【Hadoop】Hadoop的目录结构和脚本与环境搭建(本地模式、伪分布模式和全分布模式)
搭建Hadoop环境(本地模式、伪分布模式和全分布模式)
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/118635494(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
1 Hadoop的目录结构和脚本
在进行Hadoop环境安装之前,需要对Hadoop的目录结构和主要脚本有个清晰的认知。
1.1 核实已有配置
在进行介绍之前核实一下之前的操作是否无误。
(1)首先看一下之前配置的主机名和IP地址(核实无误)
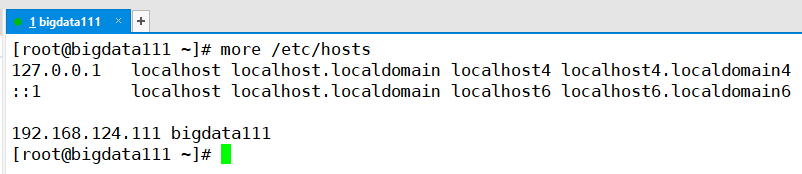
(2)防火墙关闭(核实无误)

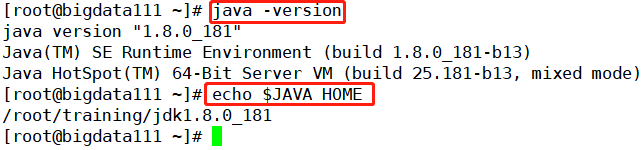
(3)Java JDK和环境变量(核实无误)
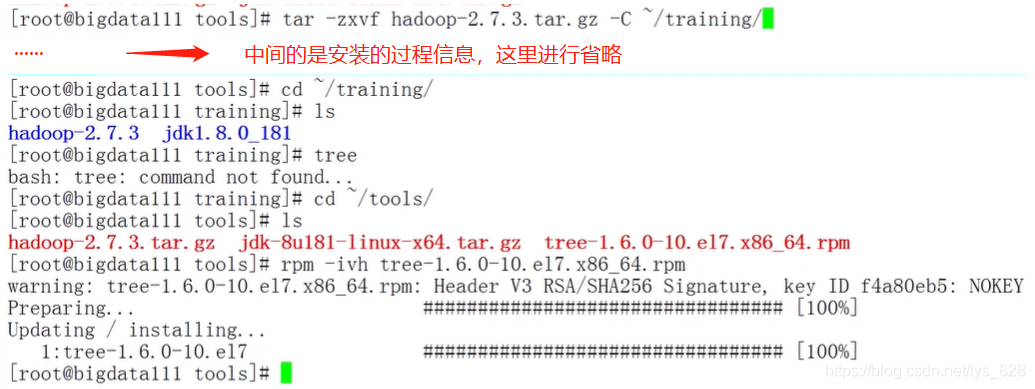
(4)之前上传Java时候顺带上传了Hadoop安装包(核实无误)
其中最后面的tree-1.6.0-10.el7.x86_64.rpm文件就是执行tree指令要安装的一个文件

1.2 安装Hadoop
以上的内容核实无误后就可以进行Hadoop的安装了,解压安装包指令为:tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/
安装tree指令文件:rpm -ivh tree-1.6.0-10.el7.x86_64.rpm
程序执行后的结果可以通过查看training文件夹下内容进行查看
至此Hadoop和tree都已经安装完成,那么就可以直接通过指令查看Hadoop的文件目录结构,具体的指令为:tree -d -L 3 hadoop-2.7.3/ 其中-d表示查看目录,-L表示查看深度,3表示3层,最后的输出结果为

