Python数据分析之豆瓣影片TOP250爬取与分析
豆瓣影片TOP250爬取与分析
我会把每次在网络上做的爬虫和数据分析都发上来,至少每周一次,这既是为了督促自己,也是希望能把自己遇到的问题及解决方法和大家分享。
爬取网页
这次爬虫使用的是pyquery和requests,requests主要是用来获取图片的字节信息的,没在pyquery中找到,知道的朋友也可以说一下,大家一起进步~!
因为豆瓣电影中比较友好,所以我只设置了一个伪装浏览器的headers就开始爬取了,很顺畅地获取到了网页信息。
接下来是解析网页了,因为影片信息都在单独
- 中,所以一次获取一个页面所有影片的
- ,接下来再进行遍历,把每部影片中的信息提取出来。
-
def get_html(url): # 获取页面 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36" } # 构建请求头 doc = pq(url, headers=headers) # 请求页面,获取返回url的html return doc def parse_html(doc): # 解析页面 li_list = doc(".article .grid_view").find("li") # 获取影片内容所在区域 for item in li_list.items(): # 对同一页中每部影片遍历,获取每部影片相关内容 try: movie_poster_src = item(".item .pic a").find("img").attr("src") # 获取海报的资源地址 movie_poster_b = requests.get(movie_poster_src).content # 获取海报,并将图片转为字节 movie_num = item(".item .pic em").text() # 获取影片排行的文本值 movie_url = item(".item .info .hd a").attr("href") # 获取影片url地址 movie_name_list = item(".item .info .hd .title").text().split("/") # 获取影片名称列表 movie_name = "/".join(clear_strip(movie_name_list)) # 对影片名称去除左右两边空格并以/分开 movie_score = item(".item .info .bd .star .rating_num").text() # 获取影片评分 movie_intro = item(".item .info .bd .quote span").text() # 获取影片简介 movie_info = item(".item .info .bd p").text() # 获取影片中信息集合,利用正则一次获取 movie_director = "".join(clear_strip(re.findall(r"导演:(.*?)\xa0", movie_info))) # 去除左右空格并获取导演信息 movie_star = "".join(re.findall(r"主演:(.*?)\n", movie_info)) # 去除左右空格获取主演信息 movie_year = "".join(re.findall(r"(\d{4}.*?)