【Python】多进程线程与CPU核数
- 多进程数量设置为CPU核数,或者略小于CPU核数;
- 多线程数量,如果是CPU密集任务设为1;如果是IO密集设为合理的值;
- IO密集型:系统运作,大部分的状况是CPU 在等I/O (硬盘/内存)的读/写。
- 计算密集型:大部份时间用来做计算、逻辑判断等CPU 动作的程序称之CPU 密集型。
- 对于IO密集型,多线程效率高于多进程;
- 对于计算密集型任务,多进程效率高于多线程。
总结一下
| IO密集 | 网络请求,文件读写 | 多进程 | CPU核数(or略小于CPU核数) |
| 多线程 | 合理值 | ||
| CPU密集 | 计算,逻辑判断 | 多进程 | CPU核数(or略小于CPU核数) |
| 多线程 | 1 |
GIL全局锁:是python多线程。
多进程设置的大小与CPU核数的关系
在Python中,多进程的数量可以根据CPU核数来设置,以充分利用计算资源并提高程序的性能。通常情况下,可以将多进程的数量设置为机器的CPU核数,或者略少于CPU核数,以避免过度竞争资源而导致性能下降。
以下是一些关于Python多进程设置大小与CPU核数的一般准则:
1. CPU核数:首先,你可以使用`multiprocessing`模块中的`cpu_count()`函数来获取机器的CPU核数。例如:
import multiprocessing
num_cpus = multiprocessing.cpu_count()2. 多进程数量:根据机器的CPU核数,你可以将多进程的数量设置为相应的值。通常情况下,将多进程数量设置为CPU核数是一个合理的选择。例如:
num_processes = num_cpus3. 考虑资源竞争:在设置多进程数量时,需要考虑到每个进程所需的资源(如内存、I/O等)。如果每个进程需要较多的资源,可以将多进程数量设置为略少于CPU核数,以避免过度竞争资源而导致性能下降。
需要注意的是,多进程的设置也取决于具体的应用场景和任务类型。有时候,根据具体情况进行实验和调整,找到最佳的多进程数量可能是更好的选择。此外,还可以考虑使用线程(`threading`模块)来实现并发操作,具体取决于任务的性质和需求。
多线程设置的大小与CPU核数的关系
在Python中,多线程的设置大小与CPU核数之间的关系是相对简单的。由于Python的全局解释器锁(GIL)机制限制了多线程的并行执行,因此多线程并不能充分利用多核处理器的能力。
在Python中,多线程适用于I/O密集型任务,如网络请求、文件读写等,因为这些任务通常会涉及等待时间,而在等待的过程中,其他线程可以继续执行。因此,对于I/O密集型任务,可以将多线程的数量设置为适当的值,以充分利用CPU的等待时间。
然而,对于CPU密集型任务,由于GIL的存在,多线程并不能实现真正的并行加速。在这种情况下,多线程的数量增加并不会提高程序的性能,反而可能由于线程之间的频繁切换而导致性能下降。因此,在CPU密集型任务中,通常建议将多线程的数量设置为1,以避免不必要的开销。
综上所述,多线程的设置大小与CPU核数之间的关系在Python中并不直接相关。对于I/O密集型任务,可以适当增加多线程的数量以充分利用CPU的等待时间;对于CPU密集型任务,通常将多线程的数量设置为1即可。需要根据具体的应用场景和任务类型来确定最佳的多线程设置。
参考:
多线程和进程比较
对于IO密集型,多线程效率高于多进程;
对于计算密集型任务,多进程效率高于多线程。
代码如下:
# -*- coding: utf-8 -*-
"""
@Time: 2023/4/18 14:42
@Author: CookieYang
@FileName: threadVsProcess.py
@SoftWare: PyCharm
@brief: 功能简介
"""
import time
from threading import Thread
from multiprocessing import Process
def f1():
# time.sleep(1) #io密集型
# 计算型:
n = 10
for i in range(10000000):
n = n + i
if __name__ == '__main__':
# 查看一下100个线程执行100个任务的执行时间
t_s_time = time.time()
t_list = []
