C语言基础知识(2)
C语言基础知识(2)
1. 常用的基础函数
1.1 字符输入输出函数
输入:getchar(); 输入一个字符
输出:putchar(); 输出一个字符
#include <stdio.h>
int main()
{
char a;
a = getchar();//函数给变量赋值,将输入的一个字符放到变量a中
//等价于scanf("%c", &a);
putchar(a); //输出a中的字符,一次只能输出一个字符
//等价于printf("%c", a);
putchar('\n');
return 0;
}

遍历字符串,以 ‘\0’ 作为字符串的结尾
#include <stdio.h>
int main()
{
char a[100] = "hello";// 使用字符串常量初始化数组a
int i = 0;
// 遍历字符串
while(a[i] != '\0')
{
putchar(a[i]);
i++ ;
}
putchar('\n');
//或者
for(i = 0; a[i] != '\0'; i++)
{
putchar(a[i]);
}
putchar('\n');
retrun 0;
}
1.2 字符串的输入输出函数
gets的参数是数组名
puts的参数是数组名或者字符串常量
%s是字符串的格式符
get string 输入: gets(); 允许输入空格,输入"xiao ming" 得到"xiao ming"; 相当于scanf(“%s”); 不允许输入空格,输入"xiao ming" 得到"xiao"
put string 输出:puts(); 默认会输出\n; 相当于printf(“%s”);自己写\n才会换行
计算字符串长度。char s[] = “Struggle for a better future”;
字符串长度不算\0,所以字符串长度为28

1.3 随机函数
计算机的随机都是假随机,所有的随机数都是根据一套算法计算出的看似随机的数
#include <stdlib.h>
// std standard标准 lib library 库 stdlib头文件中声明的内容很杂
#include <time.h>
srand(); //seed random 设置随机数的种子数 rand 生成的所有的随机数都是根据种子数计算出来的
// 没有返回值,有整型参数,就是作为种子数
rand();// random 生成一个随机数 没有参数,返回值是一个随机数
time();// time(0) 参数0是固定的,得到的是从1970年1月1日0:0:0到现在的秒数
-10~10 闭区间 区间内有21个数
rand()%21 得0~20
rand()%21-10 -10~10 之间的数
计算随机数
rand()%范围内数字的个数 + 范围内的最小值 可以得到你想要的范围内的随机数

例子:编写一个彩票机制,在1-35之间不能有重复数,输出最终中奖结果。每个人可以选择7个数;选中7个数,可以中1千万;选中6个数,可以中1百万;选中5个数可以中10万,选中4个数可以中100块钱,选中3位数可以中10块钱。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main ()
{
srand(time(0));//设置随机的种子数
int i,j;
int user[7];
int system[7];
for(i = 0; i++ ; i < 7)
{
scanf("%d",&user[i]);
if(user[i] < 1 || user[i] > 35 )
{
printf("超出范围\n");
i--;
continue;//使用 continue 语句跳过当前循环,直接进入下一次循环
}
for((j = 0;j < i;j++)
{
if(user[i] == user[j])
{
i--;
printf("输入重复\n");
break;
}
}
}
for(i = 0;i < 7;i++)
{
system[i] = rand()%35+1;
for(j = 0;j < i;j++)
{
if(system[j] == system[i])
{
i--;
break;
}
}
}
int count = 0;
for(i = 0;i < 7;i++) //遍历user
{
for(j = 0;j < 7;j++){//遍历system
if(user[i] == system[j])
{
count++;
break;//不写break;也对
}
}
}
switch(count)
{
case 7:
printf("1 0000 0000\n");
break;
case 6:
printf("10 0000\n");
break;
case 5:
printf("1000\n");
break;
case 4:
printf("100\n");
break;
case 3:
printf("10\n");
break;
default:
printf("谢谢参与\n");
break;
}
//打印开奖数字
for(i = 0;i < 7;i++)
{
printf("%d ",system[i]);
}
printf("\n");
return 0;
}
2. 冒泡排序
为什么需要排序?排序方便我们分析数据。
分析: int a[7] = {85,72,65,79,53,95,87};
以升序排序为例:比较数组中所有相邻的两个数,前者大于后者则交换两个数。反复执行这个过程实现排序。【冒泡排序的原理】
- 冒一个泡,需要比较N-1次,N是数据的数量
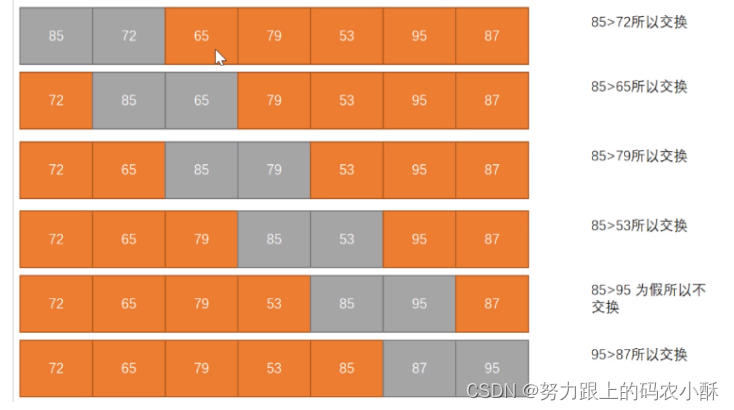
由此可以看出,冒一次泡,可能无法完全排序完成 - 所以要进行N-1轮冒泡完成排序

