paddleocr图片高精度识别
1、下载准备
下载whl文件
- 首先先下载whl文件,以下是whl文件的下载网站
https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
- 进入网站后找到和自己python版本相同的whl文件
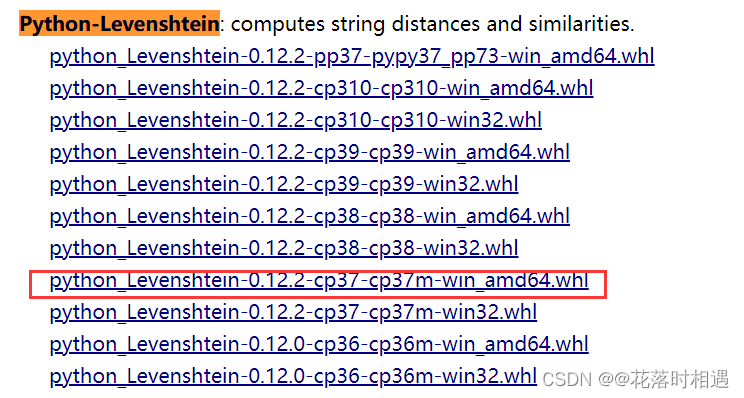
- 将文件下载好了之后,在terminal中使用pip将此文件下载到python中
pip install F:\pythonproject\python_Levenshtein\python_Levenshtein-0.12.0-cp38-cp38-win_amd64.whl
下载paddleocr
在Terminal中输入如下命令进行安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple paddleocr
下载paddlepaddle
在Terminal中输入如下命令进行安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple paddlepaddle
2、代码测试
打印识别结果
- 目标图片

from paddleocr import PaddleOCR, draw_ocr
from PIL import Image
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = 'F:/识别/1.jpg'
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)- 识别结果
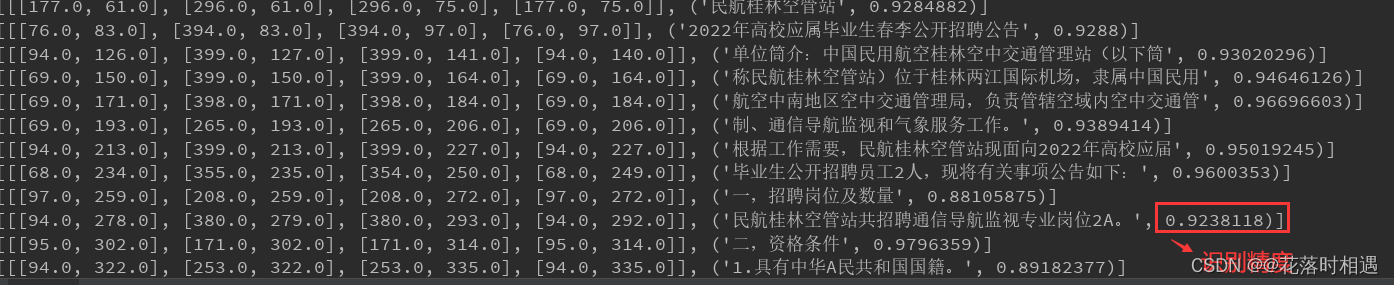 识别结果保存成图片
识别结果保存成图片
from paddleocr import PaddleOCR, draw_ocr
from PIL import Image
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
img_path = 'F:/识别/照片1.png'
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores)
im_show = Image.fromarray(im_show)
im_show.save('1.jpg')- 结果如下
