一文彻底搞懂“内存管理”
V1.0:直接使用物理地址
最开始的时候,计算机只允许运行一个进程,内存也只有几百 KB 大小,那时候的世界很简单也很美好,保留一部分内存空间给 OS 使用,剩下的都是这个进程的专属空间,想怎么用怎么用,如图 1-1。
本文福利, 免费领取C/C++ 开发学习资料包、技术视频/代码,1000道大厂面试题,内容包括(C++基础,网络编程,数据库,中间件,后端开发/音视频开发/Qt开发/游戏开发/Linuxn内核等进阶学习资料和最佳学习路线)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓
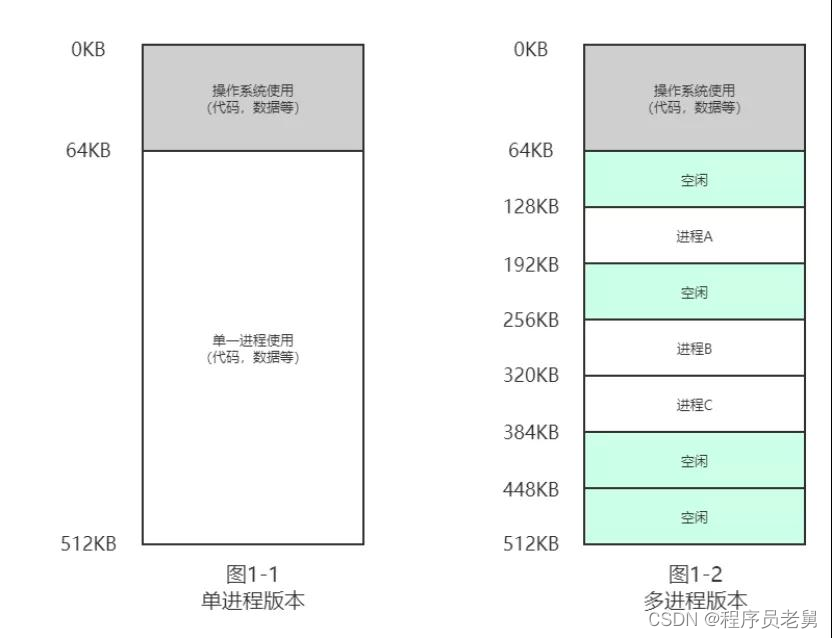
但为了更高效地利用 CPU 的计算资源,OS 需要支持"同时"运行多个进程,此时内存空间按固定大小被瓜分为几块,分属于各个进程使用,如图 1-2。
由于是直接使用内存物理地址,如果这些进程都很"本分",只访问自己的空间,那么一切都还正常,但如果某个进程闯入他人的领地,胡作非为呢?可控性是个问题。
V2.0:增加抽象转换层,使用虚拟地址
当考虑到增加管控、安全校验、动态分配等问题时,增加一层抽象进行"代理"往往是一个通用的解决方案。
到 2.0,进程不再被允许直接使用物理内存空间,而是使用从 0 开始编码的虚拟地址,经由 MMU(Memory Management Unit)转换得到实际地址,然后才能到内存中获取到数据。
中间层 MMU 会检查虚拟地址的有效性和合法性,从而保证安全性。
考虑到内存空间使用的灵活性,内存按固定大小进行分页(Paging),通常是 4KB,连续的虚拟地址页(VP,Virtual Page),映射到物理地址页(PP, Physical Page)上,可以是分散的,这种灵活的设计可以提升物理内存的空间利用率,减少内存碎片。
既然有映射,自然需要存储映射关系表,即页表(Page Table),Key 值是虚拟地址页号(Virtual Page Number)。
