Flink集群部署--Standalone模式
参考文章:在CDH集群安装Flink
1. 下载安装包
查看自己的hadoop版本和scala版本, 这里是hadoop 2.6, scala 2.11
wget https://archive.apache.org/dist/flink/flink-1.7.2/flink-1.7.2-bin-hadoop26-scala_2.11.tgz2. 解压
tar -zxf flink-1.7.2-bin-hadoop26-scala_2.11.tgz3. 配置
flink-1.7.2/conf/flink-conf.yaml
选择一个 master节点(JobManager)然后在conf/flink-conf.yaml中设置jobmanager.rpc.address 配置项为该节点的IP 或者主机名。
# 配置主节点主机名
jobmanager.rpc.address: test-hadoop1
# The RPC port where the JobManager is reachable.
jobmanager.rpc.port: 6123
# The heap size for the JobManager JVM
jobmanager.heap.size: 1024m
# The heap size for the TaskManager JVM
taskmanager.heap.size: 5024m
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
# 你希望每台机器能并行运行多少个slot, 机器上一个核可以运行一个slot
taskmanager.numberOfTaskSlots: 4
# The parallelism used for programs that did not specify and other parallelism.
# 整个集群最大可以的并行度, slave节点数 * 节点CPU核数
parallelism.default: 72修改 conf/masters 文件
test-hadoop1:8081修改 conf/slaves 文件
test-hadoop2
test-hadoop3
test-hadoop4
test-hadoop5
test-hadoop6
test-hadoop7
test-hadoop8
test-hadoop9
test-hadoop10
test-hadoop11
test-hadoop12- 确保所有节点有有一样的jobmanager.rpc.address 配置。
4. 复制到各个节点
把解压并配置好的文件夹, 复制到各个节点上
scp -r /home/soft/flink/flink-1.7.2 test-hadoop2:/home/soft/flink/依次复制到各个节点
5. 启动Flink集群
只需要在主节点执行
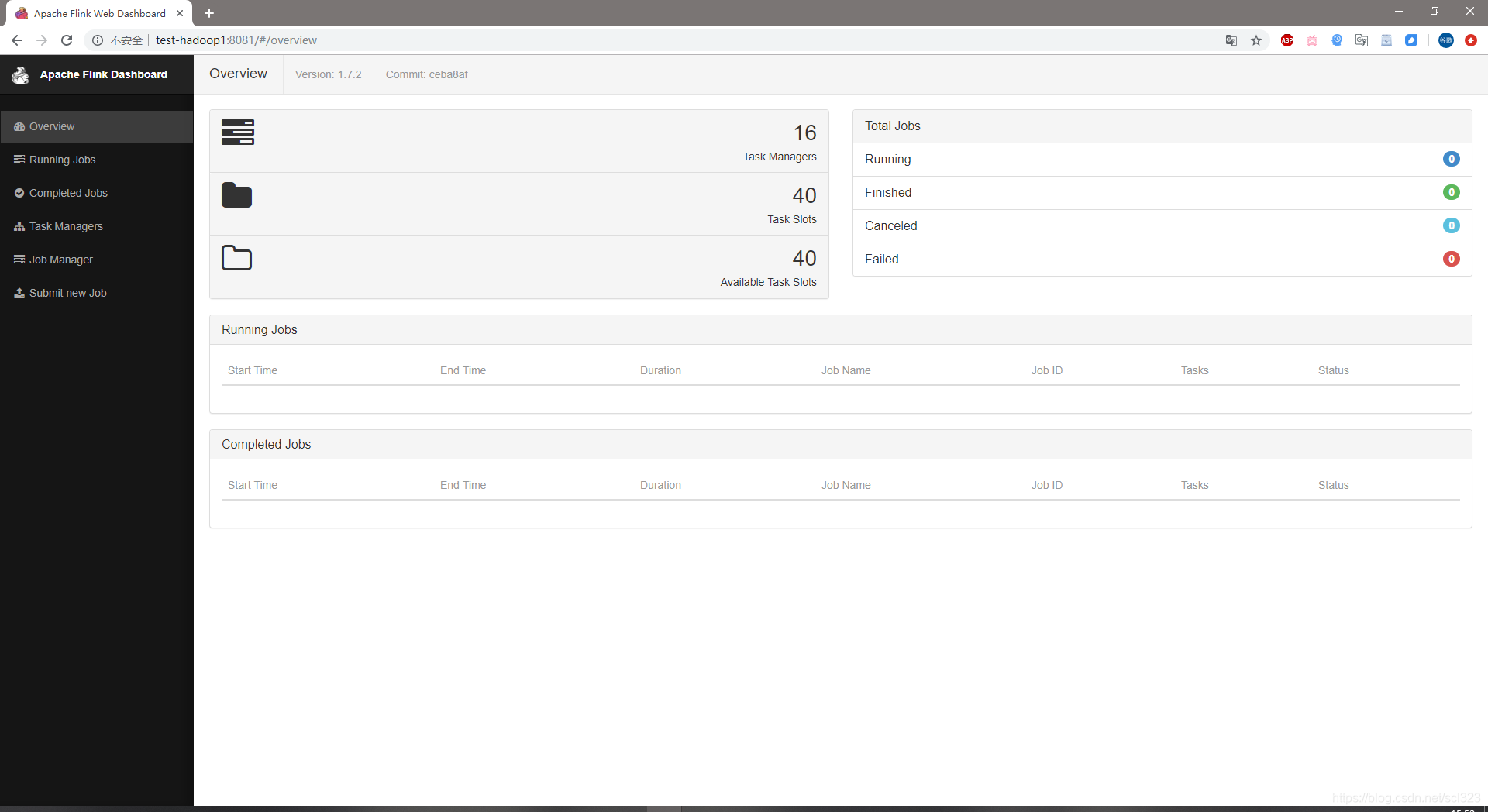
bin/start-cluster.sh6. 进入页面
http://test-hadoop1:8081/#/overview