计算机竞赛 题目:基于机器视觉opencv的手势检测 手势识别 算法 - 深度学习 卷积神经网络 opencv python
文章目录
1 简介
🔥 优质竞赛项目系列,今天要分享的是
基于机器视觉opencv的手势检测 手势识别 算法
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 传统机器视觉的手势检测
普通机器视觉手势检测的基本流程如下:
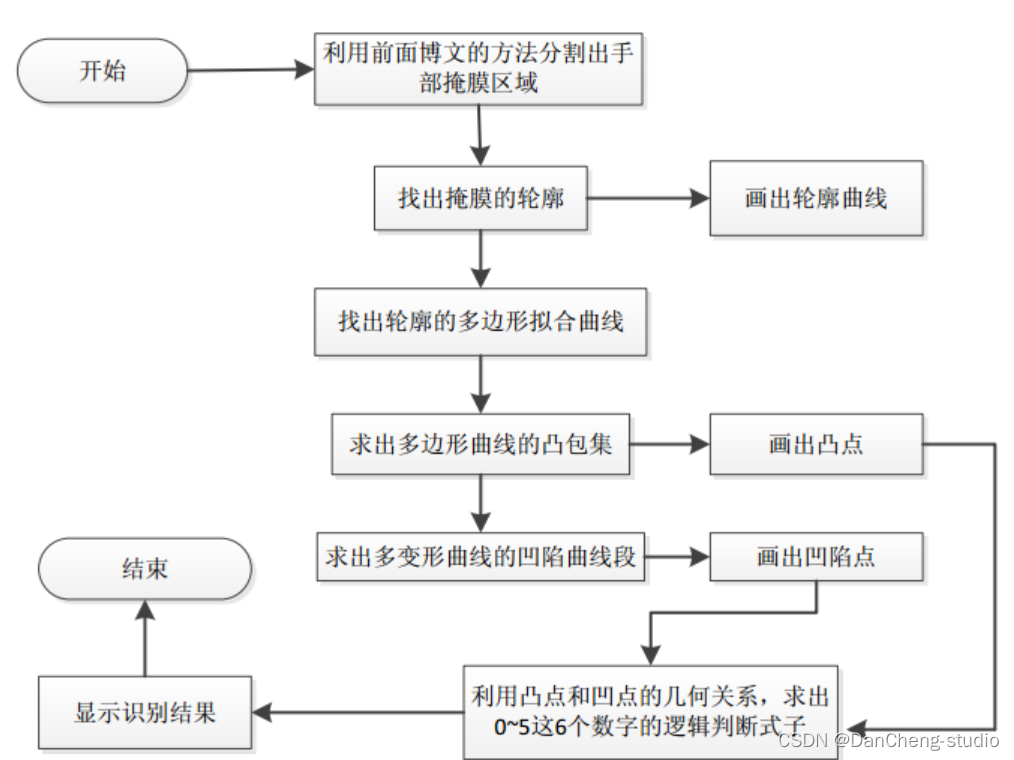
其中轮廓的提取,多边形拟合曲线的求法,凸包集和凹陷集的求法都是采用opencv中自带的函数。手势数字的识别是利用凸包点以及凹陷点和手部中心点的几何关系,简单的做了下逻辑判别了(可以肯定的是这种方法很烂),具体的做法是先在手部定位出2个中心点坐标,这2个中心点坐标之间的距离阈值由程序设定,其中一个中心点就是利用OpenNI跟踪得到的手部位置。有了这2个中心点的坐标,在程序中就可以分别计算出在这2个中心点坐标上的凸凹点的个数。当然了,这样做的前提是用人在做手势表示数字的同时应该是将手指的方向朝上(因为没有像机器学习那样通过样本来训练,所以使用时条件要苛刻很多)。利用上面求出的4种点的个数(另外程序中还设置了2个辅助计算点的个数,具体见代码部分)和简单的逻辑判断就可以识别出数字0~5了。其它的数字可以依照具体的逻辑去设计(还可以设计出多位数字的识别),只是数字越多设计起来越复杂,因为要考虑到它们之间的干扰性,且这种不通用的设计方法也没有太多的实际意义。
2.1 轮廓检测法
使用 void convexityDefects(InputArray contour, InputArray convexhull,
OutputArray convexityDefects) 方法
该函数的作用是对输入的轮廓contour,凸包集合来检测其轮廓的凸型缺陷,一个凸型缺陷结构体包括4个元素,缺陷起点坐标,缺陷终点坐标,缺陷中离凸包线距离最远的点的坐标,以及此时最远的距离。参数3即其输出的凸型缺陷结构体向量。
其凸型缺陷的示意图如下所示:
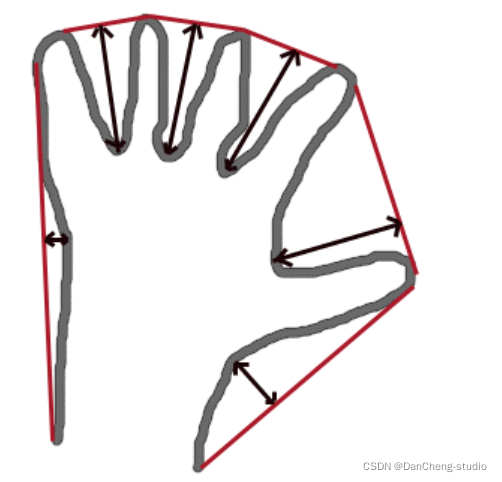