\xa0/\xa0", movie_info)) # 获取上映年份信息 movie_country = "/".join(re.findall(r"\d{4}.*?\xa0/\xa0(.*?)\xa0/\xa0", movie_info)[0].split()) # 去除空格获取拍摄国家信息 movie_type = "/".join(re.findall(r'\d{4}.*?\xa0/\xa0.*?\xa0/\xa0(.*?)$', movie_info)[0].split()[:-1]) # 去除空格获取拍摄电影类型信息 movie_comment_count = item(".item .info .bd .star .rating_num").siblings().text().strip() # 获取评价人数 yield [movie_num, movie_name, movie_director, movie_star, movie_year, movie_country, movie_type, movie_score, movie_comment_count, movie_intro, movie_url, movie_poster_b] # 每次循环以列表形式返回值 except Exception as e: print("错误:", repr(e)) # 若出现错误,打印错误信息 continue else: print("此页数据爬取成功!") # 每爬取成功一页打印一次忘记说了,我爬取时是通过定义不同功能的函数,最终通过判断是否在当前文件下执行,即“if __name__ = “__main__””来执行的,并没有封装到一个类里。
网页整体分布很规律,找到相应位置即可,只有在导演主演上映时间那一块是一堆,利用
\xa0加正则可以很轻松把导演那一堆信息提取出来。其中\xa0为HTML中的 。接下来是一个翻页操作,我直接通过多点几页分析每页网址规律写出来每页网址,然后调用获取网页和解析网页两个函数就行。
最后我把获取的数据保存为csv格式。
数据分析
对国家参与制作影片排行分析
countries = data["movie_country"].str.split("/").apply(pd.Series) # 获取所有国家,并将一行中含有多个国家的多个国家分开 country = countries.apply(pd.value_counts).fillna(0) # 对国家进行计数并填充空值 country.columns = ["area1", "area2", "area3", "area4", "area5", "area6"] # 修改列名 country["area_count"] = country.sum(axis=1) country.sort_values("area_count", ascending=False, inplace=True) # 以总和列降序排序 # print(country) mp.subplot(121) country.area_count.head(10).plot(kind="bar", color="orangered") # 绘制前10名数据条形图 mp.title("国家参与制作影片数排行TOP10") mp.xlabel("地区名", fontsize=12) # 设置x轴标签 mp.ylabel("频次", fontsize=12) mp.yticks(range(0, 