Prometheus Grafana搭建
一、prometheus介绍
prometheus是由谷歌研发的一款开源的监控软件,它通过安装在远程机器上的exporter,通过HTTP协议从远程的机器收集数据并存储在本地的时序数据库上
同时Prometheus后端用 golang语言开发,前端是 Grafana
Prometheus 还是一款基于时序数据库的开源监控告警系统,非常适合Kubernetes集群的监控。Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、
Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。Promethus有以下特点:
- 支持多维数据模型:由度量名和键值对组成的时间序列数据
- 内置时间序列数据库TSDB
- 支持PromQL查询语言,可以完成非常复杂的查询和分析,对图表展示和告警非常有意义
- 支持HTTP的Pull方式采集时间序列数据
- 支持PushGateway采集瞬时任务的数据
- 支持服务发现和静态配置两种方式发现目标
- 支持接入Grafana
- Prometheus的流行和Kubernetes密不可分,支持对Kubernetes、容器、OpenStack的监控。
二、prometheus部署
1、使用系统
| ip | 角色 | 系统 |
| 192.168.12.13 | prometheus(服务器端)grafana、node_exporter2(客户端) | centos7 |
| 192.168.12.12 | node_exporter1(数据采集数据) | centos7 |
https://prometheus.io/download/本次使用的prometheus版本为:

下载后直接上传服务器192.168.12.13 /date目录下
也可以在服务器上使用wget下载prometheus安装包
[root@node3 date]# wget https://github.com/prometheus/prometheus/releases/download/v2.27.1/prometheus-2.27.1.linux-amd64.tar.gz
[root@node3 date]# tar -xf prometheus-2.27.1.linux-amd64.tar.gz
[root@node3 date]# mv prometheus-2.27.1.linux-amd64/ Prometheus
查看版本号:
[root@node3 Prometheus]# ./prometheus --version
prometheus, version 2.27.1 (branch: HEAD, revision: db7f0bcec27bd8aeebad6b08ac849516efa9ae02)
build user: root@fd804fbd4f25
build date: 20210518-14:17:54
go version: go1.16.4
platform: linux/amd64
[root@node3 prometheus]# pwd
/date/prometheus
[root@node3 Prometheus]#
查看帮助文档
[root@node3 prometheus]# ./prometheus --help
usage: prometheus [<flags>]
The Prometheus monitoring server
Flags:
-h, --help Show context-sensitive help (also try --help-long and --help-man).
--version Show application version.
--config.file="prometheus.yml"
Prometheus configuration file path.
--web.listen-address="0.0.0.0:9090"
Address to listen on for UI, API, and telemetry.
--web.config.file="" [EXPERIMENTAL] Path to configuration file that can enable TLS or authentication.
--web.read-timeout=5m Maximum duration before timing out read of the request, and closing idle connections.
--web.max-connections=512 Maximum number of simultaneous connections.
--web.external-url=<URL> 2、prometheus.yml 配置文件解释
[root@node3 Prometheus]# cat prometheus.yml
# my global config
global:
# 默认情况下,每15s拉取一次目标采样点数据
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
# 每15秒评估一次规则。默认值为每1分钟。
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
# rule_files指定加载的告警规则文件,
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
#scrape_configs指定prometheus要监控的目标
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
# job名称会增加到拉取到的所有采样点上,同时还有一个instance目标服务的host:port标签也会增加到采样
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['192.168.12.13:9090']
- job_name: 'linux'
static_configs:
#定义监控的节点
- targets: ['192.168.12.12:9100','192.168.12.13:9100']
3、启动prometheus
# 启动服务
# 这里使用后台启动的方式启动prometheus
[root@node3 Prometheus]# nohup ./Prometheus &
#下面是启动的可选项
# 指定配置文件
--config.file="prometheus.yml"
# 默认指定监听地址端口,可修改端口
--web. Listen-address="0.0.0.0:9090"
# 最大连接数
--web.max-connections=512
# tsdb数据存储的目录,默认当前data/
--storage.tsdb.path="data/"
# premetheus 存储数据的时间,默认保存15天
--storage.tsdb.retention=15d
# 通过命令热加载无需重启 curl -XPOST 192.168.2.45:9090/-/reload
--web.enable-lifecycle
# 可以启用 TLS 或 身份验证 的配置文件的路径
--web.config.file=""
4、查看日志和端口是否启动陈宫
[root@node3 prometheus]# nohup ./prometheus &
[1] 1282
[root@node3 prometheus]# nohup: 忽略输入并把输出追加到"nohup.out"
^C
[root@node3 prometheus]# ^C
[root@node3 prometheus]# tail -f nohup.out
level=info ts=2023-09-13T01:22:29.319Z caller=main.go:988 msg="Completed loading of configuration file" filename=prometheus.yml totalDuration=1.390661ms remote_storage=1.253µs web_handler=357ns query_engine=723ns scrape=687.717µs scrape_sd=81.596µs notify=84.283µs notify_sd=7.763µs rules=12.087µs
level=info ts=2023-09-13T01:22:29.319Z caller=main.go:775 msg="Server is ready to receive web requests."