1.3 Hadoop环境变量配置
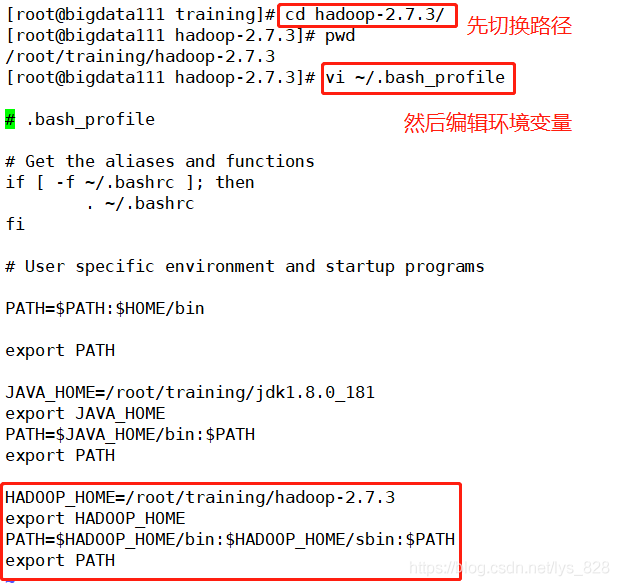
既然是安装在Linux上的软件,为了方便使用,环境变量的设置必不可少。之前已经配置好了Java的环境变量,这里就是同样的操作,在Java环境变量之后追加Hadood的环境变量,代码指令和操作如下
-
切换路径:
cd hadoop-2.7.3/ -
编辑环境变量:
vi ~/.bash_profileHADOOP_HOME=/root/training/hadoop-2.7.3 export HADOOP_HOME PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export PATH -
环境变量生效:
source ~/.bash_profile -
环境变量检验:
echo $HADOOP_HOME
然后是配置环境变量生效,进行echo检验

