8B/10B编码基本原理
一、为什么需要8B/10B编码
简单的说是为了实现直流均衡。在高速串行通信中,8B/10B编码是一种经常用到的编码方式。
而高速串行总线中,通常采用交流耦合方式,即在发送端(TX)串接电容,根据电容“隔直流,通交流”的特性,或者理想电容的阻抗公式:
电容阻抗公式
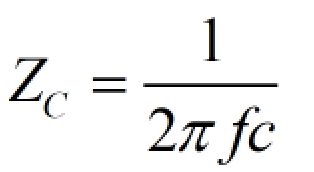
信号频率越高,电容阻抗越低。当数据位流中出现多个连续的1或0时,可以认为该时间段信号是直流的,电容的损耗变大,导致信号的幅度降低,直流信号被滤除,到最后无法识别是1还是0。而且接收端收到连续的1或0时,没有充分的定时信息,对接收端的解码带来了困难。其原理如下图所示:
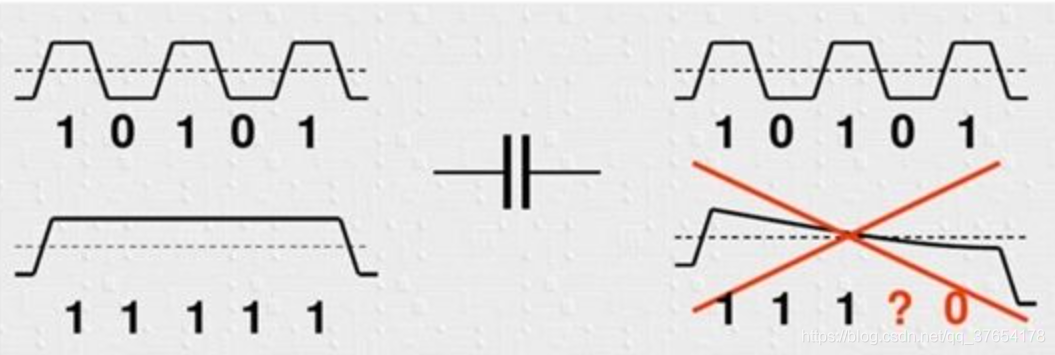
8B/10B编码以字节为单位,将数据映射成10位宽度的数据(具体映射方式可查表),使得编码后的二进制数据流中1和0的数量基本保持一致,同时确保字节同步易于实现。
二、8B/10B编码基本原理
8B/10B编码是1983年IBM公司的Al Widmer和PeterFranaszek提出的输出传输编码标准1,目前已广泛的应用在高速串行总线中。
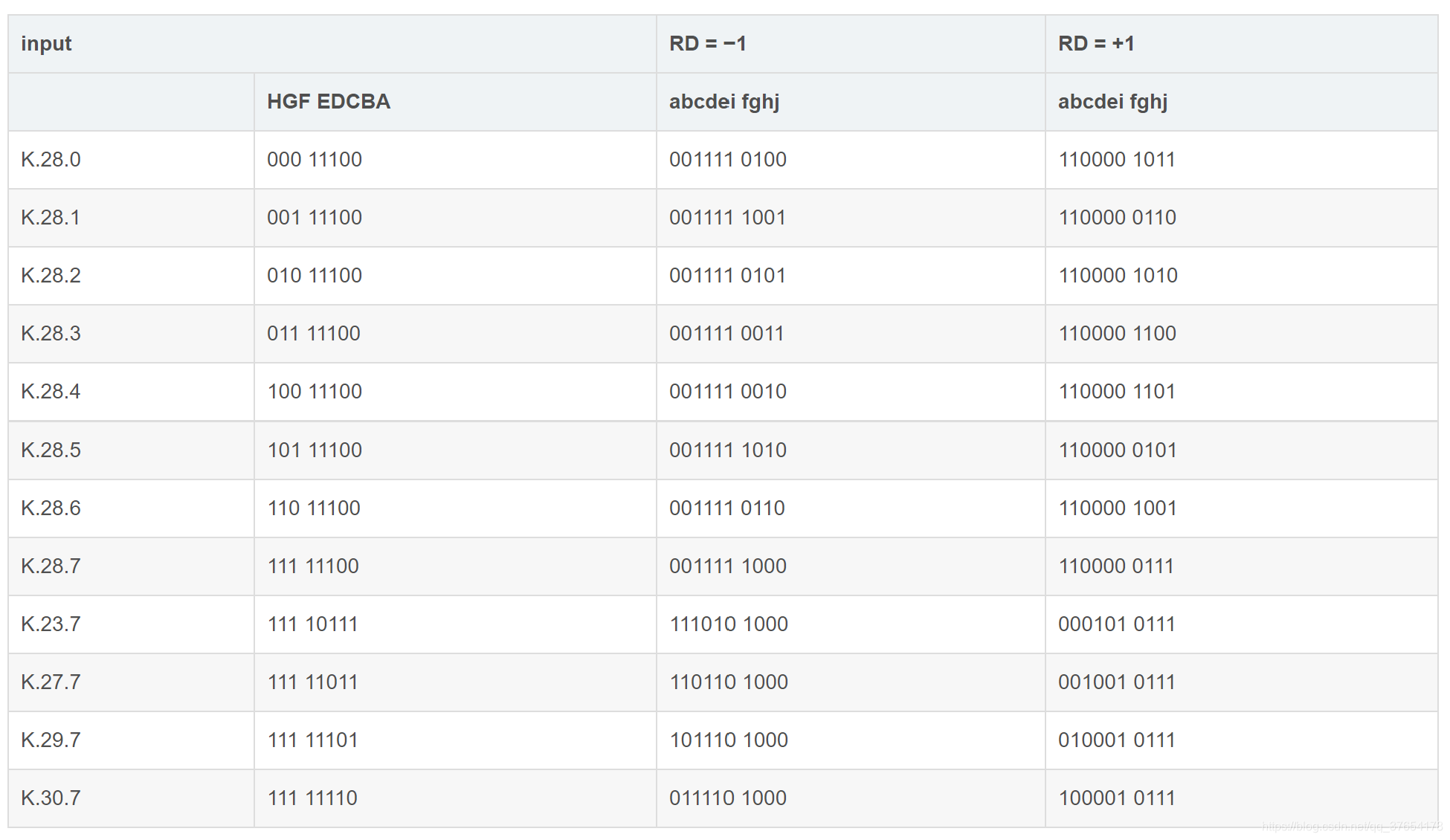