#include <stdio.h>
int main()
{
int a[7] = {85,72,65,79,53,95,87};
int i,j;
// 冒泡,将最大的数放在最后,需要循环 7-1(N-1)轮冒泡完成排序
for(j = 0; j < 7-1 ; j++)
{
int flag = 0;//表示在某一轮冒泡中没有发生过交换
for(i = 0;i < 7-1-j; i++) //内层循环负责冒一次泡,-j的目的是为了比上一轮少比较一次
{
if(a[i] > a[i + 1])
{
int temp = a[i];
a[i] = a[i+1];
a[i+1] = temp;
flag = 1; //一旦发生交换,flag值会变成1
}
}
if(flag == 0) //在每一轮冒泡完成之后判断是否发生过交换,如果没有发生交换,说明数组已经有序,停止外层循环
{
break;
}
}
//查看冒泡排序后的结果
for(j = 0; j < 7;j++)
{
printf("%d ",a[j]);
}
printf("\n");
return 0;
}
优化后的代码,用户在终端输入要排序的数组即可
#include <stdio.h>
#define MAX_SIZE 100
int mian()
{
int a[MAX_SIZE];
int i,j,n;
printf(""Enter the number of elements:");
scanf("%d",&n);
for(i = 0; i < n; i++)
{
printf("Enter %d elements:\n", n);
scanf("%d",&a[i]);
}
for(i = 0; i < n-1; i++)
{
int flag =0;
}
return 0;
}
3. 二维数组
- 本质:在C语言中,二维数组是一种特殊的一维数组,它的每个元素也是一个一维数组。
- 使用二维数组的目的:批量的定义类型相同,逻辑相似的一维数组,就定义二维数组。
- int a[2][3];
a 是二维数组的名称
2 是数组a中有两个元素,即数组a中有两个一维数组
3 是作为a的元素的一维数组的元素个数
int 作为a的元素的一维数组的元素类型
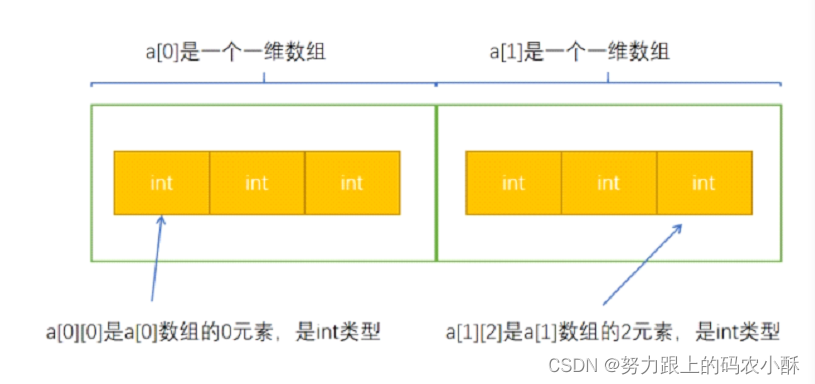
//不能直接给a[0]赋值,因为a[0]是一个一维数组,C语言没有给一维数组直接赋值的运算符
a[0][0] = 10;// 给a[0]数组的0元素赋值
a[1][2] = 10;// 给a[1]数组的2元素赋值
由于二维数组的每个元素都有两个角标,所以一般使用双重for循环遍历,一般使用外层循环的循环变量作为第一个角标,内层循环的循环变量作为第二个角标。
#include <stdio.h>
int main()
{
int a[2][3];
int i,j;
for(i = 0; i < 2;i++) //外层循环遍历第一个角标
{
for(j = 0; j < 3;j++)//内层循环遍历第二个角标
{
a[i][j] = i * j;
printf("%d\n",a[i][j]);
}
}
return 0;
}
- 三种初始化的概念和一维数组是一样的。
- 完全初始化:数组的数量和元素个数相等。
int a[2][3] = {{1,2,3},{4,5,6}};
int a[2][3] = {1,2,3,4,5,6};
- 部分初始化:数组的数量小于元素的个数,其他元素默认补0。
int a[2][3] = {1,2,3};//a[0]:1 2 3 a[1]: 0 0 0
int a[2][3] = {{1},{2,3}};//a[0]:1 0 0 a[1]:2 3 0
- 默认初始化:
二维数组的第一个长度是二维数组的长度,是二维数组中包含的一维数组的个数,可以省略。第二个长度是元素的数组长度,是不能省的,属于二维数组的元素类型。
int a[][3] = {{1,2,3},{4,5,6}};
int a[][3] = {1,2,3};
例题
- 用二维数组表示一个68的平面直角坐标系,默认显示,输入对应的位置和一个字符,给二维数组中相应的位置赋值,以行列的形式打印二维数组
我们经常使用二维数组来表示坐标系,其中二维数组的每一个一维数组用来表一行。- 用第一个角标表示Y轴,第二个角标表示X轴。
- 坐标原点在左上角。X轴向右递增,Y轴向下递增。

#include <stdio.h>
int main()
{
char a[8][6];//表示宽x=6高y=8的坐标系
int x,y;
for(y = 0; y < 8;y++)
{
for(x = 0;x < 6;x++)
{
a[y][x] = '*';
}
}
while(1)
{
//遍历打印二维数组
for(y = 0; y < 8;y++)
{
for(x = 0;x < 6;x++)
{
printf("%c ",a[y][x]);
}
}
int inputX,inputY;
char inputC;
scanf("%d%d %c",&inputX, &inputY, &inputC);
//给坐标系中的点对应的二维数组的元素赋值
a[inputY][inputX] = inputC;
}
return 0;
}
- 鞍点,判断数组中是否存在鞍点,在该行最大,并且在该列最大
int a[3][4];
a[0]: 1 2 3 4
a[1]: 5 6 7 8
a[2]:9 12 11 10
#include <stdio.h>
int main()
{
int a[3][4] = {1,2,3,4,5,6,7,8,9,12,11,10};
int x,y;
for(y = 0; y < 3;y++)
{
int max = a[y][0]; // 假设a[y]数组的0元素是最大值
int maxI = 0; // 假设最大值角标是0
for(x =0; x < 4; x++)
{
if(a[y][x] > max)
{
max = a[y][x];
maxI = x;
}
}
printf("a[%d] max = %d maxI = %d\n", y, max, maxI);
int i;
//在循环中遍历的是i,maxI是固定的
for(i = 0; i < 3;i++)
{
if(a[i][maxI] > max)
{
break;
}
}
if(i == 3) //说明没有执行过break
{
printf("a[%d][%d] = %d\n", y, maxI, max);
}
}
return 0;
}

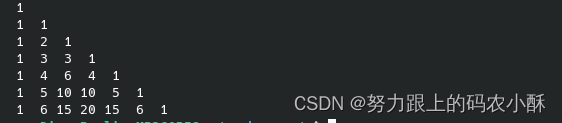
- 请将杨辉三角形(7阶)保存在二维数组中,并输出。
1 0 0 0 0
1 1 0
1 2 1 0
1 3 3 1
1 4 6 4 1
1 5 10 10 5 1
int yh[7][7] = {{1},{1},{1},{1},{1},{1},{1}};
yh[y][0] 不需要计算
yh[0] 不需要计算
从yh[1][1] 开始计算
yh[y][x] = yh[y-1][x] + yh[y-1][x-1];
#include <stdio.h>
int main()
{
int yh[7][7] = {{1},{1},{1},{1},{1},{1},{1}};
int y,x;
for(y =1; y < 7; y++)
{
for(x = 1; x < y+1; x++)
{
yh[y][x] = yh[y-1][x] + yh[y-1][x-1];
}
}
for(y =0; y < 7; y++)
{
for(x = 0; x < y+1; x++)
{
//%3d 打印的整数至少占3个格,不够3位数左边补空格
//大于3位数全部输出,此时输出会大于3个格
printf("%3d", yh[y][x]);
}
printf("\n");
}
return 0;
}
4. 函数
函:包装信息
数:数据,数据的算法
函数主要用来封装逻辑
什么时候需要封装函数?
- 固定的算法要封装 如冒泡排序 判断质数 找最大值…
- 会反复使用的代码 比如打印数组
- 如果一个函数写的太大了,它一定可以拆分成若干个小函数。【函数不能写太大】
系统函数:printf scanf putchar getchar puts gets strlen strcpy strcat strcmp 等等
4.1 自定义函数
对于完整的函数实现,需要包含四个部分:
返回值类型 函数名(形参列表[可以为空])
{
函数体
}
#include <stdio.h>
/*
函数名:function
形参列表:空
返回值类型:当函数没有返回值的时候,返回值类型要写成void
void 叫无类型,在C语言中不能定义void类型的变量 void a;不行
函数功能:打印4和9之间较小的值
*/
void function()
{
int a = 4, b = 9;
int min = a<b?a:b ;
printf("min = %d\n",min);
}
int main()
{
printf("hello world \n");
function();
printf("end\n");
return 0;
}

