fork函数详解【Linux】
fork函数详解【Linux】
fork函数的概念
调用fork函数可以在已存在的进程中创建一个子进程,此时,新进程叫做子进程,原进程叫做父进程。
#include <unistd.h>
pid_t fork(void);
其中pid_t的底层是int;

返回值::子进程中返回0,父进程返回子进程id,出错返回-1
也就是这样:
#include <iostream>
#include <unistd.h>
int main()
{
pid_t fd = fork();
if (fd == 0)
{
//this area is child
}
else if(fd > 0)
{
// this area is parent
}
else
{
// this area is error
}
return 0;
}
fork调用后的底层细节
当我们在用户空间调用了fork以后,控制会从用户空间转移到内核空间,因为fork属于系统调用,然后内核会:
- 为子进程分配新的内存块和内核数据结构。
- 以父进程为模板,将父进程的pcb和虚拟内存地址以及页表汇中的内容完整复制一份给子进程,以至于虚拟内存地址和页表以及页表和物理地址空间的映射关系,父子进程此时都是一模一样的。
- 将子进程的pcb添加到系统进程列表中。
- fork返回,开始进程调度器调度。
解释fork学习中的一些笔记和问题
- 同一个程序,每次启动运行时,分配的pid都可能不同。
- 命令行中的父进程一般是命令行解释器bash,命令行中启动的进程,都是bash的子进程。
- Linux中创建子进程有两种方式:
3.1. 在命令行行中直接启动进程。(启动进程的本质就是创建进程吗)
3.2. 通过代码来创建子进程。(一般是由父进程创建) - 只有父进程执行fork之前的代码,fork之后的代码父子进程都要执行。
- 创建子进程的原因:想让子进程协助父进程完成一些工作,这些工作是单进程完成不了的。(比如边下载边播放视频),创建子进程是为了和父进程做不一样的事。
- 为什么fork的两个返回值会给父进程返回子进程pid,给子进程返回0?
:答:因为父子进程的数量比例是 1:n , 为了使得父子进程能够一一对应,具有唯一性,且子进程主要是为了协助父进程,父进程得到了子进程的pid能够确定唯一的子进程,方便调用子进程。 - fork之后,父子进程谁先运行?
: 答:这个跟内核的调度机制有关,哪一个进程的pcb先被选择调度,哪一个进程就先执行,所以是不确定的。由各自pcb中的调度信息(时间片,优先级)和调度器算法决定,也就是有OS决定。
fork的写实拷贝
由于虚拟内存地址和页表以及页表和物理地址空间的映射关系,父子进程此时都是一模一样的。所以可以说父子继承一开始都是使用同一块地址空间。
#include <iostream>
#include <unistd.h>
#include <sys/wait.h>
int main()
{
int a = 8;
pid_t fd = fork();
if (fd == 0)
{
a = 3;
std::cout << "child: " << a << std::endl;
}
if (fd > 0)
{
std::cout << "parent: " << a << std::endl;
}
wait(NULL);
return 0;
}

看完上面这份代码,为什么明明父子进程的a是同一块地址空间的,按理来说子进程修改了a为3,父进程的a为什么还是8呢?难道是结论错误了吗?
#include <iostream>
#include <unistd.h>
#include <sys/wait.h>
int main()
{
int a = 8;
std::cout << &a << std::endl;
pid_t fd = fork();
if (fd == 0)
{
a = 3;
std::cout << "child: " << &a << std::endl;
}
if (fd > 0)
{
std::cout << "parent: " << &a << std::endl;
}
wait(NULL);
return 0;
}