第1个参数虽然写的是contour,字面意思是轮廓,但是本人实验过很多次,发现如果该参数为目标通过轮廓检测得到的原始轮廓的话,则程序运行到onvexityDefects()函数时会报内存错误。因此本程序中采用的不是物体原始的轮廓,而是经过多项式曲线拟合后的轮廓,即多项式曲线,这样程序就会顺利地运行得很好。另外由于在手势识别过程中可能某一帧检测出来的轮廓非常小(由于某种原因),以致于少到只有1个点,这时候如果程序运行到onvexityDefects()函数时就会报如下的错误:
int Mat::checkVector(int _elemChannels, int _depth, bool _requireContinuous) const
{
return (depth() == _depth || _depth <= 0) &&
(isContinuous() || !_requireContinuous) &&
((dims == 2 && (((rows == 1 || cols == 1) && channels() == _elemChannels) || (cols == _elemChannels))) ||
(dims == 3 && channels() == 1 && size.p[2] == _elemChannels && (size.p[0] == 1 || size.p[1] == 1) &&
(isContinuous() || step.p[1] == step.p[2]*size.p[2])))
? (int)(total()*channels()/_elemChannels) : -1;
}
该函数源码大概意思就是说对应的Mat矩阵如果其深度,连续性,通道数,行列式满足一定条件的话就返回Mat元素的个数和其通道数的乘积,否则返回-1;而本文是要求其返回值大于3,有得知此处输入多边形曲线(即参数1)的通道数为2,所以还需要求其元素的个数大于1.5,即大于2才满足ptnum
3。简单的说就是用convexityDefects()函数来对多边形曲线进行凹陷检测时,必须要求参数1曲线本身至少有2个点(也不知道这样分析对不对)。因此本人在本次程序convexityDefects()函数前加入了if(Mat(approx_poly_curve).checkVector(2,
CV_32S) > 3)来判断,只有满足该if条件,才会进行后面的凹陷检测。这样程序就不会再出现类似的bug了。