level=info ts=2023-09-13T01:22:36.715Z caller=compact.go:513 component=tsdb msg="write block" mint=1694505600000 maxt=1694512800000 ulid=01HA6243FNNVFAA1G64C21BSX9 duration=54.306316ms
level=info ts=2023-09-13T01:22:36.718Z caller=head.go:925 component=tsdb msg="Head GC completed" duration=2.259002ms
level=info ts=2023-09-13T01:22:36.722Z caller=checkpoint.go:97 component=tsdb msg="Creating checkpoint" from_segment=10 to_segment=11 mint=1694512800000
level=info ts=2023-09-13T01:22:36.760Z caller=head.go:1022 component=tsdb msg="WAL checkpoint complete" first=10 last=11 duration=38.585989ms
level=info ts=2023-09-13T01:22:36.828Z caller=compact.go:454 component=tsdb msg="compact blocks" count=3 mint=1694480217360 maxt=1694498400000 ulid=01HA6243JSE9ES9CM8HH1NWNQ9 sources="[01HA3RJ09QSKZSBERH7KP988BF 01HA3W5T6CXCAA74THPD7PRM7Y 01HA431HEDW8A2XBZD4M2V6P9Y]" duration=67.612531ms
level=info ts=2023-09-13T01:22:36.829Z caller=db.go:1239 component=tsdb msg="Deleting obsolete block" block=01HA3RJ09QSKZSBERH7KP988BF
