hive sql子单元查找组合单元信息
1. 背景
店铺卖东西,会将一部分子商品(单个商品,sku 粒度)打包到一起,变成一个组合商品去售卖。
用户买东西,可能会买多个组合商品。
数仓这边拿到的数据,全是已经拆分到子商品的订单商品数据,也就是说:用户买的时候是组合商品,只有一条订单数据,但数仓表中保存的全是子商品对应的订单数据,会有多条订单数据,大概示意如下。
用后购买商品产生的订单信息:
| order_id(订单id) | combine_goods_id(组合商品id) |
|---|---|
| 1 | 1 |
| 2 | 2 |
数仓得到的拆分之后的订单信息(order):
CREATE EXTERNAL TABLE `zhibo_test.order`(
`order_id` string COMMENT '订单 id',
`goods_id` string COMMENT '商品 id'
)
COMMENT '订单表'
数据:
| order_id(订单id) | goods_id(子商品id) |
|---|---|
| 1 | 1 |
| 1 | 3 |
| 1 | 2 |
| 2 | 4 |
| 2 | 6 |
| 2 | 5 |
| 2 | 7 |
组合商品 1 包含 3 个子商品,子商品 id 分别为:1、2、3,价格都是 100。
组合商品 2 包含 4 个子商品,子商品 id 分别为:4、5、6、7,价格都是 100。
数仓中的组合商品维表信息(dim_combine_goods):
CREATE EXTERNAL TABLE `zhibo_test.dim_combine_goods`(
`combine_goods_id` string COMMENT '组合商品 id',
`combine_goods_name` string COMMENT '组合商品名称',
`goods_id` string COMMENT '商品 id'
)
COMMENT '组合商品维表'
数据:
| combine_goods_id(组合商品id) | combine_goods_name(组合商品名称) | goods_id(子商品id) |
|---|---|---|
| 1 | 组合商品1 | 1 |
| 1 | 组合商品1 | 2 |
| 1 | 组合商品1 | 3 |
| 11 | 组合商品11 | 1 |
| 11 | 组合商品11 | 2 |
| 11 | 组合商品11 | 3 |
| 2 | 组合商品2 | 4 |
| 2 | 组合商品2 | 5 |
| 2 | 组合商品2 | 6 |
| 2 | 组合商品2 | 7 |
| 3 | 组合商品3 | 1 |
| 3 | 组合商品3 | 5 |
组合商品维表中的数据说明:
- 一个子商品,可以属于多个不同的组合商品,参考子商品 1(属于组合商品 1 和 3)、5(属于组合商品 2 和 3)。
- 相同的子商品组合,可以有不同的组合商品信息,参考组合商品 1 和 11,他们的子商品都是 1、2、3。
此时,我要判断数仓中的订单信息数据,每个订单中的子商品所属的组合商品 id 是哪个。
2. 解决方案
这种情况下,是不能直接使用子商品 id 和组合商品维保进行关联的,直接关联的话,由于一个子商品会同时属于多个不同的组合商品,所以会造成很大的数据膨胀,并且关联完的数据,也不是我们需要的结果。
将数仓订单表,根据订单 id 进行分组,然后将子商品 id 聚合,具体处理为:concat_ws('-', collect_set(goods_id)),也就是将订单中的所有子商品 id 聚合起来,然后使用 - 连接成字符串,然后将组合商品维表的数据,根据组合商品 id 分组,然后将子商品 id 聚合,和订单中的行为保持一致:concat_ws('-', collect_set(goods_id)),最后使用聚合之后的子商品 id 字符串进行关联,查询对应的组合商品 id 信息。实例 sql 如下:
with
order_info as (
select order_id
-- 这儿使用 collect_set 和 collect_list 效果一样,主要看自己的数据质量,只要是子商品没有重复即可
-- 使用 concat_ws 函数将 collect_set 的数组结果拼接起来变成字符串,方便后续的比较。
-- 通过实验,直接使用 collect_set 的数据结果也是可以直接 join 的,但是数组之间是不可以直接使用 = 去判断是否相等的,所以还是转化为字符串这种基本数据类型比较好。
,concat_ws('-', collect_set(goods_id)) as goods_id_set
from zhibo_test.`order`
group by order_id
)
,combine_goods_info as (
select combine_goods_id
,concat_ws('-', collect_set(goods_id)) as goods_id_set
