Mysql数据库数据结构
MySQL索引定义:索引(Index) 是帮助MySQL高效获取数据的数据结构。 提取句子主干, 就可以得到索引的本质: 索引是数据结构。
大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构
数据结构具体应用场景:
数据库是如何做到快速检索的功能。
特别有意思的小例子。
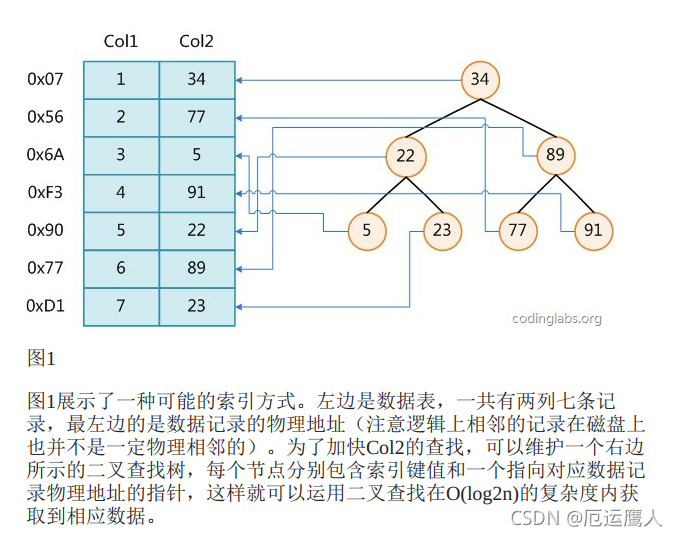
mysql索引原理的理解和数据结构
数据结构
B+树(为什么使用B+数)
- 所有数据都存储在磁盘中,读取数据由于IO问题会读取慢,如何加快IO速度
IO
- 量:减少IO量
*禁止使用slect ,避免增加不必要的量 - 次数:减少IO次数
相关知识点
- 加入索引(加快查询速度)
- 数据结构设计:key、文件编号、当前文件的offset(存在问题:当数据量特别大时,索引所占用的存储空间也特别大。)
- 解决方法:索引的数据文件也需要持久化存储到磁盘中,当需要使用时直接读取到内存中,加快数据的访问(分而治之:分块读取)
- 操作系统基本概念:
1.局部性原理:数据和程序都有聚集成群的倾向,之前被查询过的数据很快会再次被查询。冷热数据(一级缓存,二级缓存的意思)
2.磁盘预读:在数据交换时,会有一个基本逻辑单位页,一般占用空间是4k,每次在进行数据获取时可以获取整页的整数倍。(mysql中innodb的存储引擎读取数据会读取16k show variables like ‘%innodb’)