第2个参数一般是由opencv中的函数convexHull()获得的,一般情况下该参数里面存的是凸包集合中的点在多项式曲线点中的位置索引,且该参数以vector的形式存在,因此参数convexhull中其元素的类型为unsigned
int。在本次凹陷点检测函数convexityDefects()里面根据文档,要求该参数为Mat型。因此在使用convexityDefects()的参数2时,一般将vector直接转换Mat型。
参数3是一个含有4个元素的结构体的集合,如果在c++的版本中,该参数可以直接用vector来代替,Vec4i中的4个元素分别表示凹陷曲线段的起始坐标索引,终点坐标索引,离凸包集曲线最远点的坐标索引以及此时的最远距离值,这4个值都是整数。在c版本的opencv中一般不是保存的索引,而是坐标值。
2.2 算法结果
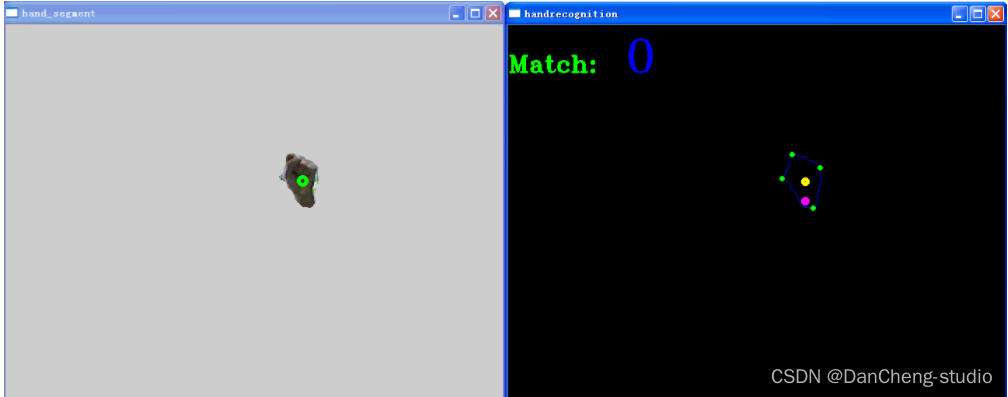
数字“0”的识别结果:
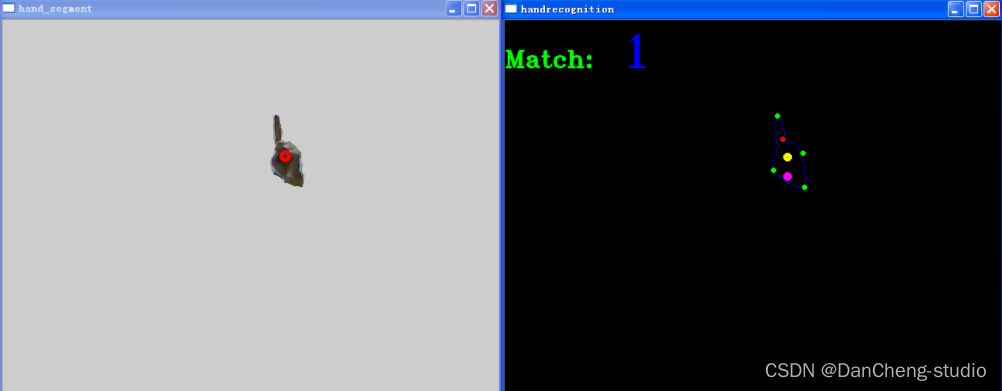
数字“1”的识别结果
数字“2”的识别结果
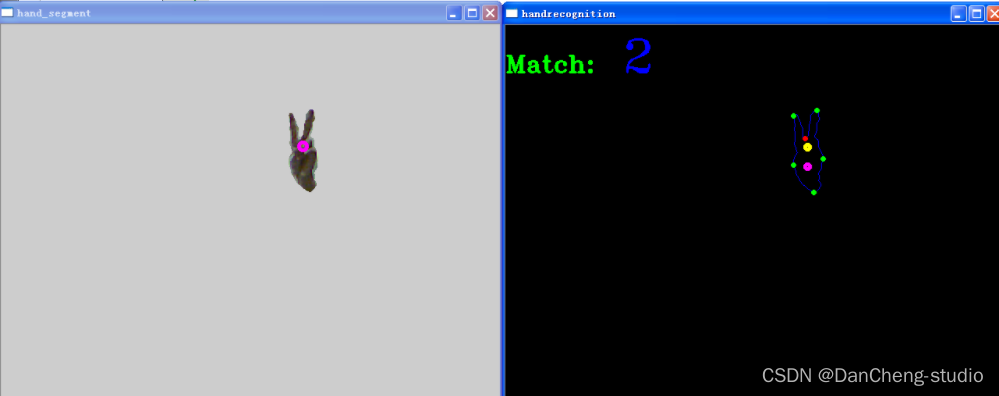
数字“3”的识别结果:
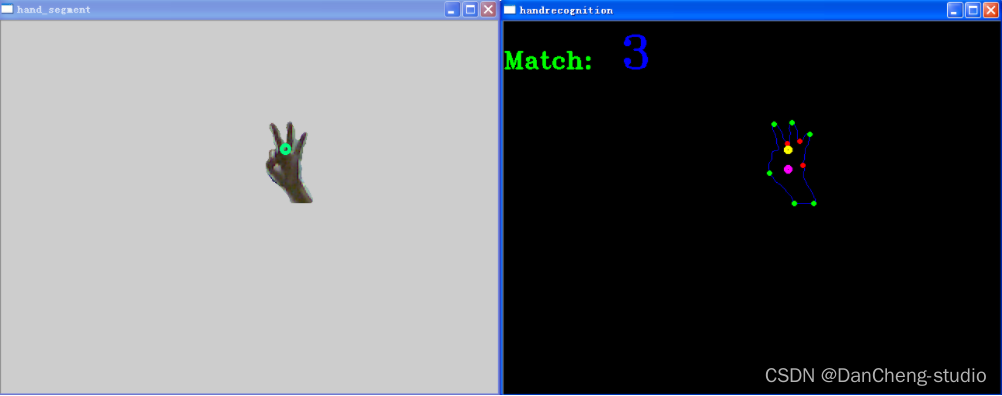
数字“4”的识别结果:
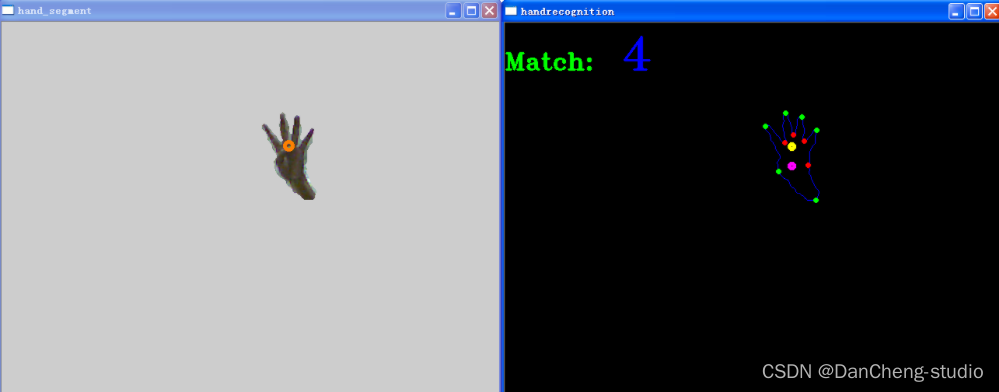
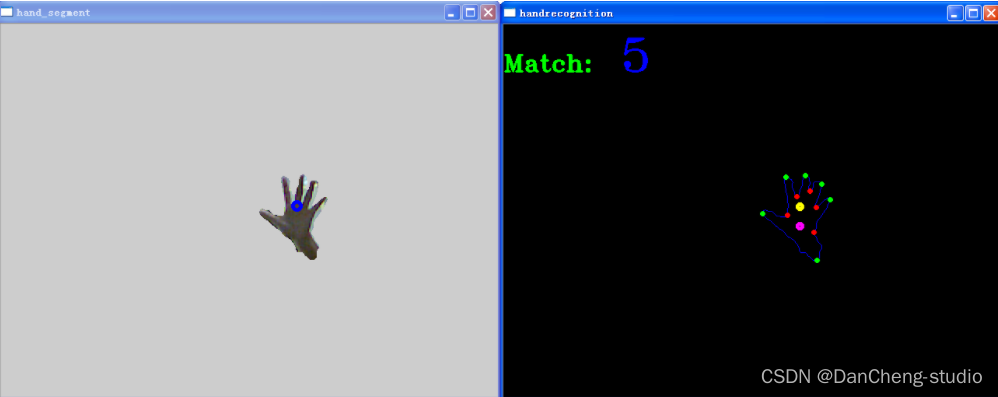
数字“5”的识别结果:
2.3 整体代码实现
2.3.1 算法流程
学长实现过程和上面的系统流程图类似,大概过程如下:
-
1. 求出手部的掩膜
-
2. 求出掩膜的轮廓
-
3. 求出轮廓的多变形拟合曲线
-
4. 求出多边形拟合曲线的凸包集,找出凸点
-
5. 求出多变形拟合曲线的凹陷集,找出凹点
-
6. 利用上面的凸凹点和手部中心点的几何关系来做简单的数字手势识别
(这里用的是C语言写的,这个代码是学长早期写的,同学们需要的话,学长出一个python版本的)
#include
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include
#include "copenni.cpp"
#include
#define DEPTH_SCALE_FACTOR 255./4096.
