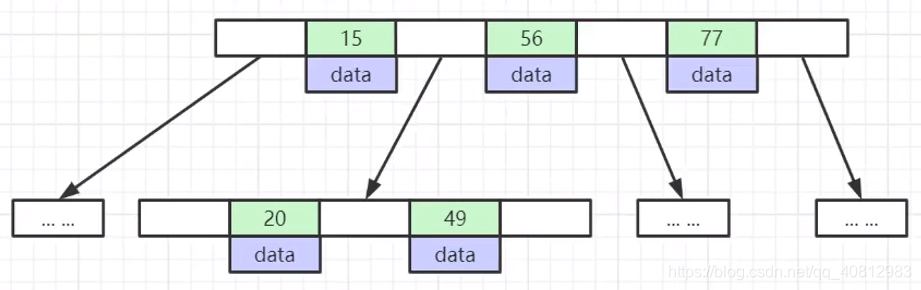
(关于B树的严格定义请自行百度)
- 每层包括N个实体结点和N+1个指针结点
- 每层结点都按照结点的Key值非递减的顺序排列
- 在Key值之间存在一个指针指向下一层结点,其中的Key值自然也是处于上层两个Key值之间
- 每个结点都直接带有自己的Data
- 对应每条记录都遍布在整个树中
B+树
B+树很大程度上是为了满足范围查找的需要,所以用双链表将所有的叶子结点都串起来;而且根据在磁盘I/O上所花的时间,要尽可能的减少磁盘I/O(每层的一个大结点通常被安排在一块物理内存上),所以会将所有的实体记录放在叶子节点上,非叶节点只存放键Key,不存放Data,这样一层的大结点能够存放更多的结点Key值,从而相应的减少磁盘I/O提高性能。
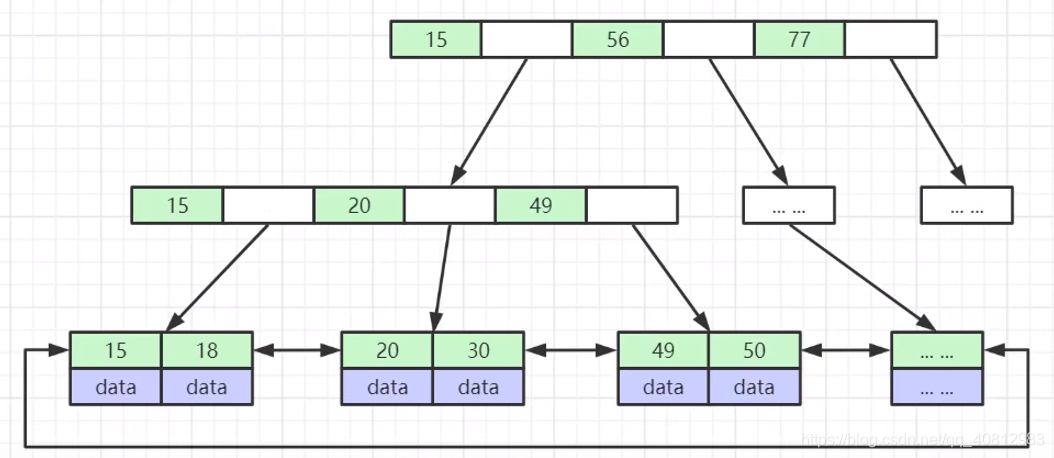
(关于B+树的严格定义请自行百度)
- 真实结点只放在叶子节点上,非叶节点只存放Key值
- 用双链表将叶子节点串联
- (这里还推荐使用Mysql中的自增主键,因为在随机插入时,难免会引起当前节点已经放满,再放时会出现分裂的操作,而按顺序递增的插入只会再最右边插入结点,并不会有分裂操作,效率较高)
2.Mysql数据库引擎
Innodb:Data数据直接存在于索引的叶节点中,支持事务,聚簇索引(数据和索引放一起,默认是主键完成,再次唯一非空索引,隐式索引,均称为辅助索引),不支持全文索引,最小粒度行锁
MyIsam:叶节点中只存放了Data的指针,不支持事务,非聚簇索引(数据和索引不放一起,存放地址),支持全文索引,最小粒度表锁
3.最左前缀优化原则
在生成索引时,如果是联合索引,则将会根据联合索引声明的顺序组织B+树的非叶节点,所以在使用Select在索引上查询时,会根据联合索引的顺序对每层节点进行排序,这才需要在使用Select语句时,注意是否使用了索引。
(未完待续。。。)