ket-value格式数据结构存储:
- 哈希表
- 树(二叉树、BST、AVL、红黑树、B树、B+树)
二分支的缺点:深度太深,解决方法:B树(多叉树)
B树
- 搜索树
- 多节点多分支的数
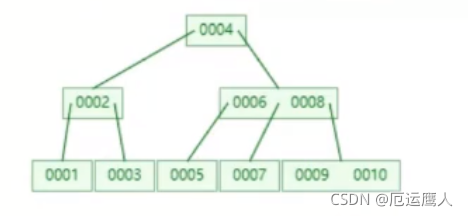
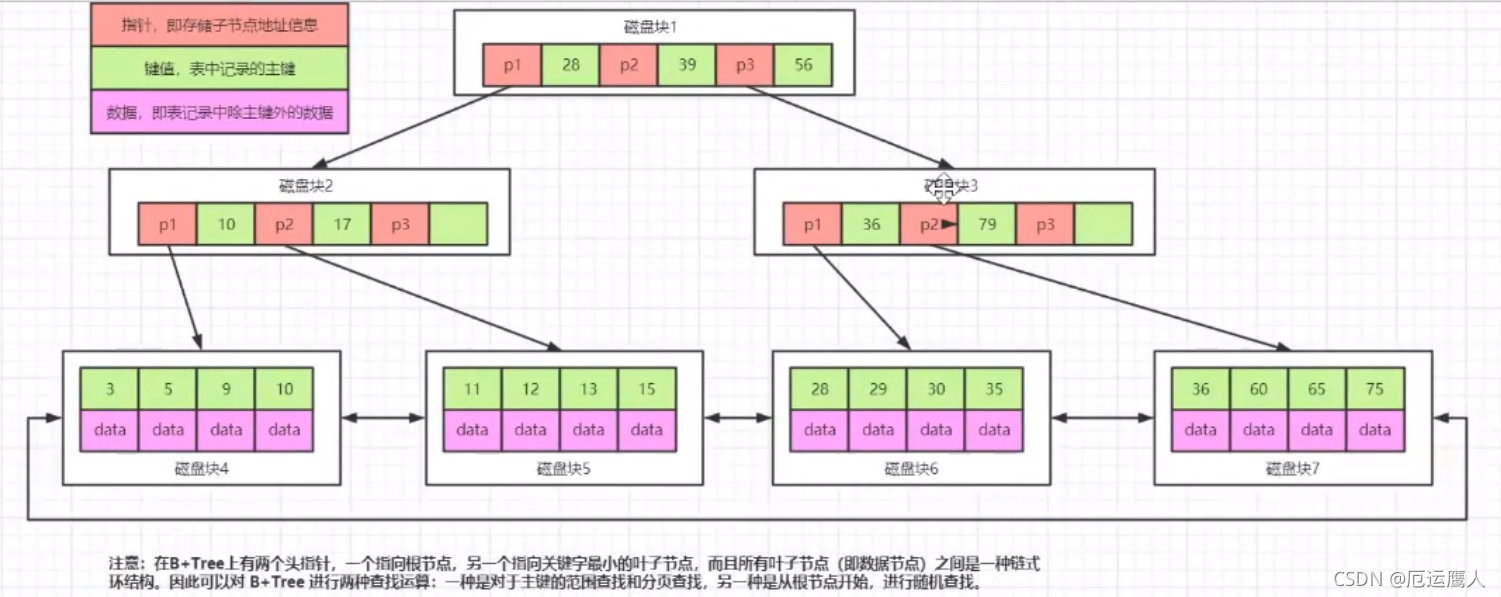
问题:假设磁盘块存放16条数据,如果是三层树,最多存放的数据:161616=4096,即48k才存放4096条数据
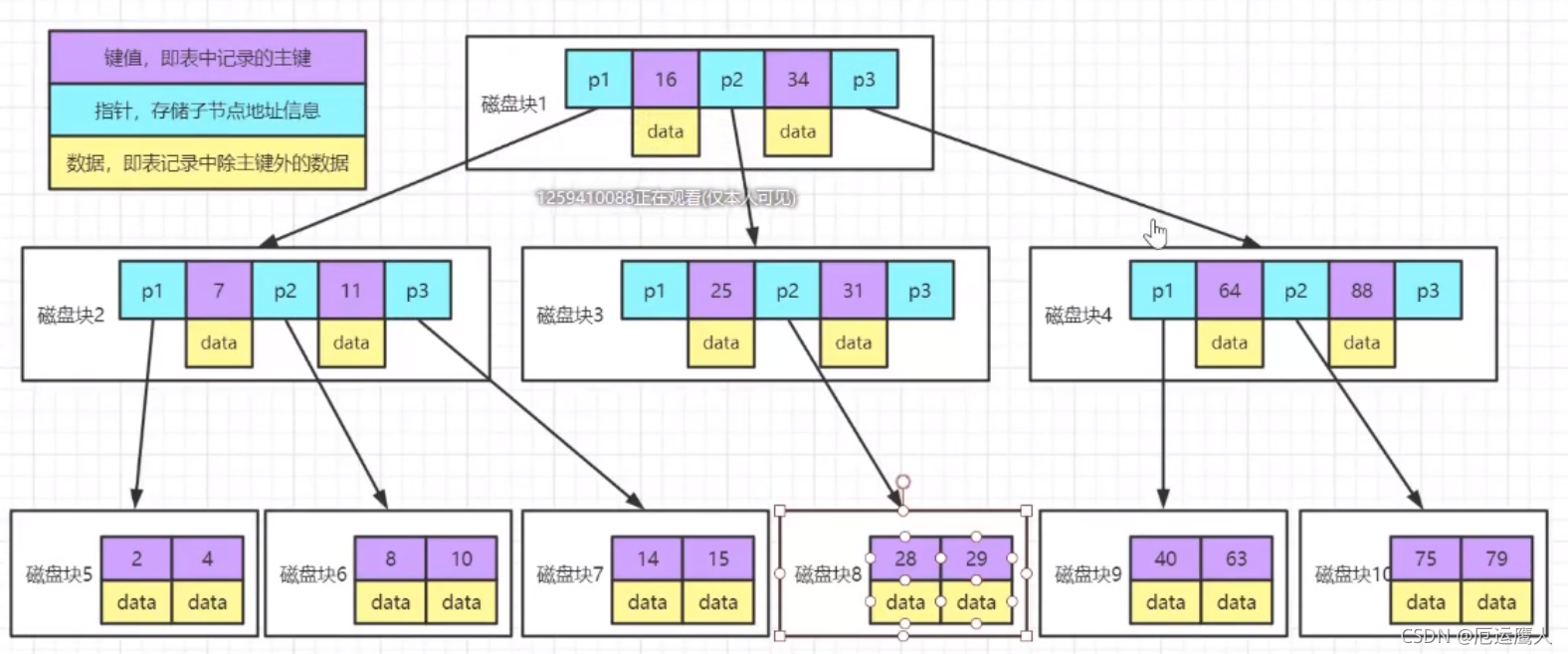
B数存在问题:存放了数据,依然占用空间,如何减少数据,需要用到B+数
B+树
- 最下面的叶子节点存放的是顺序全量数据
- 非叶子节点可以不用存放data
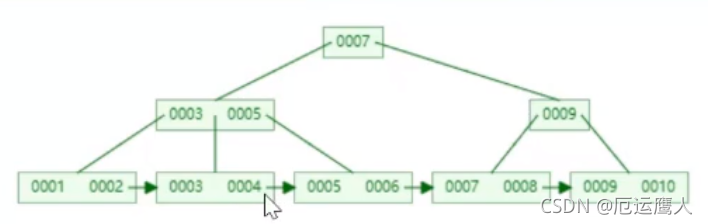
- 问题:读取数据,假设三层树48k磁盘块,1000字节为1kb,指针和键值占10字节,1行记录1k 161000/10=160016001600=40960000的数据范围,即Key键值,最下面的只存放一遍数据*
- 建索引时,key要尽可能少的占用空间
索引技术名词
**回表:**从非聚簇索引跳转到聚簇索引中查找数据的过程(避免回表操作select * from table )
索引覆盖当非聚簇索引的叶子节点中包含了查询需要的所有字段时,不需要回表的过程(推荐使用select id,name from table )
最左匹配:、索引下推