DRCN阅读笔记
本篇论文作者提出了在CNN中加入一个16次递归层,增加递归层深度可以有效提升性能表现,并且不为其他卷积层引入新的参数。由于使用标准的梯度下降DRCN很难训练,所以作者又提出了两个概念:递归监管和跳过连接
转载:receptive field 和 filter 的含义 https://blog.csdn.net/ture_dream/article/details/53240985
基础模型:
最初的模型主要包括三个副网络:嵌入,推断和重建网络
推断网络解决SR的主要问题。在该网络中,分析大图像区域由单个递归层完成。 每次递归都应用相同的整流线性单元的卷积。 对于大于1×1的卷积滤波器,每次递归都会扩大感受野。
MLP是啥?https://baike.baidu.com/item/MLP/17194455?fr=aladdin
嵌入网和推断网都是用3×3的filter,这是因为对嵌入网来说,图像梯度比超分辨率的原始图像数据所含信息更多;对于推断网来说,3×3的filter使得隐藏层状态只传递给相邻像素。重建网络同样十分重视直接相邻像素
嵌入网f1(x):
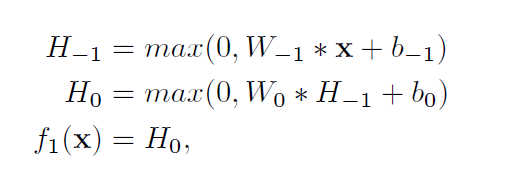
推断网f2(x):

重建网f3(x):
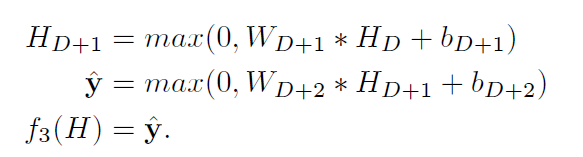
梯度爆炸:在训练过程中梯度发生巨大涨幅
梯度消失:与梯度爆炸相反
因为这两个原因,距离很远的两个像素的联系学习就变得非常困难,另外在多层递归下存储精确副本也没有想象中的容易
所以作者提出两个新模型:
递归监管:监管所有的递归来降低梯度消失/爆炸的影响。作者假设相同的表示在推断网的卷积层中可以一次又一次的使用,所有相同的重塑网也可以用来为所有的递归提供HR预测结果。所以重塑网输出D个预测结果(D即递归深度)并且同时监管训练中所有的预测结果。作者使用D个中间预测结果来计算最后的输出,这些结果在测试中被平均。w主要在训练过程中优化。显然,如果监测信号直接从损失层回到早期的递归层,反向传播的计算会容易很多
跳过连接:在SR中,输入输出图像高度相关,带着大多数的输入value到网络终端是不可避免但很没有效率的。由于梯度问题以及横跨在输入和输出之间的递归,学习一个input和output之间简单的线性关系是非常难的。所以作者添加了一个层可以直接从输入层跳跃到重建层,这对于语义分割网络来讲是非常成功的。有两个优点,一是网络可以在递归过程中存储输入信号,二是精确的输入副本信号可以在预测过程中使用。
语义分割网络?https://blog.csdn.net/sinat_35496345/article/details/79609529
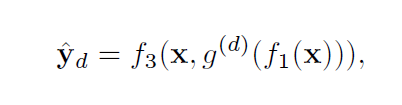
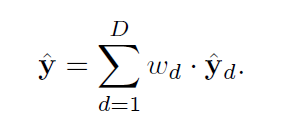
wd代表在递归过程中从每个中间隐藏状态重塑得到的预测的权重
最小二乘回归?

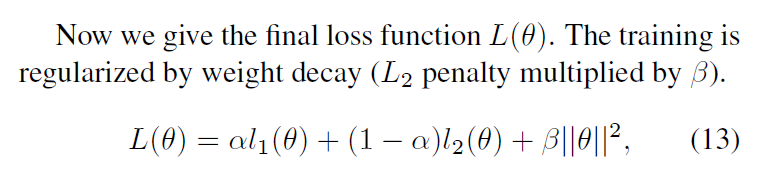
通过反向传播SGD优化
对于无递归层的w初始化使用he等人提出的方法,有递归层的则将所有w设置为0。所有层b设置为0。
最后DRCN的方法在相同的dataset上与现存的A+,RFL,SRCNN,SelfEx对比性能表现。有的方法比如A+和RFL无法预测图像边缘所以需要裁剪,DRCN并不需要,并且本方法产生了相对于图像的锐利的边缘,和其他方法所生成的HR的边缘是模糊的所不同。
结论:
DRCN有效地在利用大图像背景信息时重新使用了w参数。为了降低训练模型的难度,DRCN使用了递归检测和跳过连接,并且证明了本方法领先其他现存方法在基本dataset上。展望未来,可以尝试更深的递归层次来利用图像的背景信息。作者相信他们的方法可以很容易地应用于其他图像恢复问题,例如去噪和压缩伪影去除。