MySQL Innodb引擎锁的分类及死锁排查
1、概览
在实际工作过程中遇到了数据库死锁的问题,在查阅资料的时候遇到了各种锁的概念。
共享锁、排它锁、表级锁、行级锁、记录锁、间隙锁、临键锁、插入意向锁、自增锁等等等等,这些概念如果能够弄清楚其中区别自然最好,但理清这些概念是在是太麻烦了。而且从实际工作情况出发,理清这些概念再去解决实际的工作问题效率太低。
所以我这里基于MySQL数据库的Innodb引擎(注意是MySQL数据库的Innodb引擎,其它引擎或数据库以下总结不完全适用,但有一定的参考价值),以及实际的工作场景,做了以下梳理:
- 锁的概念进行简化
- 以实际sql详细说明锁的产生条件
- 常见解决死锁的方法
2、锁的分类
2.1、从产生锁的行为来划分
2.1.1、共享锁
又被称为读锁、S锁等,事务在对数据进行查询,需要先获取数据的共享锁
2.1.2、排它锁
又被称为写锁、X锁等,事务在对数据进行修改时,需要先获取数据的排它锁
2.1.3、注意
这里“需要先获取数据的共享锁、排它锁”不代表说操作哪条数据,就只锁哪条数据,有可能只操作一条数据,但却锁了某个数据区间、甚至是整张表。锁的范围见下方解释
2.1.4、互斥关系
共享锁和排它锁的兼容和互斥关系想必大家都清楚,这里还是做个简单说明:
如果一个事务给表已经加了S锁,则:
别的事务可以继续获得该表的S锁,也可以获得该表中某些记录的S锁。
别的事务不可以继续获得该表的X锁,也不可以获得该表中某些记录的X锁。
如果一个事务给表加了X锁,那么
别的事务不可以获得该表的S锁,也不可以获得该表某些记录的S锁。
别的事务不可以获得该表的X锁,也不可以继续获得该表某些记录的X锁。
2.2、从锁的范围来划分
2.2.1、表锁
即整张表的数据都被锁定了。
产生场景
sql执行语句没有合理的构建索引;
MySQL优化器自行进行了全表扫描
2.2.2、行锁
即只锁定一行的数据。
产生场景
- 主键索引精确查询且能查找到数据;
2.2.3、间隙锁;
即只锁定一个区间(间隙)的数据,这个产生场景最多,所以放在最后特别说明。
产生场景
- 主键索引范围查询
- 主键索引精确查询但这条数据不存在
- 普通索引进行精确查询或者范围查询都会产生间隙锁
2.2.4、锁定的范围
既然间隙锁锁定的是一个区间,那么这个区间是如何划分的呢?
根据检索条件向左寻找最靠近检索条件的记录值A,作为左区间,如果找不到记录值A,则左区间为无限小;
向右寻找最靠近检索条件的记录值B,作为右区间,如果找不到记录值B,则右区间为无限大
详细说明可以参考这里:https://blog.csdn.net/sfh2018/article/details/121016466,后续测试模拟的表格结构也参考自这里
3、测试模拟
平常学习中可以自行建表模拟事务的执行,虽然不难,但还是在这里说明下,以Navicat为例:
3.1、开启事务
新开一个sql执行界面运行命令,即可开启一个事务
start transaction ; #开启事务
insert into test_gap_table value(16,5);#事务里面可以执行多条SQL语句
COMMIT#如果没有这条指令,则事务将会一直不提交,锁将一直持有,由此便可模拟多个事务进行锁的抢占
3.2、测试表结构如下
CREATE TABLE `test_gap_table` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`number` bigint DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_number` (`number`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
INSERT INTO test_gap_table ( id, number ) VALUE ( 1, 2 );
INSERT INTO test_gap_table ( id, number ) VALUE ( 3, 4 );
INSERT INTO test_gap_table ( id, number ) VALUE ( 6, 5 );
INSERT INTO test_gap_table ( id, number ) VALUE ( 8, 5 );
INSERT INTO test_gap_table ( id, number ) VALUE ( 10, 5 );
INSERT INTO test_gap_table ( id, number ) VALUE ( 13, 11 );
4、死锁问题排查
4.1、简单方式处理
查询现在的死锁线程,然后强制杀死线程。线程id为第一步中查询到的trx_mysql_thread_id的值
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;
kill 11135
以上的方法只是解决掉了当前存在的死锁情况,并未从根本上解决死锁的产生。因此还需要进行死锁日志的查询,判断出导致死锁是哪些业务产生的,然后针对性的进行修改。
4.2、死锁日志分析
4.2.1、执行命令
show engine innodb status
4.2.2、得到日志文本
navicate显示结果如下,没法直接浏览,直接选中返回结果,复制内容到文本编辑器即可
4.2.3、日志读取方法
大家看到日志时估计是非常的头大,可能有1000多行的奇奇怪怪的内容,直接就放弃了。其实我们只需要注意关键字即可。
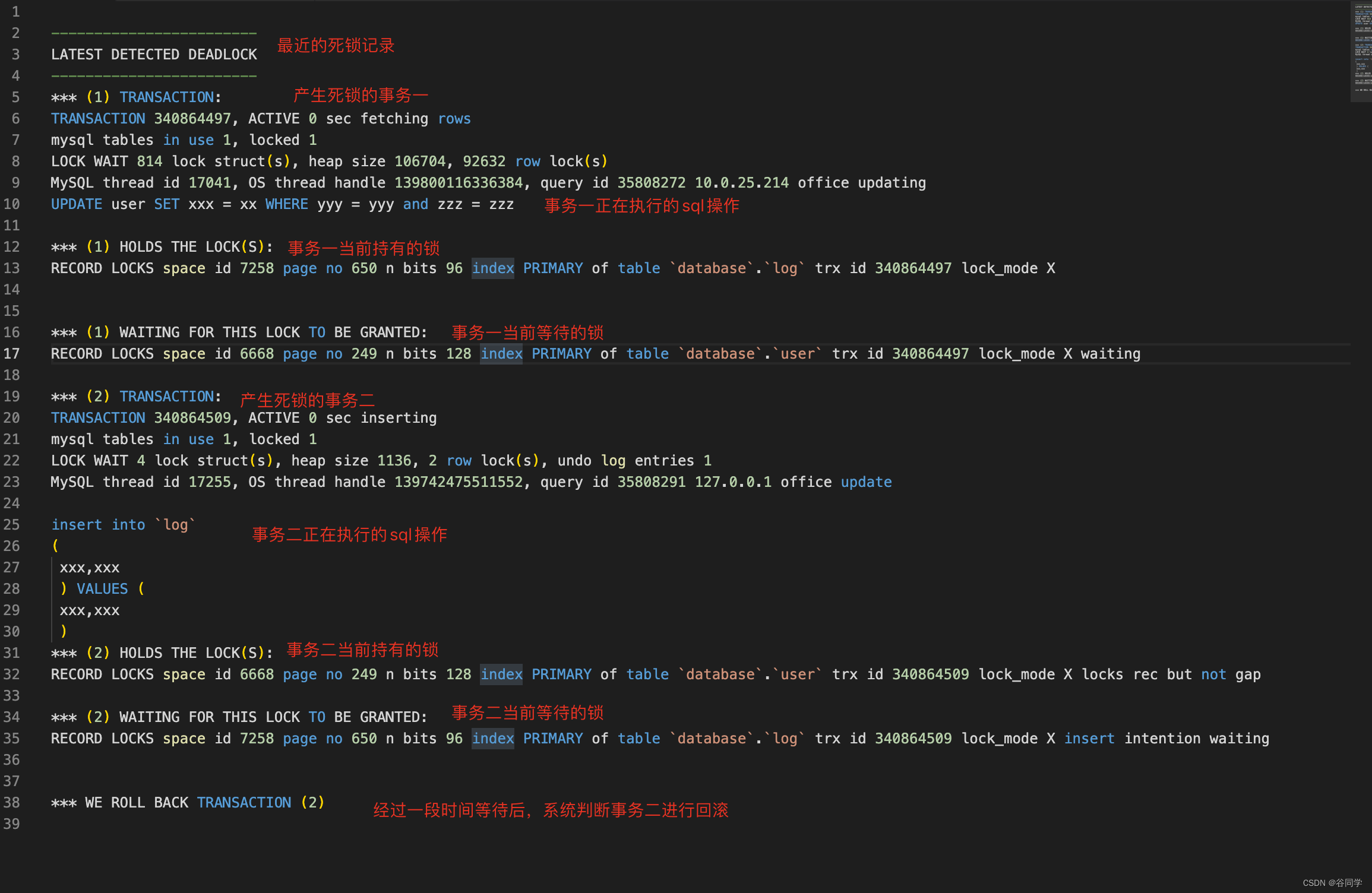
4.2.3.1、精简之后的日志
4.2.3.2关键字说明
- LATEST DETECTED DEADLOCK:最近的死锁日志记录
- *** (1) TRANSACTION:产生死锁的事务
- *** (1) HOLDS THE LOCK(S):事务持有的锁
- *** (1) WAITING FOR THIS LOCK TO BE GRANTED:事务等待的锁
- *** WE ROLL BACK TRANSACTION :系统最后决定回滚了哪个事务
明白了以上的关键字之后,就能够很明白的知道哪些表之间产生了死锁,此时就可以根据实际的业务修改代码或者sql逻辑解决死锁问题了。例如上面的图示,就是两个事务互相持有了对方所需要的锁,互相等待对方释放锁,因此产生了死锁问题。
5、死锁问题解决
首先是老生常谈的产生死锁的四个条件:互斥条件、请求和保持条件、不可剥夺条件、循环等待条件。那么就有以下的消除死锁的方法:
5.1、减小事务粒度
我们经常在代码中一个方法就是一个事务,而一个方法中可能会有多条的sql操作,此时就应该分析,这些sql是否可以拆分到不同的方法中,用不同的事务去承载,由此就可以减少死锁出现的概率。
5.2、添加索引
这个应该是最简单高效的方法,这种方式可以让进行sql操作时尽量产生的是行锁或间隙锁,避免产生表锁进而形成死锁。
5.3、修改sql操作顺序
有时因sql操作顺序不合理,会导致事务互相持有对方需要的锁,此时就需要调整sql执行的顺序,合理规划sql锁资源请求步骤。
5.4、总结
本文从锁的概念出发,基于实际工作情况对一些概念性问题进行了精简。所以如果有遗漏或错误欢迎大家指正。本文参考的博客如下:
- innodb产生行锁及表锁的时机:http://t.zoukankan.com/frankltf-p-9127440.html
- innodb死锁案例分析:https://www.jianshu.com/p/bc8dad91b5ca
- 七种锁即产生测试案例:https://andyoung.blog.csdn.net/article/details/124841771
- 间隙锁介绍:https://www.jianshu.com/p/55299e1329e7
- 间隙锁的产生及区间范围明晰:https://blog.csdn.net/sfh2018/article/details/121016466
- 插入意向锁的产生及区间范围明晰:https://blog.csdn.net/weixin_39789042/article/details/114343141