level=info ts=2023-09-13T01:22:36.829Z caller=db.go:1239 component=tsdb msg="Deleting obsolete block" block=01HA3W5T6CXCAA74THPD7PRM7Y
level=info ts=2023-09-13T01:22:36.831Z caller=db.go:1239 component=tsdb msg="Deleting obsolete block" block=01HA431HEDW8A2XBZD4M2V6P9Y
[root@node3 prometheus]# ss -ntl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:22 *:*
LISTEN 0 100 127.0.0.1:25 *:*
LISTEN 0 128 :::9090 :::*
LISTEN 0 128 :::22 :::*
LISTEN 0 100 ::1:25 :::*
[root@node3 Prometheus]#
5、访问:http://192.168.12.13:9090
看到如下界面说明prometheus启动没有问题
6、查看暴露指标
http://localhost:9090/metrics #locahost可换成自己的ip
7、将Prometheus配置为系统服务
进入cd /usr/lib/system/system 目录下
[root@node3 system]# cat prometheus.service
[Unit]
Description=https://prometheus.io
[Service]
Restart=on-failure
ExecStart=/date/prometheus/prometheus --config.file=/date/prometheus/prometheus.yml --web.listen-address=:9090
[Install]
WantedBy=multi-user. Target
生效系统system文件
systemctl daemon-reload
重启服务
[root@node3 system]# systemctl restart prometheus
[root@node3 system]#
[root@node3 system]#
三、客户端安装node_exporter
| ip | 角色 | 系统 |
| 192.168.12.13 | prometheus(服务器端)grafana、node_exporter2(客户端) | centos7 |
| 192.168.12.12 | node_exporter1(客户端 数据采集数据) | centos7 |
1、下载解压node_exporter
[root@node3 date]# wget https://github.com/prometheus/node_exporter/releases/download/v1.1.2/node_exporter-1.1.2.linux-amd64.tar.gz
[root@node3 date]# tar -xf node_exporter-1.1.2.linux-amd64.tar.gz
[root@node3 date]# mv node_exporter-1.1.2.linux-amd64/ node_exporter
2、启动node_exporter,并添加到系统服务
#直接启动
[root@node3 node_exporter]# nohup ./node_exporter &
[2] 2500
[root@node3 node_exporter]# nohup: 忽略输入并把输出追加到"nohup.out"
[root@node3 node_exporter]#
[root@node3 node_exporter]# ^C
#查看日志
[root@node3 node_exporter]# tail -f nohup.out
level=info ts=2023-09-13T01:44:58.242Z caller=node_exporter.go:113 collector=thermal_zone
level=info ts=2023-09-13T01:44:58.242Z caller=node_exporter.go:113 collector=time
level=info ts=2023-09-13T01:44:58.242Z caller=node_exporter.go:113 collector=timex
level=info ts=2023-09-13T01:44:58.242Z caller=node_exporter.go:113 collector=udp_queues
#设置系统服务