#define ROI_HAND_WIDTH 140
#define ROI_HAND_HEIGHT 140
#define MEDIAN_BLUR_K 5
#define XRES 640
#define YRES 480
#define DEPTH_SEGMENT_THRESH 5
#define MAX_HANDS_COLOR 10
#define MAX_HANDS_NUMBER 10
#define HAND_LIKELY_AREA 2000
#define DELTA_POINT_DISTENCE 25 //手部中心点1和中心点2距离的阈值
#define SEGMENT_POINT1_DISTANCE 27 //凸点与手部中心点1远近距离的阈值
#define SEGMENT_POINT2_DISTANCE 30 //凸点与手部中心点2远近距离的阈值
using namespace cv;
using namespace xn;
using namespace std;
int main (int argc, char **argv)
{
unsigned int convex_number_above_point1 = 0;
unsigned int concave_number_above_point1 = 0;
unsigned int convex_number_above_point2 = 0;
unsigned int concave_number_above_point2 = 0;
unsigned int convex_assist_above_point1 = 0;
unsigned int convex_assist_above_point2 = 0;
unsigned int point_y1 = 0;
unsigned int point_y2 = 0;
int number_result = -1;
bool recognition_flag = false; //开始手部数字识别的标志
vector<Scalar> color_array;//采用默认的10种颜色
{
color_array.push_back(Scalar(255, 0, 0));
color_array.push_back(Scalar(0, 255, 0));
color_array.push_back(Scalar(0, 0, 255));
color_array.push_back(Scalar(255, 0, 255));
color_array.push_back(Scalar(255, 255, 0));
color_array.push_back(Scalar(0, 255, 255));
color_array.push_back(Scalar(128, 255, 0));
color_array.push_back(Scalar(0, 128, 255));
color_array.push_back(Scalar(255, 0, 128));
color_array.push_back(Scalar(255, 128, 255));
}
vector<unsigned int> hand_depth(MAX_HANDS_NUMBER, 0);
vector<Rect> hands_roi(MAX_HANDS_NUMBER, Rect(XRES/2, YRES/2, ROI_HAND_WIDTH, ROI_HAND_HEIGHT));
namedWindow("color image", CV_WINDOW_AUTOSIZE);
namedWindow("depth image", CV_WINDOW_AUTOSIZE);
namedWindow("hand_segment", CV_WINDOW_AUTOSIZE); //显示分割出来的手的区域
namedWindow("handrecognition", CV_WINDOW_AUTOSIZE); //显示0~5数字识别的图像
COpenNI openni;
if(!openni.Initial())
return 1;
if(!openni.Start())
return 1;
while(1) {
if(!openni.UpdateData()) {
return 1;
}
/*获取并显示色彩图像*/
Mat color_image_src(openni.image_metadata_.YRes(), openni.image_metadata_.XRes(),
CV_8UC3, (char *)openni.image_metadata_.Data());
Mat color_image;
cvtColor(color_image_src, color_image, CV_RGB2BGR);
Mat hand_segment_mask(color_image.size(), CV_8UC1, Scalar::all(0));
for(auto itUser = openni.hand_points_.cbegin(); itUser != openni.hand_points_.cend(); ++itUser) {
point_y1 = itUser->second.Y;
point_y2 = itUser->second.Y + DELTA_POINT_DISTENCE;
circle(color_image, Point(itUser->second.X, itUser->second.Y),
5, color_array.at(itUser->first % color_array.size()), 3, 8);
/*设置不同手部的深度*/
hand_depth.at(itUser->first % MAX_HANDS_COLOR) = (unsigned int)(itUser->second.Z* DEPTH_SCALE_FACTOR);//itUser->first会导致程序出现bug
/*设置不同手部的不同感兴趣区域*/
hands_roi.at(itUser->first % MAX_HANDS_NUMBER) = Rect(itUser->second.X - ROI_HAND_WIDTH/2, itUser->second.Y - ROI_HAND_HEIGHT/2,
ROI_HAND_WIDTH, ROI_HAND_HEIGHT);
hands_roi.at(itUser->first % MAX_HANDS_NUMBER).x = itUser->second.X - ROI_HAND_WIDTH/2;
hands_roi.at(itUser->first % MAX_HANDS_NUMBER).y = itUser->second.Y - ROI_HAND_HEIGHT/2;
hands_roi.at(itUser->first % MAX_HANDS_NUMBER).width = ROI_HAND_WIDTH;
hands_roi.at(itUser->first % MAX_HANDS_NUMBER).height = ROI_HAND_HEIGHT;
if(hands_roi.at(itUser->first % MAX_HANDS_NUMBER).x <= 0)
hands_roi.at(itUser->first % MAX_HANDS_NUMBER).x = 0;
if(hands_roi.at(itUser->first % MAX_HANDS_NUMBER).x > XRES)
hands_roi.at(itUser->first % MAX_HANDS_NUMBER).x = XRES;
if(hands_roi.at(itUser->first % MAX_HANDS_NUMBER).y <= 0)
hands_roi.at(itUser->first % MAX_HANDS_NUMBER).y = 0;
if(hands_roi.at(itUser->first % MAX_HANDS_NUMBER).y > YRES)
hands_roi.at(itUser->first % MAX_HANDS_NUMBER).y = YRES;
}
imshow("color image", color_image);
/*获取并显示深度图像*/
Mat depth_image_src(openni.depth_metadata_.YRes(), openni.depth_metadata_.XRes(),
CV_16UC1, (char *)openni.depth_metadata_.Data());//因为kinect获取到的深度图像实际上是无符号的16位数据
Mat depth_image;
depth_image_src.convertTo(depth_image, CV_8U, DEPTH_SCALE_FACTOR);
imshow("depth image", depth_image);
//取出手的mask部分
//不管原图像时多少通道的,mask矩阵声明为单通道就ok
for(auto itUser = openni.hand_points_.cbegin(); itUser != openni.hand_points_.cend(); ++itUser) {
for(int i = hands_roi.at(itUser->first % MAX_HANDS_NUMBER).x; i < std::min(hands_roi.at(itUser->first % MAX_HANDS_NUMBER).x+hands_roi.at(itUser->first % MAX_HANDS_NUMBER).width, XRES); i++)
