iceberg学习笔记(2)—— 与Hive集成
前置知识:
1.了解hadoop基础知识,并能够搭建hadoop集群
2.了解hive基础知识
3.Iceberg学习笔记(1)—— 基础知识-CSDN博客
可以参考:
环境准备
hive和iceberg的适配关系
| Hive 版本 | 官方推荐Hive版本 | Iceberg 版本 |
| 2.x | 2.3.8 | 0.8.0-incubating – 1.1.0 |
| 3.x | 3.1.2 | 0.10.0 – 1.1.0 |
注意:
Iceberg与Hive 2和Hive 3.1.2/3的集成,支持以下特性:
- 创建表
- 删除表
- 读取表
- 插入表(INSERT into)
更多功能需要Hive 4.x(目前alpha版本)才能支持
hive与iceberg的环境搭建:
1.上传jar包到hive的路径下:
mkdir auxlib
cp iceberg-hive-runtime-1.1.0.jar /opt/module/hive/auxlib
cp libfb303-0.9.3.jar /opt/module/hive/auxlib auxlib文件夹通常用于存放一些用户自定义的jar包,比如UDF、UDAF函数等
在hive-site.xml中可以通过hive.aux.jars.path参数绑定auxlib文件夹的路径
2.修改hive-site.xml,添加配置项
<property>
<name>iceberg.engine.hive.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.aux.jars.path</name>
<value>/opt/module/apache-hive-3.1.2-bin/auxlib</value>
</property>开启iceberg支持以及绑定jar包依赖
如果hive需要使用Tez引擎,注意事项如下:
1.使用Hive版本>=3.1.2,需要TEZ版本>=0.10.1
2.在hive-site.xml中指定tez更新配置:
<property> <name>tez.mrreader.config.update.properties</name> <value>hive.io.file.readcolumn.names,hive.io.file.readcolumn.ids</value> </property>3.从Iceberg 0.11.0开始,如果Hive使用Tez引擎,需要关闭向量化执行
<property> <name>hive.vectorized.execution.enabled</name> <value>false</value> </property>有关Tez引擎:
Tez是一个由Apache开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分。在Hive中,Tez被用作其运行引擎,性能优于Hive默认的MR引擎。这主要是因为Tez可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能
有关向量化执行:
Hive的向量化执行是一种优化技术,它将查询操作应用于数据向量。传统的Hive执行方式是逐行处理数据,而向量化模式则允许一次处理多行数据,从而减少了数据处理的开销。这种模式通过将一组数据作为一个向量进行处理,利用SIMD(单指令多数据)指令集来并行执行操作,进而提高了查询的效率。然而,值得注意的是,开启向量化并不是万能的,它需要同时满足一些条件才能发挥出效果。此外,向量化查询执行在Hive 0.13.0及以后版本可用,并且默认情况下是关闭的,用户可以通过设置"
set hive.vectorized.execution"来启用。
相关配置完成后开启hadoop以及HMS服务即可
nohup /opt/module/apache-hive-3.1.2-bin/bin/hive --service metastore &
nohup /opt/module/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
/opt/module/apache-hive-3.1.2-bin/bin/beeline -u jdbc:hive2://hadoop102:10000 -n why
