Flink实时电商数仓之DWS层
需求分析
- 关键词
- 统计关键词出现的频率
IK分词
进行分词需要引入IK分词器,使用它时需要引入相关的依赖。它能够将搜索的关键字按照日常的使用习惯进行拆分。比如将苹果iphone 手机,拆分为苹果,iphone, 手机。
<dependency>
<groupId>org.apache.doris</groupId>
<artifactId>flink-doris-connector-1.17</artifactId>
</dependency>
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
</dependency>
测试代码如下:
public class IkUtil {
public static void main(String[] args) throws IOException {
String s = "Apple 苹果15 5G手机";
StringReader stringReader = new StringReader(s);
IKSegmenter ikSegmenter = new IKSegmenter(stringReader, true);//第二个参数表示是否再对拆分后的单词再进行拆分,true时表示不在继续拆分
Lexeme next = ikSegmenter.next();
while (next!= null) {
System.out.println(next.getLexemeText());
next = ikSegmenter.next();
}
}
}
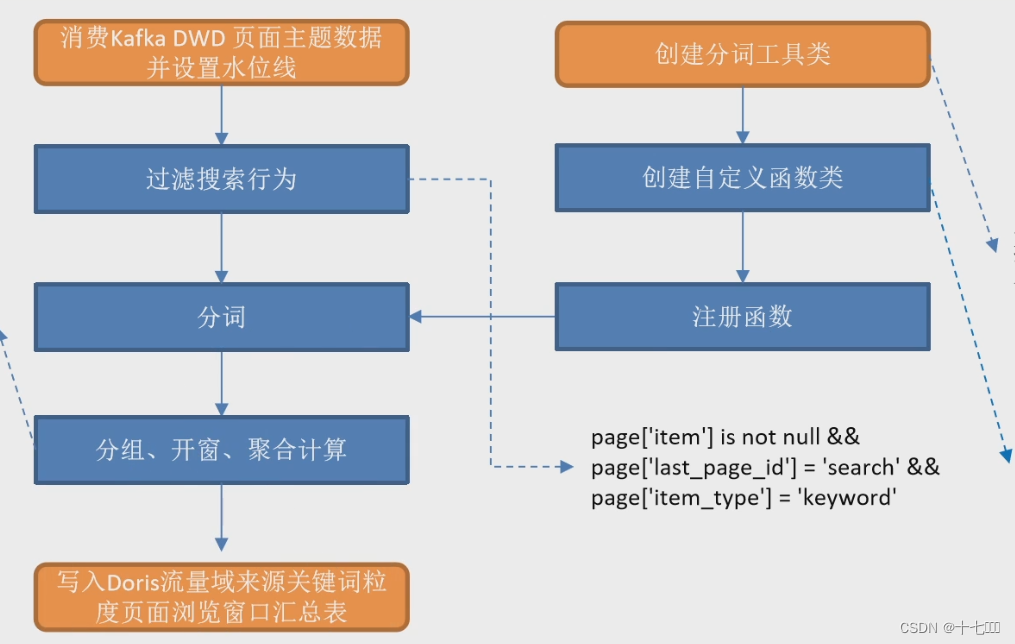
整体流程
- 创建自定义分词工具类IKUtil,IK是一个分词工具依赖
- 创建自定义函数类
- 注册函数
- 消费kafka DWD页面主题数据并设置水位线
- 从主流中过滤搜索行为
- page[‘item’] is not null
- item_type : “keyword”
- last_page_id: “search”
- 使用分词函数对keyword进行拆分
- 对keyword进行分组开窗聚合
- 写出到doris
- 创建doris sink
- flink需要打开检查点才能将数据写出到doris
具体实现
import com.atguigu.gmall.realtime.common.base.BaseSQLApp;
import com.atguigu.gmall.realtime.common.constant.Constant;
import com.atguigu.gmall.realtime.common.util.SQLUtil;
import com.atguigu.gmall.realtime.dws.function.KwSplit;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
/**
* title:
*
* @Author 浪拍岸
* @Create 28/12/2023 上午11:06
* @Version 1.0
*/
public class DwsTrafficSourceKeywordPageViewWindow extends BaseSQLApp {
public static void main(String[] args) {
new DwsTrafficSourceKeywordPageViewWindow().start(10021,4,"dws_traffic_source_keyword_page_view_window");
}
@Override
public void handle(StreamExecutionEnvironment env, TableEnvironment tableEnv, String groupId) {
//1. 读取主流dwd页面主题数据
tableEnv.executeSql("create table page_info(\n" +
" `common` map<string,string>,\n" +
" `page` map<string,string>,\n" +
" `ts` bigint,\n" +
" `row_time` as to_timestamp_ltz(ts,3),\n" +
" WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND\n" +
")" + SQLUtil.getKafkaSourceSQL(Constant.TOPIC_DWD_TRAFFIC_PAGE, groupId));
//测试是否获取到数据
//tableEnv.executeSql("select * from page_info").print();
//2. 筛选出关键字keywords
Table keywrodTable = tableEnv.sqlQuery("select\n" +
" page['item'] keywords,\n" +
" `row_time`,\n" +
" ts\n" +
" from page_info\n" +
" where page['last_page_id'] = 'search'\n" +
" and page['item_type'] = 'keyword'\n" +
" and page['item'] is not null");
tableEnv.createTemporaryView("keywords_table", keywrodTable);
// 测试是否获取到数据
//tableEnv.executeSql("select * from keywords_table").print();
//3. 自定义分词函数并注册
tableEnv.createTemporarySystemFunction("kwSplit", KwSplit.class );
//4. 调用分词函数对keywords进行拆分
Table splitKwTable = tableEnv.sqlQuery("select keywords, keyword, `row_time`" +
" from keywords_table" +
" left join lateral Table(kwSplit(keywords)) on true");
tableEnv.createTemporaryView("split_kw_table", splitKwTable);
//tableEnv.executeSql("select * from split_kw_table").print();
//5. 对keyword进行分组开窗聚合
Table windowAggTable = tableEnv.sqlQuery("select\n" +
" keyword,\n" +
" cast(tumble_start(row_time,interval '10' second ) as string) wStart,\n" +
" cast(tumble_end(row_time,interval '10' second ) as string) wEnd,\n" +
" cast(current_date as string) cur_date,\n" +
" count(*) keyword_count\n" +
"from split_kw_table\n" +
"group by tumble(row_time, interval '10' second), keyword");
//tableEnv.createTemporaryView("result_table",table);
//tableEnv.executeSql("select keyword,keyword_count+1 from result_table").print();
//6. 写出到doris
tableEnv.executeSql("create table doris_sink\n" +
"(\n" +
" keyword STRING,\n" +
" wStart STRING,\n" +
" wEnd STRING,\n" +
" cur_date STRING,\n" +
" keyword_count BIGINT\n" +
")" + SQLUtil.getDorisSinkSQL(Constant.DWS_TRAFFIC_SOURCE_KEYWORD_PAGE_VIEW_WINDOW));
windowAggTable.insertInto("doris_sink").execute();
}
}