for(int j = hands_roi.at(itUser->first % MAX_HANDS_NUMBER).y; j < std::min(hands_roi.at(itUser->first % MAX_HANDS_NUMBER).y+hands_roi.at(itUser->first % MAX_HANDS_NUMBER).height, YRES); j++) {
hand_segment_mask.at<unsigned char>(j, i) = ((hand_depth.at(itUser->first % MAX_HANDS_NUMBER)-DEPTH_SEGMENT_THRESH) < depth_image.at<unsigned char>(j, i))
& ((hand_depth.at(itUser->first % MAX_HANDS_NUMBER)+DEPTH_SEGMENT_THRESH) > depth_image.at<unsigned char>(j,i));
}
}
medianBlur(hand_segment_mask, hand_segment_mask, MEDIAN_BLUR_K);
Mat hand_segment(color_image.size(), CV_8UC3);
color_image.copyTo(hand_segment, hand_segment_mask);
/*对mask图像进行轮廓提取,并在手势识别图像中画出来*/
std::vector< std::vector<Point> > contours;
findContours(hand_segment_mask, contours, CV_RETR_LIST, CV_CHAIN_APPROX_SIMPLE);//找出mask图像的轮廓
Mat hand_recognition_image = Mat::zeros(color_image.rows, color_image.cols, CV_8UC3);
for(int i = 0; i < contours.size(); i++) { //只有在检测到轮廓时才会去求它的多边形,凸包集,凹陷集
recognition_flag = true;
/*找出轮廓图像多边形拟合曲线*/
Mat contour_mat = Mat(contours[i]);
if(contourArea(contour_mat) > HAND_LIKELY_AREA) { //比较有可能像手的区域
std::vector<Point> approx_poly_curve;
approxPolyDP(contour_mat, approx_poly_curve, 10, true);//找出轮廓的多边形拟合曲线
std::vector< std::vector<Point> > approx_poly_curve_debug;
approx_poly_curve_debug.push_back(approx_poly_curve);
drawContours(hand_recognition_image, contours, i, Scalar(255, 0, 0), 1, 8); //画出轮廓
// drawContours(hand_recognition_image, approx_poly_curve_debug, 0, Scalar(256, 128, 128), 1, 8); //画出多边形拟合曲线
/*对求出的多边形拟合曲线求出其凸包集*/
vector<int> hull;
convexHull(Mat(approx_poly_curve), hull, true);
for(int i = 0; i < hull.size(); i++) {
circle(hand_recognition_image, approx_poly_curve[hull[i]], 2, Scalar(0, 255, 0), 2, 8);
/*统计在中心点1以上凸点的个数*/
if(approx_poly_curve[hull[i]].y <= point_y1) {
/*统计凸点与中心点1的y轴距离*/
long dis_point1 = abs(long(point_y1 - approx_poly_curve[hull[i]].y));
int dis1 = point_y1 - approx_poly_curve[hull[i]].y;
if(dis_point1 > SEGMENT_POINT1_DISTANCE && dis1 >= 0) {
convex_assist_above_point1++;
}
convex_number_above_point1++;
}
/*统计在中心点2以上凸点的个数*/
if(approx_poly_curve[hull[i]].y <= point_y2) {
/*统计凸点与中心点1的y轴距离*/
long dis_point2 = abs(long(point_y2 - approx_poly_curve[hull[i]].y));
int dis2 = point_y2 - approx_poly_curve[hull[i]].y;
if(dis_point2 > SEGMENT_POINT2_DISTANCE && dis2 >= 0) {
convex_assist_above_point2++;
}
convex_number_above_point2++;
}
}
// /*对求出的多边形拟合曲线求出凹陷集*/
std::vector<Vec4i> convexity_defects;
if(Mat(approx_poly_curve).checkVector(2, CV_32S) > 3)
convexityDefects(approx_poly_curve, Mat(hull), convexity_defects);
for(int i = 0; i < convexity_defects.size(); i++) {
circle(hand_recognition_image, approx_poly_curve[convexity_defects[i][2]] , 2, Scalar(0, 0, 255), 2, 8);
/*统计在中心点1以上凹陷点的个数*/
if(approx_poly_curve[convexity_defects[i][2]].y <= point_y1)
concave_number_above_point1++;
/*统计在中心点2以上凹陷点的个数*/
if(approx_poly_curve[convexity_defects[i][2]].y <= point_y2)
concave_number_above_point2++;
}
}
}
/**画出手势的中心点**/
for(auto itUser = openni.hand_points_.cbegin(); itUser != openni.hand_points_.cend(); ++itUser) {
circle(hand_recognition_image, Point(itUser->second.X, itUser->second.Y), 3, Scalar(0, 255, 255), 3, 8);
circle(hand_recognition_image, Point(itUser->second.X, itUser->second.Y + 25), 3, Scalar(255, 0, 255), 3, 8);
}
/*手势数字0~5的识别*/
//"0"的识别
if((convex_assist_above_point1 ==0 && convex_number_above_point2 >= 2 && convex_number_above_point2 <= 3 &&
concave_number_above_point2 <= 1 && concave_number_above_point1 <= 1) || (concave_number_above_point1 ==0
|| concave_number_above_point2 == 0) && recognition_flag == true)
number_result = 0;
//"1"的识别
if(convex_assist_above_point1 ==1 && convex_number_above_point1 >=1 && convex_number_above_point1 <=2 &&
convex_number_above_point2 >=2 && convex_assist_above_point2 == 1)
number_result = 1;
//"2"的识别
if(convex_number_above_point1 == 2 && concave_number_above_point1 == 1 && convex_assist_above_point2 == 2
/*convex_assist_above_point1 <=1*/ && concave_number_above_point2 == 1)
number_result = 2;
//"3"的识别
if(convex_number_above_point1 == 3 && concave_number_above_point1 <= 3 &&
concave_number_above_point1 >=1 && convex_number_above_point2 >= 3 && convex_number_above_point2 <= 4 &&
convex_assist_above_point2 == 3)
number_result = 3;
//"4"的识别
if(convex_number_above_point1 == 4 && concave_number_above_point1 <=3 && concave_number_above_point1 >=2 &&
convex_number_above_point2 == 4)
number_result = 4;
//"5"的识别
if(convex_number_above_point1 >=4 && convex_number_above_point2 == 5 && concave_number_above_point2 >= 3 &&
convex_number_above_point2 >= 4)
number_result = 5;
if(number_result !=0 && number_result != 1 && number_result != 2 && number_result != 3 && number_result != 4 && number_result != 5)
number_result == -1;
/*在手势识别图上显示匹配的数字*/
std::stringstream number_str;
number_str << number_result;
putText(hand_recognition_image, "Match: ", Point(0, 60), 4, 1, Scalar(0, 255, 0), 2, 0 );
if(number_result == -1)
putText(hand_recognition_image, " ", Point(120, 60), 4, 2, Scalar(255, 0 ,0), 2, 0);
else
putText(hand_recognition_image, number_str.str(), Point(150, 60), 4, 2, Scalar(255, 0 ,0), 2, 0);
imshow("handrecognition", hand_recognition_image);
imshow("hand_segment", hand_segment);
/*一个循环中对有些变量进行初始化操作*/
convex_number_above_point1 = 0;
convex_number_above_point2 = 0;
concave_number_above_point1 = 0;
concave_number_above_point2 = 0;
convex_assist_above_point1 = 0;
convex_assist_above_point2 = 0;
number_result = -1;
recognition_flag = false;
number_str.clear();
waitKey(20);
}
}
#include "copenni.h"
#include
#include
#include
using namespace xn;
using namespace std;
COpenNI::COpenNI()
{
}
COpenNI::~COpenNI()
{
}
bool COpenNI::Initial()
{
status_ = context_.Init();
if(CheckError("Context initial failed!")) {
return false;
}
context_.SetGlobalMirror(true);//设置镜像
xmode_.nXRes = 640;
xmode_.nYRes = 480;
xmode_.nFPS = 30;
//产生颜色node
status_ = image_generator_.Create(context_);
if(CheckError("Create image generator error!")) {
return false;
}
//设置颜色图片输出模式
status_ = image_generator_.SetMapOutputMode(xmode_);
if(CheckError("SetMapOutputMdoe error!")) {
return false;
}
//产生深度node
status_ = depth_generator_.Create(context_);
if(CheckError("Create depth generator error!")) {
return false;
}
//设置深度图片输出模式
status_ = depth_generator_.SetMapOutputMode(xmode_);
if(CheckError("SetMapOutputMdoe error!")) {
return false;
}
//产生手势node
status_ = gesture_generator_.Create(context_);
if(CheckError("Create gesture generator error!")) {
return false;
}
/*添加手势识别的种类*/
gesture_generator_.AddGesture("Wave", NULL);
gesture_generator_.AddGesture("click", NULL);
gesture_generator_.AddGesture("RaiseHand", NULL);
gesture_generator_.AddGesture("MovingHand", NULL);
//产生手部的node
status_ = hand_generator_.Create(context_);
if(CheckError("Create hand generaotr error!")) {
return false;
}
//产生人体node
status_ = user_generator_.Create(context_);
if(CheckError("Create gesturen generator error!")) {
return false;
}
//视角校正
status_ = depth_generator_.GetAlternativeViewPointCap().SetViewPoint(image_generator_);
if(CheckError("Can't set the alternative view point on depth generator!")) {
return false;
}
//设置与手势有关的回调函数
XnCallbackHandle gesture_cb;
gesture_generator_.RegisterGestureCallbacks(CBGestureRecognized, CBGestureProgress, this, gesture_cb);
//设置于手部有关的回调函数
XnCallbackHandle hands_cb;
hand_generator_.RegisterHandCallbacks(HandCreate, HandUpdate, HandDestroy, this, hands_cb);
//设置有人进入视野的回调函数
XnCallbackHandle new_user_handle;
user_generator_.RegisterUserCallbacks(CBNewUser, NULL, NULL, new_user_handle);
user_generator_.GetSkeletonCap().SetSkeletonProfile(XN_SKEL_PROFILE_ALL);//设定使用所有关节(共15个)
//设置骨骼校正完成的回调函数
XnCallbackHandle calibration_complete;
user_generator_.GetSkeletonCap().RegisterToCalibrationComplete(CBCalibrationComplete, this, calibration_complete);
return true;
}
bool COpenNI::Start()
{
status_ = context_.StartGeneratingAll();
if(CheckError("Start generating error!")) {
return false;
}
return true;
}
bool COpenNI::UpdateData()
{
status_ = context_.WaitNoneUpdateAll();
if(CheckError("Update date error!")) {
return false;
}
//获取数据
image_generator_.GetMetaData(image_metadata_);
depth_generator_.GetMetaData(depth_metadata_);
return true;
}
ImageGenerator &COpenNI::getImageGenerator()
{
return image_generator_;
}
DepthGenerator &COpenNI::getDepthGenerator()
{
return depth_generator_;
}
UserGenerator &COpenNI::getUserGenerator()
{
return user_generator_;
}
GestureGenerator &COpenNI::getGestureGenerator()
{
return gesture_generator_;
}
HandsGenerator &COpenNI::getHandGenerator()
{
return hand_generator_;
}
bool COpenNI::CheckError(const char *error)
{
if(status_ != XN_STATUS_OK) {
cerr << error << ": " << xnGetStatusString( status_ ) << endl;
return true;
}
return false;
}
void COpenNI::CBNewUser(UserGenerator &generator, XnUserID user, void *p_cookie)
{
//得到skeleton的capability,并调用RequestCalibration函数设置对新检测到的人进行骨骼校正
generator.GetSkeletonCap().RequestCalibration(user, true);
}
void COpenNI::CBCalibrationComplete(SkeletonCapability &skeleton, XnUserID user, XnCalibrationStatus calibration_error, void *p_cookie)
{
if(calibration_error == XN_CALIBRATION_STATUS_OK) {
skeleton.StartTracking(user);//骨骼校正完成后就开始进行人体跟踪了
}
else {
UserGenerator *p_user = (UserGenerator*)p_cookie;
skeleton.RequestCalibration(user, true);//骨骼校正失败时重新设置对人体骨骼继续进行校正
}
}
void COpenNI::CBGestureRecognized(GestureGenerator &generator, const XnChar *strGesture, const XnPoint3D *pIDPosition, const XnPoint3D *pEndPosition, void *pCookie)
{
COpenNI *openni = (COpenNI*)pCookie;
openni->hand_generator_.StartTracking(*pEndPosition);
}
void COpenNI::CBGestureProgress(GestureGenerator &generator, const XnChar *strGesture, const XnPoint3D *pPosition, XnFloat fProgress, void *pCookie)
{
}
void COpenNI::HandCreate(HandsGenerator &rHands, XnUserID xUID, const XnPoint3D *pPosition, XnFloat fTime, void *pCookie)
{
COpenNI *openni = (COpenNI*)pCookie;
XnPoint3D project_pos;
openni->depth_generator_.ConvertRealWorldToProjective(1, pPosition, &project_pos);
pair<XnUserID, XnPoint3D> hand_point_pair(xUID, XnPoint3D());//在进行pair类型的定义时,可以将第2个设置为空
hand_point_pair.second = project_pos;
openni->hand_points_.insert(hand_point_pair);//将检测到的手部存入map类型的hand_points_中。
pair<XnUserID, vector<XnPoint3D>> hand_track_point(xUID, vector<XnPoint3D>());
hand_track_point.second.push_back(project_pos);
openni->hands_track_points_.insert(hand_track_point);
}
void COpenNI::HandUpdate(HandsGenerator &rHands, XnUserID xUID, const XnPoint3D *pPosition, XnFloat fTime, void *pCookie)
{
COpenNI *openni = (COpenNI*)pCookie;
XnPoint3D project_pos;
openni->depth_generator_.ConvertRealWorldToProjective(1, pPosition, &project_pos);
openni->hand_points_.find(xUID)->second = project_pos;
openni->hands_track_points_.find(xUID)->second.push_back(project_pos);
}
void COpenNI::HandDestroy(HandsGenerator &rHands, XnUserID xUID, XnFloat fTime, void *pCookie)
{
COpenNI *openni = (COpenNI*)pCookie;
openni->hand_points_.erase(openni->hand_points_.find(xUID));
openni->hands_track_points_.erase(openni->hands_track_points_.find(xUID ));
}
3 深度学习方法做手势识别
3.1 经典的卷积神经网络
卷积神经网络的优势就在于它能够从常见的视觉任务中自动学习目 标数据的特征, 然后将这些特征用于某种特定任务的模型。 随着时代的发展,
深度学习也形成了一些经典的卷积神经网络。
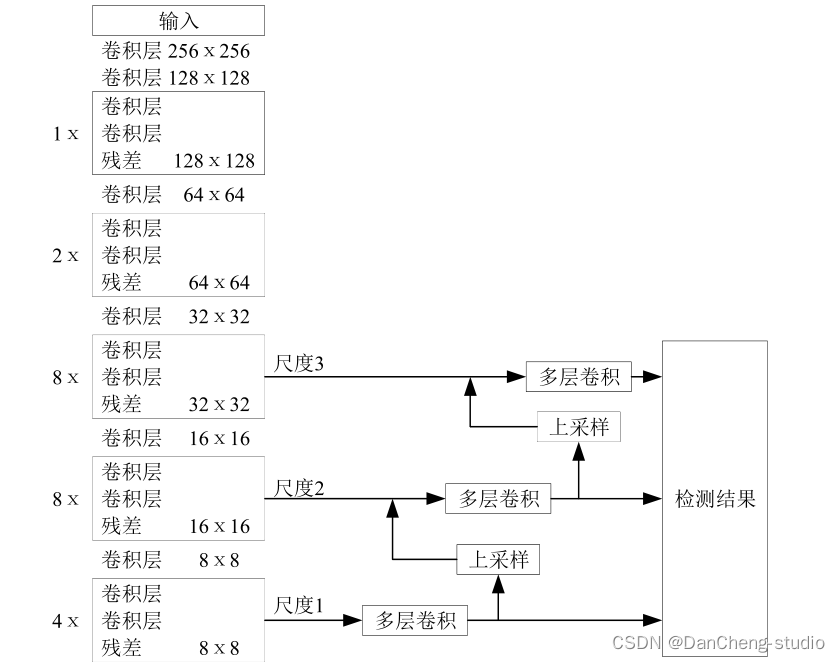
3.2 YOLO系列
YOLO 系列的网络模型最早源于 2016 年, 之后几年经过不断改进相继推出YOLOv2、 YOLOv3
等网络,直到今日yoloV5也诞生了,不得不感慨一句,darknet是真的肝。
最具代表性的yolov3的结构
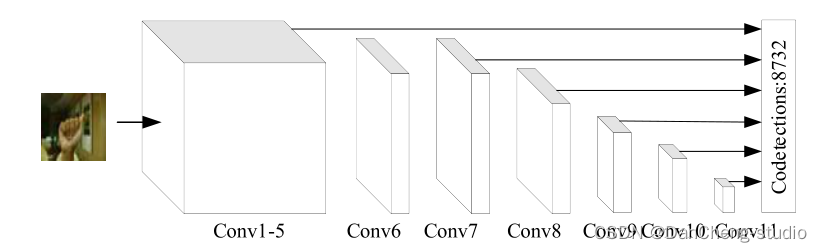
3.3 SSD
SSD 作为典型的一阶段网络模型, 具有更高的操作性, 端到端的学习模式同样受到众多研究者的喜爱
3.4 实现步骤
3.4.1 数据集
手势识别的数据集来自于丹成学长实验室,由于中国手势表示3的手势根据地区有略微差异,按照这个数据集的手势训练与测试即可。
- 图像大小:100*100 像素
- 颜色空间:RGB 种类:
- 图片种类:6 种(0,1,2,3,4,5)
- 每种图片数量:200 张
一共6种手势,每种手势200张图片,共1200张图片(100x100RGB)

3.4.2 图像预处理
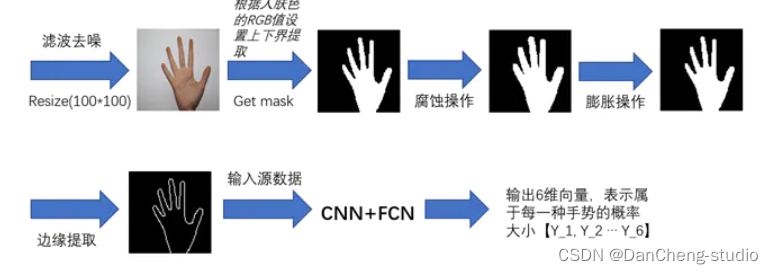
实际图片处理展示:resize前先高斯模糊,提取边缘后可以根据实际需要增加一次中值滤波去噪:

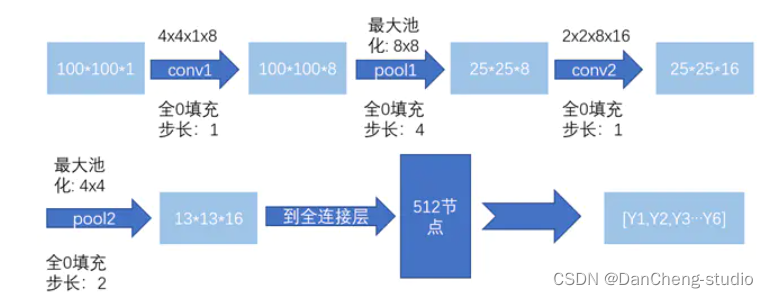
3.4.3 构建卷积神经网络结构
使用tensorflow的框架,构建一个简单的网络结构

Dropout: 增加鲁棒性帮助正则化和避免过拟合
一个相关的早期使用这种技术的论文((ImageNet Classification with Deep Convolutional Neural
Networks, by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton
(2012).))中启发性的dropout解释是:
因为一个神经元不能依赖其他特定的神经元。因此,不得不去学习随机子集神经元间的鲁棒性的有用连接。换句话说。想象我们的神经元作为要给预测的模型,dropout是一种方式可以确保我们的模型在丢失一个个体线索的情况下保持健壮的模型。在这种情况下,可以说他的作用和L1和L2范式正则化是相同的。都是来减少权重连接,然后增加网络模型在缺失个体连接信息情况下的鲁棒性。在提高神经网络表现方面效果较好。
3.4.4 实验训练过程及结果
经过约4800轮的训练后,loss基本收敛,在0.6左右,在120份的测试样本上的模型准确率能够达到约96%


3.5 关键代码
import tensorflow as tf
IMAGE_SIZE = 100
NUM_CHANNELS = 1
CONV1_SIZE = 4
CONV1_KERNEL_NUM = 8
CONV2_SIZE = 2
CONV2_KERNEL_NUM = 16
FC_SIZE = 512
OUTPUT_NODE = 6
def get_weight(shape, regularizer):
w = tf.Variable(tf.truncated_normal(shape,stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(regularizer)(w))
return w
def get_bias(shape):
b = tf.Variable(tf.zeros(shape))
return b
def conv2d(x,w):
return tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_8x8(x):