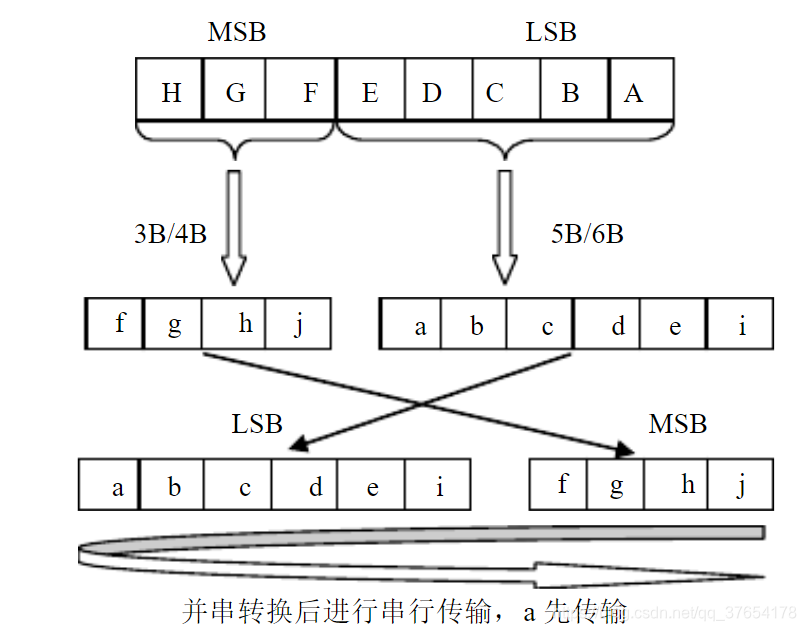
假设原始8位数据从高到低用HGFEDCBA表示,8B/10B编码将8位数据分成高3位HGF和低5位EDCBA两个子组。然后经过5B/6B编码,将低5位EDCBA映射成abcdei;高3位经过3B/4B编码,映射成fghj,最后合成abcdeifghj发送。发送时由于是小端模式,a先发送。其对应关系如下图所示:
通常,认为会将低5位EDCBA按其十进制数值记为x,将高3位按其十进制数值记为y,将原始8bit数据记为D.x.y。例如8bit数“101 10101”,即十进制数181,按照上述划分原则x=10101(21),y=101(5),所示这个数被表示为D.21.5。此外在8B/10B编码中,还需用到12种控制字符,用来标识传输数据的开始和结束,传输空闲等状态,按照上述规则,将控制字符记为K.x.y。
这个时候问题来了,8位原始数据对应256个码,加上12种控制字符,而编码后的10位数据有1024个码,肯定有很多是用不到的,故需选择其中一部分来表示8bit数据,所选的码字0和1的数量应尽可能相等。
表1所示为5B/6B编码映射关系表2:
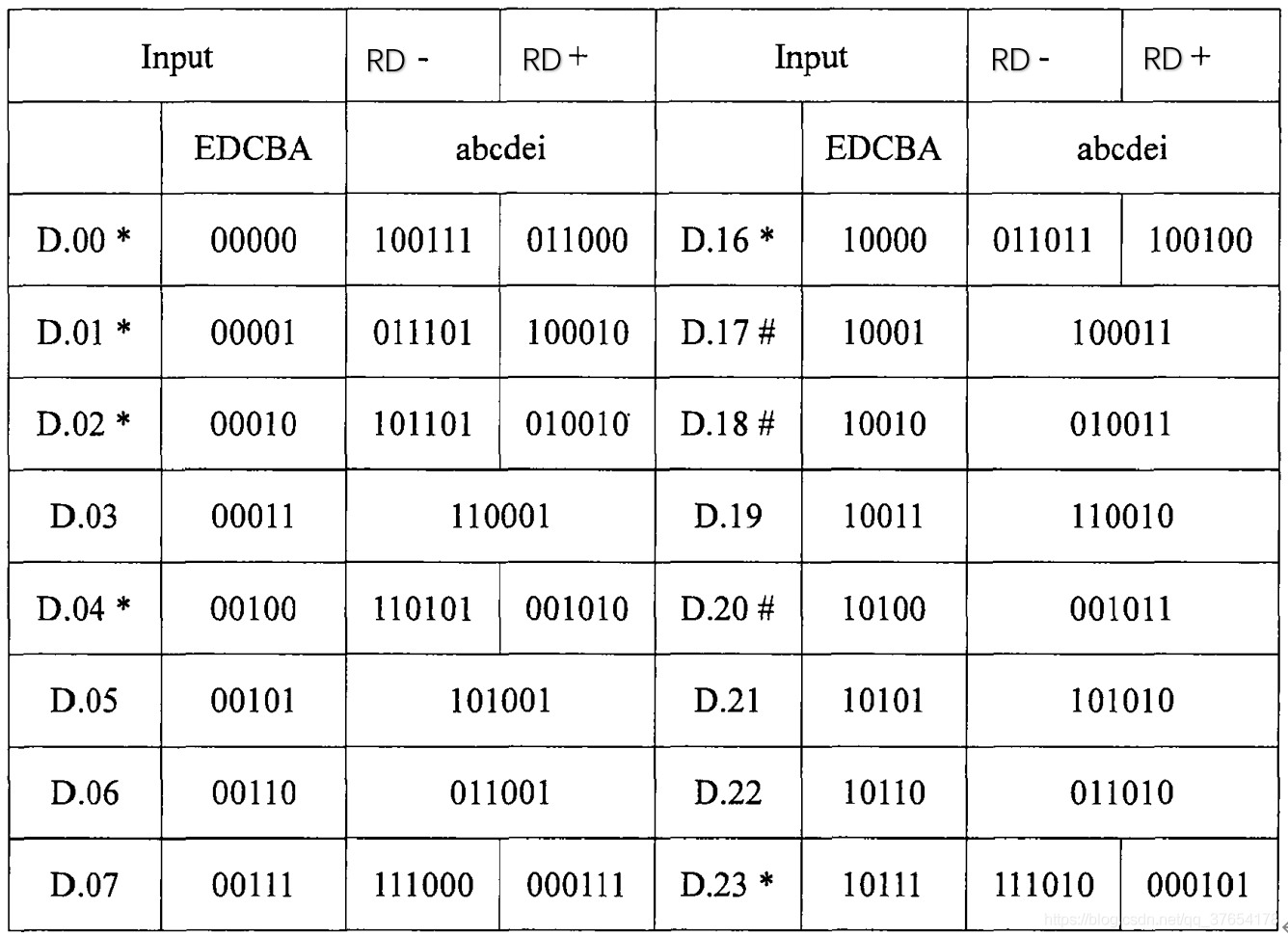
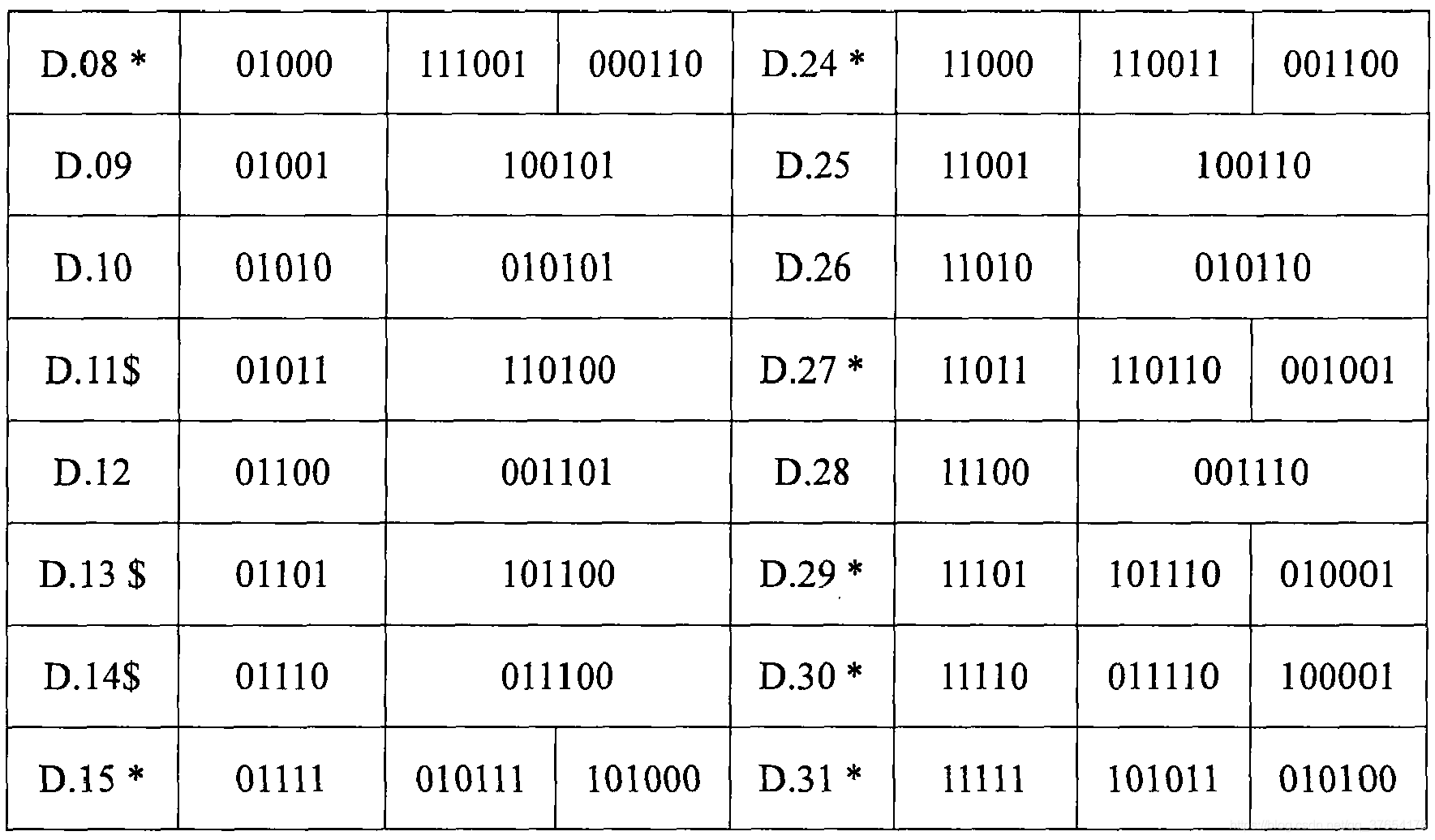
表2所示为3B/4B编码映射关系表:
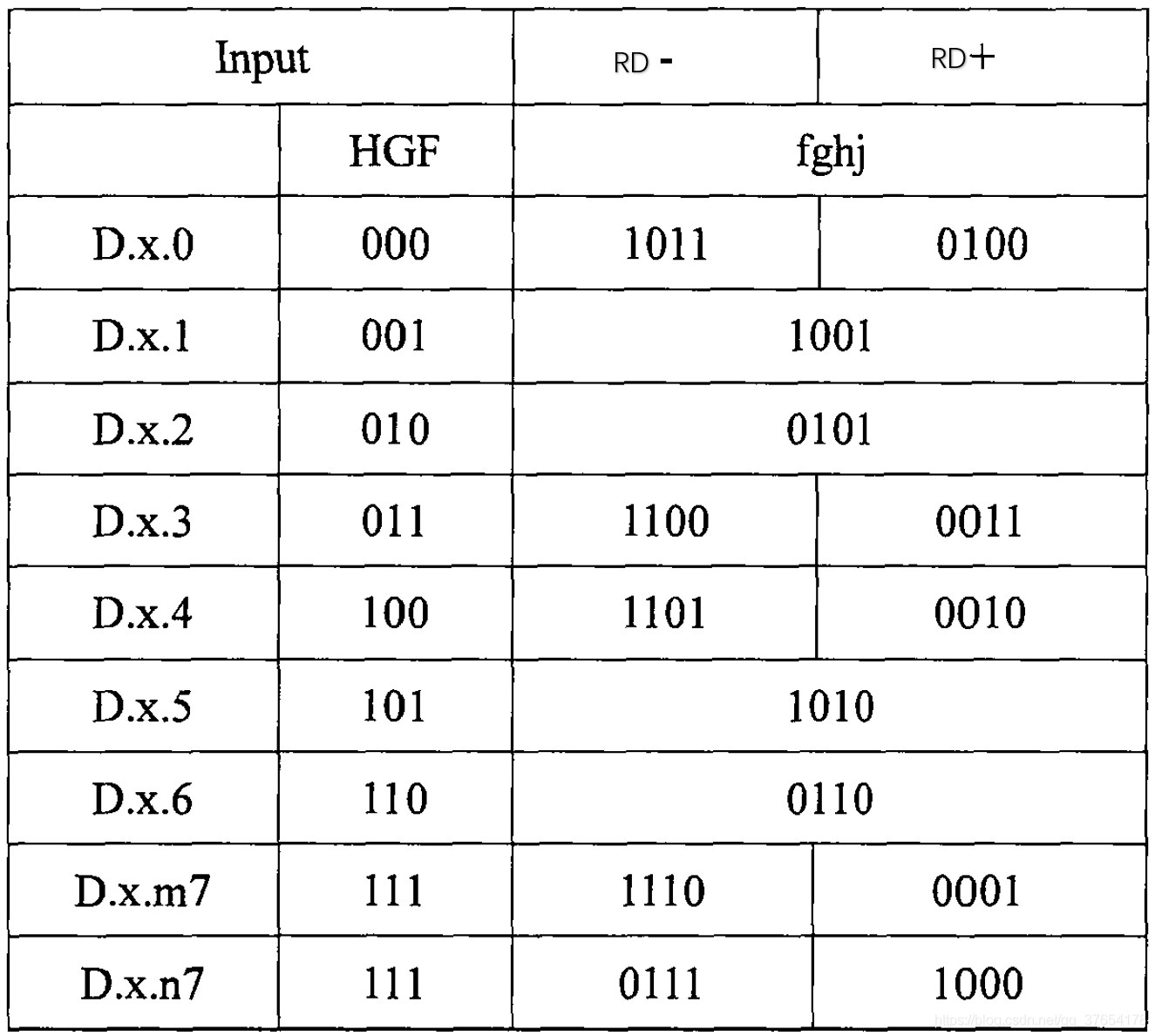
表3所示为8B/10B编码映射关系表3:其映射原理将在下文中阐述。
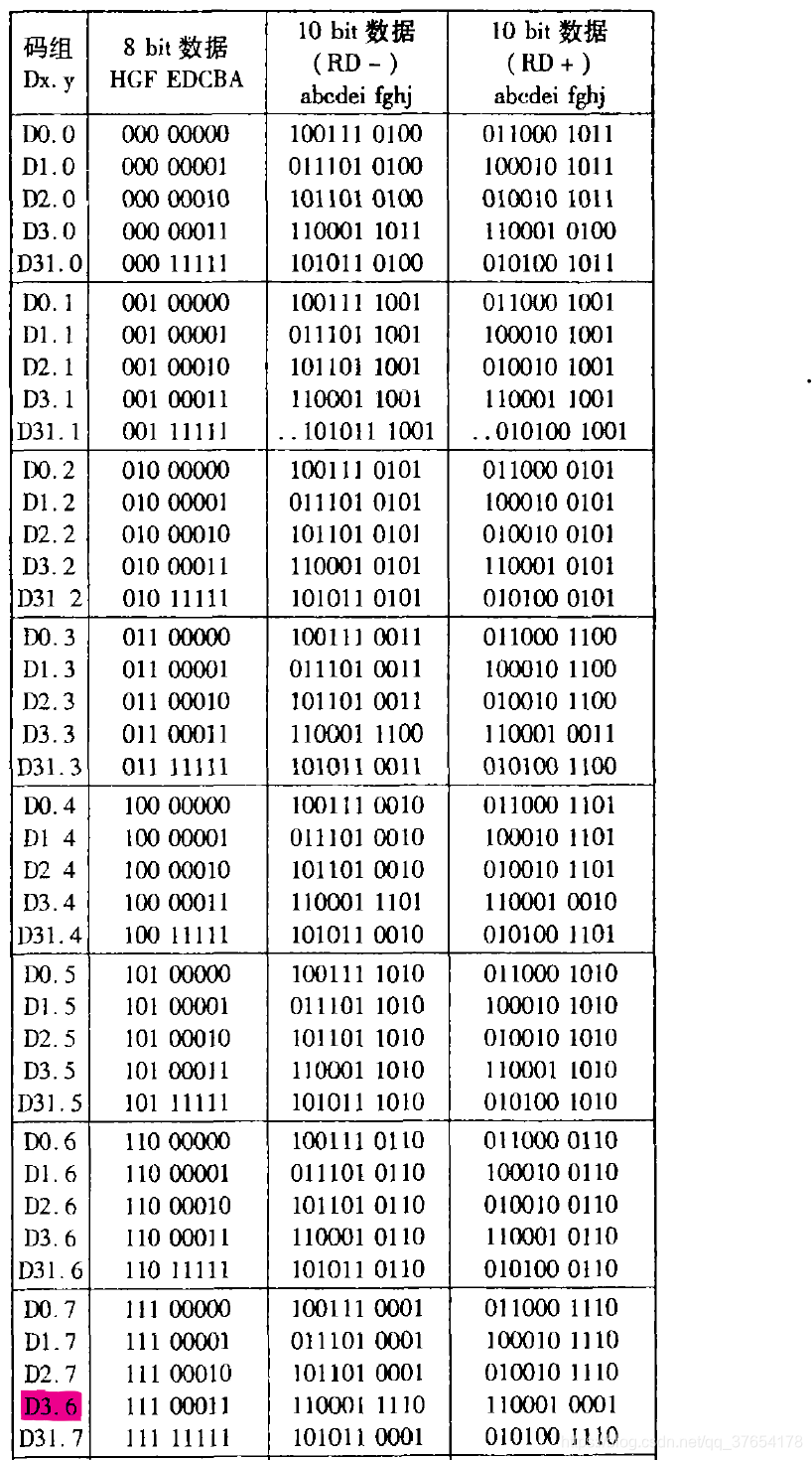
注:表中用红色标注的应为D3.7。表中只列出部分编码映射关系。
为了明白8B/10B的编码原理,首先要明白两个重要的概念:“不一致性”(disparity)和“运行不一致性”,也翻译成“极性偏差”(running disparity,RD)。
Disparity表示编码后的码型数据中“1”的个数与“0”的个数的差值。由表1,表2及表3中的编码规则可知:Dirparity的取值只有“+2”(“0”比“1”多两个)、“0”(“0”和“1”数量相等)和“-2”(“0”比“1”少两个)。编码中“1”和“0”数量相等的码字称为“完美平衡码”。
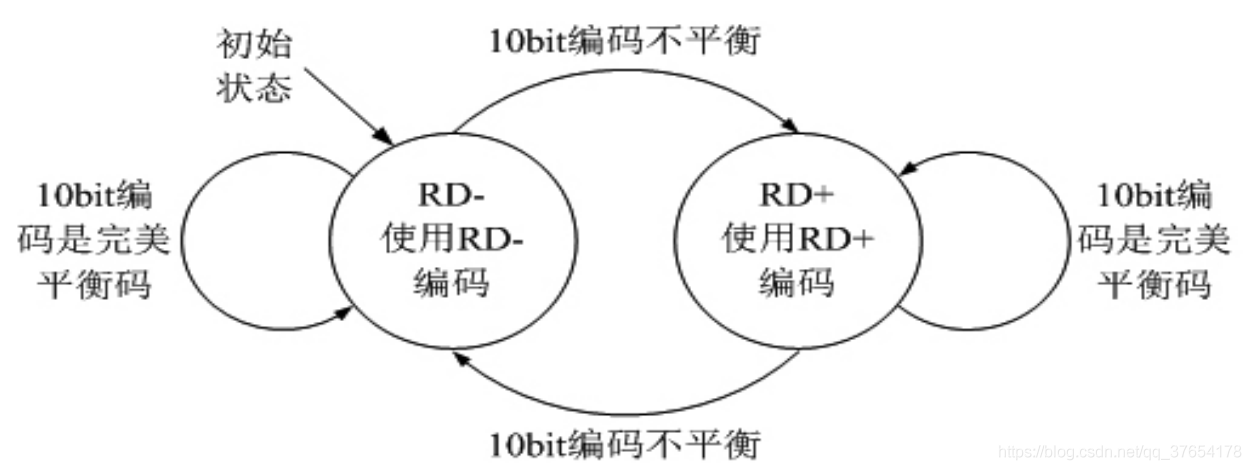
RD是对编码后的数据流Disparity的一个统计,如果“1”的个数大于“0”的个数,则RD取正,记为RD+;如果“1”的个数小于“0”的个数,RD取负,记为RD-。8B/10B编码由3B/4B编码和5B/6B编码两部分组合而成,通过传递RD参数来使整个编码结果具有很好的直流平衡性。4
在编码时,RD的初始值为负,即RD-,根据当前的RD值,决定相应的编码输出。比如:在表1中,对于D.x.3(011),其对应的4B码字有两种:1100和0011,若此时RD为负,则取1100作为其对应的4B码字作为输出,同时检验此时的编码是否为完美编码,如果是完美编码,则保持RD的极性不变;否则改变RD的极性。通过控制RD的极性,同时在编码时根据RD的极性选择相对应的编码值,使得编码后的数据流有更好的直流平衡特性。5
下图所示为RD状态转移图:
由于控制字符只有12种,对其单独编码即可,可不按照上述方法对其编码。其编码映射关系如下: