calcite 启发式优化器(HepPlanner)原理与自定义优化规则实现
文章目录
HepPlanner
HepPlanner是基于RBO 模型的一种优化器,单纯基于规则,对关系代数进行优化
思考🤔
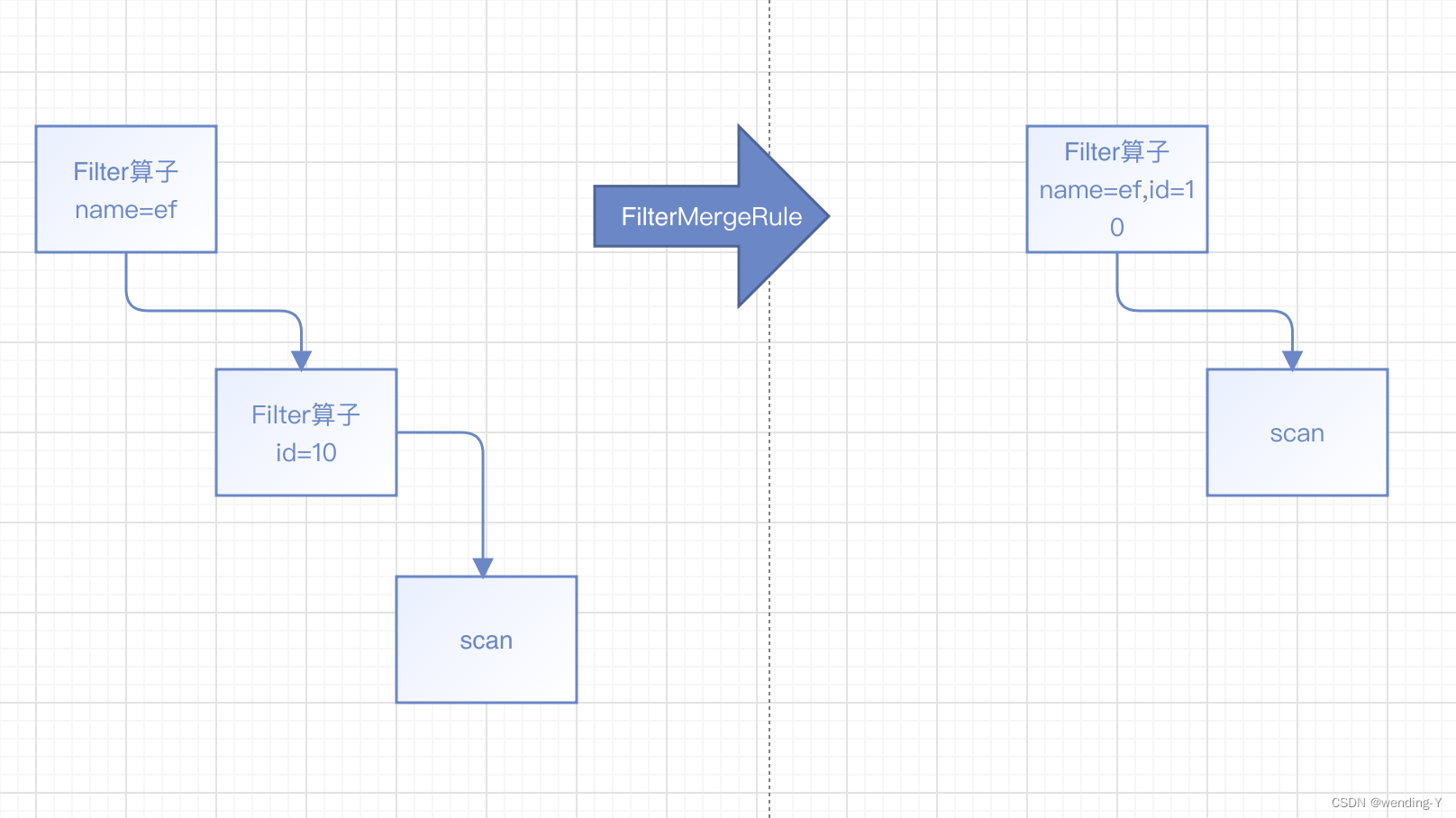
AST 转换为RelNode,其实是一个树形结构,再由RelNode 生成执行计划,给人的第一感觉,如果要加速查询的话,也就是去优化这个树结构的执行顺序,很直接就会想到在树中根据规则去优化,这里的规则要表明,目标要优化哪种结构的子树。以下图2为例,对于两个连续的Filter 所表示的子树可以进行优化,合并为一个。
流程
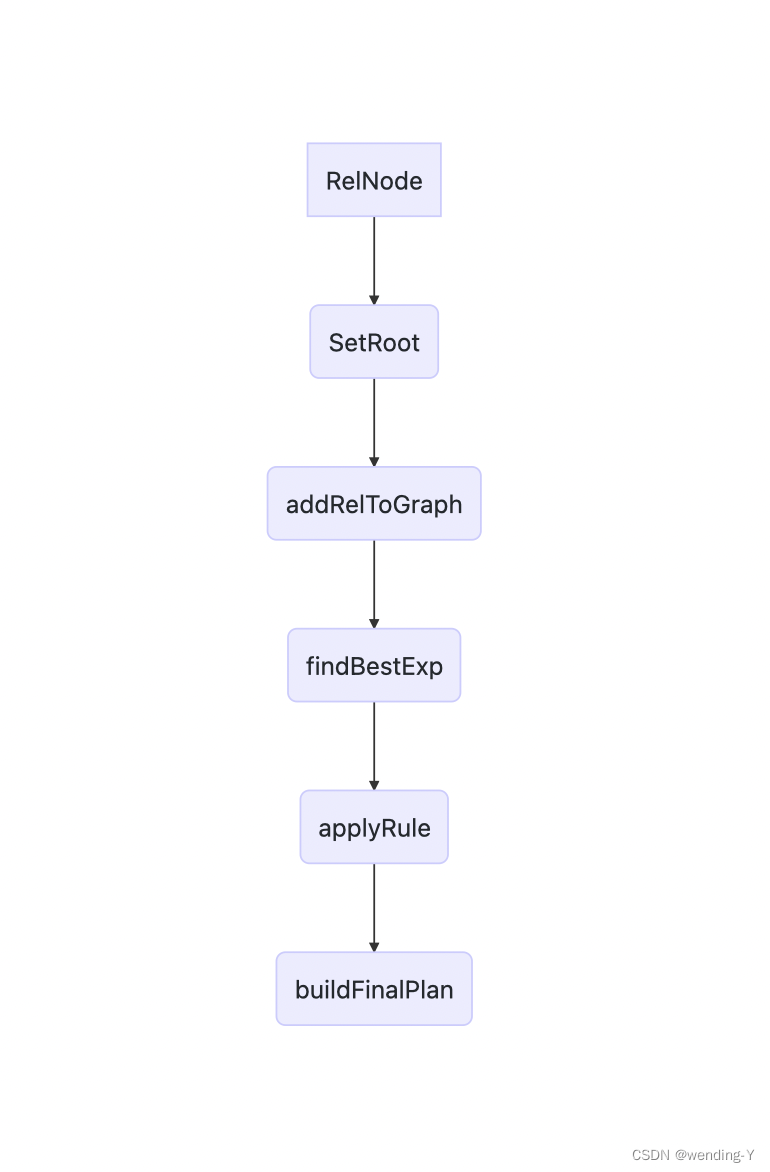
规则
规则定义
以FilterMergeRule 规则为例,此规则是把多个Filter 进行合并
定义匹配
从代码中能看出来匹配规则是filterClass 的输入是filterClass,相当于连续两个过滤条件
实现转换方法
转换做法,把底下一个Filter的输入 压入栈中,再把两个Filter一起压入栈中
@Override public void onMatch(RelOptRuleCall call) {
final Filter topFilter = call.rel(0);
final Filter bottomFilter = call.rel(1);
//示例如何重写计划
final RelBuilder relBuilder = call.builder();
relBuilder.push(bottomFilter.getInput())
.filter(bottomFilter.getCondition(), topFilter.getCondition());
call.transformTo(relBuilder.build());
}
/** Rule configuration. */
@Value.Immutable
public interface Config extends RelRule.Config {
Config DEFAULT = ImmutableFilterMergeRule.Config.of()
.withOperandFor(Filter.class);
@Override default FilterMergeRule toRule() {
return new FilterMergeRule(this);
}
/** Defines an operand tree for the given classes. */
default Config withOperandFor(Class<? extends Filter> filterClass) {
//匹配规则
return withOperandSupplier(b0 ->
b0.operand(filterClass).oneInput(b1 ->
b1.operand(filterClass).anyInputs()))
.as(Config.class);
}
}
核心代码分析
生成有向无环图
private HepRelVertex addRelToGraph(
RelNode rel) {
// Check if a transformation already produced a reference
// to an existing vertex.
if (graph.vertexSet().contains(rel)) {
return (HepRelVertex) rel;
}
// Recursively add children, replacing this rel's inputs
// with corresponding child vertices.
final List<RelNode> inputs = rel.getInputs();
final List<RelNode> newInputs = new ArrayList<>();
for (RelNode input1 : inputs) {
HepRelVertex childVertex = addRelToGraph(input1);
newInputs.add(childVertex);
}
// 后面省略
}
findBestExp
private void applyRules(HepProgram.State programState,
Collection<RelOptRule> rules, boolean forceConversions) {
final HepInstruction.EndGroup.State group = programState.group;
if (group != null) {
checkArgument(group.collecting);
Set<RelOptRule> ruleSet = requireNonNull(group.ruleSet, "group.ruleSet");
ruleSet.addAll(rules);
return;
}
LOGGER.trace("Applying rule set {}", rules);
final boolean fullRestartAfterTransformation =
programState.matchOrder != HepMatchOrder.ARBITRARY
&& programState.matchOrder != HepMatchOrder.DEPTH_FIRST;
int nMatches = 0;
boolean fixedPoint;
do {
// 遍历每一个图结点
Iterator<HepRelVertex> iter =
getGraphIterator(programState, requireNonNull(root, "root"));
fixedPoint = true;
while (iter.hasNext()) {
HepRelVertex vertex = iter.next();
for (RelOptRule rule : rules) {
// 遍历每一个规则
HepRelVertex newVertex =
applyRule(rule, vertex, forceConversions);
if (newVertex == null || newVertex == vertex) {
continue;
}
++nMatches;
if (nMatches >= programState.matchLimit) {
return;
}
if (fullRestartAfterTransformation) {
iter = getGraphIterator(programState, requireNonNull(root, "root"));
} else {
// To the extent possible, pick up where we left
// off; have to create a new iterator because old
// one was invalidated by transformation.
iter = getGraphIterator(programState, newVertex);
if (programState.matchOrder == HepMatchOrder.DEPTH_FIRST) {
nMatches =
depthFirstApply(programState, iter, rules, forceConversions, nMatches);
if (nMatches >= programState.matchLimit) {
return;
}
}
// Remember to go around again since we're
// skipping some stuff.
fixedPoint = false;
}
break;
}
}
} while (!fixedPoint);
}
应用规则
private @Nullable HepRelVertex applyRule(
RelOptRule rule,
HepRelVertex vertex,
boolean forceConversions) {
if (!graph.vertexSet().contains(vertex)) {
return null;
}
RelTrait parentTrait = null;
List<RelNode> parents = null;
if (rule instanceof ConverterRule) {
// Guaranteed converter rules require special casing to make sure
// they only fire where actually needed, otherwise they tend to
// fire to infinity and beyond.
ConverterRule converterRule = (ConverterRule) rule;
if (converterRule.isGuaranteed() || !forceConversions) {
if (!doesConverterApply(converterRule, vertex)) {
return null;
}
parentTrait = converterRule.getOutTrait();
}
} else if (rule instanceof CommonRelSubExprRule) {
// Only fire CommonRelSubExprRules if the vertex is a common
// subexpression.
List<HepRelVertex> parentVertices = getVertexParents(vertex);
if (parentVertices.size() < 2) {
return null;
}
parents = new ArrayList<>();
for (HepRelVertex pVertex : parentVertices) {
parents.add(pVertex.getCurrentRel());
}
}
final List<RelNode> bindings = new ArrayList<>();
final Map<RelNode, List<RelNode>> nodeChildren = new HashMap<>();
boolean match =
matchOperands(
rule.getOperand(),
vertex.getCurrentRel(),
bindings,
nodeChildren);
if (!match) {
return null;
}
HepRuleCall call =
new HepRuleCall(
this,
rule.getOperand(),
bindings.toArray(new RelNode[0]),
nodeChildren,
parents);
// Allow the rule to apply its own side-conditions.
if (!rule.matches(call)) {
return null;
}
//前面主要判断有没有规则能匹配上,根据规则里定义的节点关系
//应用规则进行转换
fireRule(call);
if (!call.getResults().isEmpty()) {
return applyTransformationResults(
vertex,
call,
parentTrait);
}
return null;
}
示例
前面是通过一种通用的方式来进行规则转换,下面给出了一种直接转换关系的示例(FilterMergeRule规则),可以加深对整个流程的理解。
示例1(FilterMergeRule 规则)
代码直接转换
RelBuilder builder = RelBuilder.create(config().build());
RelNode root = builder.scan("test_user")
.filter(builder.equals(builder.field(0), builder.literal(10)))
.filter(builder.equals(builder.field(1), builder.literal("ef")))
.build();
System.out.println("优化前\n" + RelOptUtil.toString(root));
/**
* 通过自己的代码改写逻辑计划
*/
Filter topFilter= (Filter) root;
