记录一些报错
1.random.sample函数
1.1错误提示
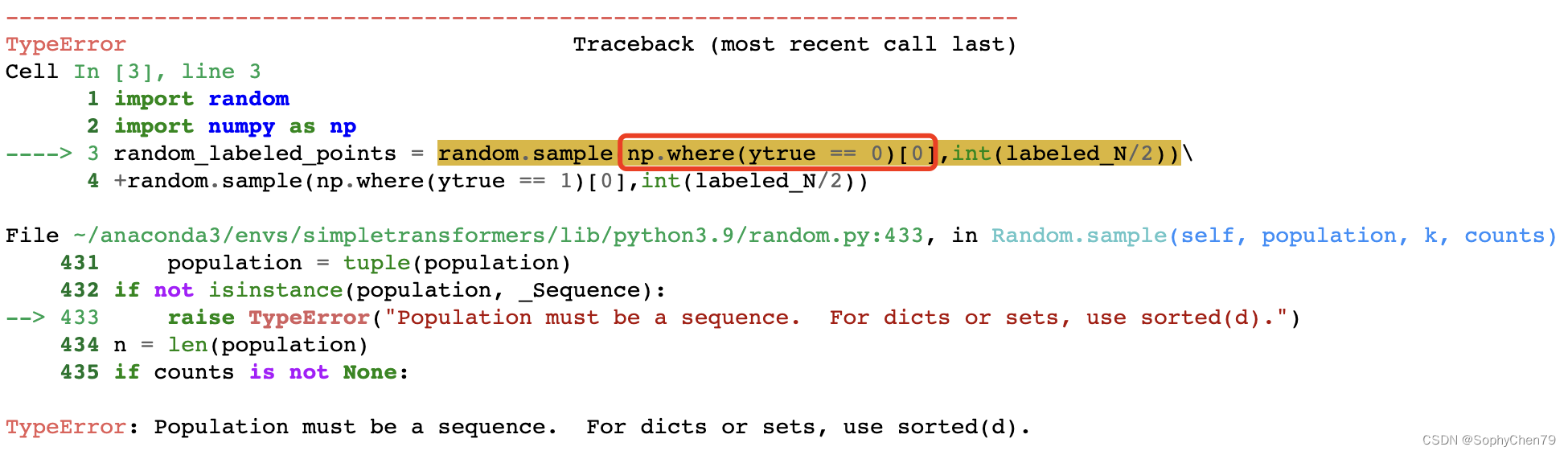
TypeError: Population must be a sequence. For dicts or sets, use sorted(d).
1.2 原因分析
是因为我们random.sample里面没有使用list,而是set
1.3 解决方法
用list()包起来即可
list(np.where(ytrue == 0)[0])

2.数组形状不同,拼接出错
2.1 错误提示

ValueError: setting an array element with a sequence.
ValueError: float() argument must be a string or a number, not ‘csr_matrix’
2.2 原因分析
这里的特征矩阵是稀疏矩阵,输入到模型里的数据没严格转换成 np.arry()形式,要对其进行转换
使用 .toarray()
2.3 解决方法
model.fit(numpy.vstack((labeledX.toarray(), unlabeledX[uidx].toarray())), numpy.hstack((labeledy, unlabeledy_old[uidx])))
3.XGBClassifier
3.1 错误提示
Starting in XGBoost 1.3.0, the default evaluation metric used with the objective ‘binary:logistic’ was changed from ‘error’ to ‘logloss’. Explicitly set eval_metric if you’d like to restore the old behavior.
3.2 原因分析
eval_metric是评价函数,对模型的训练没有影响,而是在模型训练完成之后评估模型效果。如我们经常使用logloss作为objective,经常与之搭配的评价函数是auc、acc等。
回归任务 (默认rmse)
rmse–均方根误差
mae–平均绝对误差
分类任务 (默认error)
auc–roc曲线下面积
error–错误率(二分类)
merror–错误率(多分类)
logloss–负对数似然函数(二分类)
mlogloss–负对数似然函数(多分类)
map–平均正确率
3.3 解决方法
拟合模型时加上 eval_metric 参数
model.fit(train, train, eval_metric='error')
4.mac打不开jupyter
4.1 错误提示
The file /Users/sophychen/anaconda3/envs/comap/bin/jupyter_mac.command does not exist.