[root@node3 node_exporter]# cd /usr/lib/system/system/
[root@node3sysystem vim node_exporter.service
[root@node3ssystem# cat node_exporter.service
[Unit]
Description=node_exporter
After=network.target
[Service]
ExecStart=/date/node_exporter/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user. Target
# 重启node_exporter
systemctl daemon-reload
systemctl start node_exporter
3、prometheus服务端配置文件添加监控项
[root@node3 Prometheus]# cat prometheus.yml
# my global config
global:
# 默认情况下,每15s拉取一次目标采样点数据
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
# 每15秒评估一次规则。默认值为每1分钟。
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
# rule_files指定加载的告警规则文件,
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
#scrape_configs指定prometheus要监控的目标
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
# job名称会增加到拉取到的所有采样点上,同时还有一个instance目标服务的host:port标签也会增加到采样
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['192.168.12.13:9090']
- job_name: 'linux'
static_configs:
#定义监控的节点 如果有监控多个节点用逗号隔开
- targets: ['192.168.12.12:9100','192.168.12.13:9100']
4、重启prometheus
[root@node3 systemd]# systemctl restart prometheus
[root@node3 systemd]#
打开普罗米修斯自带的监控页面,Status -> Targets 查看:
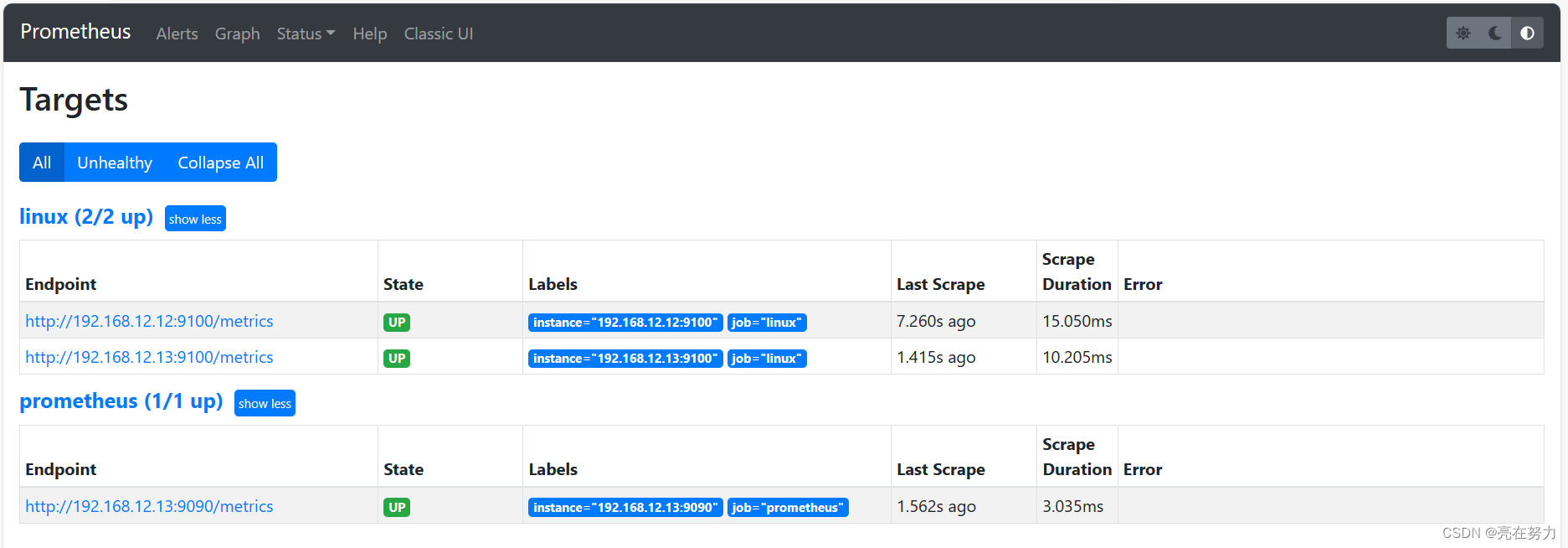
4、为了管理服务,将宿主机节点监控采集node_exporter加入到服务配置文件里
[root@node3 system]# cat node_exporter.service
[Unit]
Description=node_exporter
After=network.target[Service]
ExecStart=/date/node_exporter/node_exporter --collector.systemd --collector.systemd.unit-whitelist=(sshd|nginx).service
Restart=on-failure[Install]
WantedBy=multi-user. Target
如果要监控节点的系统服务,需要在后面添加名单参数
–collector.systemd.unit-whitelist=".+" 从systemd中循环正则匹配单元
–collector.systemd.unit-whitelist="(docker|sshd|nginx).service" 白名单,收集目标
/usr/bin/node_exporter --collector.systemd --collector.systemd.unit-whitelist=(docker|sshd|nginx).service
我们在配置文件有两个监控节点 刚才配置了node3 现在开始同样配置node2
node2加入系统服务如下:
[root@node2 data01]# cd /usr/lib/systemd/system
[root@node2 system]# vim node_exporter.service
[root@node2 system]#
[root@node2 system]# cat node_exporter.service[Unit]
Description=node_exporter
After=network.target[Service]
ExecStart=/date/node_exporter/node_exporter --collector.systemd --collector.systemd.unit-whitelist=(sshd|nginx).service
Restart=on-failure[Install]
[root@node2 system]#
四、Grafana 展示 Prometheus 数据
1、下载安装grafana
下载后解压grafana 并加入系统服务
#解压grafana
[root@node3 date]# tar -xf grafana-enterprise-9.0.0.linux-amd64.tar.gz#grafana加入系统服务
[root@node3 system]# cat grafana.service
[Unit]
Description=Grafana
After=network.target
[Service]
Type=notify
ExecStart=/date/grafana/bin/grafana-server -homepath /date/grafana
Restart=on-failure
[Install]
WantedBy=multi-user.target
[root@node3 system]#启动grafana
[root@node3 system]# systemctl daemon-reload
[root@node3 system]# systemctl start grafana.service
[root@node3 system]# systemctl status grafana.service
● grafana.service - Grafana
Loaded: loaded (/usr/lib/systemd/system/grafana.service; disabled; vendor preset: disabled)
Active: active (running) since 三 2023-09-13 10:26:21 CST; 2s ago
Main PID: 2826 (grafana-server)
CGroup: /system.slice/grafana.service
└─2826 /date/grafana/bin/grafana-server -homepath /date/Grafana
启动后访问地址:ip:3000
初始用户名和密码都是admin
第一次进入默认都会提示修改密码
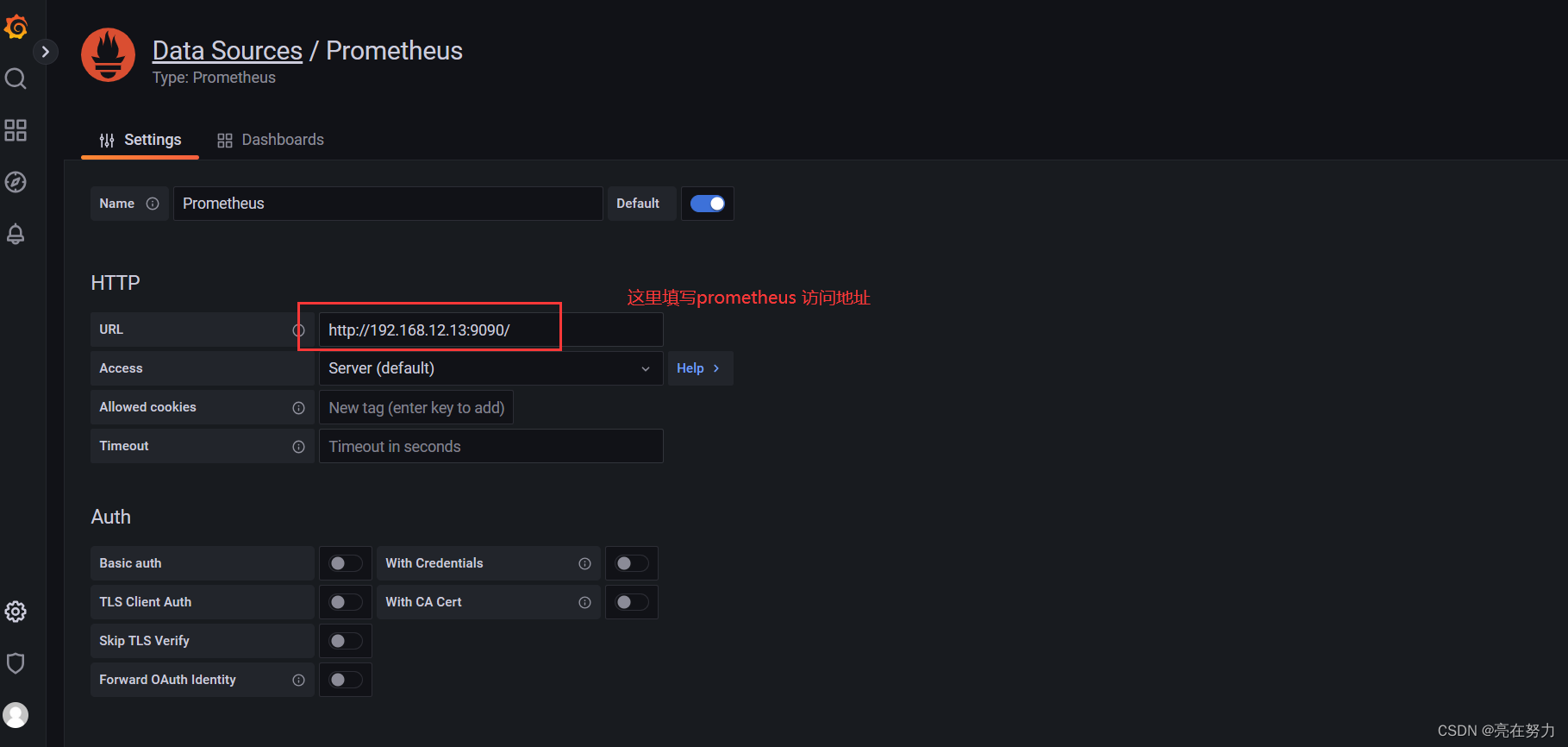
2、添加Prometheus数据源
Configuration -> Data Sources ->add data source -> Prometheus
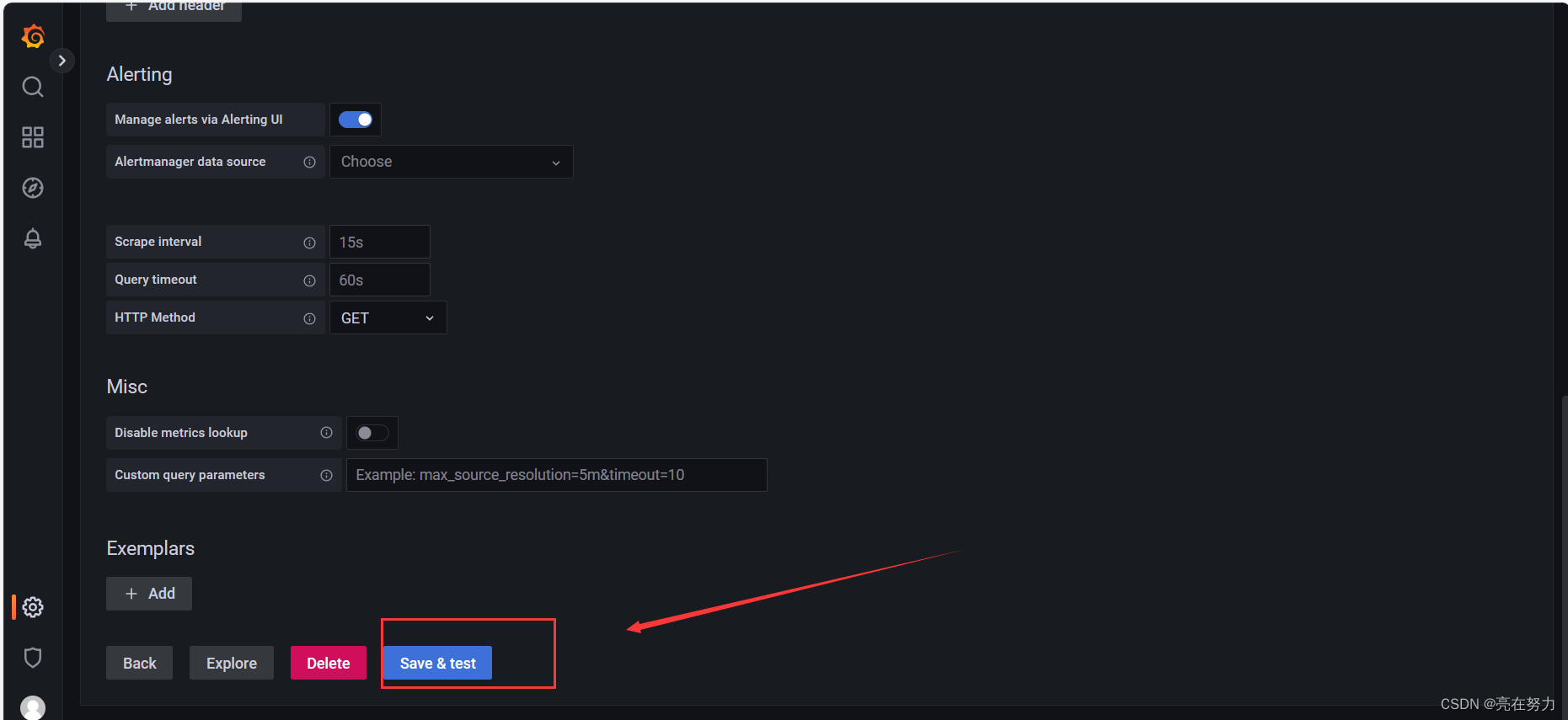
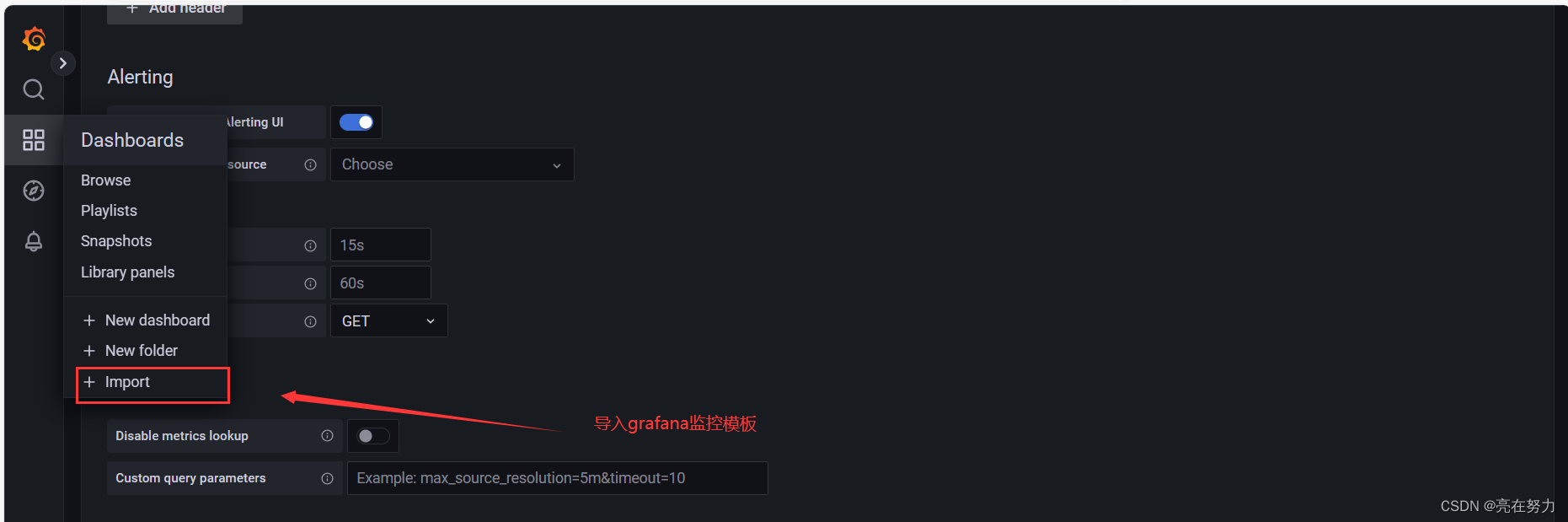
2、新增Dashboard Linux基础数据展示
Create -> import
3、导入模板
grafana官网模板下载地址:
Dashboards | Grafana Labs https://grafana.com/grafana/dashboards/
https://grafana.com/grafana/dashboards/
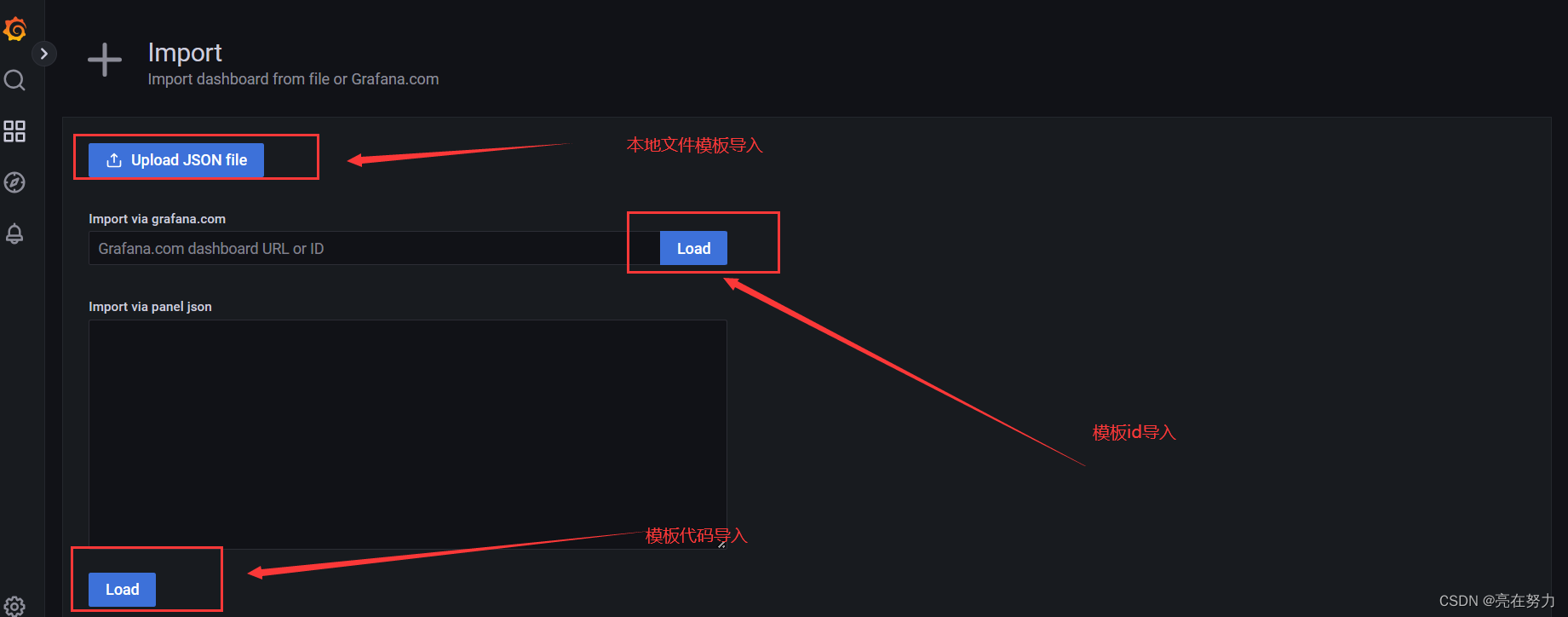
我们选择本地文件导入
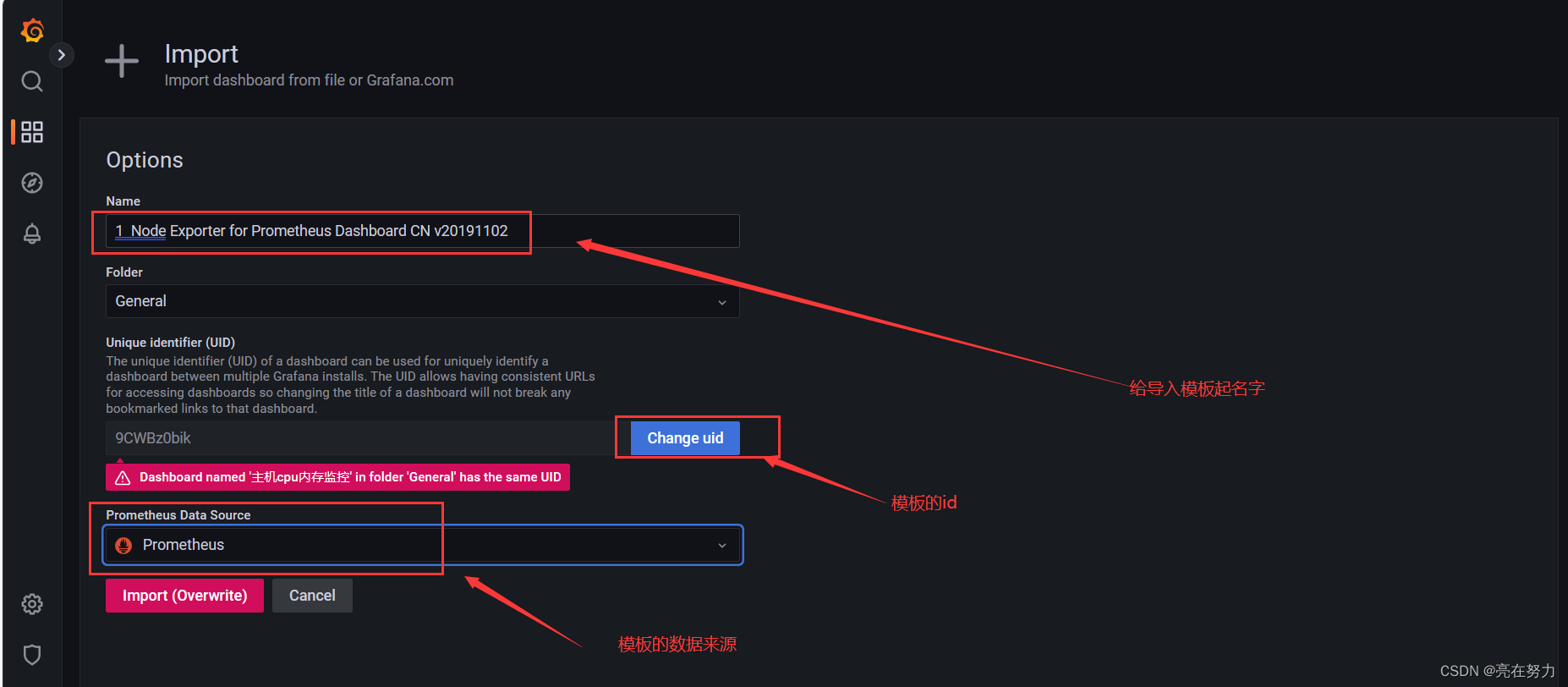
4、查看Dashboard
点击-->>>Dashboards 选择自己创建的模板
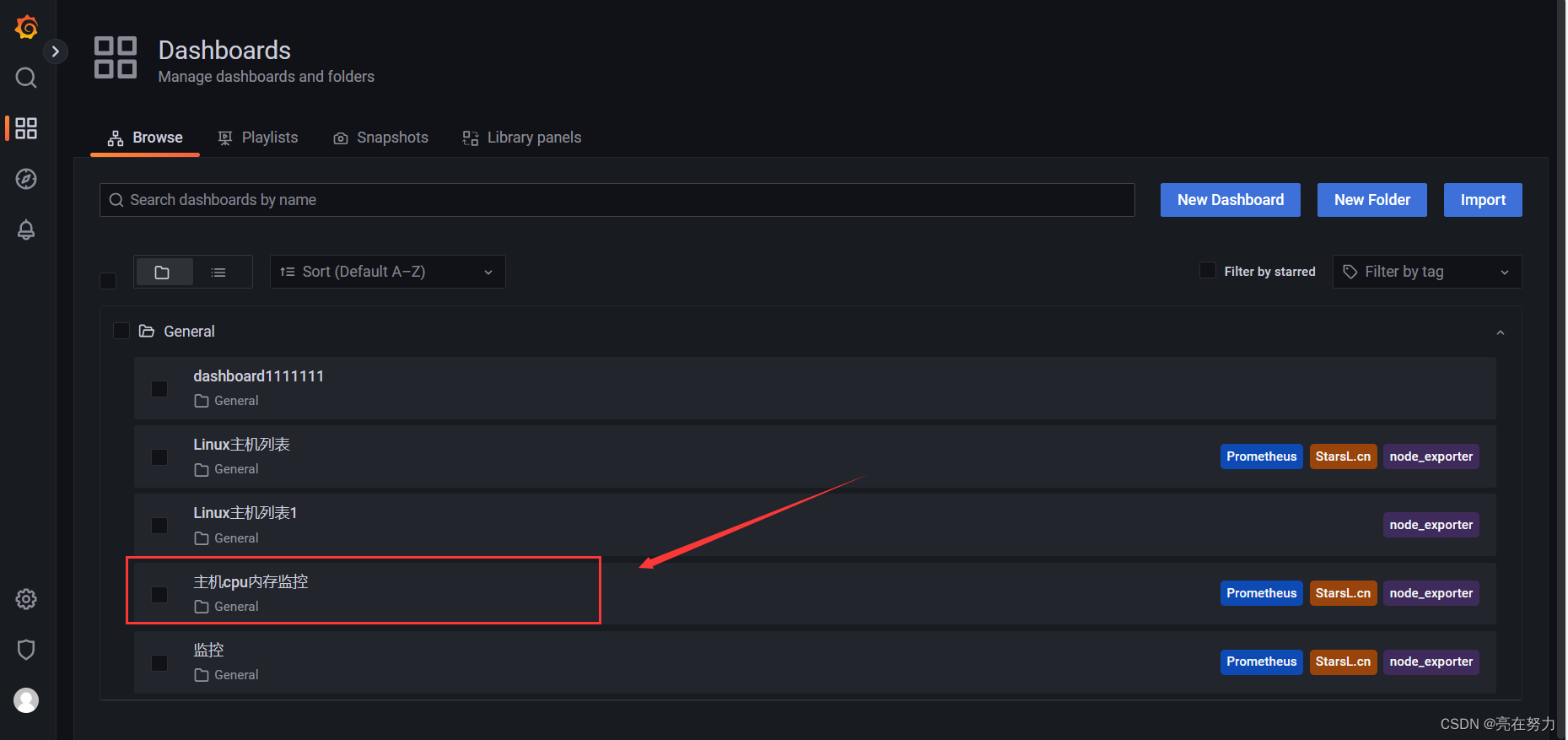
效果如下:
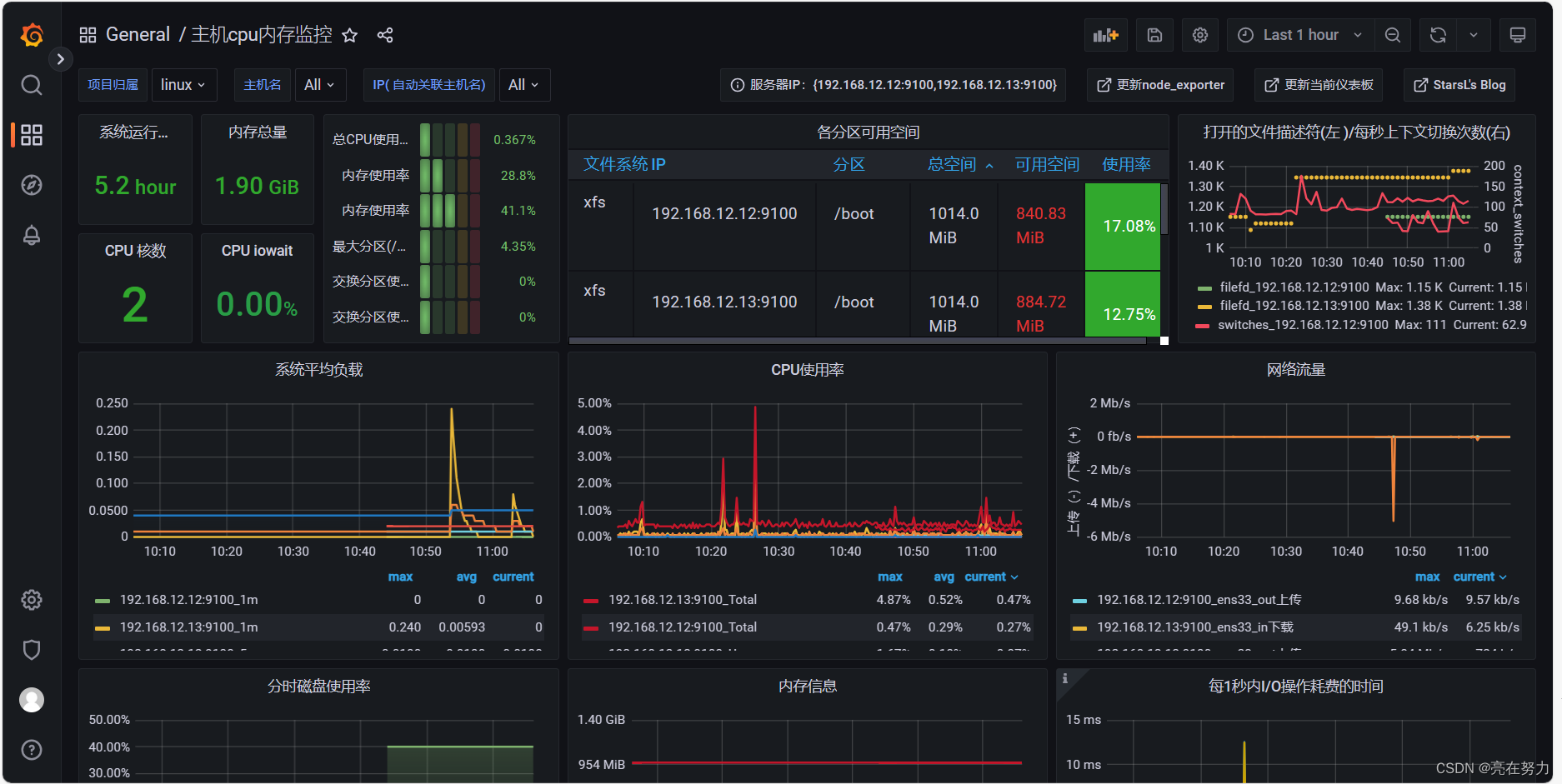
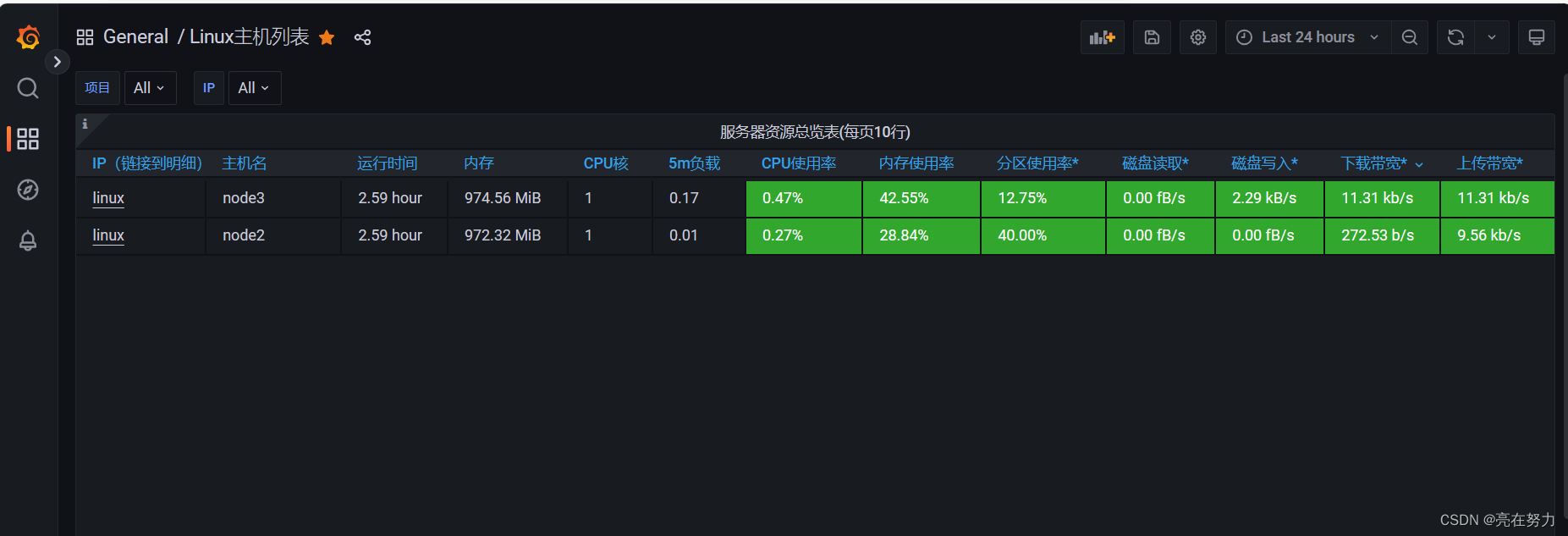
五、搭建过程中可能遇到的问题
1、如图所示
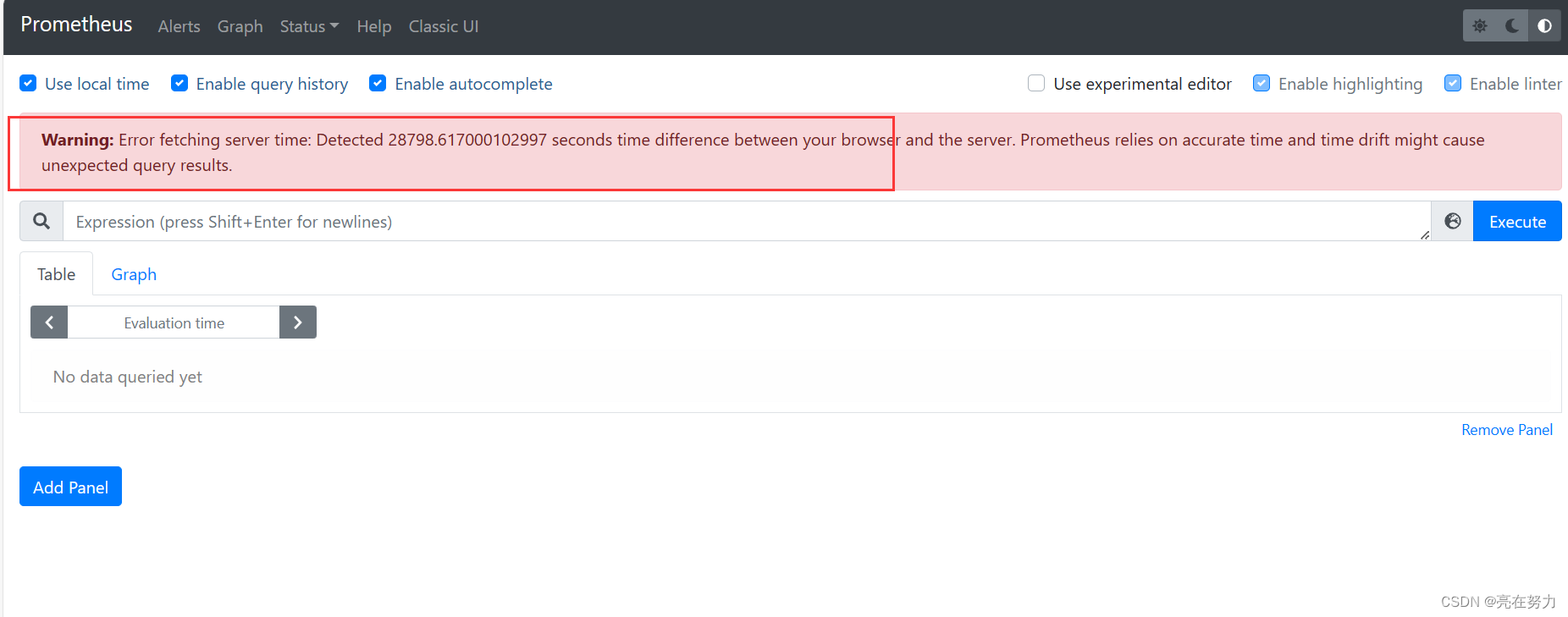
上面这个问题是因为客户端和服务端的时间不同步导致的问题
可以在客户端和服务器上使用date命令查看两台呢服务器时间是否相同
不相同可以使用同步时间命令同步
之后即可恢复正常
2、搭建完成之后,查看日志正常 但是grafana只写实部分数据 想了很久 最后发现是node_exporter 监控组件版本问题
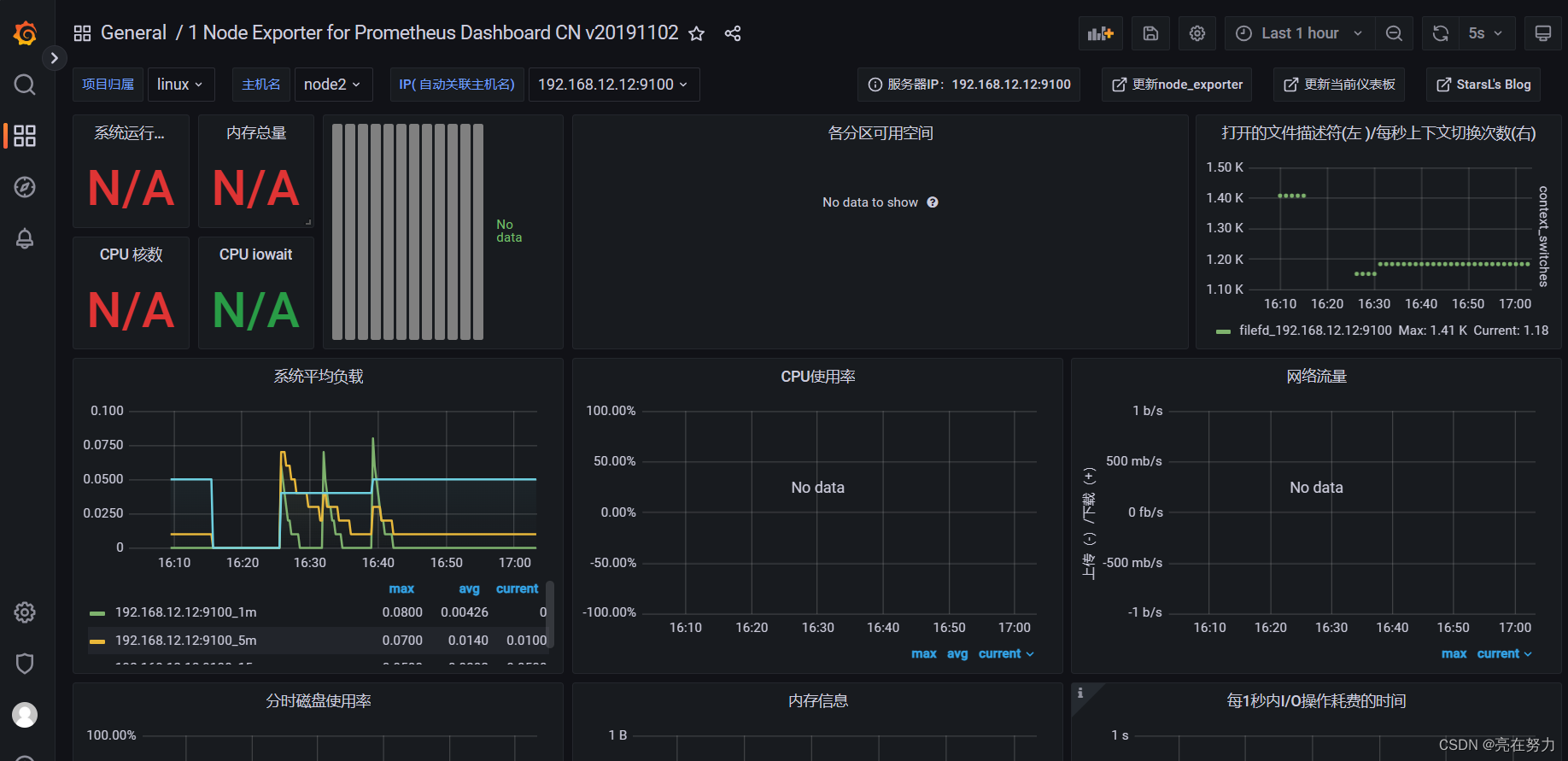
之前我的node_exporter的版本为:
node_exporter-0.14.0.linux-amd64.tar.gz
升级为:
node_exporter-1.1.2.linux-amd64.tar.gz
后grafana监控数据正常
本次为模拟生产环境搭建,欢迎大家指导,