数据分享|R语言、SPSS基于主成分PCA的中国城镇居民消费结构研究可视化分析
全文链接:http://tecdat.cn/?p=31563
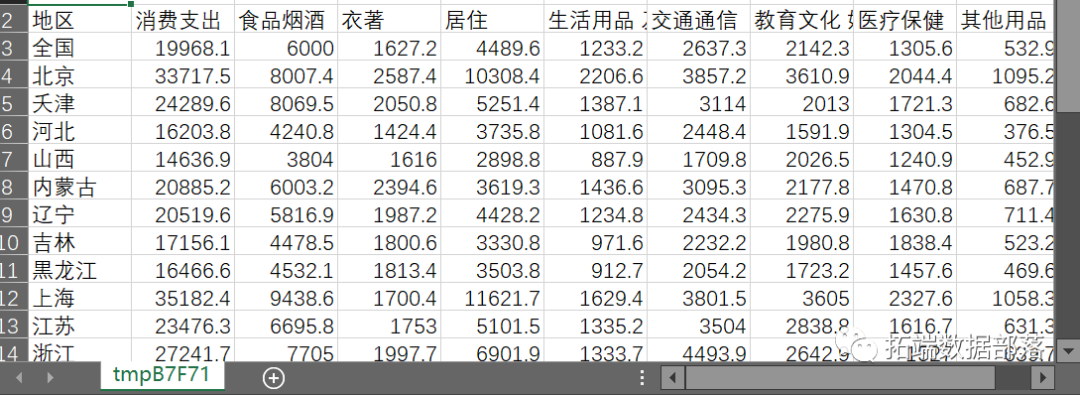
以全国31个省、市、自治区的城镇居民家庭平均每人全年消费性支出的食品、衣着、居住、家庭设备用品及服务、医疗保健、交通与通讯、娱乐教育文化服务、其它商品和服务等 8 个指标数据(查看文末了解数据免费获取方式)为依据, 利用SPSS和R统计软件, 采用主成分分析法对当前城镇居民消费结构进行分析(点击文末“阅读原文”获取完整代码数据)。
相关视频
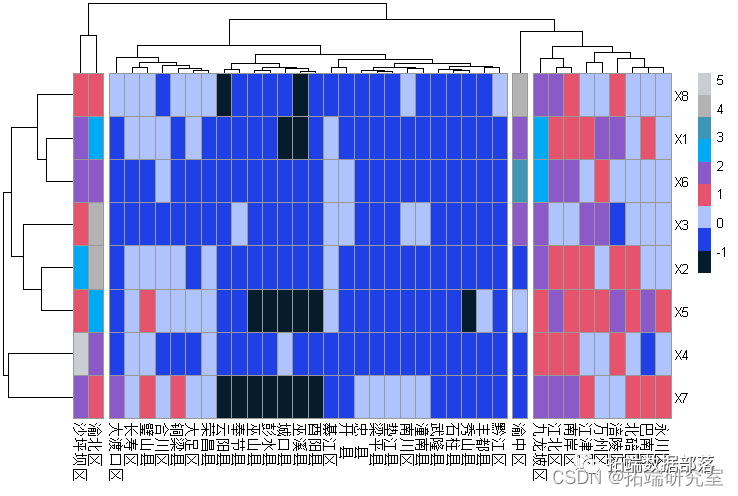
结果显示: 娱乐教育文化服务、交通通讯、家庭设备用品、居住、食品是影响消费大小变动的主要因素, 而衣着、医疗保健、居住、食品是影响消费结构变动的主要因素; 各省市城镇居民消费大小与其经济发达程度密切相关; 相邻省市消费结构比较相似; 沿海地区与内地消费结构有较大的差别。
第一步:录入或调入数据
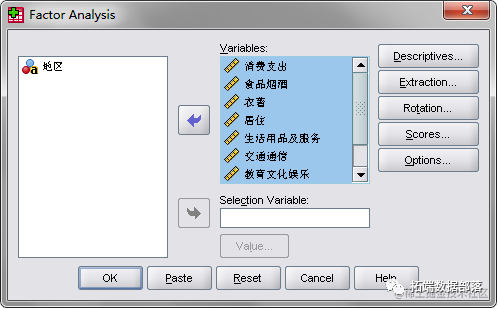
第二步:打开“因子分析”对话框。
沿着主菜单的“Analyze→Data Reduction→Factor”的路径(图2)打开因子分析选项框
第三步:选项设置。
首先,在源变量框中选中需要进行分析的变量,点击右边的箭头符号,将需要的变量调入变量(Variables)栏中(图3)。在本例中,全部8个变量都要用上,故全部调入(图4)。因无特殊需要,故不必理会“Value”栏。下面逐项设置
⒈ 设置Descriptives选项。
单击Descriptives按钮(图4),弹出Descriptives对话框(图5)。
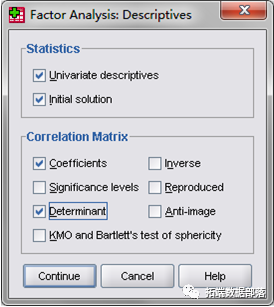
在Statistics栏中选中Univariate descriptives复选项,则输出结果中将会给出原始数据的抽样均值、方差和样本数目(这一栏结果可供检验参考);选中Initial solution复选项,则会给出主成分载荷的公因子方差(这一栏数据分析时有用)。
点击标题查阅往期内容

R语言主成分PCA、因子分析、聚类对地区经济研究分析重庆市经济指标

左右滑动查看更多

01
02
03
04
在Correlation Matrix栏中,选中Coefficients复选项,则会给出原始变量的相关系数矩阵(分析时可参考);选中Determinant复选项,则会给出相关系数矩阵的行列式,如果希望在Excel中对某些计算过程进行了解,可选此项,否则用途不大。其它复选项一般不用,但在特殊情况下可以用到(本例不选)。
设置完成以后,单击Continue按钮完成设置(图5)。
设置Extraction选项。
打开Extraction对话框(图6)。因子提取方法主要有7种,在Method栏中可以看到,系统默认的提取方法是主成分,因此对此栏不作变动,就是认可了主成分分析方法。
在Analyze栏中,选中Correlation matirx复选项,则因子分析基于数据的相关系数矩阵进行分析;如果选中Covariance matrix复选项,则因子分析基于数据的协方差矩阵进行分析。对于主成分分析而言,由于数据标准化了,这两个结果没有分别,因此任选其一即可。
在Display栏中,选中Unrotated factor solution(非旋转因子解)复选项,则在分析结果中给出未经旋转的因子提取结果。对于主成分分析而言,这一项选择与否都一样;对于旋转因子分析,选择此项,可将旋转前后的结果同时给出,以便对比。
选中Scree Plot(“山麓”图),则在分析结果中给出特征根按大小分布的折线图(形如山麓截面,故得名),以便我们直观地判定因子的提取数量是否准确。
主成分计算是利用迭代(Iterations)方法,系统默认的迭代次数是25次。但是,当数据量较大时,25次迭代是不够的,需要改为50次、100次乃至更多。对于本例而言,变量较少,25次迭代足够,故无需改动。
设置Scores设置。
选中Save as variables栏,则分析结果中给出标准化的主成分得分(在数据表的后面)。至于方法复选项,对主成分分析而言
选中Display factor score coefficient matrix,则在分析结果中给出因子得分系数矩阵及其相关矩阵。
选中Display factor score coefficient matrix,则在分析结果中给出因子得分系数矩阵及其相关矩阵。
其它。
对于主成分分析而言,旋转项(Rotation)可以不必设置;对于数据没有缺失的情况下,Option项可以不必理会。
| Correlation Matrixa | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 消费支出 | 食品烟酒 | 衣著 | 居住 | 生活用品及服务 | 交通通信 | 教育文化娱乐 | 医疗保健 | 其他用品及服务 | ||
| Correlation | 消费支出 | 1.000 | .873 | .499 | .960 | .838 | .872 | .860 | .715 | .906 |
| 食品烟酒 | .873 | 1.000 | .262 | .811 | .663 | .755 | .620 | .396 | .751 | |
| 衣著 | .499 | .262 | 1.000 | .377 | .646 | .424 | .355 | .606 | .649 | |
| 居住 | .960 | .811 | .377 | 1.000 | .774 | .761 | .825 | .657 | .861 | |
| 生活用品及服务 | .838 | .663 | .646 | .774 | 1.000 | .685 | .730 | .608 | .804 | |
| 交通通信 | .872 | .755 | .424 | .761 | .685 | 1.000 | .774 | .624 | .727 | |