通过上面这个代码也可以清楚知道父子进程的a指向的地址空间确实是同一个。
这里的原因是因为我们所看到的地址叫做虚拟内存空间,每一个进程都会有一份虚拟内存和一个页表。但是物理内存只有一个,页表中保存着虚拟内存和物理内存之间的一份映射关系。
我们可以浅显的将页表看做下图(真正页表中的字段不止三个,但是此刻这三个字段足以说明问题);
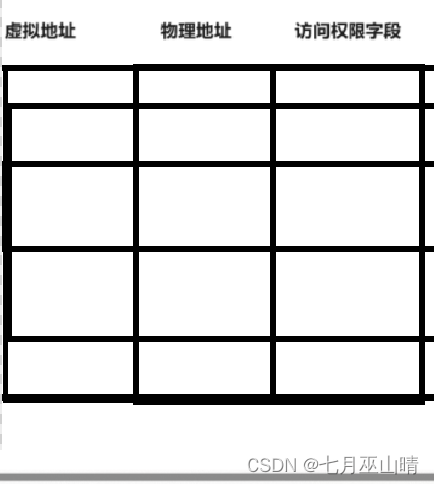
所以真实情况是:子进程的创建确实以父进程为模板将其内容拷贝到了子进程的内核数据结构中,但是当数据有所变化时,就以深拷贝的方式父子进程各自私有一份。
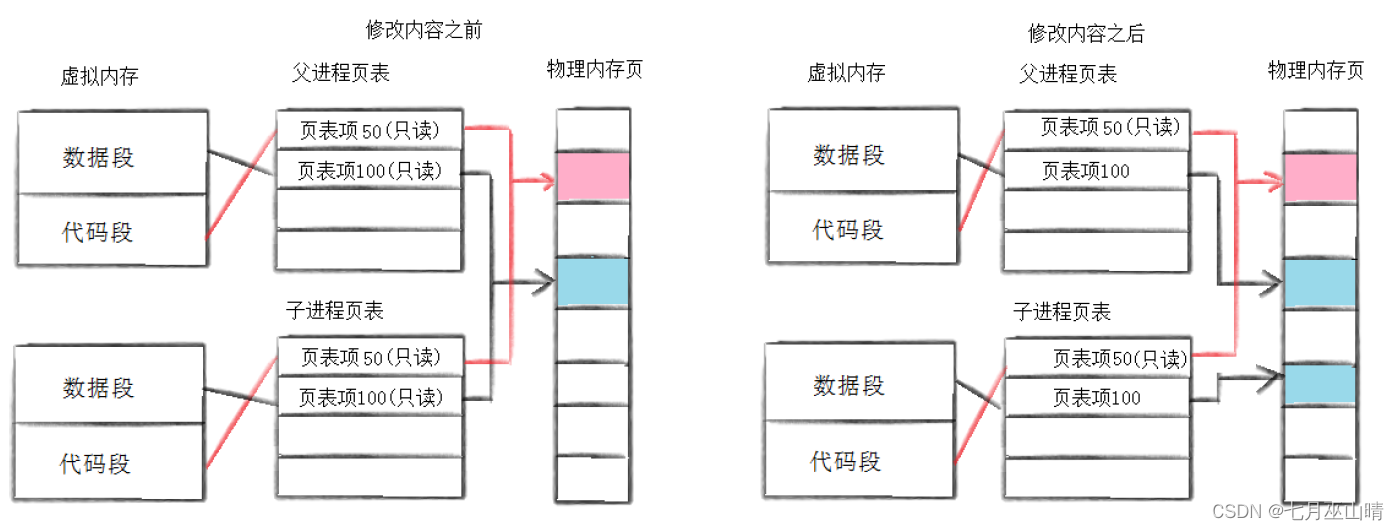
深拷贝的策略
- 父进程创建子进程的时候会先将自己页表中的访问权限字段中的读写权限改为只读,然后再创建,使得父子进程的数据都是只读。
- 当父子进程任意一方试图更改共同数据,就会触发页表权限问题,在页表映射转换时出现权限问题会有两种情况:
- 真的出错了
- 不是出错,触发深拷贝的策略机制,需要进程重新申请内存
此时显然是属于后者。
- 此时再物理内存中开辟了一段新空间,然后将更改后的数据写入到内存,页表中的物理地址也要改成新物理空间的地址。
- 因为没有更改虚拟地址,所以我们打印出来的地址会发现深拷贝之后的虚拟地址依旧没有改变。这也就解释了开头那份代码所带来的问题。
fork调用失败的原因
- 系统中有太多的进程
- 实际用户的进程数超过了限制
😄 创作不易,你的点赞和关注都是对我莫大的鼓励,再次感谢您的观看😄