180, 20), [0, 20, 40, 60, 80, 100, 120, 140, 160]) # 设置y轴坐标 mp.xticks(range(10), country.head(10).index, rotation=45) # 设置x轴坐标,并让x轴坐标标签旋转45度 # axes[0, 0].xaxis.set_major_locator(10) for x, y in zip(range(10), country.area_count.head(10)): mp.text(x, y, "%d" % y, ha="center", va="bottom") # 为每个条形图增加文本注释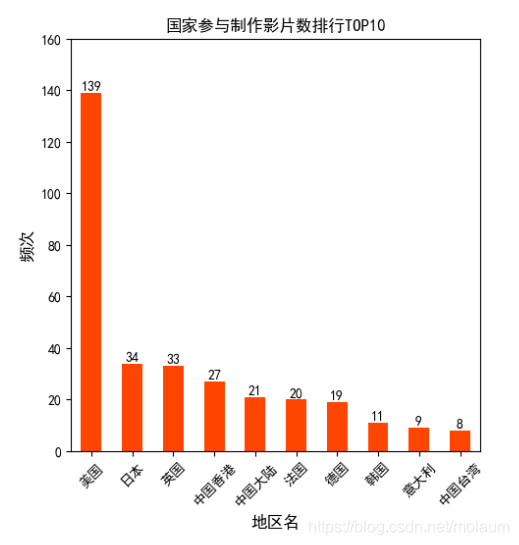
因为数据比较多,所以只选择前10来绘制条形图。电影类型前10
代码和国家差不多,其实doubanTOP250中基本所有分析都是一样的格式,没多大差别。
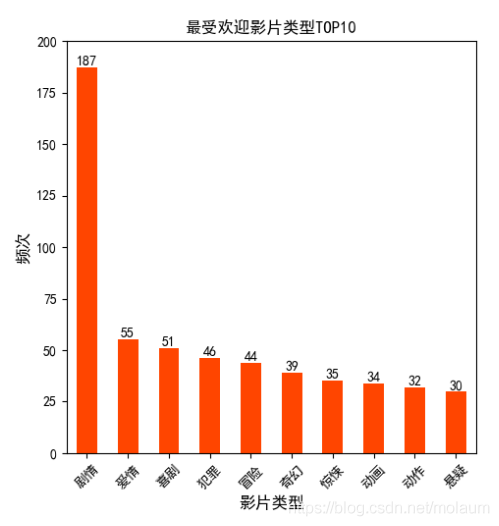
还有词云图。

词云图代码如下,使用的是最基础设置,并用了jiebe分词。text_type = data["movie_type"].str.split("/").tolist() # 将获取的电影类型数据做split分割后转为列表 text = "".join(jieba.cut(str(text_type).replace("'", ""), cut_all=False)) # 以空格连接列表并用jieba分词 # print(text) wc_type = WordCloud(background_color="white", font_path="STXIHEI.TTF", width=900, height=600).generate(text) # 设置词云图 mp.figure("词云图分析") # 新建一图 mp.subplot(121) mp.imshow(wc_type, interpolation="bilinear") # 绘制热图函数 mp.title("电影类型词云图分析") mp.axis("off")导演与主演排行前10
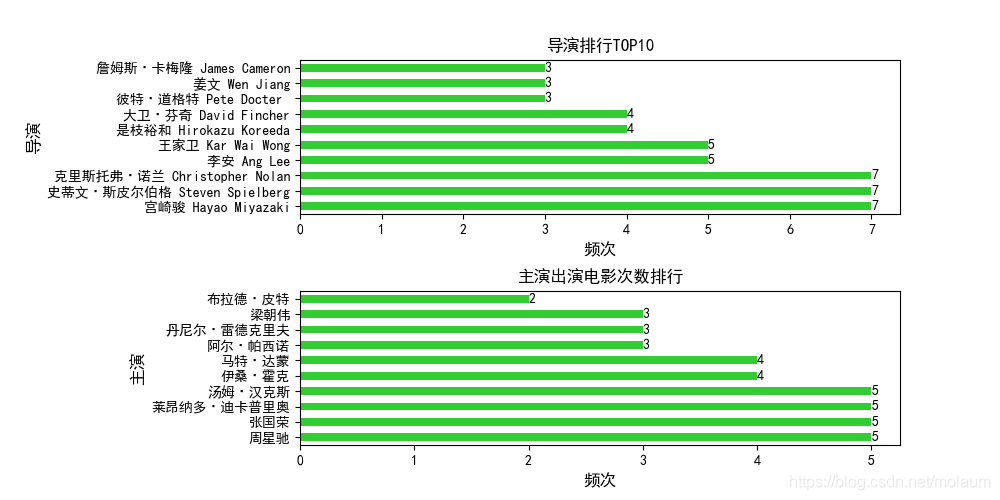
上映时间、排名、评价人数、评分的分析
评价人数获取到后还有“人评价”,因此得先把它去掉转为数值型,才能进行分析。使用
strip("人评价")就可以很方便地去掉,在这儿我必须强调一点,熟悉python中最基础的函数,有时候的确事半功倍,像我之前一直以为strip()只能去除左右空格,处理这儿的时候可费了一些功夫。data["movie_comment_count"] = data["movie_comment_count"].str.strip("人评价").astype(int) # print(data) num_comment_corr = data["movie_num"].corr(data["movie_comment_count"]) ax5 = mp.subplot(gs[3, :]) ax5.scatter(data["movie_num"], data["movie_comment_count"], s=5, label="%.2f" % num_comment_corr) ax5.set_title("电影排名与评价人数关系") ax5.xaxis.set_major_locator(ticker.MultipleLocator(5)) ax5.set_xlim(0, 