MapReduce实战案例:发现共同好友
mapreduce原理
MapReduce是一种编程模型,用于大规模数据集的并行运算,其中包含 Map(映射) 和 Reduce(归约) 两个阶段。
接下来以最经典的 Word Count 案例进行解析
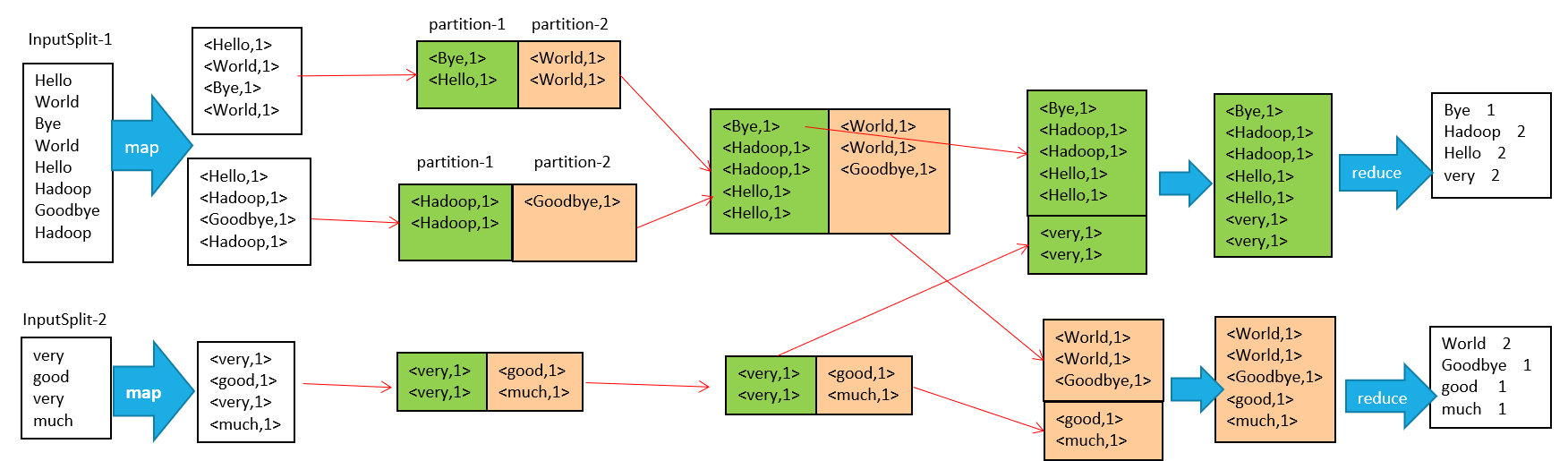
在MapReduce整个过程可以概括为以下过程:
输入 --> map --> shuffle --> reduce -->输出
流程说明如下:
-
输入文件分片,每一片都由一个MapTask来处理
-
Map输出的中间结果会先放在内存缓冲区中,这个缓冲区的大小默认是100M,当缓冲区中的内容达到80%时(80M)会将缓冲区的内容写到磁盘上。也就是说,一个map会输出一个或者多个这样的文件,如果一个map输出的全部内容没有超过限制,那么最终也会发生这个写磁盘的操作,只不过是写几次的问题。
-
从缓冲区写到磁盘的时候,会进行分区并排序,分区指的是某个key应该进入到哪个分区,同一分区中的key会进行排序,如果定义了Combiner的话,也会进行combine操作
-
如果一个map产生的中间结果存放到多个文件,那么这些文件最终会合并成一个文件,这个合并过程不会改变分区数量,只会减少文件数量。例如,假设分了3个区,4个文件,那么最终会合并成1个文件,3个区
-
以上只是一个map的输出,接下来进入reduce阶段
-
每个reducer对应一个ReduceTask,在真正开始reduce之前,先要从分区中抓取数据
-
相同的分区的数据会进入同一个reduce。这一步中会从所有map输出中抓取某一分区的数据,在抓取的过程中伴随着排序、合并。
-
reduce输出
案例背景
假设有以下好友列表,A的好友有B,C,D,F,E,O; B的好友有A,C,E,K
那我们要如何算出A-O用户每个用户之间的共同好友呢?