from zhibo_test.dim_combine_goods
group by combine_goods_id
)
select a.order_id
,c.combine_goods_id
,b.goods_id
from order_info as a
join zhibo_test.`order` as b
on a.order_id = b.order_id
left join combine_goods_info as c
on a.goods_id_set = c.goods_id_set
运行完上面的 SQL 之后,发现结果中的 combine_goods_id 字段全是 null

经排查发现,由于子商品的顺序在订单表和组合商品维表中的顺序不同,两个 SQL 对子商品 collect_set() 之后的数组结果,里面的顺序也是不同的,因此对其进行优化,优化之后的 SQL 如下:
with
order_info as (
select order_id
-- 这儿使用 collect_set 和 collect_list 效果一样,主要看自己的数据质量,只要是子商品没有重复即可
-- 使用 concat_ws 函数将 collect_set 的数组结果拼接起来变成字符串,方便后续的比较。
-- 通过实验,直接使用 collect_set 的数据结果也是可以直接 join 的,但是数组之间是不可以直接使用 = 去判断是否相等的,所以还是转化为字符串这种基本数据类型比较好。
,concat_ws('-', collect_set(goods_id)) as goods_id_set
from (
select order_id
,goods_id
from zhibo_test.`order`
-- 先对子商品 id 进行排序,再对子商品 id 进行收集和拼接,保证对比时的顺序一致
order by goods_id
) as a
group by order_id
)
,combine_goods_info as (
select combine_goods_id
,concat_ws('-', collect_set(goods_id)) as goods_id_set
from (
select combine_goods_id
,goods_id
from zhibo_test.dim_combine_goods
-- 先对子商品 id 进行排序,再对子商品 id 进行收集和拼接,保证对比时的顺序一致
order by goods_id
) as a
group by combine_goods_id
)
select a.order_id
,c.combine_goods_id
,b.goods_id
from order_info as a
join zhibo_test.`order` as b
on a.order_id = b.order_id
left join combine_goods_info as c
on a.goods_id_set = c.goods_id_set
运行优化之后的 SQL,发现结果正确,所有的订单商品都找到了对应的组合商品信息
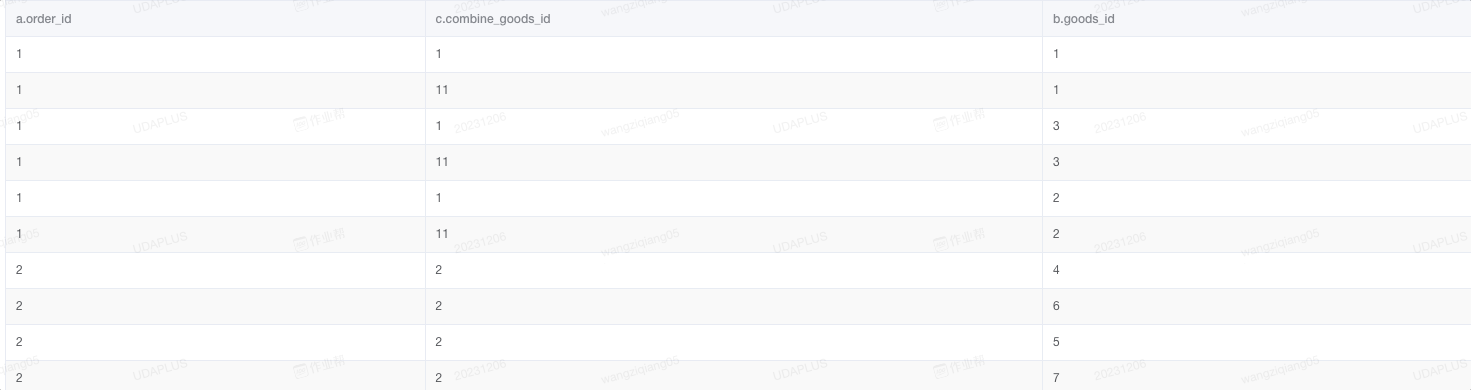
但是,订单表中,order_id 为 1 的数据本来只有 3 条,现在的结果却有 6 条,明显膨胀了。
经过排查可以发现,组合商品维表中,由子商品:1、2、3 组合成的组合商品有两个,分别对应的组合商品 id 为:1、11,因此通过 concat_ws('-', collect_set(goods_id)) as goods_id_set 的结果进行 join 连接,会造成数据的膨胀。
解决方法也很简单,在组合商品维表中,如果相同子商品集合会对应多个组合商品的话,我们取其一即可,也可以将多个组合商品的信息合并起来。下面演示选择其一的 SQL:
with
order_info as (
select order_id
-- 这儿使用 collect_set 和 collect_list 效果一样,主要看自己的数据质量,只要是子商品没有重复即可
-- 使用 concat_ws 函数将 collect_set 的数组结果拼接起来变成字符串,方便后续的比较。
-- 通过实验,直接使用 collect_set 的数据结果也是可以直接 join 的,但是数组之间是不可以直接使用 = 去判断是否相等的,所以还是转化为字符串这种基本数据类型比较好。
,concat_ws('-', collect_set(goods_id)) as goods_id_set
from (
select order_id
,goods_id
from zhibo_test.`order`
-- 先对子商品 id 进行排序,再对子商品 id 进行收集和拼接,保证对比时的顺序一致
order by goods_id
) as a
group by order_id
)
,combine_goods_info as (
select combine_goods_id
,goods_id_set
from (
select combine_goods_id
,goods_id_set
,row_number() over(partition by goods_id_set
order by combine_goods_id) as rn
from (
select combine_goods_id
,concat_ws('-', collect_set(goods_id)) as goods_id_set
from (
select combine_goods_id
,goods_id
from zhibo_test.dim_combine_goods
-- 先对子商品 id 进行排序,再对子商品 id 进行收集和拼接,保证对比时的顺序一致
order by goods_id
) as a
group by combine_goods_id
) as a
) as a
where rn = 1
)
select a.order_id
,c.combine_goods_id
,b.goods_id
from order_info as a
join zhibo_test.`order` as b
on a.order_id = b.order_id
left join combine_goods_info as c
on a.goods_id_set = c.goods_id_set
主要思想就是,对组合商品维表中的 goods_id_set 进行分区,然后对 combine_goods_id 取 Top1,进行去重。执行后的结果如下:

可以看到,所有订单信息,找到了组合商品,并且没有发生数据膨胀。
下面演示将多个组合商品的信息合并起来的 SQL:
with
order_info as (
select order_id
-- 这儿使用 collect_set 和 collect_list 效果一样,主要看自己的数据质量,只要是子商品没有重复即可
-- 使用 concat_ws 函数将 collect_set 的数组结果拼接起来变成字符串,方便后续的比较。
-- 通过实验,直接使用 collect_set 的数据结果也是可以直接 join 的,但是数组之间是不可以直接使用 = 去判断是否相等的,所以还是转化为字符串这种基本数据类型比较好。
,concat_ws('-', collect_set(goods_id)) as goods_id_set
from (
select order_id
,goods_id
from zhibo_test.`order`
-- 先对子商品 id 进行排序,再对子商品 id 进行收集和拼接,保证对比时的顺序一致
order by goods_id
) as a
group by order_id
)
,combine_goods_info as (
select concat_ws('-', collect_set(combine_goods_id)) as combine_goods_id
,goods_id_set
from (
select combine_goods_id
,concat_ws('-', collect_set(goods_id)) as goods_id_set
from (
select combine_goods_id
,goods_id
from zhibo_test.dim_combine_goods
-- 先对子商品 id 进行排序,再对子商品 id 进行收集和拼接,保证对比时的顺序一致
order by goods_id
) as a
group by combine_goods_id
) as a
group by goods_id_set
)
select a.order_id
,c.combine_goods_id
,b.goods_id
from order_info as a
join zhibo_test.`order` as b
on a.order_id = b.order_id
left join combine_goods_info as c
on a.goods_id_set = c.goods_id_set
主要思想就是将多个组合商品维表中的 goods_id_set 对应的 combine_goods_id 进行合并,变成一条,执行后的结果如下:

可以看到,所有订单信息,找到了组合商品,并且没有发生数据膨胀。
3. 注意
在实际使用中发现,如果夹杂了其他很多处理,整个 SQL 的处理莲路很长,代码中的 order by goods_id 会失效,也就是 concat_ws('-', collect_set(goods_id)) 的结果并不是理想结果,会导致关联时关联不上。
解决方案也很简单,自定义 UDF,输入值为 concat_ws('-', collect_set(goods_id)) 的结果,然后对字符串根据 - 符号拆分成数组,然后在 java 中排序,最后再通过 - 符号拼接,得到处理后的结果,最后再 join 连接,就没问题了。