Filter bottomFilter=(Filter) root.getInput(0);
RelNode build = builder.push(bottomFilter.getInput())
.filter(bottomFilter.getCondition(), topFilter.getCondition()).build();
System.out.println("优化后\n" + RelOptUtil.toString(build));
输出
优化前
LogicalFilter(condition=[=($1, 'ef')])
LogicalFilter(condition=[=($0, 10)])
LogicalTableScan(table=[[test_user]])
优化后
LogicalFilter(condition=[AND(=($0, 10), =($1, 'ef'))])
LogicalTableScan(table=[[test_user]])
示例2(FILTER_INTO_JOIN规则)
这是一个经典的谓词下推的例子,把后面的where 条件,下推到查询数据层面,用图可以表示为
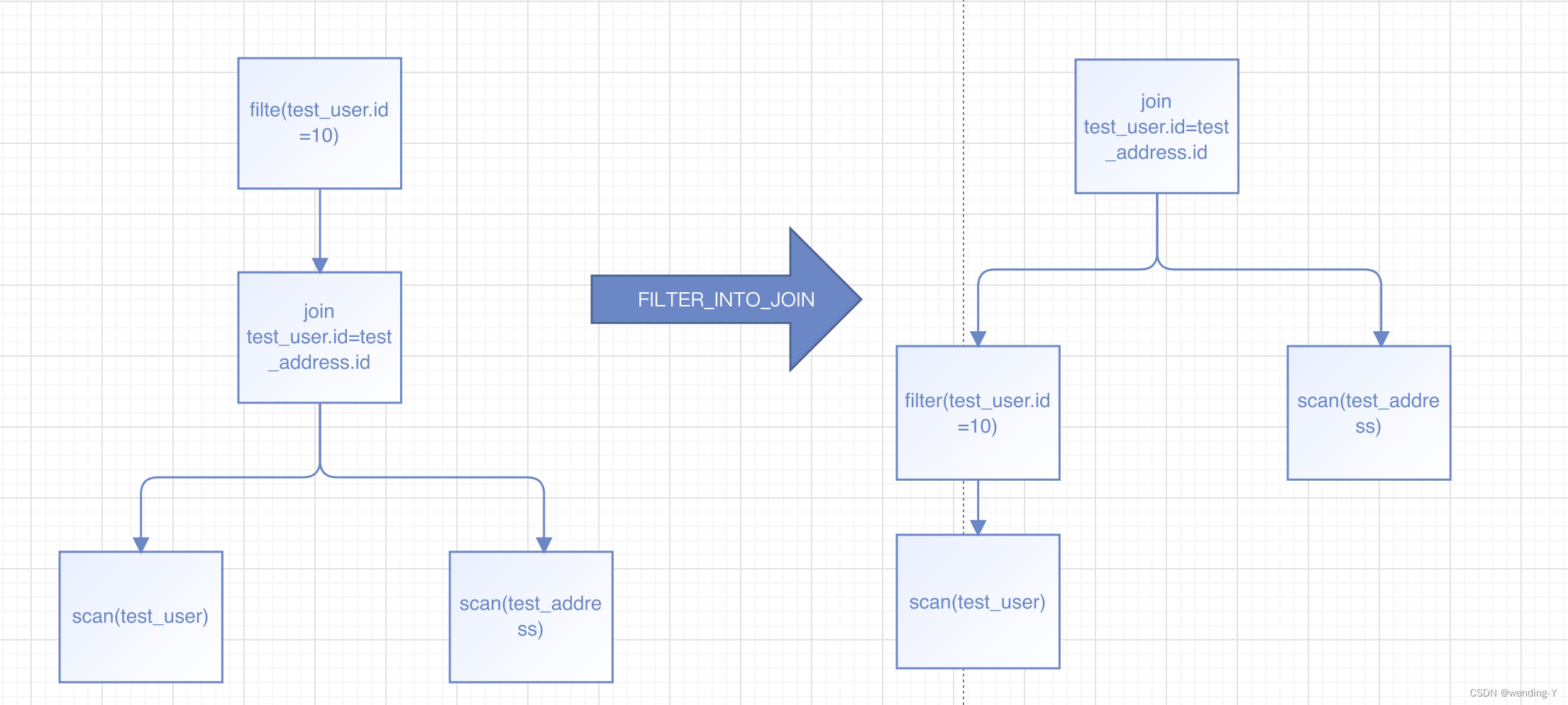
代码直接转换
RelBuilder builder = RelBuilder.create(config().build());
RelNode root = builder.scan("test_user")
.scan("test_address").join(JoinRelType.INNER, builder.field("id"))
.filter(builder.equals(builder.field("id"), builder.literal(10)))
.build();
System.out.println("优化前\n" + RelOptUtil.toString(root));
LogicalFilter filter = (LogicalFilter) root;
LogicalJoin join = (LogicalJoin) root.getInput(0);
/**
* 直接根据规则进行转换
*/
RelNode build = builder.push(join.getLeft())
.filter(filter.getCondition())
.push(join.getRight())
.join(join.getJoinType(), join.getCondition())
.build();
System.out.println("优化后\n" + RelOptUtil.toString(build));
输出
优化前
LogicalFilter(condition=[=($0, 10)])
LogicalJoin(condition=[$0], joinType=[inner])
LogicalTableScan(table=[[test_user]])
LogicalTableScan(table=[[test_address]])
优化后
LogicalJoin(condition=[$0], joinType=[inner])
LogicalFilter(condition=[=($0, 10)])
LogicalTableScan(table=[[test_user]])
LogicalTableScan(table=[[test_address]])
总结
HepPlanner 模型直接基于规则来对关系代数进行优化,没有考虑到实现的数据量对计划的影响,而且也容易受规则顺序的影响,实际最后的计划可能不是最优的。后面是介绍基于成本CBO的优化器VolcanoPlanner