for i in range(100):
t = Thread(target=f1,)
t.start()
t_list.append(t)
[tt.join() for tt in t_list]
t_e_time = time.time()
t_dif_time = t_e_time - t_s_time
print('===================================')
# 查看一下100个进程执行同样的任务的执行时间
p_s_time = time.time()
p_list = []
for i in range(100):
p = Process(target=f1,)
p.start()
p_list.append(p)
[pp.join() for pp in p_list]
p_e_time = time.time()
p_dif_time = p_e_time - p_s_time
print('多线程的执行时间:',t_dif_time)
print('多进程的执行时间:',p_dif_time) 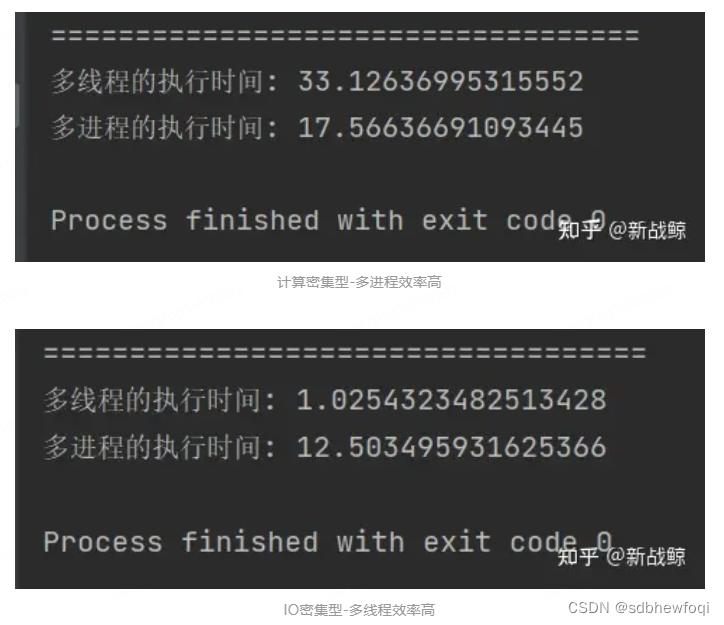
Ubuntu判断进程、线程是IO密集型还是计算密集型

判断方式(看最后的):
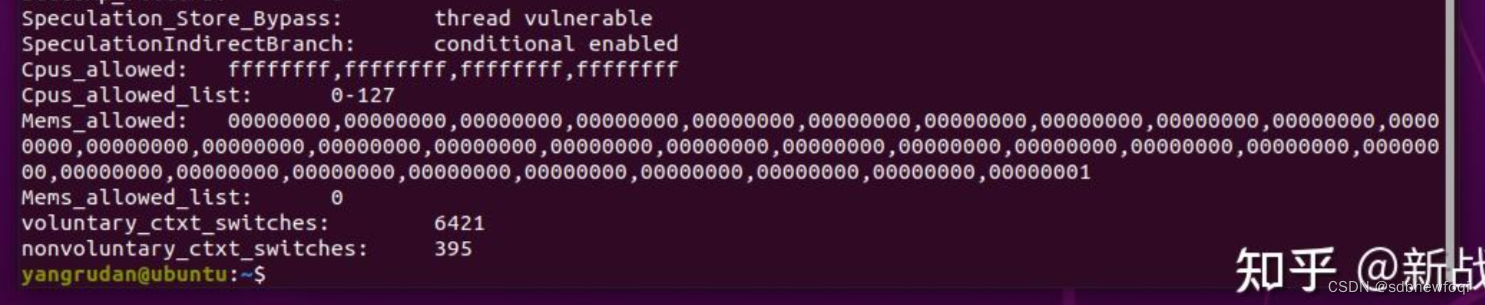
如果voluntary_ctxt_switches 远远小于 nonvoluntary_ctxt_switches,就表示该任务是计算密集型的。
反之voluntary_ctxt_switches 远远大于 nonvoluntary_ctxt_switches,就表示该任务是io密集型的。
进程池
简单用了一下multiprocessing的进程池,非阻塞的apply_async版本,代码如下:
# -*- coding: utf-8 -*-
"""
@Time: 2023/4/18 14:31
@Author: CookieYang
@FileName: multiprocess00L.py
@SoftWare: PyCharm
@brief: 功能简介
"""
# coding: utf-8
import multiprocessing
import time
def func():
msg = "ok"
print("msg:", msg)
time.sleep(0.01)
print("end")
if __name__ == "__main__":
pool = multiprocessing.Pool(processes=3)
for i in range(20):
msg = "hello %d" % (i)
pool.apply_async(func) # 维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
print("wait close~~~~~~~~~~~~~~~~~~~~~~")
pool.close()
pool.join() # 调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
print("done")还有map版本的:
# -*- coding: utf-8 -*-
"""
@Time: 2023/4/18 14:25
@Author: CookieYang
@FileName: multiprocessL.py
@SoftWare: PyCharm
@brief: 功能简介
"""
import time
from multiprocessing import Pool
def f(x):
time.sleep(10)
# n = 10
# for i in range(10000000):
# n = n + i
return x * x
if __name__ == '__main__':
with Pool() as p:
max_count = 10000
time1 = time.time()
res = p.map(f, range(1, max_count + 1))
print(sum(res))
time2 = time.time()
print(f"{max_count},耗时:{time2 - time1:.2f}秒")并发是指多进程还是多线程