4.1.1 使用要点
- 调用才执行。不调用的函数和没写是一样的。
- 先声明再使用。
主调函数和被调函数: A函数调用B函数,A是主调函数,B是被调函数。【被调函数定义在主调函数的下面,需要在调用之前先声明】;
调用函数的语法:函数名()
#include <stdio.h>
//当函数没有定义在主调函数上面时,需要在主调函数上面先对被调函数进行声明
void function();
int main()
{
printf("hello world \n");
function();
printf("end\n");
return 0;
}
void function()
{
int a = 4, b = 9;
int min = a<b?a:b ;
printf("min = %d\n",min);
}
4.1.2 变量的作用域
变量的作用域就是变量的使用范围。
变量的作用域可以简单理解就是定义变量的{}。
4.1.3 形参列表
作用:主调函数给被调函数传数据。
注意要点
- 信息传递的方向:由主调函数 传递给 被调函数
- 形参与实参,个数要一致,类型要一致。
实参:主调函数传给被调函数的数据,实参可以是常量也可以是变量,实参的数量和类型需要和形参一一对应。
形参:在函数的()里定义的变量,就是形参。每个变量都必须有自己的类型,int a,b 这样是不可以的!每个形参之间使用逗号分割,数量没有上限。形参的作用域是它所在的函数。

驼峰命名法
每个单词的首字母大写
大驼峰:整个名称的首字母大写 ,其余字母均小写。 用于给类型命名,例如:FirstName、LastName、UserName等。
小驼峰:整个名称的首字母小写 用于给除类型以外的命名,后面的每个单词的首字母大写,其余字母均小写。例如:firstName、lastName、userName等。
4.1.4 返回值
作用:将被调函数中的数据传给主调函数
注意要点
- 信息传递的方向:被调函数 传给 主调函数
- 返回值类型:在定义函数的时候,函数名左边的类型,决定函数的返回值类型。void表示没有返回值,void类型不能定义变量。
- 返回值只能返回一个值,不可以返回数组,因为C语言的数组不能整体赋值。
return: 用于结束函数,return后面的表达式的结果将会传给主调函数。如果函数的返回值类型是void,那么return后面不能写表达式。


return 0; //main函数的return 0 是返回给系统,0 代表的意思只有自己,一般情况下main函数返回0表示正常结束
函数如果定义了有返回值,那么每一个结束函数的逻辑分支都要有返回值。
4.1.5 局部变量与全局变量
局部变量:定义在函数中的变量,就是局部变量,是有作用域限制的。
全局变量:定义在函数以外的变量,就是全局变量,它没有作用域的限制。
对比
- 对于全局变量,如果没有进行初始化操作,那么这个变量默认为0。局部变量默认没有值。
- 生命周期:
- 全局变量从程序开始执行创建,到程序结束删除。
- 局部变量从所在的{}开始执行创建,{}执行完删除。
- 作用域:
- 全局变量程序的任何地方都可以用。
- 局部变量只能在定义的{}里使用。
- 全局变量不能重名。局部变量在同一个作用域里也不能重名。
- 全局变量 与局部变量 重名的问题:
当小作用域和大作用域变量重名时,优先使用小作用域的变量。

C语言是面向过程的语言,过程就是函数,C语言中我们的编码单位是函数
C++语言是面向对象的语言 对象就是类,C++语言中我们的编码单位是类
5. 指针
指针变量的本质是变量。
指针变量是存放地址的变量。
内存单元地址即为指针
简单的用我们生活的例子来说:顺丰快递将电脑这个物品送到联想大厦(地址)里面,顺丰快递就是变量就是存放地址的变量。
地址起到了什么作用?查找的作用
地址的作用是查找。地址指的是内存中的地址
内存的最小编址单位是字节
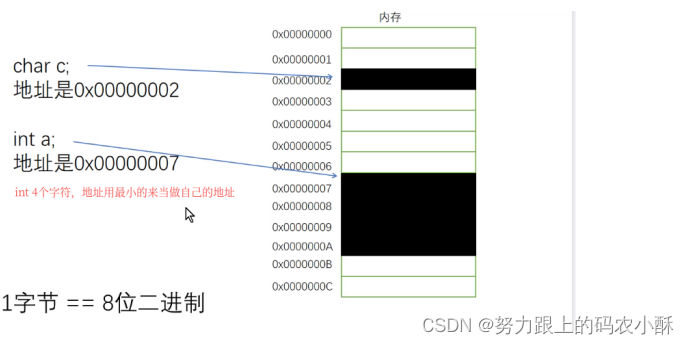
变量的运算,本质上是对变量中数据的运算
地址只有两种运算:地址偏移、间接运算
5.1 地址偏移
+、-
char 在内存中占1个字节,所以+1,差值是1

int在内存占4个字节,+1 差值是4

地址±N 是±N*地址类型大小个字节
地址是有类型的
5.2 间接运算
*单目运算
- 只能对地址运算
2.它的运算结果不是数值,是地址对应的对象本身。对象可以是变量、可以是常量、可以是数组。

#include <stdio.h>
int main()
{
int a;
/*
&a运算得到变量a的地址
*&a运算得到&a地址对应的对象本身,就是变量a
=10 将10 赋值给a
*/
*(&a) = 10;
printf("%d\n", a); //10
return 0;
}
5.3 定义指针变量
int *p;
*:说明p是指针变量
int 说明p中存放的地址是int类型
指针变量是存放地址的变量
在C/C++中,出现在声明和语句中的符号,都不是运算符。
能够出现在声明语句中的符号,在C语言中只有3个
*:指针变量
[]: 数组
(): 函数
int a; 整型变量
int a[10]; 数组
int a(); 函数
5.3.1 初始化
指针变量只能存放地址,地址也只能被指针变量存放。
int a;
int *p = &a; //使用&a初始化指针变量p。
这里"*p",是表示指针身份的符号。
5.3.2 赋值