| 教育文化娱乐 | .860 | .620 | .355 | .825 | .730 | .774 | 1.000 | .735 | .743 | |
| 医疗保健 | .715 | .396 | .606 | .657 | .608 | .624 | .735 | 1.000 | .694 | |
| 其他用品及服务 | .906 | .751 | .649 | .861 | .804 | .727 | .743 | .694 | 1.000 | |
| a. Determinant = 1.69E-014 |
Correlation Matrix(相关系数矩阵),一般而言,相关系数高的变量,大多会进入同一个主成分,但不尽然,除了相关系数外,决定变量在主成分中分布地位的因素还有数据的结构。相关系数矩阵对主成分分析具有参考价值,毕竟主成分分析是从计算相关系数矩阵的特征根开始的。
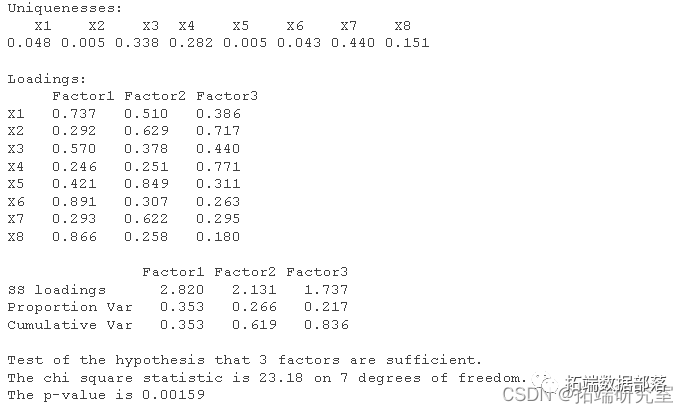
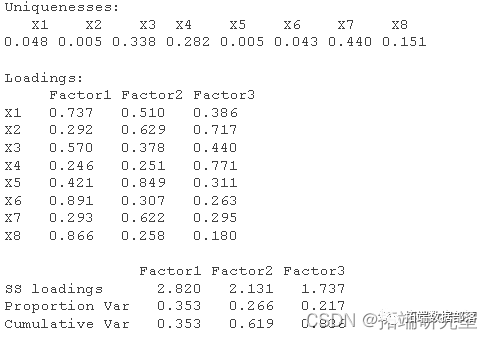
在Communalities(公因子方差)中,给出了因子载荷阵的初始公因子方差(Initial)和提取公因子方差(Extraction)
| Communalities | ||
|---|---|---|
| Initial | Extraction | |
| 消费支出 | 1.000 | .975 |
| 食品烟酒 | 1.000 | .659 |
| 衣著 | 1.000 | .362 |
| 居住 | 1.000 | .860 |
| 生活用品及服务 | 1.000 | .770 |
| 交通通信 | 1.000 | .754 |
| 教育文化娱乐 | 1.000 | .764 |
| 医疗保健 | 1.000 | .605 |
| 其他用品及服务 | 1.000 | .864 |
| Extraction Method: Principal Component Analysis. |
在Total Variance Explained(全部解释方差) 表的Initial Eigenvalues(初始特 7 征根)中,给出了按顺序排列的主成分得分的方差(Total),在数值上等于相关系数矩阵的各个特征根λ,因此可以直接根据特征根计算每一个主成分的方差百分比(% of Variance)。
| Total Variance Explained | ||||||
|---|---|---|---|---|---|---|
| Component | Initial Eigenvalues | Extraction Sums of Squared Loadings | ||||
| Total | % of Variance | Cumulative % | Total | % of Variance | Cumulative % | |
| 1 | 6.613 | 73.479 | 73.479 | 6.613 | 73.479 | 73.479 |
| 2 | .992 | 11.027 | 84.506 | |||