return tf.nn.max_pool(x, ksize=[1, 8, 8, 1], strides=[1, 4, 4, 1], padding='SAME')
def max_pool_4x4(x):
return tf.nn.max_pool(x, ksize=[1, 4, 4, 1], strides=[1, 2, 2, 1], padding='SAME')
def forward(x, train, regularizer):
conv1_w = get_weight([CONV1_SIZE, CONV1_SIZE, NUM_CHANNELS, CONV1_KERNEL_NUM], regularizer)
conv1_b = get_bias([CONV1_KERNEL_NUM])
conv1 = conv2d(x, conv1_w)
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_b))
pool1 = max_pool_8x8(relu1)
conv2_w = get_weight([CONV2_SIZE, CONV2_SIZE, CONV1_KERNEL_NUM, CONV2_KERNEL_NUM],regularizer)
conv2_b = get_bias([CONV2_KERNEL_NUM])
conv2 = conv2d(pool1, conv2_w)
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_b))
pool2 = max_pool_4x4(relu2)
pool_shape = pool2.get_shape().as_list()
nodes = pool_shape[1] * pool_shape[2] * pool_shape[3]
reshaped = tf.reshape(pool2, [pool_shape[0], nodes])
fc1_w = get_weight([nodes, FC_SIZE], regularizer)
fc1_b = get_bias([FC_SIZE])
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_w) + fc1_b)
if train: fc1 = tf.nn.dropout(fc1, 0.5)
fc2_w = get_weight([FC_SIZE, OUTPUT_NODE], regularizer)
fc2_b = get_bias([OUTPUT_NODE])
y = tf.matmul(fc1, fc2_w) + fc2_b
return y
import tensorflow as tf
import numpy as np
import gesture_forward
import gesture_backward
from image_processing import func5,func6
import cv2
def restore_model(testPicArr):
with tf.Graph().as_default() as tg:
x = tf.placeholder(tf.float32,[
1,
gesture_forward.IMAGE_SIZE,
gesture_forward.IMAGE_SIZE,
gesture_forward.NUM_CHANNELS])
#y_ = tf.placeholder(tf.float32, [None, mnist_lenet5_forward.OUTPUT_NODE])
y = gesture_forward.forward(x,False,None)
preValue = tf.argmax(y, 1)
variable_averages = tf.train.ExponentialMovingAverage(gesture_backward.MOVING_AVERAGE_DECAY)
variables_to_restore = variable_averages.variables_to_restore()
saver = tf.train.Saver(variables_to_restore)
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(gesture_backward.MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
#global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
preValue = sess.run(preValue, feed_dict={x:testPicArr})
return preValue
else:
print("No checkpoint file found")
return -1
def application01():
testNum = input("input the number of test pictures:")
testNum = int(testNum)
for i in range(testNum):
testPic = input("the path of test picture:")
img = func5(testPic)
cv2.imwrite(str(i)+'ttt.jpg',img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
img = img.reshape([1,100,100,1])
img = img.astype(np.float32)
img = np.multiply(img, 1.0/255.0)
# print(img.shape)
# print(type(img))
preValue = restore_model(img)
print ("The prediction number is:", preValue)
def application02():
#vc = cv2.VideoCapture('testVideo.mp4')
vc = cv2.VideoCapture(0)
# 设置每秒传输帧数
fps = vc.get(cv2.CAP_PROP_FPS)
# 获取视频的大小
size = (int(vc.get(cv2.CAP_PROP_FRAME_WIDTH)),int(vc.get(cv2.CAP_PROP_FRAME_HEIGHT)))
# 生成一个空的视频文件
# 视频编码类型
# cv2.VideoWriter_fourcc('X','V','I','D') MPEG-4 编码类型
# cv2.VideoWriter_fourcc('I','4','2','0') YUY编码类型
# cv2.VideoWriter_fourcc('P','I','M','I') MPEG-1 编码类型
# cv2.VideoWriter_fourcc('T','H','E','O') Ogg Vorbis类型,文件名为.ogv
# cv2.VideoWriter_fourcc('F','L','V','1') Flask视频,文件名为.flv
#vw = cv2.VideoWriter('ges_pro.avi',cv2.VideoWriter_fourcc('X','V','I','D'), fps, size)
# 读取视频第一帧的内容
success, frame = vc.read()
# rows = frame.shape[0]
# cols = frame.shape[1]
# t1 = int((cols-rows)/2)
# t2 = int(cols-t1)
# M = cv2.getRotationMatrix2D((cols/2,rows/2),90,1)
# frame = cv2.warpAffine(frame,M,(cols,rows))
# frame = frame[0:rows, t1:t2]
# cv2.imshow('sd',frame)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
while success:
#90度旋转
# img = cv2.warpAffine(frame,M,(cols,rows))
# img = img[0:rows, t1:t2]
img = func6(frame)
img = img.reshape([1,100,100,1])
img = img.astype(np.float32)
img = np.multiply(img, 1.0/255.0)
preValue = restore_model(img)
# 写入视频
cv2.putText(frame,"Gesture:"+str(preValue),(50,50),cv2.FONT_HERSHEY_PLAIN,2.0,(0,0,255),1)
#vw.write(frame)
cv2.imshow('gesture',frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 读取视频下一帧的内容
success, frame = vc.read()
vc.release()
cv2.destroyAllWindows()
print('viedo app over!')
def main():
#application01()
application02()
if __name__ == '__main__':
main()
4 最后
🧿 更多资料, 项目分享: