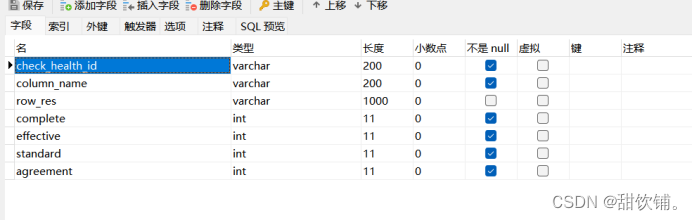
SparkDF存储目标表修改字段类型解决过程
原始问题,指定前三个字段类型后,SparkDF存储数据后出现,更改字段类型
添加插入配置进行测试
rowResult1.write
.mode(SaveMode.Overwrite)
.option("createTableColumnTypes", "check_health_id varchar(200), column_name varchar(200), row_res varchar(1000), complete int, effective int, standard int, agreement int")
.jdbc(url, "health_archives_update", prop)
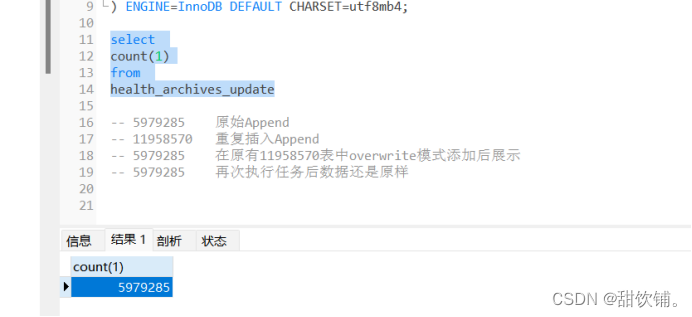
测试Append插入是否会发生改变
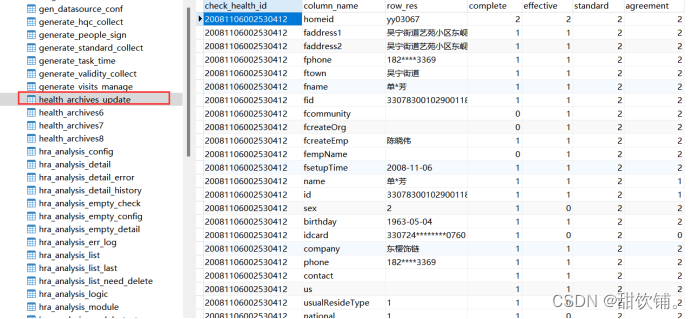
再次使用Append模式再次插入后
字段类型没有发生改变
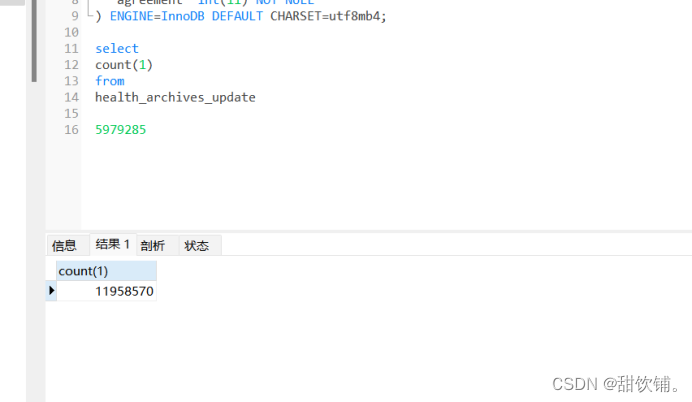
更换代码为overwrite模式测试
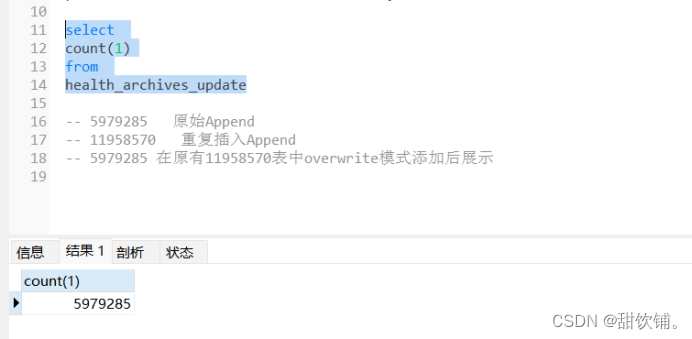
表字段没有发生改变。
再次执行任务查看
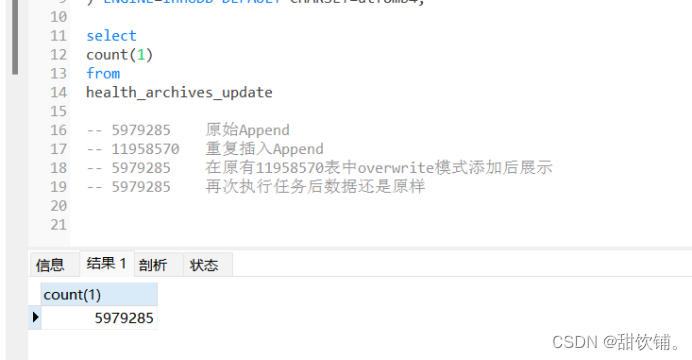
字段类型没有发生改变
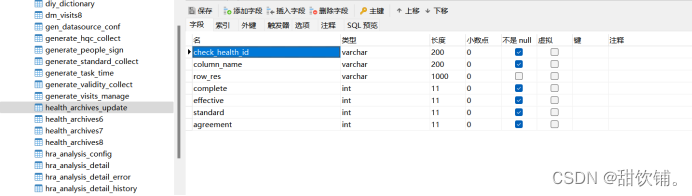
测试表是否区分大小写

更换为小写U,测试没有影响
类型没有发生改变
PS: 此次出现的问题为SparkDF字段类型为以下所示
root
|-- check_health_id: string (nullable = true)
|-- column_name: string (nullable = true)
|-- row_res: string (nullable = true)
|-- complete: integer (nullable = true)
|-- effective: integer (nullable = true)
|-- standard: integer (nullable = true)
|-- agreement: integer (nullable = true)
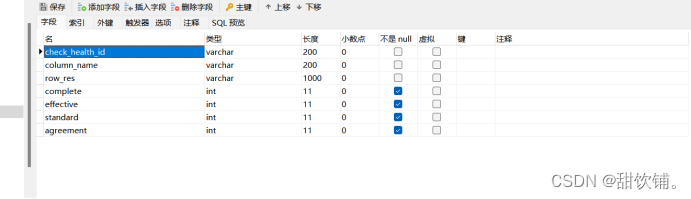