输出指针变量

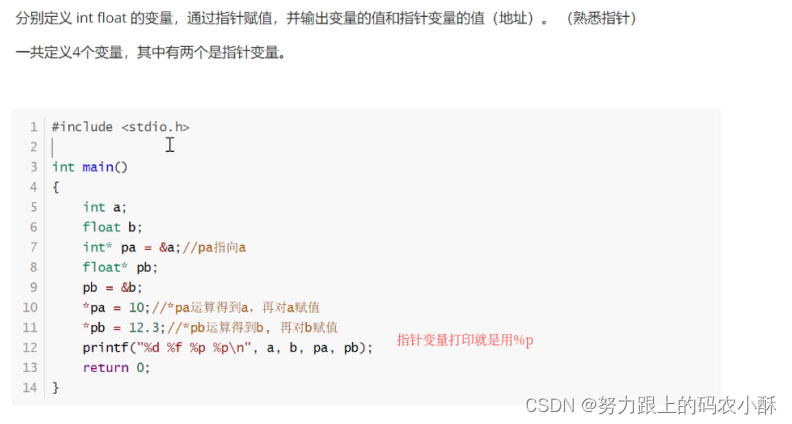
应用层的编码,使用的都是假地址。
5.3.3 指针变量的意义
指针变量常见的用法之一: 在被调函数中对主调函数中的变量赋值。【将被调函数的运算结果通过指针变量传给主调函数】
#include <stdio.h>
int main()
{
int a;
int* p = &a; //使用&a初始化指针p
//当p中存放a的地址,我们说p指向a
*p = 10; //指针变量的运算是对变量中地址的运算,*p运算得到a本身,=10 是给a赋值
printf("%d\n",a);//10
return 0;
}
#include <stdio.h>
void fun(int* b)//定义指针类型的形参
{
*b = 10;
}
int main()
{
int a;
fun(&a); // 使用&a初始化形参b,此时形参b指向main中的变量a
printf("%d\n",a);//10
return 0;
}
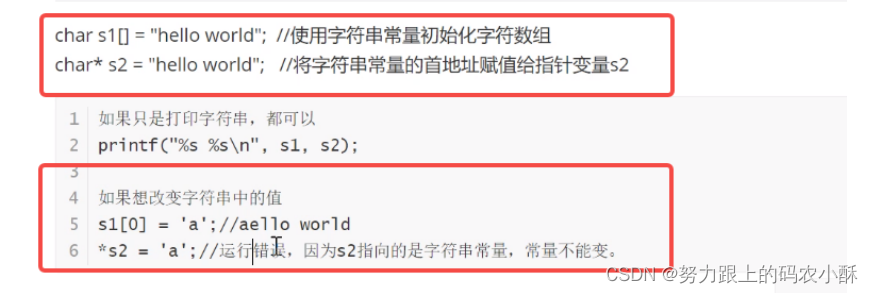
指针变量常见的用法之二: 指针指向字符串常量
指针所占内存空间的大小:
- 一个字节有8位二进制
- 在32位系统中一个地址占4个字节,和地址类型无关,和谁的地址都无关,所以一个指针变量是4个字节;64位系统,指针变量是8个字节
在32位系统中,每个地址(指向内存中某个位置的指针)占用4个字节的内存空间。这意味着,无论指针的具体类型、指向的变量或函数的类型,或者指针指向的内存区域是在哪个进程或线程中,一个指针变量都需要4个字节的内存空间来存储它所指向的地址。
例如,在C语言中,一个指向整数类型int的指针变量,其实际上只是一个内存地址,用来存储该整数变量在内存中的地址。在32位系统中,这个指针变量需要4个字节的内存空间来存储它所指向的整数变量的地址。同样地,一个指向字符类型char的指针变量,也需要4个字节的内存空间。
因此,可以得出结论:在32位系统中,一个指针变量所占用的内存空间大小固定为4个字节,与它所指向的变量类型、指向的内存区域、以及指针本身的类型等都无关。
这个规律同样适用于64位系统,只不过每个地址占用的内存空间变为8个字节。

两个指针变量之间赋值,就是修改指向
#include <stdio.h>
// 实参初始化形参 int* m = p int* n = q;
//函数内部三行执行完,m指向q,n指向p
void fun(int* m,int* n)
{
int* temp = m;
m = n;
n = temp;
}
int main()
{
int a = 3, b = 5;
int* p = &a, q = &b;
fun(p,q);
//函数中并没有写有关a b的值的语句,只是更改了指向,所以在此输出a b 的值并不变
printf("a is %d b is %d\n", a, b); // ? ? 3 5
return 0;
}
5.4 指针与数组的联系
- 数组名就是数组的首地址。数组名是常量,是数组的元素类型的地址。
- 数组中的元素在内存中连续存放。已知数组首地址,可以通过地址的偏移运算得到数组中的每个元素的地址。
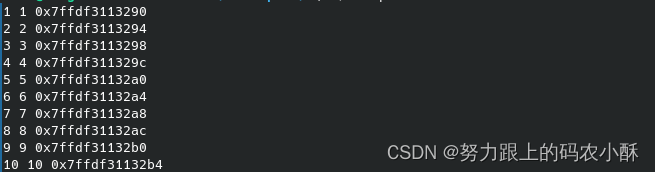
#include <stdio.h>
int main()
{
int a[5];
int i;
printf("a = %p\n", a); //指针变量的打印是%p,打印数组名,数组名是数组的首地址
for(i = 0; i < 5; i++)
{
printf("%p\n",&a[i]);//打印每个元素的地址
}
return 0;
}



5.4.1 下标运算
下标运算:[], 是二元运算,左值是地址,右值是整数
运算规则:*(地址+整数);地址+整数得到一个新的地址
下标运算得到的运算结果不是数值,而是 新地址对应的对象本身。
将数值的首元素地址赋值给指针,我们叫指针指向数组。
定义一个指针指向一个数组,指针的类型应该是数组的元素类型。
#include <stdio.h>
int main()
{
int a[10] = {1,2,3,4,5,6,7,8,9,10};
int* p;//想要定义指针指向数组a;那么指针的类似应与数组a元素的类型一致
p = a;// 等价于 p = &a[0]; 让p指向数组a
int i;
for(i = 0; i < 10; i++)
{
/*
因为p中存放数组a的首地址,所以p+i得到数组a的i元素的地址
*(p+i)运算得到a中i元素本身,等价于p[i]--下标运算
*/
printf("%d %d %p\n",p[i], *(p+i), p+i);
}
return 0;
}

5.4.2 字符数组
- 定义字符数组,将字符串放在数组中,定义指针指向数组,使用指针输出数组中保存的字符串。
- 字符串初始化一个字符数组
- %s需要的参数是 字符类型的地址,它是从所给的地址开始一个一个字符的打印,直到\0为止。
#include <stdio.h>
int main()
{
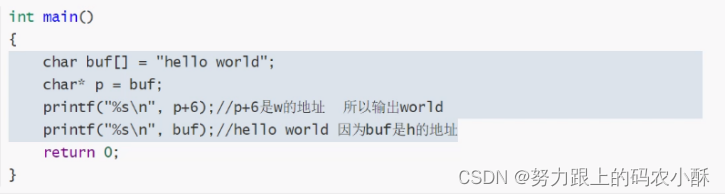
char buf[] = "hello world";
char* p = buf;
printf("%s\n%s\n",p, buf);
return 0;
}

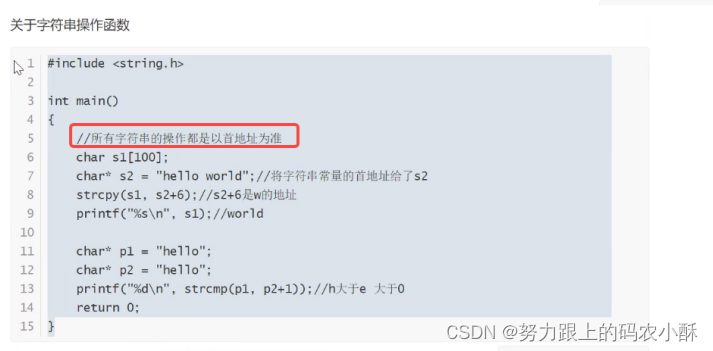
C语言对字符串的处理有两个要素:
- 字符串首地址作为字符串的开始
- ‘\0’作为字符串的结尾【C语言因为对于字符串的所有操作,都是从字符串的首地址开始,到’\0’结束。】
使用%s需要传给它字符串的首地址,它会从首地址开始输出,直到’\0’为止。


5.5 空指针和野指针
野指针:当指针中存放的地址是无效地址,就是野指针。在编程时要避免野指针野指针非常危险,可能会造成不可预计的bug。
空指针 :当一个指针被赋值成NULL的时候,它是空指针,NULL表示没有地址,空指针也不能间接运算,空指针一旦进行间接运算程序必然崩溃。
- 当一个指针还不能确定指向的时候,应该赋值成空指针。
- 当定义一个指针不赋值的时候,它里面一定是无效地址,一定是野指针。
- 错误的三种级别:
- 编译错误,编译器会提示
- 程序运行崩溃,下面的错误叫做段(内存段)错误。

- 没有任何提示,就是得不到正确的结果。

值传递和地址传递
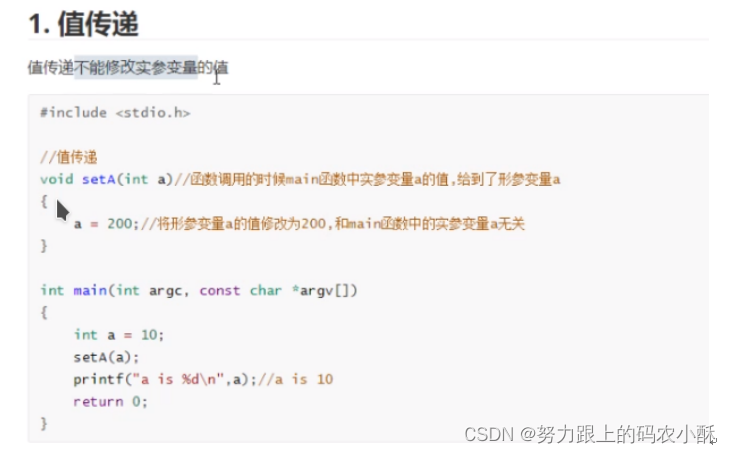
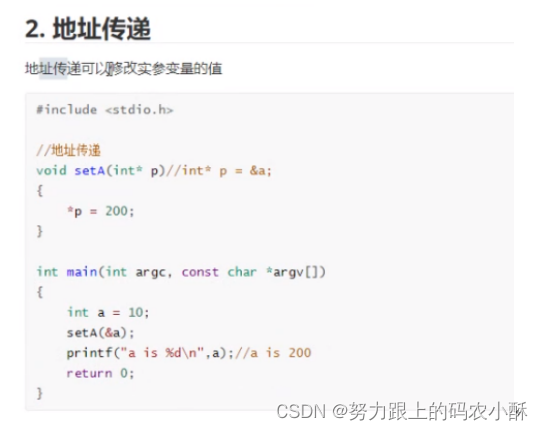
函数传递值的方式
一个函数想要给调用值,传递值,有两种方式
- 返回值:return max;
- 参数上的地址传递 getMax(a,5,&max)

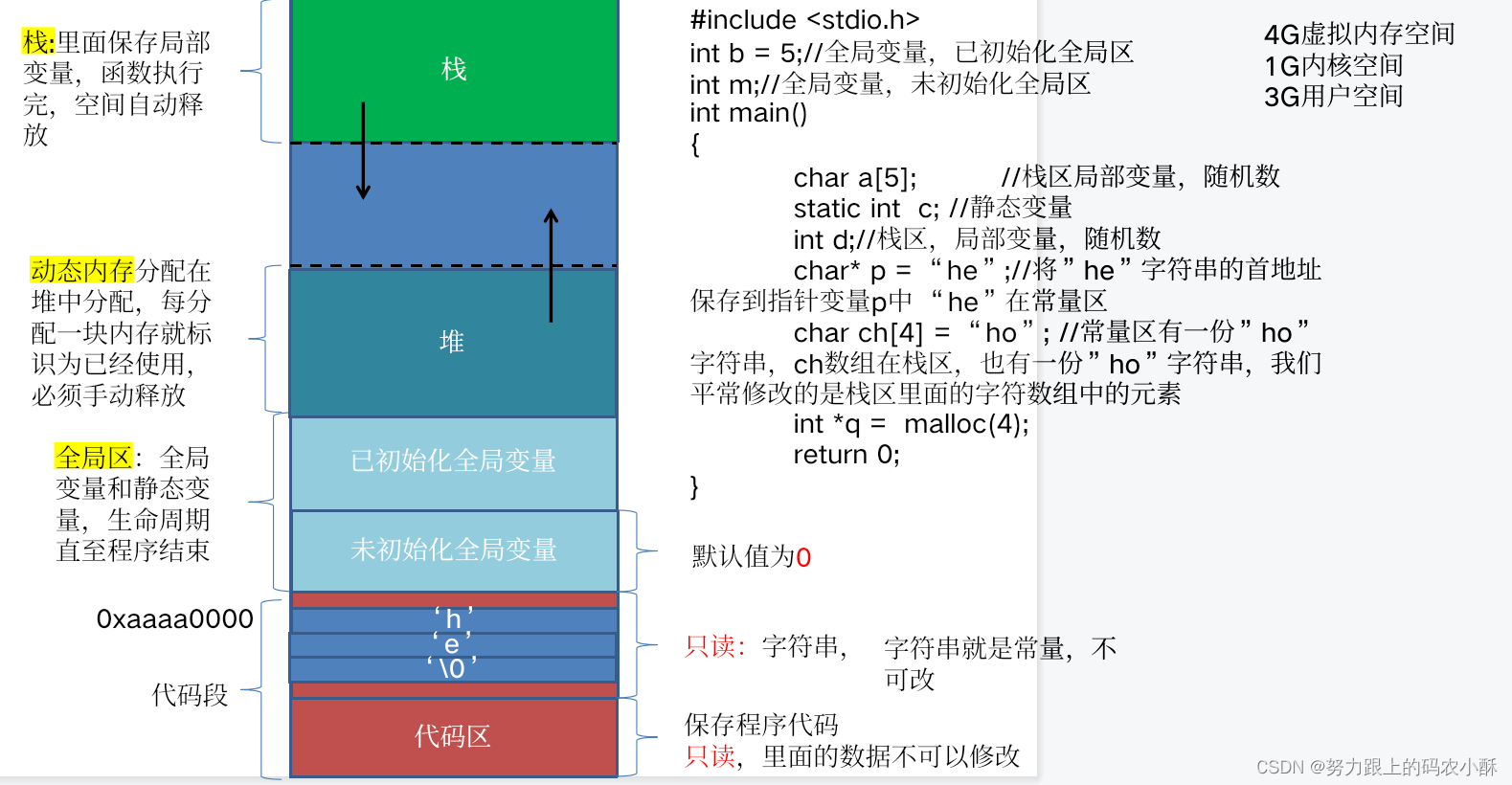
6. 内存分配
系统给内存分出好多区间,我们只关注存放变量的区间
6.1 内存分区(变量可能被分配的内存分区)
- 栈(stack):普通的局部变量在栈空间,在作用域开始执行时自动创建,作用域执行完毕自动删除。栈空间的变量生命周期太短。
栈是一种线性数据结构,通常具有先进后出(Last-In-First-Out,LIFO)的特性。它是一种特殊的内存区域,用于存储函数调用和本地变量。当函数被调用时,栈会在内存中分配一段区域,用于存储函数的参数、返回地址和局部变量等数据。在函数返回时,这些数据会被从栈中弹出,栈的内存空间也会被释放。
- 堆(heap):堆中的变量自己创建自己删除。堆中变量的生命周期自定义。
堆是一种动态分配内存的机制,其数据结构为树形结构。堆的内存空间是由程序员通过动态分配内存来管理的,即程序可以在运行时请求堆内存。堆中存储的数据可以在任何时候被访问和修改,而且不会随着函数的返回而被释放。堆通常用于动态创建对象和数据结构等场景。
- 静态(bss:Block Started by Symbol和data):全局变量和静态局部变量在静态区。程序开始执行就自动创建,程序执行完毕自动删除。
静态(Static)是一种内存分配方式,通常用于存储全局变量、静态变量和常量等数据。静态分配的内存在程序编译时就已经分配好了,并且在程序运行期间保持不变。
在静态内存分配中,有两个主要的存储区域:BSS 和 Data。
除了全局变量和静态变量,还有以下数据类型可以使用静态内存分配:
- 常量(const):常量是一种不可修改的数据类型,可以使用静态内存分配来存储常量的值。
- 函数:函数也可以使用静态内存分配来存储,这样可以避免函数调用时的动态内存分配开销。
- 枚举类型(enum):枚举类型是一种由编译器分配的整数类型,可以使用静态内存分配来存储枚举类型的值\
- 结构体(struct)和联合体(union):结构体和联合体是一种复合数据类型,可以使用静态内存分配来存储它们的成员变量。
- 静态数据类型:C++中的静态数据类型(static)也可以使用静态内存分配来存储。
总之,静态内存分配可以用于存储各种类型的数据,包括全局变量、静态变量、常量、函数、枚举类型、结构体和联合体等。在使用静态内存分配时,需要注意避免内存泄漏和内存溢出等问题,以确保程序的正确性和效率。
- 静态区分为有初始化和没有初始化两部分。我们称没有初始化的区间叫bss、有初始化的叫data
BSS(Block Started by Symbol)段用于存储未初始化的全局变量和静态变量,它通常包含一些程序中定义的未初始化的全局变量和静态变量,这些变量在程序运行之前会被自动初始化为0或者空指针。
Data 段用于存储已初始化的全局变量和静态变量,它通常包含一些程序中定义的已初始化的全局变量和静态变量,这些变量在程序运行之前就已经被初始化为具体的值了
静态变量是一种在程序编译时就已经分配好内存空间的变量,其生命周期与程序的生命周期相同,与函数的调用无关。通常,静态变量的值在程序运行期间不会发生变化,除非程序中显式地对它们进行修改。
在 C 语言中,静态变量可以在函数内部或函数外部定义,使用关键字 static 来标识。在函数内部定义的静态变量只能在函数内部访问,而在函数外部定义的静态变量可以在整个程序中访问。
静态变量与普通变量的区别在于它们不会在函数调用结束后被销毁,而是在程序运行期间一直存在,直到程序结束。因此,静态变量可以用于存储需要在多次函数调用之间保持不变的数据,比如计数器、缓存等。
另外,由于静态变量的作用域是整个程序,因此可以在多个函数之间共享数据,这对于一些需要共享数据的场景非常有用。
- 三个内存分区对变量生命周期的管理不同
静态内存分配和动态内存分配是两种不同的内存管理方式,它们的主要区别在于内存的分配和释放方式不同。
- 静态内存分配是在程序编译时就已经分配好了内存空间,程序运行时不需要再进行内存分配和释放。静态内存分配通常用于存储全局变量、静态变量、常量和函数等数据,以及一些固定大小的数据结构。
- 动态内存分配是在程序运行时根据需要进行内存分配和释放。动态内存分配通常使用堆内存来分配内存空间,程序员可以通过调用 malloc() 或 new() 等函数来动态地分配内存空间,并通过调用 free() 或 delete() 等函数来释放已经分配的内存空间。
- 静态内存分配的主要优点是可以提高程序的运行效率,因为内存空间在编译时已经分配好了,不需要在程序运行时进行内存分配和释放操作。但是,静态内存分配的缺点是内存空间的大小在编译时就已经确定了,不能动态调整大小,因此无法应对一些动态变化的情况。
- 动态内存分配的主要优点是可以动态地分配和释放内存空间,可以根据程序的实际需要动态调整内存空间大小,因此更灵活。但是,动态内存分配的缺点是需要手动管理内存,容易出现内存泄漏和内存溢出等问题,需要程序员自己负责管理内存,增加了程序的复杂度。
6.2 堆空间内存的申请与释放
#include <stdlib.h>
6.2.1 申请内存
void *malloc(size_t size);
malloc :memory allocation
参数:size_t是malloc函数对int类型起的别名,size尺寸,_t type,表示要申请内存的大小,单位字节。
返回值: *表示返回地址,void表示地址的类型是无类型地址,返回的地址是申请内存的地址。比如申请了100个字节,返回的是地址最小的字节的地址。malloc申请的内存是连续的。如果申请内存失败返回NULL。

malloc申请的内存不会初始化
强制类型转换
(类型)变量 这是一个运算,运算的结果是将变量中的值转换成()里的类型后的值。
根据 C 语言标准,void* 可以自动转换为其他指针类型,所以int * p = (int * )malloc(10*sizeof(int)) 等价于 int * p = malloc(10 *sizeof(int))

6.2.2 释放内存
void free(void *p);
参数:是要释放内存的地址,必须是malloc申请的内存才能使用free释放。 free之后内存中的数据还在。
6.2.3 使用注意事项
- malloc 和free 成对去写
- 如果申请的内存没有释放,那么就算程序结束内存依然会被占用,重启电脑会清理掉。
- 申请堆空间的内存却不释放,叫内存泄漏
- malloc 申请内存,会成功或失败,如果成功,则可以使用申请来的堆空间;如果失败,会返回NULL
- 在堆空间被释放掉之后,及时将指针p归零,以防出现使用这块已经被释放掉的内存,造成不必要的风险。
#include <stdio.h>
#include <stdlib.h>
int main()
{
//使用malloc的正常用法
//使用malloc创建数组我们叫动态创建数组,因为可以使用变量表示数组长度。
//int *p = (int *)malloc(10*sizeof(int));
/*
在堆空间申请内存,40个字节,10*sizeof(int)为了提高可读性,表明空间用来做整型数组
将返回的无类型地址放到指针变量pv中
*/
void* pv = malloc(10*sizeof(int));
int *p = (int *)pv;
if(p == NULL) //判读是否申请内存失败
{
printf("error\n");
return 0;
}
int i;
//循环输入,给每个元素赋值
for(i = 0;i < 10;i++)
{
scanf("%d", &p[i]);//p指向数组首地址,所以p[i]是数组i元素
}
for(i = 0;i < 10;i++)
{
printf("%d", &p[i]);
}
free(p); //释放空间,但是不清空数据,释放之后p和pv都是野指针,因为虽然p和pv类型不一样,但是指向同一内存。
//由于后面程序就结束了,这里不置空也行,主要是为了演示用法
p = NULL; //将野指针置空
pv = NULL;//将野指针置空
return 0;
}



#include <stdio.h>
#include <stdlib.h>
int main(int argc, const char *argv[])
{
//在堆区申请空间
int n;
printf("请输入申请空间个数: \n");
scanf("%d",&n);
int *p = malloc(n*sizeof(int));
if(p == NULL)//申请空间失败
{
printf("malloc failed\n");
return -1; // -1代表失败
}
//申请成功,往空间里存值
int i;
for(i = 0;i < n; i++)
{
p[i] = i;
}
//打印空间里的值
for(i = 0;i < n; i++)
{
printf("%d\n",p[i]);
}
printf("\n");
free(p);//释放空间
p = NULL; //将野指针置空
return 0;
}

#include <stdio.h>
#include <stdlib.h>
struct student
{
char name[20];
int age;
int score;
};
void setStudentInfo( struct student *p,int n)
{
int i;
for(i = 0;i < n; i++)
{
printf("请输入第%d个学生信息:姓名 年龄 成绩:\n",i+1);
scanf("%s%d%d",p[i].name,&p[i].age,&p[i].score);
}
}
void showStudentInfo( struct student *p,int n)
{
int i;
for(i = 0;i < n; i++)
{
printf("学生信息:姓名: %s 年龄%d 成绩%d\n",p[i].name,p[i].age,p[i].score);
}
}
int main(int argc, const char *argv[])
{
//在堆区申请空间
struct student *p = NULL;
int n; //班级人数
printf("请输入班级人数: \n");
scanf("%d",&n);
p = malloc(n*sizeof( struct student));
if(p == NULL)//申请空间失败
{
printf("malloc failed\n");
return -1; // -1代表失败
}
setStudentInfo(p,n);
showStudentInfo(p,n);
free(p);//释放空间
p = NULL; //将野指针置空
return 0;
}

7. 位运算
位bit 位运算是对二进制位的运算
为什么使用位运算?
- 赋值运算符至少是给1个字节中的8个bit同时赋值,但是有些逻辑只想给变量中的某些二进制位赋值,此时需要使用位运算。
- 位运算就相当于一个组合拳,用一个变量值,通过位运算来表示好几种状态。
- 所有的位运算,只能针对整数运算 unsigned char short int (无符号数)
- 绝大部分情况下使用位运算都是对无符号整数进行位运算的。因为无符号数没有负数。
- 位运算的目标是变量中具体的二进制位

7.1 左移和右移
7.1.1 左移
“<<” 二元运算,左值<<右值,将左值变量中的所有二进制位,向高位移动右值个位,高位溢出,低位补0。【溢出就是不要了】

7.1.2 右移
“>>” 二元运算 左值>>右值 将左值变量中的所有二进制位,向低位移动右值个位,低位溢出,高位补0,如果是负数,高位补1。

7.2 按位取反
~ 单目运算,将变量中所有的位,1变成0,0变成1
#include <stdio.h>
int main()
{
unsigned char a = 1;//0000 0001
a = ~a;//1111 1110
//查看二进制,使用十六机制更方便
printf("%#x\n", a); //0xFE
return 0;
}
7.3 按位与
& 二元运算,对应的位,有一个位0结果就是0
#include <stdio.h>
int main()
{
unsigned char a = 0xA5; //1010 0101
unsigned char b = 0x8C; // 1000 1100
unsigned char c = a&b;
/*
1010 0101
1000 1100
--------------------
1000 0100
*/
printf("%#x\n", c);//0x84
return 0;
}
按位与的作用
- 给指定的二进制位写0
unsigned char a;
a = a&~(1<<n);//将变量a的n位写0,其他位不变 n>=0 0位是最低位
#include <stdio.h>
int main()
{
unsigned char a = 0xA5; //1010 0101
a = a &~(1<<5);
/*
0010 0000 1<<5
1101 1111 ~(1<<5)
1010 0101
1101 1111 a&~(1<<5)
-----------------------
1000 0101 5位由1变位0
最低位读作0位
*/
printf("%#x\n", a);
return 0;
}
- 读取指定位的值
#include <stdio.h>
int main()
{
unsigned char a = 0xA5;
int i;
for(i = 0; i < 8;i++)
{
if((a&1<<i) == 0)
{
printf("a的%d bit is 0 \n", i);
}
else //a&1<<i 就算不得0,也未必是1
{
printf("a的%d bit is 1\n", i);
}
}
/*
1010 0101
0000 0100
----------------------
0000 0100
*/
return 0;
}
7.4 按位或
| 指定的二进制位,写1 ,有一个1结果就是1
a = a|1<<n; 给a的第n位写1 ,n>=0
#include <stdio.h>
int main()
{
unsigned char a = 0xA5;
a = a|1<<3;
/*
1010 0101
0000 1000
--------------------
1010 1101 3位由0变为1
*/
printf("%#x\n", a); //0xad
return 0;
}
7.5 按位异或
^ 指定位取反 对应的位,相同得0 ,不同得1



8. 宏定义
为什么使用宏定义?
int a = 1;
常量本身没有意义,我们在编程时需要让常量看起来有意义,此时可以使用宏定义。
8.1 无参数
#define 宏名(自己起名) 宏值
#预处理
define是宏定义的指令
宏名需要我们自己起名,一般都是全大写,为了在代码中容易和变量区分,宏名就是我们要给常量起的名字
宏值 是需要起名的常量
宏定义的原理是在预处理的时候,用宏值替代宏名


宏定义要是有多行的话,用\来链接宏的值
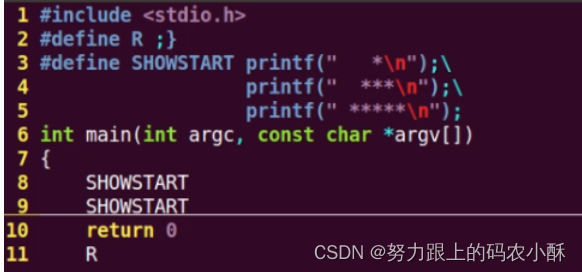
8.2 有参数
代码量比较小的,可以用宏定义带参数的
#include <stdio.h>
#define SQR(x) x*x
int main(int argc, const char *argv[])
{
printf("res is %d\n",SQR(3));
printf("res is %d\n",SQR(3 + 2)); // 3 + 2 * 3 + 2
return 0;
}

#include <stdio.h>
#define SQR(x) (x)*(x)
int main(int argc, const char *argv[])
{
printf("res is %d\n",SQR(3 + 2));
return 0;
}

8.3 带参宏与函数的区别
带参宏:
宏是在编译的时候替换
如果代码量小,调用频率又很高
带参宏会导致代码量大
函数:运行时调用函数,要分配栈空间
8.4 宏定义的优点
-
宏值不仅可以是常量,还可以是任意代码。宏定义的替换是无脑替,写什么就替换成什么,哪怕有语法错误

-
使用宏定义方便后期的修改和维护
-
增加代码的可读性
-
提高程序的运行效率,使用带参宏可以完成函数调用功能,又能减少系统开销,提高运行效率
9. 结构体
为什么使用结构体?
为了将数据进行封装。
将数据封装成一个整体,形成一个新的类型,叫结构体类型
结构体的本质是一种类型
9.1 结构体类型的定义
/*
struct是定义结构体类型的关键字
student 是结构体类型的名字
{}; 注意:{}的结尾有; 这里的{}不是作用域,它里面不能写任何逻辑;里面写的代码不是在定义变量也不是在定义数组,只是在告诉编译器,一旦定义了结构体类型的变量,那么变量中包含这些内容。
*/
struct Student
{
char name[20]; //结构体的成员,或者叫属性
char number[20];//结构体的成员,或者叫属性
int grade; //结构体的成员,或者叫属性
float score; //结构体的成员,或者叫属性
}; //注意:{}的结尾有;
9.2 结构体变量的定义
struct Student
{
char name[20];
char number[20];
int grade;
float score;
};
int main()
{
/*
定义结构体变量首先需要使用关键字 struct ,后面跟结构体类型的名字,最后是结构体变量的名字
*/
struct Student a; //在这里结构体变量的名称叫a,定义结构体变量时结构体的成员才会被定义出来,结构体的成员都在结构体的变量中
printf(“%d\n”,sizeof(a)); //48,结构体变量这么大因为它得装得下所以的成员。
return 0;
}
9.3 访问成员变量
成员运算符 . 二元运算
左值是结构体变量,右值是成员名称
运算结果:是结构体变量中的成员对象本身,可以是变量还可以是数组

9.4 输出
不能直接把结构体变量格式化,只能一个一个属性单独进行格式化。

#include <stdio.h>
#include <string.h>
struct Student
{
char name[20];
char major[20];
int age;
float num;
};
// 因为函数的形参使用了结构体类型,所以函数的声明必须在结构体下面
void print_info(struct Student stu);
int main()
{
struct Student a;
strcpy(a.name, "小明");
strcpy(a.major, "数学");
a.age = 18;
a.num = 10086;
struct Student b;
strcpy(b.name, "小明");
strcpy(b.major, "英语");
b.age = 38;
b.num = 10000;
print_info(a);
print_info(b);
return 0;
}
void print_info(struct Student stu)
{
printf("%s %s %d %f\n",stu.name,stu.major,stu.age,stu.num);
}
9.5 结构体指针
结构体指针,就是普通的指针变量。

9.6 结构体数组
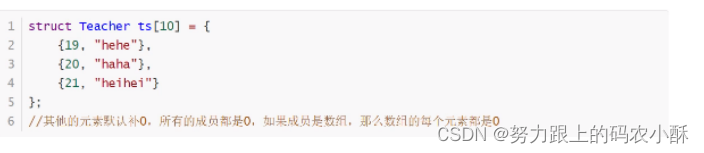
参考:http://c.biancheng.net/view/245.html
9.7 结构体嵌套
参考:https://www.yiibai.com/cprogramming/nested-structure-in-c.html
9.8 总结
定义结构体,尽量把相同的类型的成员写在一起,尽可能的节省内存。