高光谱图像分类--HybridSN: Exploring 3-D–2-DCNN Feature Hierarchy for Hyperspectral Image Classification
《HybridSN: Exploring 3-D–2-DCNN Feature Hierarchy for Hyperspectral Image Classification》
S. K. Roy, G. Krishna, S. R. Dubey, B. B. Chaudhuri HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification, IEEE GRSL 2020
这篇论文构建了一个 混合网络 (3D卷积+2D卷积)解决高光谱图像分类问题。
Q:3D卷积和2D卷积的区别?
首先两者都是多通道卷积,而3D卷积比2D卷积多一个深度信息,本质上是一样的,因为2D卷积可以默认深度信息为1。
2D卷积 shape:(batch_size, channel, height, weight)
3D卷积shape:(batch_size, channel, depth, height, weight)
模型网络结构
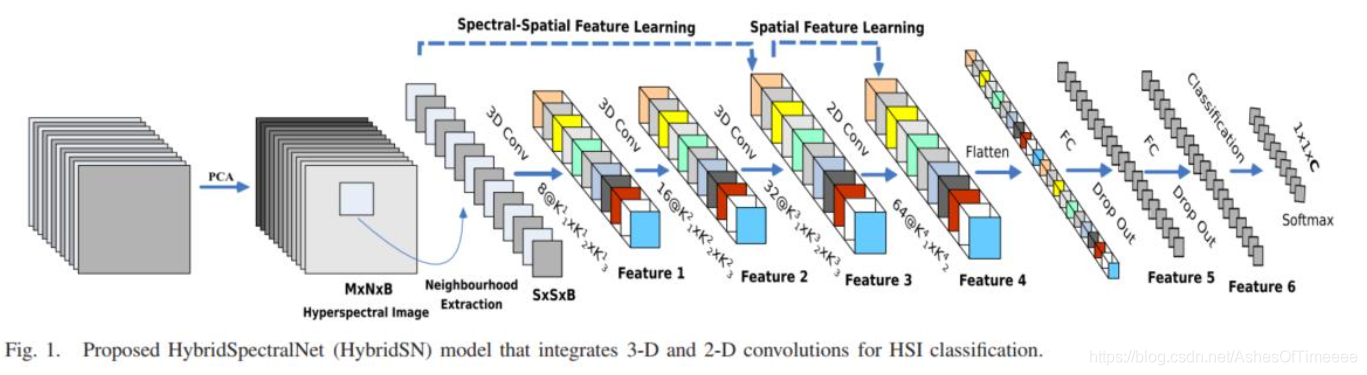
三维卷积部分:
conv1:(1, 30, 25, 25), 8个 7x3x3 的卷积核 ==>(8, 24, 23, 23)
conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21)
conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19)
二维卷积
把前面的 32*18 reshape 一下,得到 (576, 19, 19)
接下来是一个 flatten 操作,变为 18496 维的向量
接下来依次为256,128节点的全连接层,都使用比例为0.4的 Dropout
最后输出为 16 个节点,是最终的分类类别数
网络结构
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
self.conv3d_1 = nn.Sequential(
nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(8),
nn.ReLU(inplace = True),
)
self.conv3d_2 = nn.Sequential(
nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(16),
nn.ReLU(inplace = True),
)
self.conv3d_3 = nn.Sequential(
nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU(inplace = True)
)
self.conv2d_4 = nn.Sequential(
nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0),
nn.BatchNorm2d(64),
nn.ReLU(inplace = True),
)
self.fc1 = nn.Linear(18496,256)
self.fc2 = nn.Linear(256,128)
self.fc3 = nn.Linear(128,16)
self.dropout = nn.Dropout(p = 0.4)
def forward(self,x):
out = self.conv3d_1(x)
out = self.conv3d_2(out)
out = self.conv3d_3(out)
out = self.conv2d_4(out.reshape(out.shape[0],-1,19,19))
out = out.reshape(out.shape[0],-1)
out = F.relu(self.dropout(self.fc1(out)))
out = F.relu(self.dropout(self.fc2(out)))
out = self.fc3(out)
return out
开始训练
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 网络放到GPU上
net = HybridSN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
# 开始训练
total_loss = 0
for epoch in range(100):
for i, (inputs, labels) in enumerate(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
print('[Epoch: %d] [loss avg: %.4f] [current loss: %.4f]' %(epoch + 1, total_loss/(epoch+1), loss.item()))
print('Finished Training')
[Epoch: 1] [loss avg: 19.6715] [current loss: 1.9873]
[Epoch: 2] [loss avg: 15.6281] [current loss: 1.0401]
[Epoch: 3] [loss avg: 13.1159] [current loss: 0.8418]
[Epoch: 4] [loss avg: 11.2389] [current loss: 0.5678]
[Epoch: 5] [loss avg: 9.6885] [current loss: 0.3103]
[Epoch: 6] [loss avg: 8.4845] [current loss: 0.2024]
[Epoch: 7] [loss avg: 7.5417] [current loss: 0.1180]
[Epoch: 8] [loss avg: 6.7961] [current loss: 0.2098]
[Epoch: 9] [loss avg: 6.1619] [current loss: 0.2179]
[Epoch: 10] [loss avg: 5.6341] [current loss: 0.0968]
[Epoch: 11] [loss avg: 5.1822] [current loss: 0.1244]
