利用redis ZSet 有序集合实现可靠滚动分页
利用redis ZSet 有序集合实现可靠滚动分页 即在有新的数据插入分页查询不会查询重复或者遗漏数据
传统的分页 前端参数一般传入当前页数curpage和页面长度paegsize 最终通过数据库limit curpage*(pageszie-1),pageszie 实现分页 假设两参数分别为1,5 即 limit 0,5 也就是查询序号0到4的5条数据 这时如果数据库新增了一条数据其序号为1。
如果查询下一页即limit 5,5 查询序号为5 到9的数据
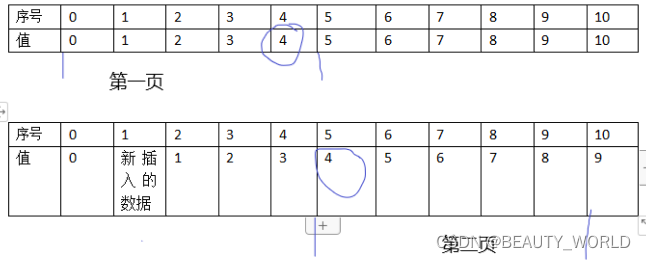
如图所示,很显然值为四的数据被重复查了。 查了下比较流行的做法就是新增一个字段,记录数据插入的时间。 然后查寻第一页的时候记录当前时间,之后每次分页查询都需要带上这个时间 把比这个时间大的数据排除。该方案挺不错,但是要修改数据库,费事.
我的方案是借助redis 的有序集合 ,每次插入数据库成功时,额外保存一份<数据id,插入时间>到redis的有序集合里 。这时就可以通过插入时间分页了。第一次查询返回按时间排序前1到5的数据, 然后记录当前的时间6 。 之后的查询带上这个时间。 返回从 比这个时间小的第一个数据(即为5)和其后的四条数据。
。如图:
| 时间戳 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 值 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 第一页 | ||||||||||
| 时间戳 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 值 | 新插入的数据 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 第一页 | 第二页 | ||||||||||
但是这也有个问题 假如同一时间新增很多条数据怎么办。
| 时间戳 | 10 | 9 | 8 | 7 | 6 | 6 | 6 | 5 | 4 | 3 | 2 | 1 |
| 值 | 10 | 9 | 8 | 7 | 6 | 6 | 6 | 5 | 4 | 3 | 2 | 1 |
引入个新的变量offset 记录返回的数据中有几个和 他们最后一个数据时间相同 上图
第一次查询返回 10 9 8 7 6 6即为2。 然后下一次查询的参数即为最后一个数据的时间戳6 ,偏移量2 ,就能确定是从第三个6开始了。表达能力太差了说不清楚 直接上代码:
@PostMapping
public Result saveBlog(@RequestBody Blog blog) {
// 获取登录用户
UserDTO user = UserHolder.getUser();
Long userId = user.getId();
blog.setUserId(userId);
// 保存探店博客
if (blogService.save(blog)) {
Long currTime = System.currentTimeMillis();
// 博客推送给关注作者的人
// 1获得关注该作者的用户列表
List<Follow> follows = followService.query().select("user_id").eq("follow_user_id", userId).list();
for (Follow follow : follows
) {
Long followId = follow.getUserId();
//
String key = RedisConstants.FEED_KEY + followId;
stringRedisTemplate.opsForZSet().add(key,String.valueOf(blog.getId()),currTime);
}
// 返回id
return Result.ok(blog.getId());
}
return Result.fail("发布笔记失败");
}
@Override
public Result queryBlogByFollow(Long max, Integer offset) {
// 1.获取当前用户
Long userId = UserHolder.getUser().getId();
// 2.查询收件箱 ZREVRANGEBYSCORE key Max Min LIMIT offset count
String key = RedisConstants.FEED_KEY + userId;
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, max, offset, 2);
// 3.非空判断
if (typedTuples == null || typedTuples.isEmpty()) {
return Result.ok();}
// 4.解析数据:blogId、minTime(时间戳)、offset
List<Long> ids = new ArrayList<>(typedTuples.size());
long minTime = 0; // 2
int os = 1; // 2
for (ZSetOperations.TypedTuple<String> tuple : typedTuples) { // 5 4 4 2 2
// 4.1.获取id
ids.add(Long.valueOf(tuple.getValue()));
// 4.2.获取分数(时间戳)
long time = tuple.getScore().longValue();
if (time == minTime) {
os++;
} else {
minTime = time;
os = 1;
}
}
os = minTime == max ? os : os + offset;
// 5.根据id查询blog
String idStr = StrUtil.join(",", ids);
List<Blog> blogs = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list();
for (Blog blog : blogs) {
// 5.1.查询blog有关的用户
queryBlogUser(blog);
// 5.2.查询blog是否被点赞
// isBlogLiked(blog);
}
// 6.封装并返回
ScrollResult r = new ScrollResult();
r.setList(blogs);
r.setOffset(os);
r.setMinTime(minTime);
return Result.ok(r);
}