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
解决思路
下面我们将演示分步计算,思路主要如下:
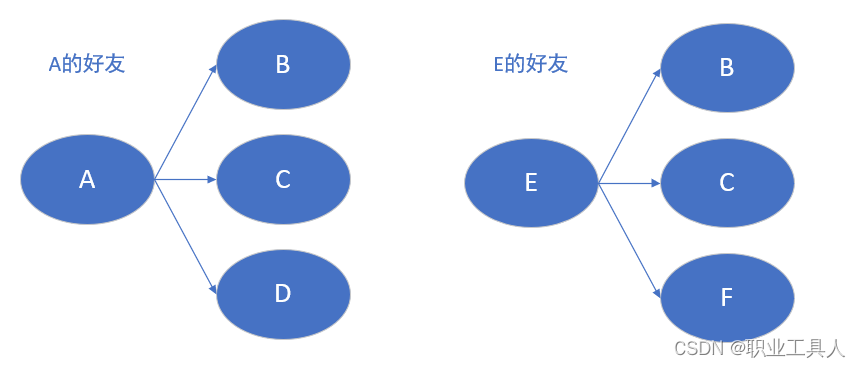
- 提取用户的好友列表
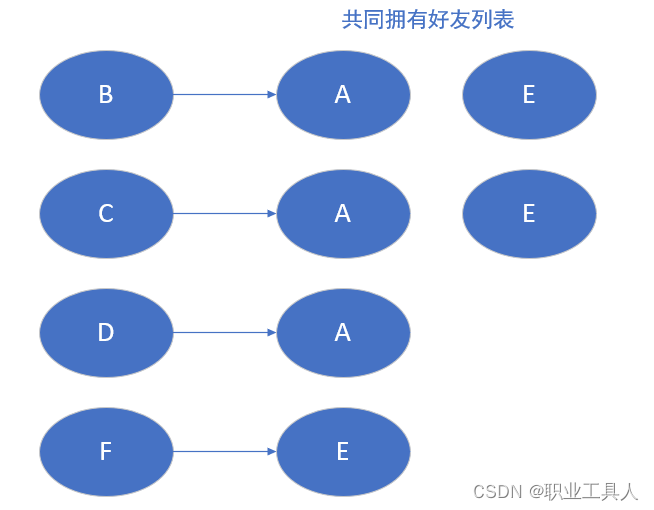
- 提取共同好友
代码实现
由上可知,此次计算由两步组成,因此需要两个MapReduce程序先后执行
Maven项目配置
在编写程序前需要先导入Maven依赖与打包插件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!--此处为Maven项目信息-->
<groupId></groupId>
<artifactId></artifactId>
<version></version>
<!--Maven项目全局配置-->
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<!--Hadoop依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.7</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--打包插件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<mainClass></mainClass> <!-- 此处为主入口函数,需自行填写-->
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>
Step 1
第一步:通过mapreduce得到某个用户是哪些用户的共同好友
/**
* Mapper<> 定义的是两对键值对的泛型
* 即为输入键值对与输出键值对
* LongWritable 对应 long
* Text 对应 String
*/
public class FriendListMap extends Mapper<LongWritable, Text,Text,Text> {
//重现map方法
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException {
// 读取需要处理的文件内容
String line = value.toString();
// 将内容进行分割
// A:B,C,D,F,E,O
String[] split = line.split(":");
// 第一部分为用户
// A
String user = split[0];
// 第二部分为用户拥有的好友列表
// [B,C,D,F,E,O]
String[] friends = split[1].split(",");
// 遍历好友列表
for(String friend: friends){
// 生成键值对
// {B:A},{C:A},{D:A},{F:A},{E,A},{O,A}
context.write(new Text(friend),new Text(user));
}
}
}
/**
* Reducer<>定义两个键值对的泛型
* 与Mapper<>一致
*/
public class FriendListReduce extends Reducer<Text,Text,Text,Text> {
// 重写reduce方法,将Map过程生成的键值对进行聚合
@Override
public void reduce(Text key,Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 生成一个StringBuffer对象
StringBuffer sb = new StringBuffer();
// 将键值对的values进行拼接
for (Text person : values){
sb.append(person).append(",");
}
// 最后生成新的键值对
context.write(key,new Text(sb.toString().substring(0,sb.length())));
}
}
public class FriendListJob {
public static void main(String[] args) throws Exception {
// 导入配置
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,"step1");
// 指定主类
job.setJarByClass(FriendListJob.class);
// 指定mapper类与reduce类
job.setMapperClass(FriendListMap.class);
job.setReducerClass(FriendListReduce.class);
// 指定输出的键值对类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 指定输入文件与输入文件的路径(需要是HDFS内部路径)
String prefix = "hdfs://192.168.50.133:9000";
FileInputFormat.setInputPaths(job,new Path(prefix + args[0]));
FileOutputFormat.setOutputPath(job,new Path(prefix + args[1]));
// 保证程序运行完成时退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}

Step 2
由上一步可以得知,I,K,C,B,G,F,H,O,D都有好友A;A,F,J,E都有好友B。
接下来我们只需组合这些拥有相同的好友的用户,作为key发送给reduce,由reduce端聚合d得到所有共同的好友
public class SameFriendMap extends Mapper<LongWritable, Text, Text, Text> {
// 重写map方法
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 获取读取文件内容
String line = value.toString();
// 分割数据
String[] split = line.split("\t");
// 第一个元素为好友
String friend = split[0];
// 第二个元素为好友拥有的好友
String[] persons = split[1].split(",");
// 将数组进行排序,避免出现重复的情况 A--B B--A
Arrays.sort(persons);
// 进行匹配
for(int i = 0;i<persons.length-1;i++){
for(int j = i+1;j<persons.length;j++){
context.write(new Text(persons[i]+ "--" +persons[j]),new Text(friend));
}
}
}
}
public class SameFriendReduce extends Reducer<Text,Text,Text,Text> {
// 重写reduce方法
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//声明StringBuffer对象
StringBuffer sb = new StringBuffer();
// 拼接值一样的结果
for(Text friend : values){
sb.append(friend).append(",");
}
// 整合Map的键值对
context.write(key,new Text(sb.toString().substring(0,sb.length()-1)));
}
}
public class SameFriendJob {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 导入配置
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,"step2");
// 指定主类
job.setJarByClass(SameFriendJob.class);
// 指定mapper类与reduce类
job.setMapperClass(SameFriendMap.class);
job.setReducerClass(SameFriendReduce.class);
// 指定输出的键值对类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 指定输入文件与输入文件的路径(需要是HDFS内部路径)
String prefix = "hdfs://192.168.50.133:9000";
FileInputFormat.setInputPaths(job,new Path(prefix + "/output/part-r-00000"));
FileOutputFormat.setOutputPath(job,new Path(prefix + args[0]));
// 保证程序运行完成时退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}

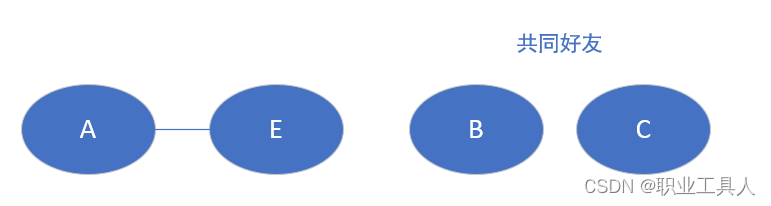
如图,我们就得到了拥有共同好友的用户列表及其对应关系,在实际场景中再根据用户关系(如是否已经是好友)进行过滤,就形成了我们所看到"可能认识"或者"好友推荐"啦