255) ax5.tick_params(rotation=45) ax5.set_xlabel("电影排名", fontsize=12) ax5.set_ylabel("评价人数", fontsize=12) ax5.set_yticklabels(()) ax5.legend()这里用了栅格布局器,因为我把涉及到数值的图都放在了一起。就在下面
↓↓↓,个人感觉看得很舒畅~~
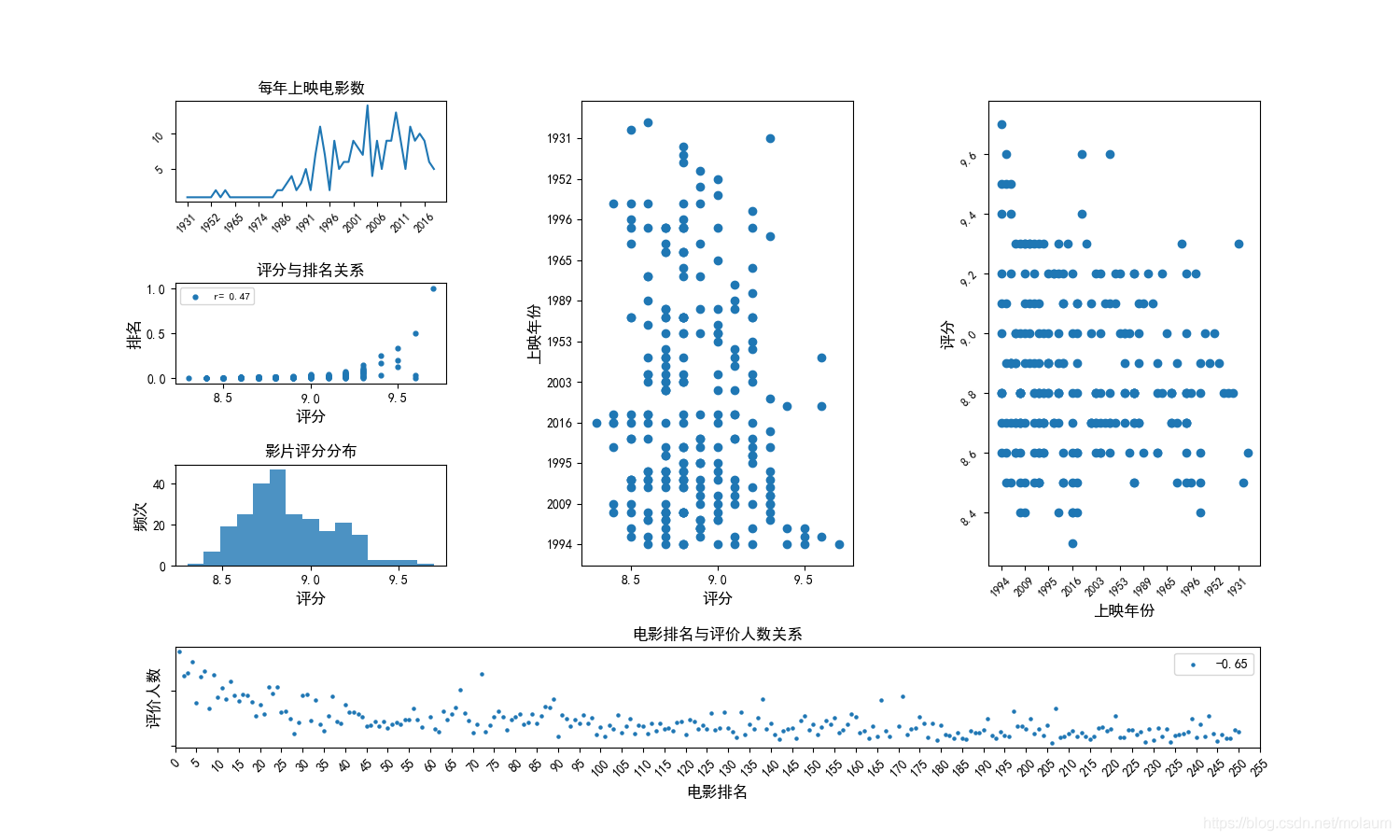
重点说一下右边两个散点图, 因为想给它们俩设置同一标题,网上搜了好久也没想要的,我就按我自己的来了,效果还不错。新设置一坐标,位置找好后,把这个坐标的背景、脊柱线颜色都设为
"none",记住是"none"不是None# h. 评分与上映年份关系 data.drop(index=[58, 168], axis=0, inplace=True) ax2 = mp.subplot(gs[:3, 1]) # 在第一列绘制占三行高的图 ax2.scatter(data["movie_score"], data["movie_year"]) # 绘制散点图 ax2.yaxis.set_major_locator(ticker.MultipleLocator(5)) ax2.set_xlabel("评分", fontsize=12) ax2.set_ylabel("上映年份", fontsize=12) ax3 = mp.subplot(gs[:3, 2]) # 在第二列绘制占三行高的图 ax3.scatter(data["movie_year"], data["movie_score"]) ax3.xaxis.set_major_locator(ticker.MultipleLocator(5)) ax3.tick_params(labelsize=9, rotation=45) ax3.set_xlabel("上映年份", fontsize=12) ax3.set_ylabel("评分", fontsize=12) ax4 = mp.axes([0.4, 0.1, 0.5, 0.8], zorder=0, facecolor="w", alpha=1) # 目的是为了给两个散点图设置统一标题 ax4.set_title("评分与上映年份关系") ax4.set_xticks(()) ax4.set_yticks(()) ax4.patch.set_facecolor("none") # 设置坐标系无背景颜色 # ax4.patch.set_alpha(0) ax = mp.gca() # 获取当前绘图区域 ax.spines["right"].set_color("none") ax.spines["left"].set_color("none") ax.spines["top"].set_color("none") ax.spines["bottom"].set_color("none") # 将坐标系四条“脊柱”颜色设为无ok,以上就是我对豆瓣影片250的分析,虽然关于豆瓣250分析可以说是烂大街了,但我觉着每个人分析的时候总会有不一样的想法。我在我的公众号里也有这篇分析,里面有一些我对这些数据的个人分析,感兴趣的朋友可以看一下!多谢观看!!