[Epoch: 12] [loss avg: 4.7971] [current loss: 0.0295]
[Epoch: 13] [loss avg: 4.4596] [current loss: 0.0777]
[Epoch: 14] [loss avg: 4.1665] [current loss: 0.0476]
[Epoch: 15] [loss avg: 3.9178] [current loss: 0.0910]
[Epoch: 16] [loss avg: 3.6988] [current loss: 0.0331]
[Epoch: 17] [loss avg: 3.5068] [current loss: 0.0327]
[Epoch: 18] [loss avg: 3.3333] [current loss: 0.0324]
[Epoch: 19] [loss avg: 3.1683] [current loss: 0.0548]
[Epoch: 20] [loss avg: 3.0232] [current loss: 0.0196]
[Epoch: 21] [loss avg: 2.8877] [current loss: 0.0215]
[Epoch: 22] [loss avg: 2.7742] [current loss: 0.0244]
[Epoch: 23] [loss avg: 2.6641] [current loss: 0.0139]
[Epoch: 24] [loss avg: 2.5632] [current loss: 0.0097]
[Epoch: 26] [loss avg: 2.3853] [current loss: 0.0657]
[Epoch: 27] [loss avg: 2.3084] [current loss: 0.0164]
[Epoch: 28] [loss avg: 2.2347] [current loss: 0.0143]
[Epoch: 29] [loss avg: 2.1671] [current loss: 0.0189]
[Epoch: 30] [loss avg: 2.1063] [current loss: 0.0331]
[Epoch: 31] [loss avg: 2.0429] [current loss: 0.0220]
[Epoch: 32] [loss avg: 1.9878] [current loss: 0.0173]
[Epoch: 33] [loss avg: 1.9329] [current loss: 0.0154]
[Epoch: 34] [loss avg: 1.8801] [current loss: 0.0306]
[Epoch: 35] [loss avg: 1.8305] [current loss: 0.0442]
[Epoch: 36] [loss avg: 1.7823] [current loss: 0.0077]
[Epoch: 37] [loss avg: 1.7399] [current loss: 0.0359]
[Epoch: 38] [loss avg: 1.6970] [current loss: 0.0004]
[Epoch: 39] [loss avg: 1.6546] [current loss: 0.0198]
[Epoch: 40] [loss avg: 1.6153] [current loss: 0.0126]
[Epoch: 41] [loss avg: 1.5795] [current loss: 0.0608]
[Epoch: 42] [loss avg: 1.5454] [current loss: 0.0296]
[Epoch: 43] [loss avg: 1.5121] [current loss: 0.0053]
[Epoch: 44] [loss avg: 1.4795] [current loss: 0.0325]
[Epoch: 45] [loss avg: 1.4492] [current loss: 0.0058]
[Epoch: 46] [loss avg: 1.4193] [current loss: 0.0130]
[Epoch: 47] [loss avg: 1.3904] [current loss: 0.0055]
[Epoch: 48] [loss avg: 1.3622] [current loss: 0.0013]
[Epoch: 49] [loss avg: 1.3354] [current loss: 0.0110]
[Epoch: 50] [loss avg: 1.3093] [current loss: 0.0041]
[Epoch: 51] [loss avg: 1.2845] [current loss: 0.0004]
[Epoch: 52] [loss avg: 1.2607] [current loss: 0.0028]
[Epoch: 53] [loss avg: 1.2375] [current loss: 0.0109]
[Epoch: 54] [loss avg: 1.2150] [current loss: 0.0010]
[Epoch: 55] [loss avg: 1.1934] [current loss: 0.0008]
[Epoch: 56] [loss avg: 1.1725] [current loss: 0.0011]
[Epoch: 57] [loss avg: 1.1524] [current loss: 0.0044]
[Epoch: 58] [loss avg: 1.1331] [current loss: 0.0012]
[Epoch: 59] [loss avg: 1.1151] [current loss: 0.0092]
[Epoch: 60] [loss avg: 1.0982] [current loss: 0.0035]
[Epoch: 61] [loss avg: 1.0822] [current loss: 0.0062]
[Epoch: 62] [loss avg: 1.0671] [current loss: 0.0412]
[Epoch: 63] [loss avg: 1.0517] [current loss: 0.0006]
[Epoch: 64] [loss avg: 1.0367] [current loss: 0.0206]
[Epoch: 65] [loss avg: 1.0213] [current loss: 0.0052]
[Epoch: 66] [loss avg: 1.0071] [current loss: 0.0027]
[Epoch: 67] [loss avg: 0.9940] [current loss: 0.0268]
[Epoch: 68] [loss avg: 0.9807] [current loss: 0.0500]
[Epoch: 69] [loss avg: 0.9686] [current loss: 0.0058]
[Epoch: 70] [loss avg: 0.9561] [current loss: 0.0032]
[Epoch: 71] [loss avg: 0.9454] [current loss: 0.0004]
[Epoch: 72] [loss avg: 0.9352] [current loss: 0.0764]
[Epoch: 73] [loss avg: 0.9268] [current loss: 0.0020]
[Epoch: 74] [loss avg: 0.9178] [current loss: 0.0977]
[Epoch: 75] [loss avg: 0.9097] [current loss: 0.0547]
[Epoch: 76] [loss avg: 0.8997] [current loss: 0.0115]
[Epoch: 77] [loss avg: 0.8921] [current loss: 0.0407]
[Epoch: 78] [loss avg: 0.8830] [current loss: 0.0063]
[Epoch: 79] [loss avg: 0.8748] [current loss: 0.0147]
[Epoch: 80] [loss avg: 0.8664] [current loss: 0.0070]
[Epoch: 81] [loss avg: 0.8570] [current loss: 0.0042]
[Epoch: 82] [loss avg: 0.8473] [current loss: 0.0022]
[Epoch: 83] [loss avg: 0.8382] [current loss: 0.0274]
[Epoch: 84] [loss avg: 0.8300] [current loss: 0.0600]
[Epoch: 85] [loss avg: 0.8209] [current loss: 0.0004]
[Epoch: 86] [loss avg: 0.8125] [current loss: 0.0008]
[Epoch: 87] [loss avg: 0.8038] [current loss: 0.0005]
[Epoch: 88] [loss avg: 0.7961] [current loss: 0.0016]
[Epoch: 89] [loss avg: 0.7889] [current loss: 0.0196]
[Epoch: 90] [loss avg: 0.7812] [current loss: 0.0037]
[Epoch: 91] [loss avg: 0.7748] [current loss: 0.0013]
[Epoch: 92] [loss avg: 0.7674] [current loss: 0.0358]
[Epoch: 93] [loss avg: 0.7600] [current loss: 0.0045]
[Epoch: 94] [loss avg: 0.7533] [current loss: 0.0483]
[Epoch: 95] [loss avg: 0.7462] [current loss: 0.0121]
[Epoch: 96] [loss avg: 0.7389] [current loss: 0.0052]
[Epoch: 97] [loss avg: 0.7316] [current loss: 0.0117]
[Epoch: 98] [loss avg: 0.7260] [current loss: 0.0028]
[Epoch: 99] [loss avg: 0.7200] [current loss: 0.0115]
[Epoch: 100] [loss avg: 0.7136] [current loss: 0.0001]
Finished Training
模型测试
count = 0
# 模型测试
for inputs, _ in test_loader:
inputs = inputs.to(device)
outputs = net(inputs)
outputs = np.argmax(outputs.detach().cpu().numpy(), axis=1)
if count == 0:
y_pred_test = outputs
count = 1
else:
y_pred_test = np.concatenate( (y_pred_test, outputs) )
# 生成分类报告
classification = classification_report(ytest, y_pred_test, digits=4)
print(classification)
precision recall f1-score support
0.0 0.9444 0.8293 0.8831 41
1.0 0.9769 0.9525 0.9645 1285
2.0 0.9723 0.9853 0.9787 747
3.0 0.9947 0.8779 0.9327 213
4.0 0.9861 0.9793 0.9827 435
5.0 0.9877 0.9802 0.9840 657
6.0 1.0000 0.9600 0.9796 25
7.0 0.9817 1.0000 0.9908 430
8.0 0.7727 0.9444 0.8500 18
9.0 0.9875 0.9909 0.9892 875
10.0 0.9725 0.9910 0.9816 2210
11.0 0.9499 0.9588 0.9543 534
12.0 0.9572 0.9676 0.9624 185
13.0 0.9887 0.9965 0.9926 1139
14.0 0.9826 0.9741 0.9783 347
15.0 0.8933 0.7976 0.8428 84
accuracy 0.9767 9225
macro avg 0.9593 0.9491 0.9529 9225
weighted avg 0.9768 0.9767 0.9765 9225
准确率达到了97.67.
Q:通过上文中训练网络,然后多测试几次,会发现每次分类的结果都不一样,请思考为什么?
A: 网络的全连接层中使用了 nn.Dropout,网络层的节点会随机失活。因此测试的时候没有启用测试模式。
解决方法:
训练时:
net.train()
测试时:
net.eval()
显示分类结果
# load the original image
X = sio.loadmat('Indian_pines_corrected.mat')['indian_pines_corrected']
y = sio.loadmat('Indian_pines_gt.mat')['indian_pines_gt']
height = y.shape[0]
width = y.shape[1]
X = applyPCA(X, numComponents= pca_components)
X = padWithZeros(X, patch_size//2)
# 逐像素预测类别
outputs = np.zeros((height,width))
for i in range(height):
for j in range(width):
if int(y[i,j]) == 0:
continue
else :
image_patch = X[i:i+patch_size, j:j+patch_size, :]
image_patch = image_patch.reshape(1,image_patch.shape[0],image_patch.shape[1], image_patch.shape[2], 1)
X_test_image = torch.FloatTensor(image_patch.transpose(0, 4, 3, 1, 2)).to(device)
prediction = net(X_test_image)
prediction = np.argmax(prediction.detach().cpu().numpy(), axis=1)
outputs[i][j] = prediction+1
if i % 20 == 0:
print('... ... row ', i, ' handling ... ...')
… … row 0 handling … …
… … row 20 handling … …
… … row 40 handling … …
… … row 60 handling … …
… … row 80 handling … …
… … row 100 handling … …
… … row 120 handling … …
… … row 140 handling … …
predict_image = spectral.imshow(classes = outputs.astype(int),figsize =(5,5))
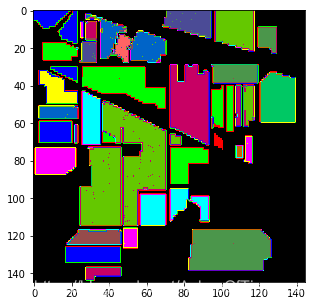
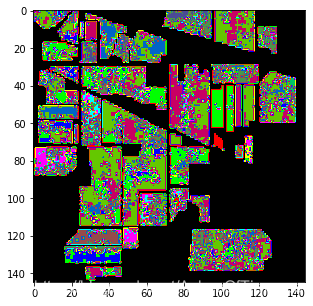
原始代码结果:
增加训练测试模式代码结果:
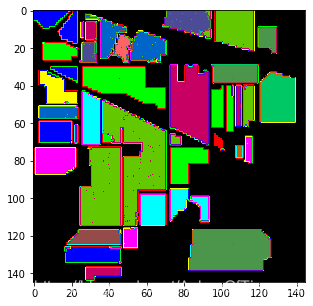
可以看出分类效果也明显变好了。
加入注意力机制
Q:如果想要进一步提升高光谱图像的分类性能,可以如何使用注意力机制?
class_num = 16
# 通道注意力机制
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
# 空间注意力机制
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class HybridSN(nn.Module):
def __init__(self, num_classes, self_attention=False):
super(HybridSN, self).__init__()
self.conv3d_1 = nn.Sequential(
nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(8),
nn.ReLU(inplace = True),
)
self.self_attention = self_attention #默认
self.conv3d_2 = nn.Sequential(
nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(16),
nn.ReLU(inplace = True),
)
self.conv3d_3 = nn.Sequential(
nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU(inplace = True)
)
if self_attention:
self.channel_attention_1 = ChannelAttention(576)
self.spatial_attention_1 = SpatialAttention(kernel_size=7)
self.conv2d_4 = nn.Sequential(
nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0),
nn.BatchNorm2d(64),
nn.ReLU(inplace = True),
)
if self_attention:
self.channel_attention_1 = ChannelAttention(576)
self.spatial_attention_1 = SpatialAttention(kernel_size=7)
self.fc1 = nn.Linear(18496,256)
self.fc2 = nn.Linear(256,128)
self.fc3 = nn.Linear(128,16)
self.dropout = nn.Dropout(p = 0.4)
def forward(self,x):
out = self.conv3d_1(x)
out = self.conv3d_2(out)
out = self.conv3d_3(out)
out = self.conv2d_4(out.reshape(out.shape[0],-1,19,19))
out = out.reshape(out.shape[0],-1)
out = F.relu(self.dropout(self.fc1(out)))
out = F.relu(self.dropout(self.fc2(out)))
out = self.fc3(out)
return out
# 随机输入,测试网络结构是否通
# x = torch.randn(1, 1, 30, 25, 25)
# net = HybridSN()
# y = net(x)
# print(y.shape)
测试准确率明显提高到了 98.51
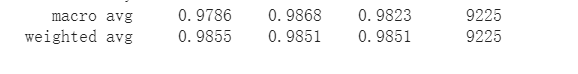
结果图片: