Spark 简单介绍 基本概念 和MapReduce的区别
1.概述
Spark是一种快速而通用的集群计算的平台,Spark 的一个主要特点就是能够在内存中进行计算,因而更快。
2.特点
与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的
DAG执行引擎,可以通过基于内存来高效处理数据流。
Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。
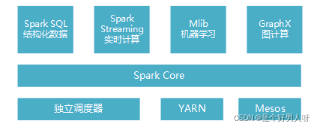
-
Spark Core实现了任务调度、内存管理、错误恢复与存储系统交互等模块,并且还包含了对弹性分布式数据集(Resilient Distributed Dataset,简称RDD)的API的定义。它主要担任了系统管理员的角色。
-
Spark SQL 主要用来操作结构化数据的程序包,通过Spark SQL可以使用SQL或者hive版本的HQL来查询数据库。
-
Spark Streaming 主要是对实时数据进行流式计算。Spark Streaming 提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应
-
MLib提供了很多机器学习算法。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
-
GraphX用来操作图,可以并行的进行图计算,支持了图的各种操作。
Spark SQL组件是经常用到的,使用hql语句从Hive中读取结构化的数据,存为RDD数据集,进行一些操作后分布式存储到hdfs中。
3.Spark基本概念
-
Application:Spark用户程序,用户提交一次应用为一个App,一个App产生一个SparkContext。
-
Job:一个App可被划分为多个Job,划分标记为action动作;action动作有collect,count等。
-
Stage:每个Job会被划分多层Stage,划分标记为shuffle过程;Stage按照父子(血统)关系依次执行。
-
Task:具体的执行任务单位,被发到executor上执行具体任务。
-
Cluster Manager:集群资源管理服务,通常包含主节点(主备)和多个运行节点;支持运行模式有Standalone、Mesos(用得少)、Yarn。
-
Driver:运行App的大脑,负责job的初始化,将job转换成task并提交执行。
-
DAGScheduler:是一个面向Stage层面的调度器,按照Stage提交Task集合给TaskScheduler。
-
TaskScheduler:提交Task给Executor运行,并管理执行结果。
-
BlockManager:管理App运行周期的中间数据,比如存在内存、本地。
-
Executor:是App运行在worker node上的一个进程,该进程负责运行Task,生命周期和App相同
4.Spark与MapReduce的区别
Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。可以直接对HDFS进行数据的读写,同样支持Spark on Yarn。Spark可以与MapReduce运行于同集群中,共享存储资源与计算。
-
spark把中间计算结果存放在内存中,减少迭代计算过程中的数据落地,运算效率高。MapReduce中的计算中间结果是保存在磁盘上的,运算效率差。
-
spark容错性高。spark支持DAG图的分布式并行计算。DAG:有向无环图,描述了任务间的先后依赖关系。
-
spark通用性高。MapReduce只提供了map和reduce两种操作,spark提供的操作类型有很多,分为转换和行动操作两大类。转换操作包括:map,filter,flatmap,sample,groupbykey,reducebykey,union,join,cogroup,mapvalues,sort,partitionby等多种操作,行动操作包括:collect,reduce,lookup和save等操作。