python并发是指多进程还是多线程。
Python中的并发可以指多进程并发和多线程并发,两者都是实现并发执行的方式,但有一些区别。
多进程并发是通过创建多个独立的进程来实现的,每个进程有自己独立的内存空间和资源,它们可以并行执行不同的任务。多进程并发可以充分利用多核处理器的能力,适用于CPU密集型任务。在Python中,可以使用`multiprocessing`模块来实现多进程并发。
多线程并发是在同一个进程内创建多个线程来执行任务,这些线程共享进程的内存空间和资源。由于Python的全局解释器锁(GIL)机制的存在,多线程并不能实现真正的并行执行,只能在单个CPU核上进行切换执行。因此,多线程并发适用于I/O密集型任务,如网络请求、文件读写等。在Python中,可以使用`threading`模块来实现多线程并发。
需要根据具体的应用场景和任务类型选择适合的并发方式。对于CPU密集型任务,多进程并发可能更适合;对于I/O密集型任务,多线程并发可能更适合。同时,还可以结合多进程和多线程的方式来实现更高效的并发执行,例如使用`concurrent.futures`模块中的线程池和进程池。
如何理解并发
并发是指在同一时间段内,多个任务或操作同时进行或交替执行的能力。它是一种并行执行的概念,但并发的实现方式可以有多种。
在计算机领域,并发通常用于提高系统的性能和资源利用率。通过并发执行,可以使多个任务或操作在同一时间段内共享计算机的资源,如CPU、内存、磁盘等,从而提高系统的吞吐量和响应能力。
并发可以通过多进程、多线程、协程等方式实现。多进程并发是通过创建多个独立的进程来执行任务,每个进程有自己独立的资源和执行环境。多线程并发是在同一个进程内创建多个线程来执行任务,这些线程共享进程的资源。协程是一种轻量级的线程,可以在同一个线程内实现并发执行,通过协作的方式进行任务切换。
并发的好处在于可以提高系统的响应速度、资源利用率和用户体验。例如,在一个网络服务器中,通过并发处理多个客户端请求,可以提高服务器的吞吐量和并发连接数。在一个图像处理应用中,通过并发执行多个图像处理任务,可以加快处理速度。
然而,并发也带来了一些挑战,如资源竞争、同步和通信等问题。在并发编程中,需要注意对共享资源的访问控制,避免数据竞争和死锁等问题。同时,还需要合理地设计任务调度和通信机制,以确保并发执行的正确性和效率。
综上所述,理解并发意味着理解在同一时间段内多个任务或操作的同时执行或交替执行的能力,以及实现并发的不同方式和应用场景。
并发与并行
并发和并行(图解) - deeplearning的文章 - 知乎(并发,并行的概念看该链接)
总结
- 并发针对单核 CPU 而言,它指的是 CPU 交替执行不同任务的能力;
- 并行针对多核 CPU 而言,它指的是多个核心同时执行多个任务的能力。
- 单核 CPU 只能并发,无法并行;换句话说,并行只可能发生在多核 CPU 中。
- 在多核CPU中,并发和并行一般都会同时存在,它们都是提高 CPU 处理任务能力的重要手段。
我们现在使用的应该都是多核CPU了。
大概理解一下,并行指的是每个核都执行1个任务。并发指的是在每个核内部可以同时交替执行多个任务。
并发+并行
执行任务的数量恰好等于 CPU 核心的数量,是一种理想状态。
但是在实际场景中,处于运行状态的任务是非常多的,尤其是电脑和手机,开机就几十个任务,而 CPU 往往只有 4 核、8 核或者 16 核,远低于任务的数量.
这个时候就会同时存在并发和并行两种情况:所有核心都要并行工作,并且每个核心还要并发工作。例如,一个双核 CPU 要执行四个任务,它的工作状态如下图所示:
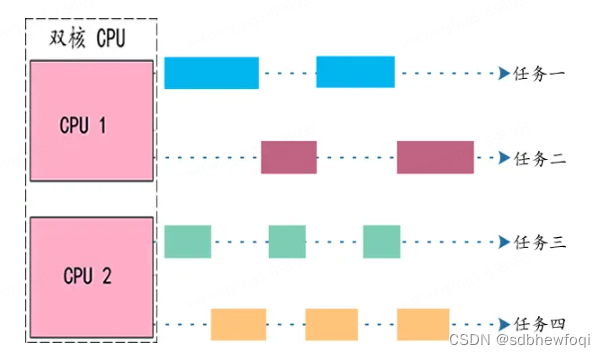
每个核心并发执行两个任务,两个核心并行的话就能执行四个任务。当然也可以一个核心执行一个任务,另一个核心并发执行三个任务,这跟操作系统的分配方式,以及每个任务的工作状态有关系。
引子
一开始梳理这些关系的原因。
服务端开30个进程+100个线程。
这里引发的思考,多线程是不是针对客户端来说的呢?就是你调用模型的时候你可以开多线程,请求服务端的域名呗。
就服务端(模型部署本身来说),有一套pipeline,就是下载图片+图像处理+前向推理+softmax返回结果,这个流程怎么开多线程呢?
梳理完基础概念之后我的回答:请求下载图片的时候,请求访问下图链接,这是IO密集型任务,可以通过多线程并发来提高效率。