ES的使用
1.搭建环境
1.Docker部署
1.1) 拉取镜像
docker pull elasticsearch:7.4.0
1.2) 创建容器
docker run -id --name elasticsearch -d --restart=always -p 9200:9200 -p 9300:9300 -v /usr/share/elasticsearch/plugins:/usr/share/elasticsearch/plugins -e "discovery.type=single-node" elasticsearch:7.4.0
1.3) 配置中文分词器 ik
因为在创建elasticsearch容器的时候,映射了目录,所以可以在宿主机上进行配置ik中文分词器
在去选择ik分词器的时候,需要与elasticsearch的版本好对应上
把资料中的elasticsearch-analysis-ik-7.4.0.zip上传到服务器上,放到对应目录(plugins)解压
#切换目录
cd /usr/share/elasticsearch/plugins
#新建目录
mkdir analysis-ik
cd analysis-ik
#root根目录中拷贝文件
mv elasticsearch-analysis-ik-7.4.0.zip /usr/share/elasticsearch/plugins/analysis-ik
#解压文件
cd /usr/share/elasticsearch/plugins/analysis-ik
unzip elasticsearch-analysis-ik-7.4.0.zip
1.4) 使用postman测试
192.168.200.130:9200/_analyze post请求
{"analyzer":"ik_max_word",
"text":"欢迎使用ES"}
2.创建索引
2.1 确定索引字段
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aCruPJK2-1689144977434)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230712135950421.png)]](https://images2.imgbox.com/d5/9f/zLPFMwLI_o.png)
2.2 那些需分词
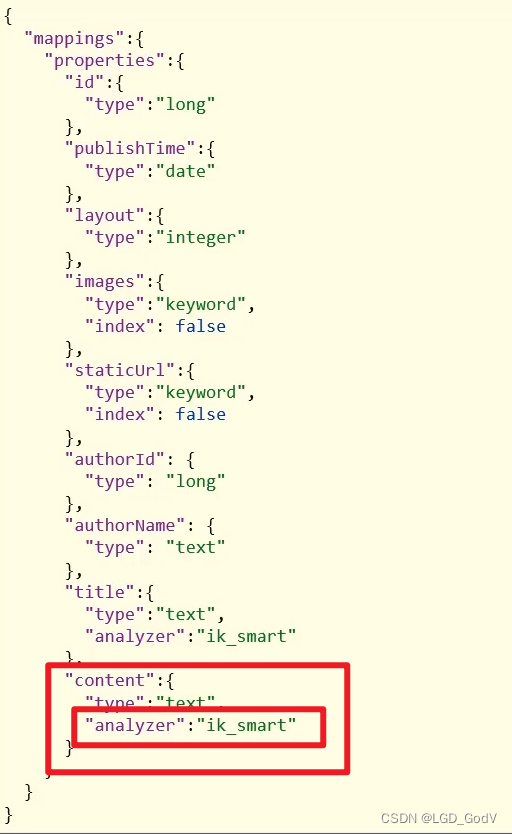
{
"mappings":{
"properties":{
"id":{
"type":"long",
"copy_to":"all"
},
"publishTime":{
"type":"date"
},
"layout":{
"type":"integer"
},
"all":{
"type":"text",
"analyzer":"ik_smart"
},
"images":{
"type":"keyword",
"index": false
},
"staticUrl":{
"type":"keyword",
"index": false
},
"location":{
"type": "geo_point"
},
"authorId": {
"type": "long"
},
"authorName": {
"type": "text"
},
"title":{
"type":"text",
"analyzer":"ik_smart"
},
"content":{
"type":"text",
"analyzer":"ik_smart"
}
}
}
}
几个特殊字段说明:
- location:地理坐标,里面包含精度、纬度
- all:一个组合字段,其目的是将多字段的值 利用copy_to合并,提供给用户搜索
地理坐标说明:

copy_to说明:

2.3其他的操作
使用postman添加映射
put请求 : http://192.168.200.130:9200/app_info_article
GET请求查询映射:http://192.168.200.130:9200/app_info_article
DELETE请求,删除索引及映射:http://192.168.200.130:9200/app_info_article
GET请求,查询所有文档:http://192.168.200.130:9200/app_info_article/_search
3.DSL语法
1.mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
2.索引库操作
2.1 新增索引库
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}
2.2 查询索引库
GET /索引库名
2.3 修改索引库
//只能新增 不能修改
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
2.4 删除索引库
DELETE /索引库名
3.文档操作
3.1.新增文档
语法:
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}
3.2.查询文档
根据rest风格,新增是post,查询应该是get,不过查询一般都需要条件,这里我们把文档id带上。
语法:
GET /{索引库名称}/_doc/{id}
通过kibana查看数据:
GET /heima/_doc/1
3.3.删除文档
删除使用DELETE请求,同样,需要根据id进行删除:
语法:
DELETE /{索引库名}/_doc/id值
示例:
# 根据id删除数据
DELETE /heima/_doc/1
修改有两种方式:
- 全量修改:直接覆盖原来的文档
- 增量修改:修改文档中的部分字段
3.4 修改文档
3.4.1.全量修改
全量修改是覆盖原来的文档,其本质是:
- 根据指定的id删除文档
- 新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
语法:
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
3.4.2.增量修改
增量修改是只修改指定id匹配的文档中的部分字段。
语法:
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}