Mapreduce小试牛刀(1)
1.与hdfs一样,mapreduce基于hadoop框架,所以我们首先要启动hadoop服务器
---------------------------------------------------------------------------------------------------------------------------------
2.修改hadoop-env.sh位置JAVA_HOME配置,在JAVA_HOME前面加上export,重启主虚拟机,最好也把另外两个节点同位置的该配置文件改了

如果这里不配置好JAVA_HOME变量,那么在后续运行时会出现127号报错,显示未找到JAVA_HOME
---------------------------------------------------------------------------------------------------------------------------------
3.修改内存
修改yarn-site.xml文件中的内存大小。一般来说,第一次都分配的1024mb,但是在进行mapreduce运算时,会要求至少1536mb内存。但是不要直接设置为1536mb,不要忘记操作系统也会占用内存!但是也不要设置的太大,以免把本机下爆

---------------------------------------------------------------------------------------------------------------------------------
4.示例1
本地文档单词统计
1.在某一文件夹下,编辑一个txt文件
vi wdtest.txt
2.上传到某一hdfs的目录下
hdfs dfs -put wdtest.txt /input3.利用hadoop自带的包,进行单词统计
hadoop jar /home/hadoop/hadoop-3.3.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /input /output系统会新建一个叫做ouput的目录收录统计结果(part-r-00000文件)
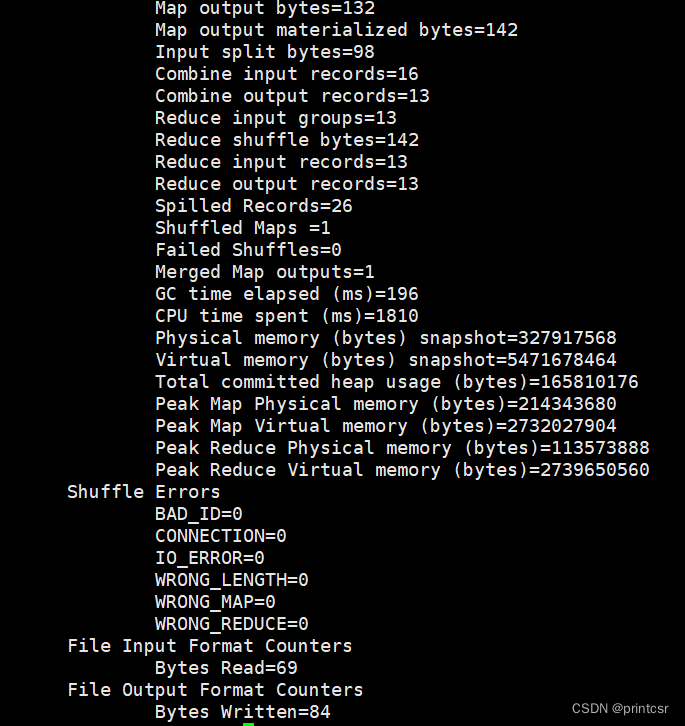