| 3 | .555 | 6.162 | 90.668 | |||
| 4 | .298 | 3.313 | 93.980 | |||
| 5 | .259 | 2.879 | 96.859 | |||
| 6 | .131 | 1.454 | 98.314 | |||
| 7 | .088 | .980 | 99.294 | |||
| 8 | .064 | .706 | 100.000 | |||
| 9 | 8.213E-11 | 9.125E-10 | 100.000 | |||
| Extraction Method: Principal Component Analysis. |
主成分的数目可以根据相关系数矩阵的特征根来判定,如前所说,相关系数矩阵的特征根刚好等于主成分的方差,而方差是变量数据蕴涵信息的重要判据之一。根据λ值决定主成分数目的准则有三:
i 只取λ>1的特征根对应的主成分
从Total Variance Explained表中可见,第一、第二和第三个主成分对应的λ值都大于1,这意味着这三个主成分得分的方差都大于1。本例正是根据这条准则提取主成分的。
ii 累计百分比达到80%~85%以上的λ值对应的主成分
在Total Variance Explained表可以看出,前三个主成分对应的λ值累计百分比达到89.584%,这暗示只要选取三个主成分,信息量就够了。
iii 根据特征根变化的突变点决定主成分的数量
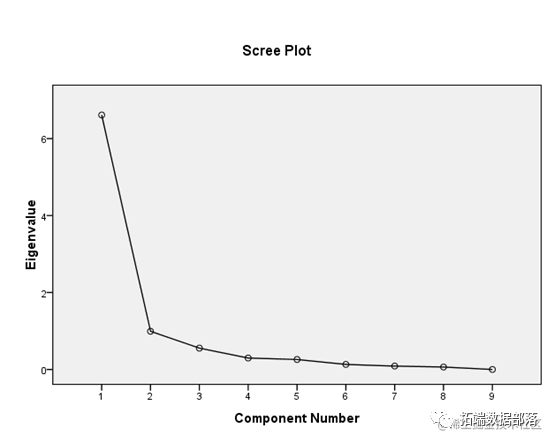
从特征根分布的折线图(Scree Plot)上可以看到,第4个λ值是一个明显的折点,这暗示选取的主成分数目应有p≤4(图8)。那么,究竟是3个还是4个呢?根据前面两条准则,选3个大致合适(但小有问题)。
在Component Matrix(成分矩阵)中,给出了主成分载荷矩阵,每一列载荷值都显示了各个变量与有关主成分的相关系数。以第一列为例,0.885实际上是消费支出与第一个主成分的相关系数。
| Component Matrixa | |
|---|---|
| Component | |
| 1 | |
| 消费支出 | .987 |
| 食品烟酒 | .812 |
| 衣著 | .601 |
| 居住 | .928 |
| 生活用品及服务 | .877 |
| 交通通信 | .868 |
| 教育文化娱乐 | .874 |
| 医疗保健 | .778 |
| 其他用品及服务 | .930 |
| Extraction Method: Principal Component Analysis. | |
| a. 1 components extracted. |
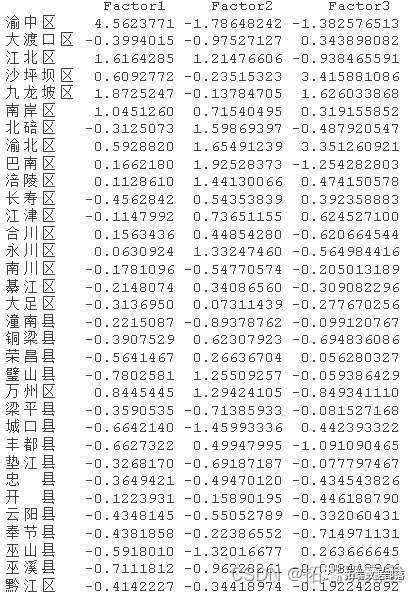
R语言按地区划分的主成分可视化
res.pca <- prcomp(data[, -1], scale = TRUE)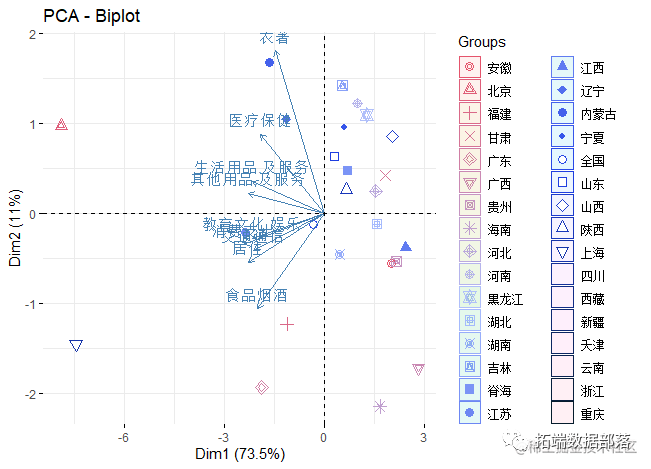
数据获取
在公众号后台回复“居民消费数据”,可免费获取完整数据。

本文中分析的数据分享到会员群,扫描下面二维码即可加群!


点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《R语言、SPSS基于主成分PCA的中国城镇居民消费结构研究可视化分析》。
点击标题查阅往期内容
R语言主成分PCA、因子分析、聚类对地区经济研究分析重庆市经济指标
数据分享|R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言逻辑回归logistic模型分析泰坦尼克titanic数据集预测生还情况
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言逻辑回归(Logistic回归)模型分类预测病人冠心病风险
R语言用局部加权回归(Lowess)对logistic逻辑回归诊断和残差分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言用线性模型进行臭氧预测:加权泊松回归,普通最小二乘,加权负二项式模型,多重插补缺失值
R语言Bootstrap的岭回归和自适应LASSO回归可视化
R语言多元时间序列滚动预测:ARIMA、回归、ARIMAX模型分析
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言混合效应逻辑回归(mixed effects logistic)模型分析肺癌数据
R语言建立和可视化混合效应模型mixed effect model
R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)
R语言如何解决线性混合模型中畸形拟合(Singular fit)的问题
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言用WinBUGS 软件对学术能力测验(SAT)建立分层模型
使用SAS,Stata,HLM,R,SPSS和Mplus的分层线性模型HLM
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
SPSS中的多层(等级)线性模型Multilevel linear models研究整容手术数据
R语言高维数据的主成分pca、 t-SNE算法降维与可视化分析案例报告
R语言惩罚logistic逻辑回归(LASSO,岭回归)高维变量选择的分类模型案例
R语言使用Metropolis- Hasting抽样算法进行逻辑回归
R语言自适应LASSO 多项式回归、二元逻辑回归和岭回归应用分析
R语言基于树的方法:决策树,随机森林,Bagging,增强树
python在Scikit-learn中用决策树和随机森林预测NBA获胜者
R语言惩罚logistic逻辑回归(LASSO,岭回归)高维变量选择的分类模型案例
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分

![]()