Hive Catalog
catalog是database的上一层抽象,翻译过来叫做“目录”
catalog的作用在于提供了远端连接的入口,对元数据进行统一的管理
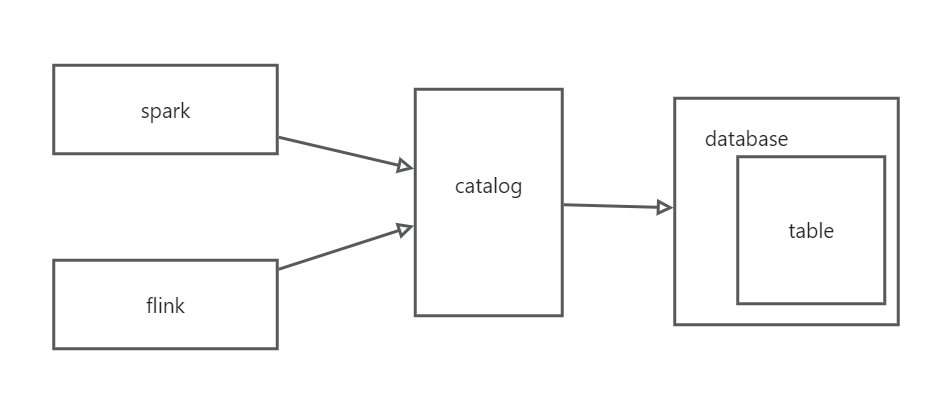
Iceberg支持多种不同的Catalog类型,例如:Hive、Hadoop、亚马逊的AWS Glue和自定义Catalog
- 没有设置iceberg.catalog,默认使用HiveCatalog
CREATE TABLE iceberg_test1 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';通过STORED BY指定创建的是iceberg表
在hive4中,可以简写为'iceberg'
- 设置了 iceberg.catalog的类型,使用指定的Catalog类型:
| 配置项 | 说明 |
| iceberg.catalog.<catalog_name>.type | Catalog的类型: hive, hadoop, 如果使用自定义Catalog,则不设置 |
| iceberg.catalog.<catalog_name>.catalog-impl | Catalog的实现类, 如果上面的type没有设置,则此参数必须设置(适用于自定义的catalog) |
| iceberg.catalog.<catalog_name>.<key> | Catalog的其他配置项 |
- 设置
iceberg.catalog=location_based_table,直接通过指定的根路径来加载Iceberg表
使用默认的catalog
CREATE TABLE iceberg_test1 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
INSERT INTO iceberg_test1 values(1);指定catalog类型
使用 HiveCatalog
首先进行相关参数的设置:
set iceberg.catalog.iceberg_hive.type=hive;
set iceberg.catalog.iceberg_hive.uri=thrift://hadoop102:9083;
set iceberg.catalog.iceberg_hive.clients=10;
set iceberg.catalog.iceberg_hive.warehouse=hdfs://hadoop102:8020/user/hive/warehouse/iceberg-hive;然后创建表并插入数据,通过TBLPROPERTIES指定catalog的类型;
CREATE TABLE iceberg_test2 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
TBLPROPERTIES('iceberg.catalog'='iceberg_hive');
INSERT INTO iceberg_test2 values(1);问题说明:
①
iceberg.catalog.iceberg_hive.type中,iceberg_hive是自定义的名称,只要和TBLPROPERTIES('iceberg.catalog'='iceberg_hive');中的对应起来就可以;②
iceberg.catalog.iceberg_hive.warehouse设置失效,但官网的示例是这样给出的,无论如何设置该参数,路径仍会按照hive-site.xml中配置的来存储但使用HadoopCatalog时有效;
使用 HadoopCatalog
设置相关参数:
set iceberg.catalog.iceberg_hadoop.type=hadoop;
set iceberg.catalog.iceberg_hadoop.warehouse=hdfs://hadoop102:8020/user/hive/warehouse/iceberg-hadoop;创建表并插入数据:
CREATE TABLE iceberg_test3 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://hadoop102:8020/user/hive/warehouse/iceberg-hadoop/default/iceberg_test3'
