爬虫实战案例
前言:
实战携程案例,也是一个学习总结
目标:
全国景区名
1.数据分析
目标网站pc段实在不好分析,于是想到了手机端
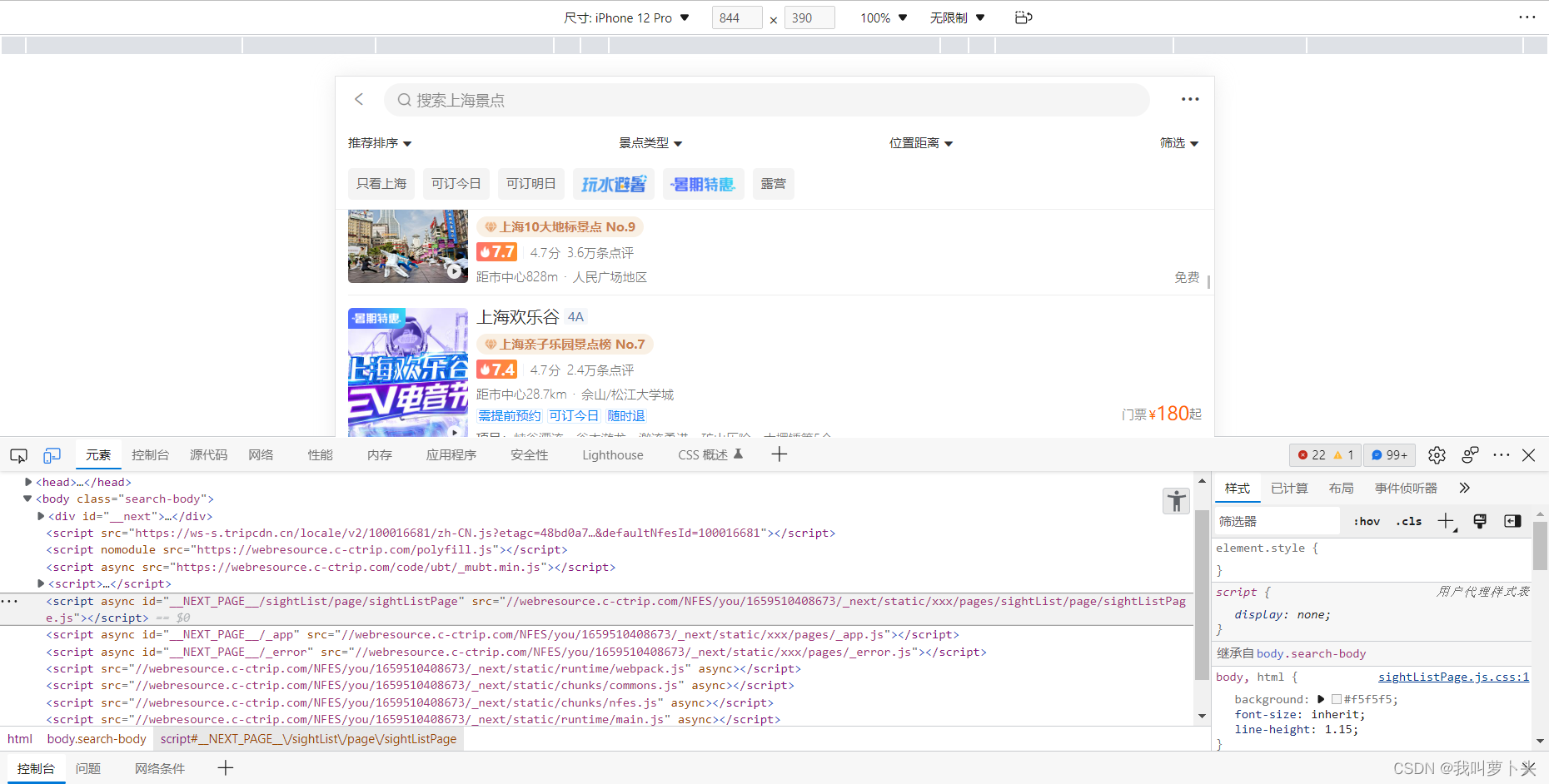
目标网站异步加载,目标数据存放在名为getAttractioList?*****下

分析一遍后发现一个头疼的事,下一页的token参数在上一页的响应数据里,这里后面代码要注意一下
因为目标要求是全国景区数据,这里只是上海,通过分析负载数据,得知count是每页的数据条,districtId是城市Id,上海就是2,北京是1

通过对响应数据的分析,这里用xpath解析最方便,在postman分析一段时间后也是将初步数据拿下来了
代码块
self.jq_payload ={
"index": 1,
"count": 20,
"sortType": 1,
"isShowAggregation": True,
"districtId": 2,
"scene": "DISTRICT",
"pageId": "214062",
"traceId": "63675663-049d-d442-3189-93e543806482",
"extension": [
{
"name": "osVersion",
"value": "13.2.3"
},
{
"name": "deviceType",
"value": "ios"
}
],
"filter": {
"filterItems": []
},
"crnVersion": "2020-09-01 22:00:45",
"isInitialState": True,
"head": {
"cid": "09031138417081694673",
"ctok": "",
"cver": "1.0",
"lang": "01",
"sid": "8888",
"syscode": "09",
"xsid": "",
"extension": []
}
}
self.jq_headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6,pl;q=0.5',
'Connection': 'keep-alive',
'Cookie': 'GUID=09031138417081694673; nfes_isSupportWebP=1; _bfaStatusPVSend=1; _RGUID=e8d913f6-e1e1-4b35-a53d-45bb72e4f277; _RDG=288799a623152421103541a50c6b033c50; _RSG=riKuXR_4PZEt9FvojRHzKA; MKT_CKID=1658192357207.a68d9.kssa; appFloatCnt=1; _ga=GA1.2.1863916334.1658192399; ibu_h5_lang=en; ibu_h5_local=en-us; _RF1=36.63.50.106; ibulanguage=CN; ibulocale=zh_cn; cookiePricesDisplayed=CNY; MKT_CKID_LMT=1659943689861; _gcl_au=1.1.1499402294.1659943691; Session=smartlinkcode=U130727&smartlinklanguage=zh&SmartLinkKeyWord=&SmartLinkQuary=&SmartLinkHost=; _jzqco=%7C%7C%7C%7C1659943690175%7C1.107574341.1658192357204.1659943689865.1659943699647.1659943689865.1659943699647.0.0.0.6.6; __zpspc=9.3.1659943689.1659943699.2%233%7Ccn.bing.com%7C%7C%7C%7C%23; _bfs=1.2; _bfi=p1%3D102001%26p2%3D102001%26v1%3D37%26v2%3D36; _bfaStatus=success; MKT_Pagesource=H5; _gid=GA1.2.199342908.1659943769; _gat=1; mktDpLinkSource=ullink; _pd=%7B%22r%22%3A14%2C%22d%22%3A293%2C%22_d%22%3A279%2C%22p%22%3A293%2C%22_p%22%3A0%2C%22o%22%3A295%2C%22_o%22%3A2%2C%22s%22%3A296%2C%22_s%22%3A1%7D; _bfa=1.1652697082838.1x1gqg.1.1659856911096.1659943805593.4.41.214062; _ubtstatus=%7B%22vid%22%3A%221652697082838.1x1gqg%22%2C%22sid%22%3A4%2C%22pvid%22%3A41%2C%22pid%22%3A214062%7D; Union=OUID=&AllianceID=4902&SID=353701&SourceID=&AppID=&OpenID=&exmktID=&createtime=1659943806&Expires=1660548605624; MKT_OrderClick=ASID=4902353701&AID=4902&CSID=353701&OUID=&CT=1659943805625&CURL=https%3A%2F%2Fm.ctrip.com%2Fwebapp%2Fyou%2Fgspoi%2Fsight%2F2.html%3Fseo%3D0%26allianceid%3D4902%26sid%3D353701%26isHideNavBar%3DYES%26from%3Dhttps%253A%252F%252Fm.ctrip.com%252Fwebapp%252Fyou%252Fgsdestination%252Fplace%252F2.html%253Fseo%253D0%2526ishideheader%253Dtrue%2526secondwakeup%253Dtrue%2526dpclickjump%253Dtrue%2526allianceid%253D4902%2526sid%253D353701%2526sourceid%253D55551831%2526from%253Dhttps%25253A%25252F%25252Fm.ctrip.com%25252Fhtml5%25252F&VAL={"h5_vid":"1652697082838.1x1gqg"}',
'Origin': 'https://m.ctrip.com',
'Referer': 'https://m.ctrip.com/webapp/you/gspoi/sight/2.html?seo=0&allianceid=4902&sid=353701&isHideNavBar=YES&from=https%3A%2F%2Fm.ctrip.com%2Fwebapp%2Fyou%2Fgsdestination%2Fplace%2F2.html%3Fseo%3D0%26ishideheader%3Dtrue%26secondwakeup%3Dtrue%26dpclickjump%3Dtrue%26allianceid%3D4902%26sid%3D353701%26sourceid%3D55551831%26from%3Dhttps%253A%252F%252Fm.ctrip.com%252Fhtml5%252F',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1 Edg/104.0.5112.81',
'content-type': 'application/json',
'cookieOrigin': 'https://m.ctrip.com'
} def get_jq_data(self): #json数据用来传递网页本身数据类型为json的
response=requests.post(self.jq_url,headers=self.jq_headers,json=self.jq_payload)
print(response.text)
这只是单个城市的单页数据,要想获得全国城市的信息就要获得全国城市的代号Id,这里我去到酒店页面去找了发现代号基本相同
最后通过拿前一页token,构造翻页参数基本完成,主要代码如下
def parse_jq_data(self):
cname, cityId = self.parse_city_data() # 调用该方法获得所有城市名和ID
for cnames, cityIds in zip(cname, cityId):
print("城市名字:", cnames)
print("城市ID:", cityIds)
self.jq_payload['districtId'] = cityIds # 切换每个城市ID
one_data = self.get_jq_data() # 调用请求景点的方法,像不同城市景点发起请求
# 构造翻页参数
totalCount = jsonpath(one_data, '$..totalCount')[0]
# print(totalCount)
# 向上取整计算出总页数
page = math.ceil(totalCount / 20) # 总页数
# print(page)
for i in range(1, page+1):
print('当前城市名为{},城市ID为{},此时正在下载{}页'.format(cnames, cityIds, i))
self.jq_payload['index'] = i # 修改翻页参数
# 像每一页参数发起请求
page_json = self.get_jq_data()
token = jsonpath(page_json, '$..token')[0]
print('token值为:', token)
self.jq_payload['token'] = token
poiName = jsonpath(page_json, '$..poiName') # 景区名字
detailUrl = jsonpath(page_json, '$..detailUrl') # 链接
if poiName == False:
poiName = ['无']
if detailUrl == False:
detailUrl = ['无']
for p, d in zip(poiName, detailUrl):
print(p)
print(d)
print('=' * 10)保存代码就偷懒没写了,不管这个数据很大,建议保存到数据库