Value 值是包含有物理地址页号(PPN,Physical Page Number)的数据结构(PTE,Page Table Entry),值得一提的是,页表不存在 MMU 里面,同样也是存在内存里。
图 2-1 简要地展示了虚拟地址到物理地址的转换过程:
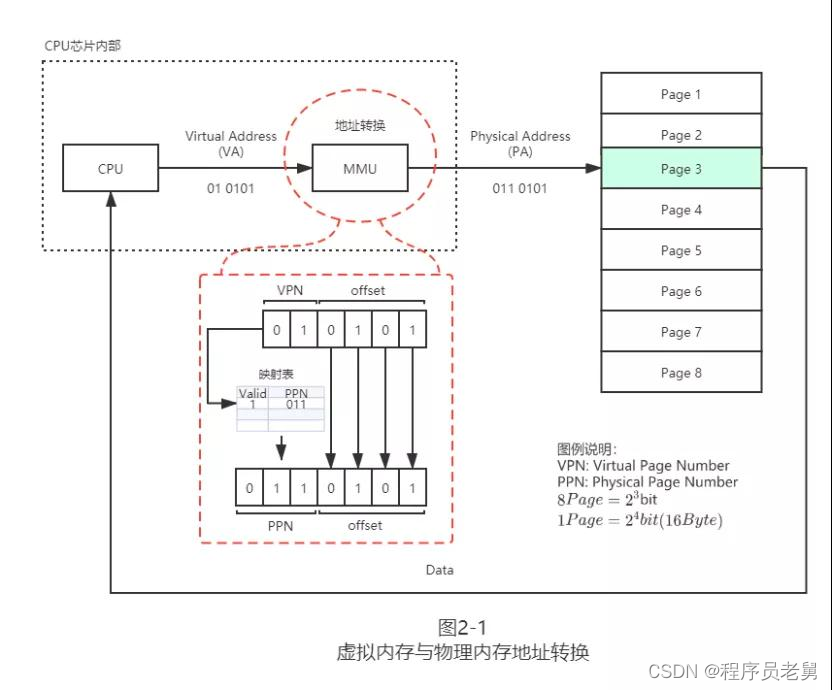
为了方便说明,这里页大小设置为 16 字节(2^4,offset 占用 4bit),总的物理内存大小有 8 页(2^3,PPN 占用 3bit)即 128 字节,虚拟内存至多使用 4 个页(2^2,vpn 占用 2bit)。
MMU 将一个 6bit 的虚拟地址转化为 7bit 的物理地址,其中通过页表完成 vpn 到 PPN 的转换,而 offset 部分保持不动。
①V2.1 时间优化:增加 TLB 缓存
在计算机领域,当考虑性能提升的问题时,使用缓存是个万金油般的解决方案。
其背后主要是基于时空局限性理论(temporal/spatial locality):时间上,一个刚被访问过的数据,很可能在不久之后被再次访问;空间上,一个刚被访问过的空间 x,很可能在不久之后 x 的邻近空间也被访问。
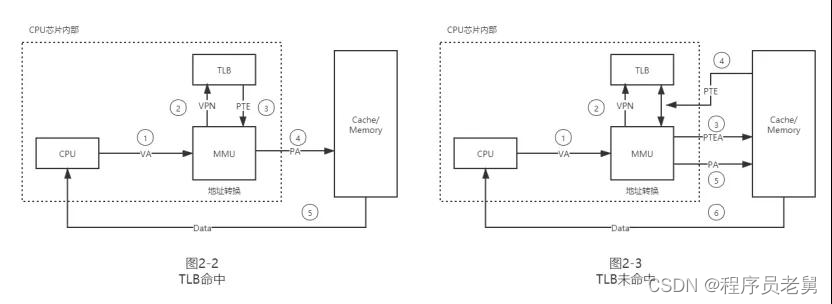
很自然地,我们可以在 MMU 里面加入一小块缓存空间,即快表 TLB(Translation Lookasid Buffer),里面保存着最近的 vpn->PPN 映射关系。
如果缓存命中(TLB Hit),将极大地提升地址转换速度,如果缓存未命中(TLB Miss),则重新从页表中查询。
遗憾的是,空间和时间永远是一对矛盾,TLB 容量越大,访问速度也随着降低,你无法实现一个足够大的 TLB 去替换掉内存上的页表,因此当 TLB 快满时,通常会使用近似 LRU 的算法将最少被使用的单元踢除。
图 2-2 和 2-3 分别展示了 TLB 命中和未命中情况下的流程,如果命中,则只需一次物理内存访问;如果未命中,则会先到物理内存中查询 PTE,并更新至 TLB,然后再访问真正的数据地址。
②V2.2 空间优化:多级页表和交换分区
进行时间优化后,我们再来思考空间上有哪些可以优化的。我们注意到,原始的线性页表会随着虚拟内存的增大而增大。
试算一下,一个 32bit 大小的虚拟地址(2^32),分页大小为 4KB(2^12),则会有 1M 个分页 (2^20)。
假如一个映射单元 PTE 占用 4 个字节,则光存储这个进程的映射表就需要 4MB。
如果机器上同时运行了 100 个进程,那么将吃掉 400MB 大小的内存空间!这对于整个系统来说将是极大的浪费。
避免这种浪费的关键在于,并非所有的虚拟分页都需要保存其映射关系,对于还未被使用的分页群,可以只使用一个 PTE(Page Table Entry)表示,而对于连续使用的分片群,可以使用多级映射来定位。
图 2-4 展示了二级页表的寻址过程,图中一级页表的一个 PTE 可以代表 1 千个 VP。
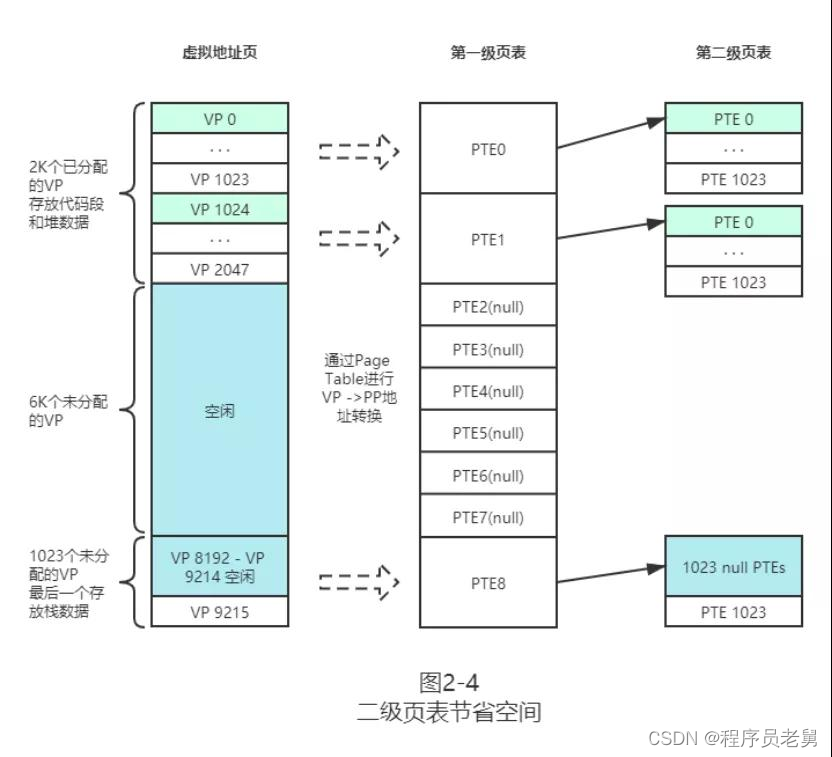
这样对于中段大量空闲的 VP,只需使用若干个 PTE 即可表示,显著地减小了页表的总大小,对于大容量且稀疏的虚拟地址空间,可以依此类推,再增加几级页表。
为了更高效使用我们珍贵的内存空间,除了通过多级页表节流之外,我们还能通过使用部分磁盘空间,即交换分区,作为虚拟内存来达到开源的效果。
具体来说,我们提供给上层应用的虚拟内存空间是可以大于实际可用的内存空间的。
只要 OS 时不时将一些不常用的内存数据复制到交换分区然后从内存清除,就可以源源不断地提供新的内存空间。
当读取到这部分虚拟内存时,再从交换分区恢复到内存就可以了,当然了,这种操作会一定程度上降低内存的读写速度。
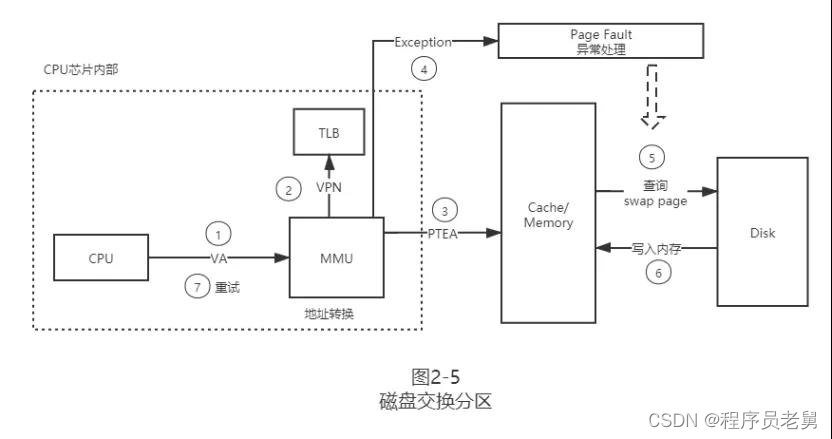
图 2-5 展示了增加了交换分区后的工作流程,当 OS 发现要查找的 PTE 既不在 TLB 中,也不在内存中,就会抛出一个 Page Fault 异常,OS 再异步地从交换分区中查找出 PTE 并写回内存,完成后 CPU 再发起重试就可以了。
V3.0:无招胜有招,自动管理内存
通过上述的设计,操作系统为上层应用搭建了一个安全舒适的虚拟乐园,在这个乐园里面,应用无需关注真实的内存转换、寻址等繁琐事项,只管在需要时 malloc 申请内存,不需要时 free 掉即可。
然而随着应用复杂度的快速上升,即使是自己的一亩三分地,也常常因为疏漏或者 Bug 导致申请的内存未及时释放,造成内存泄露最终导致应用崩溃。
由此以 JVM 为代表的一系列自动内存管理平台应运而生,通过定期扫描内存中的数据对象,使用引用计数法或者可达性分析,区分出数据对象是否可回收,再结合标记-清除算法、复制算法等实现内存垃圾回收。
关于垃圾回收器的具体实现业界仍在不断地更迭出新,这里不再细述。
结语
本文尝试从最基础的设计开始,逐步引入虚拟地址转换,随后进行时间和空间上的优化,最后介绍应用层的自动内存管理机制,循序渐进,希望能帮你构建出一幅内存管理的基本蓝图。
当然,基于篇幅的限制,真实的系统设计细节远比本文介绍复杂得多,会引入更多层级的缓存、映射,并基于硬件特性做更多的优化策略以提升内存使用效率。
但大道至简,理解其最核心的设计思路,再去看技术细节,相信会帮你更快地理解领悟。
作者:李腾辉
简介:Akulaku 高级开发工程师,目前负责金融借贷平台架构设计及核心建设工作,对微服务体系、JVM 虚拟机及操作系统原理机制有较深入的研究,擅长定位并解决线上疑难问题。
本文福利, 免费领取C/C++ 开发学习资料包、技术视频/代码,1000道大厂面试题,内容包括(C++基础,网络编程,数据库,中间件,后端开发/音视频开发/Qt开发/游戏开发/Linuxn内核等进阶学习资料和最佳学习路线)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