4.利用cat命令查看统计结果
hadoop fs -cat /output/part-r-00000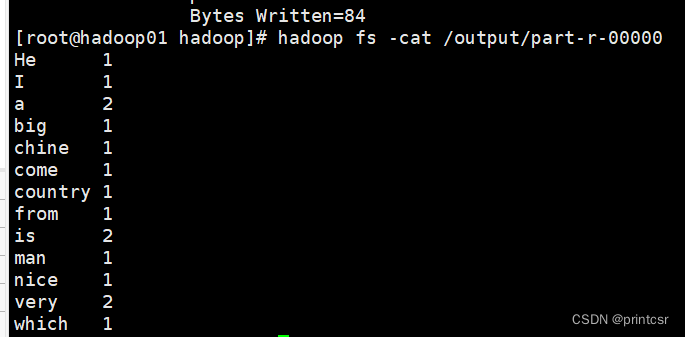
---------------------------------------------------------------------------------------------------------------------------------
5.示例2(Hadoop Streaming统计总的字节数)
输入如下代码,结果会在output2目录下显示
mapred streaming \
-input /input \
-output /output2 \
-mapper /bin/cat \
-reducer /usr/bin/wc注意:要连续、完整输入这段代码,输完后会自动开始计算作业!
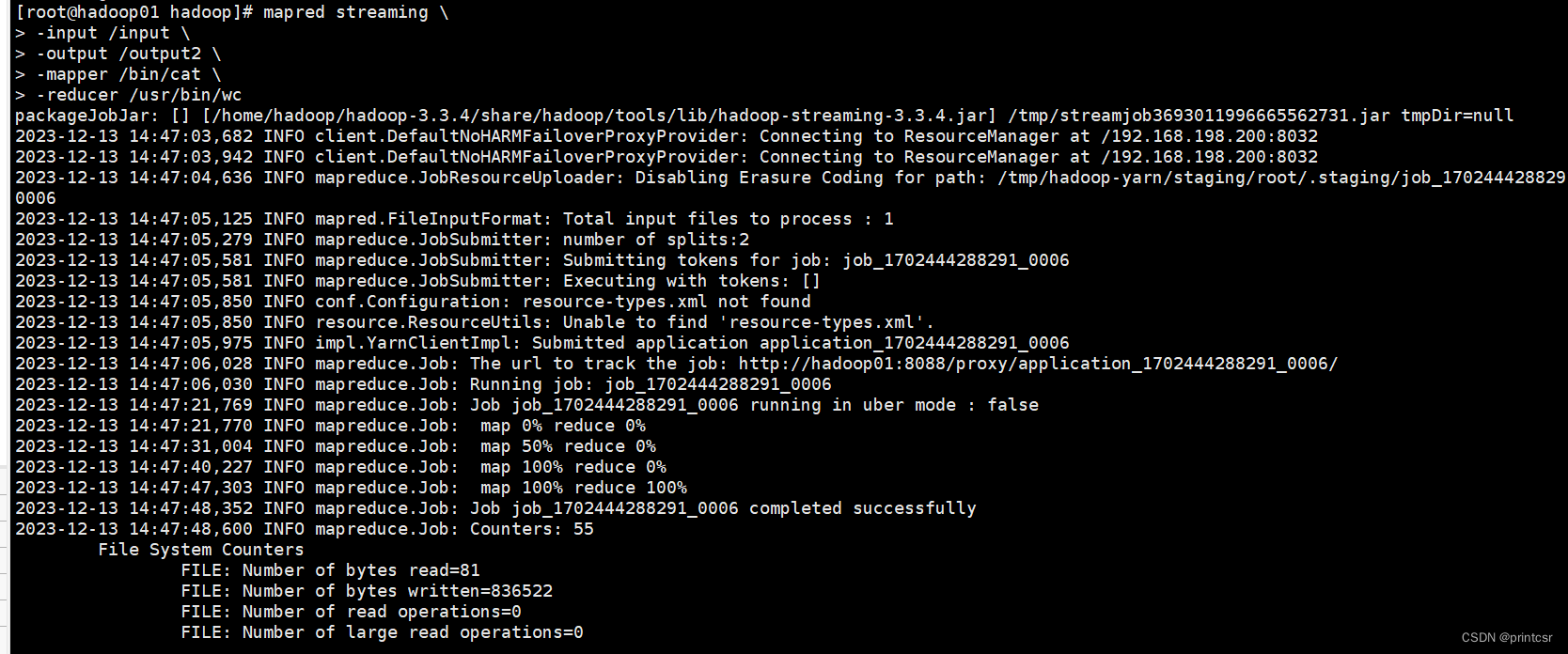

输入代码,查看统计结果:
hadoop fs -cat /output2/part-00000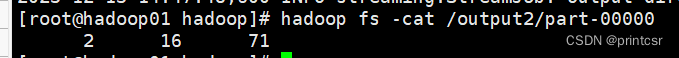
分别为行数、单词数、字节数
这里采用了Hadoop Streaming工具集。Hadoop Streaming是Hadoop新推出的一个工具集。这个工具集并不是提供流式计算的功能,而是允许以命令行的方式代替千篇一律的Driver代码。但是与第一种方法相比,它并不能统计出各个单词出现的次数