TBLPROPERTIES('iceberg.catalog'='iceberg_hadoop');
INSERT INTO iceberg_test3 values(1);注意:
必须设置LOCATION,且其中的路径和
iceberg.catalog.iceberg_hadoop.warehouse配置的要一致,否则会报错;
指定路径加载
如果HDFS中已经存在iceberg格式表,我们可以通过在Hive中创建Icerberg格式表指定对应的location路径映射数据
DROP TABLE IF EXISTS iceberg_test4;
CREATE EXTERNAL TABLE iceberg_test4 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://hadoop102:8020/user/hive/warehouse/iceberg-hadoop/default/iceberg_test3'
TBLPROPERTIES ('iceberg.catalog'='location_based_table');如上例,基于hdfs://hadoop102:8020/user/hive/warehouse/iceberg-hadoop/default/iceberg_test3路径创建了表iceberg_test4,这样iceberg_test3中的数据就能同步到iceberg_test4中去;
需要注意:
①两张表的表格式需要相同;
②iceberg_test4需要是外部表(EXTERNAL),否则修改iceberg_test4中的数据可能对iceberg_test3中的数据造成影响
③指定LOCATION时一定要注意指定正确的位置,因为即使路径不存在也不会报错,但数据无法同步
基本操作
创建表
创建外部表
CREATE EXTERNAL TABLE iceberg_create1 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
describe formatted iceberg_create1;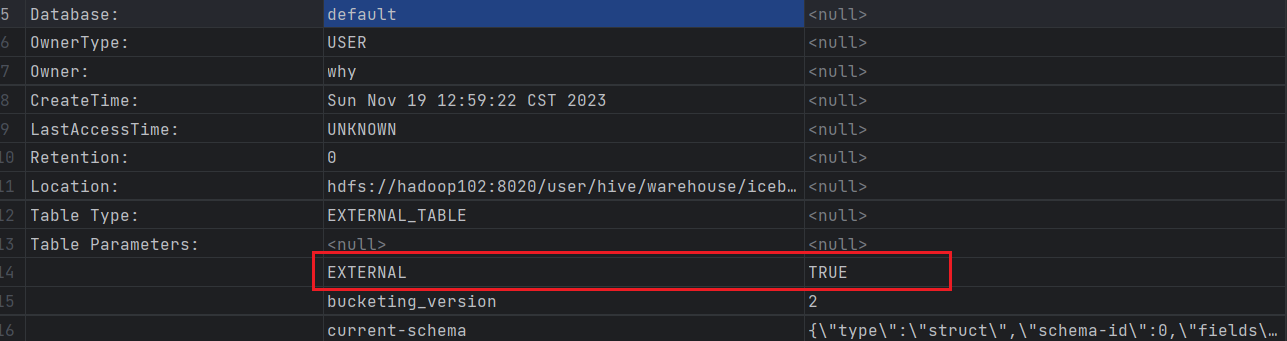
创建内部表
CREATE TABLE iceberg_create2 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
describe formatted iceberg_create2;
创建分区表
CREATE EXTERNAL TABLE iceberg_create3 (id int,name string)
PARTITIONED BY (age int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
describe formatted iceberg_create3;注意:
Hive语法创建分区表,不会在HMS中创建分区,而是将分区数据转换为Iceberg标识分区。这种情况下不能使用Iceberg的分区转换,例如:days(timestamp),如果想要使用Iceberg格式表的分区转换标识分区,需要使用Spark或者Flink引擎创建表
修改表
只支持HiveCatalog表修改表属性,Iceberg表属性和Hive表属性存储在HMS中是同步的
ALTER TABLE iceberg_create1 SET TBLPROPERTIES('external.table.purge'='FALSE');插入表
支持标准单表INSERT INTO操作
INSERT INTO iceberg_create2 VALUES (1);
INSERT INTO iceberg_create1 select * from iceberg_create2;在HIVE 3.x中,INSERT OVERWRITE虽然能执行,但其实是追加
INSERT OVERWRITE TABLE iceberg_create2 VALUES (2);查询后发现数据并没有覆盖掉:
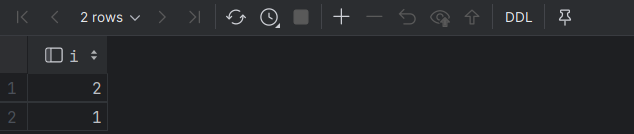
删除表
drop table <tablename>