GBK编码的理解
1、我们学程序的时候,所熟知的ASCII码,就是一种编码方式
计算机底层,就只认识0和1.
举个例子,以3bit为例:
所以,如果是000的话,可以对应数字0
如果是001的话,可以对应数字1
。。。
如果是111的话,可以对应数字7。
老外才多少个字符,总共才26个英文字母,加上大小写,才52个。
后来有扩展了一些其他字符,如+-*/ 空格之类的,又扩展了一些控制字符和不可见字符,如CTRL键,DEL键,空格键等。
总之,1个字节,8bit,有256种编码方式,完全可以对应这么多字符。
所以ASCII码字符的所谓编码方式,其实就是数值跟字符建立一个一一映射的关系。(这个一一映射就是高中里面学到的函数)
然后计算机解析到这个这个数值,就会在屏幕上画出对应的点阵字母——所有在屏幕上显示的东西,都是点阵显示的。因为像素比较大,人眼看起来还是比较连续的,但是如果放大的话,可以看出来还是歪歪曲曲的。

如上图,B这个字母就可以用8*12的点阵来显示,当读取到B的ASCII码值的时候,就调出来显示即可。这就完成了编码。
2、ASCII初始字符就127个。后来又扩展了,扩展了一些希腊字母。
整个欧洲的知识体系就是建立在希腊字母表上面的。
3、但是中国不一样,中国的语言体系,是另一套体系,中国的文字,不是字母,而是象形文字。
很明显,以8bit一个字节来编码汉字,很明显不够。中国常用的汉字有6000多个。
那就用两个字节16bit来编码。16bit最多是65536种可能,完全可以覆盖常用的汉字(当然,如果遇到生僻字怎么办?)
用16bit来编码,比如,用16进制数字,0xBABA,可以编码成汉字——“汉”
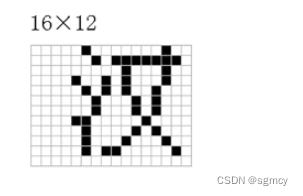
当计算机识别到16进制数字0xBABA,就可以采用一个16*12的点阵来显示汉字“汉”。这样就完成了编码。
这种编码方式,取了一个名字,叫做GBK编码。也叫国标编码。
GBK编码表,类似ASCII码表,很明显,GBK编码表比ASCII表更复杂,排列可能性更多。
GBK编码表,可以查看下面的连接:

每个编码表前面有一个字节,如上图所示,那么多字节显示在BA这一个模块里面。如果要查找汉字“汉”,那么汉字在BA模块里面,在第B行,第A列,所以“汉”的编码就是——BABA(16进制的数,0xBABA)

同理,如果要查看汉字“花”的GBK编码值,那么查找到花在“BB”方块内,在第A行第8列,所以“花”——BBA8
这就完成了GBK编码汉字的功能。
GBK编码范围:8140-FEFE
所有的汉字都是放在一个个的方块里面的,这个方块的编码是在81~FE范围的,行是4~F行,列是0~F列,但是每个方块里面最后一个F行F列都没有被编码使用。所以每个方块的编码范围又是从40~FE。这样就完成了所有汉字的编码。

GBK编码是对之前老的编码GB2312的扩展。所以猜测,GBK编码是为了解决一些偏僻字的问题,进行了扩展。两万多个汉字,足够用了。
我们国家GBK的编码,不仅仅编码了中文,还编码了日文,还编码了希腊字母。这说明我们国家在制定GBK编码的时候其实就考虑到向世界学习的态度。

当然这涉及到一个计算机世界话语权的问题。因为我们国家前期在计算机领域的发展相较于美国比较慢,所以我们国家也没主导Unicode统一码的标准制定。
从上面的GBK编码表中可以看出,我们国家的工作人员,是有这个雄心壮志,想制定一套兼容天下编码字符的一个表的