Mysql存储格式为
CREATE TABLE
health_archives_Update(check_health_idvarchar(200) NOT NULL,column_namevarchar(200),row_resvarchar(1000),completeint(11) NOT NULL,effectiveint(11) NOT NULL,standardint(11) NOT NULL,agreementint(11) NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
当在使用rowResult1.write.mode(SaveMode.Overwrite).jdbc(url, “health_archives_update”, prop)存储时出现check_health_id、column_name、row_res统一更改字段类型为text
原因在于:
因为SparkDF中的check_health_id、column_name、row_res字段被推断为字符串类型string,而MySQL表中的该字段定义为varchar类型,所以在写入数据时Spark会尝试将string类型转换为MySQL中的varchar类型。由于varchar类型是可变长度的字符类型,因此MySQL JDBC驱动程序可能会将Spark中的string类型映射为MySQL中的text类型。
为了解决这个问题,尝试更换.option(“createTableColumnTypes”, “check_health_id varchar(200), column_name varchar(200), row_res varchar(1000), complete int, effective int, standard int, agreement int”)来指定创建表时的列类型,这样Spark就会将check_health_id、column_name、row_res字段定义为varchar(指定的数据长度)类型。
注意:
Option指定的数据类型必须要与SparkDF的列名、数据类型匹配,否则会导致写入过程发生异常(存在删除表,数据插入失败)直接跳过存储步骤结束任务
此外还必须要与Mysql表的列名和数据类型匹配,否则也会出现导入失败或发生数据转换错误。
另外,在覆盖已存在的表时,目标表的结构将不会更改,因此在这种情况下,option参数的设置可能会被忽略。