1.4 Hadoop主要脚本命令
开启服务:
- Hadoop启动进程:
start-all.sh(包含了启动HDFS和yarn) - 启动HDFS:
strat-dfs.sh(对应NameNode、DataNode、SecondaryNameNode) - 启动yarn:
start-yarn.sh(对应Nodemanager、ResourceManager)
关闭任务,将上面的start换成stop即可
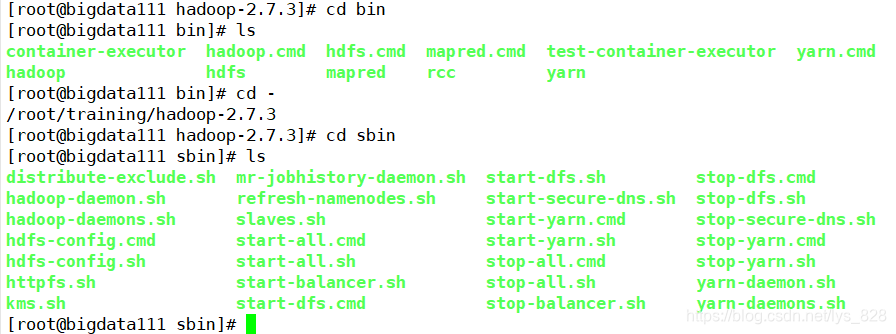
还有其它的一些命令,可以直接通过查看bin文件夹和sbin文件夹得知(具体的一些命名在之后搭建完环境,再进行讲解)
2 本地模式搭建
本地模式的特点:
(1)没有HDFS、也没有Yarn
(2)只能测试MapReduce程序,作为一个普通的Java程序
(3)处理的数据是本地Linux的文件
(4)一般用于开发和测试
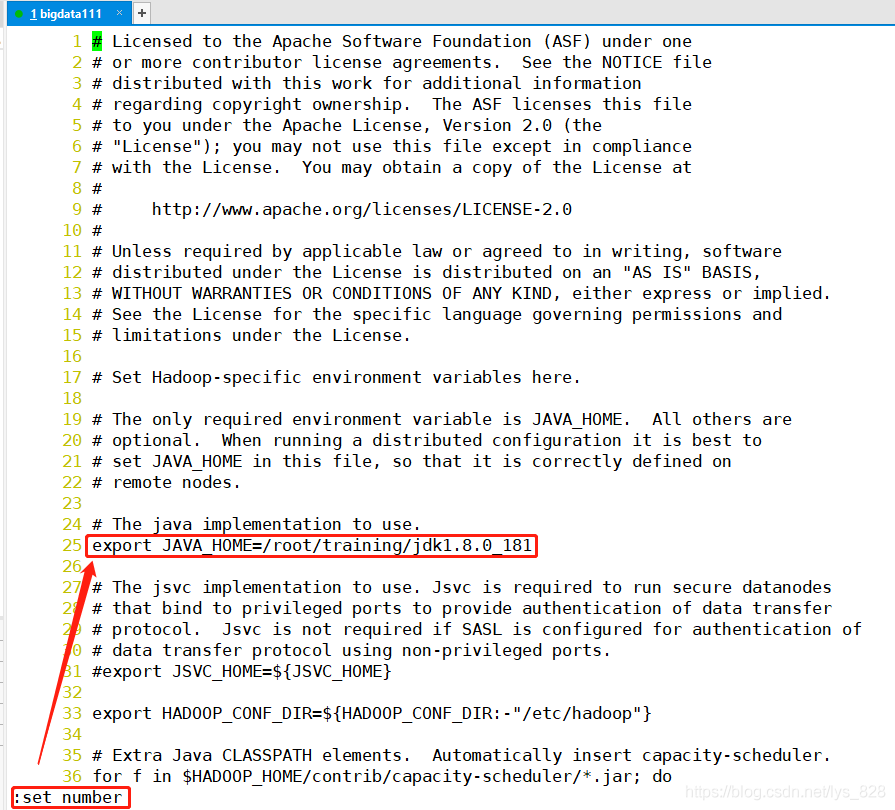
本地模式的配置:只需要修改hadoop-env.sh参数文件中的JAVA_HOME的配置参数,具体执行代码:
- 先将路径转到根目录下:
cd ~ - 然后计入hadoop路径下:
cd training/hadoop-2.7.3/etc/hadoop/ - 核实文件是够存在:
ls hadoop-env.sh - 编辑文件:
vi hadoop-env.sh - 打开行号:
:set number<Enter> - 输入要修改的内容:
export JAVA_HOME=/root/training/jdk1.8.0_181
修改地方如下,核实无误后退出编辑器
回到窗口界面,之前输入的指令如下

至此本地的模式就配置完成了,接着执行一下计数程序看看。首先要在本地模式需要有准备数据,由于本地模式不支持HDFS和yarn,所以最终读取文件和存放数据的文件均在本地的Linux系统中

运行完毕后,查看一下生成的文件,如下,最后也是完成了计数的功能
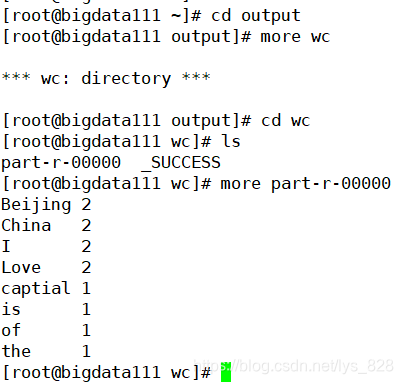
至此本地模式的配置安装以及使用就梳理到此结束,只需要修改一个文件中的配置参数即可

3 伪分布模式搭建
由于本地模式功能有限,所以配置起来很简单,除此之外功能越多的模式配置项就会越复杂。对于伪分布模式的特点梳理如下:(需要是在本地模式基础之上)
特点:(1)在单机上,模拟一个分布式的环境
(2)具备Hadoop的所有的功能
HDFS:NameNode、DataNode、SecondaryNameNode
Yarn:ResourceManager、NodeManager
(3)用于开发和测试
需要配置的信息如下:(基于本地模式之上,第一条的配置就默认已经完成了)
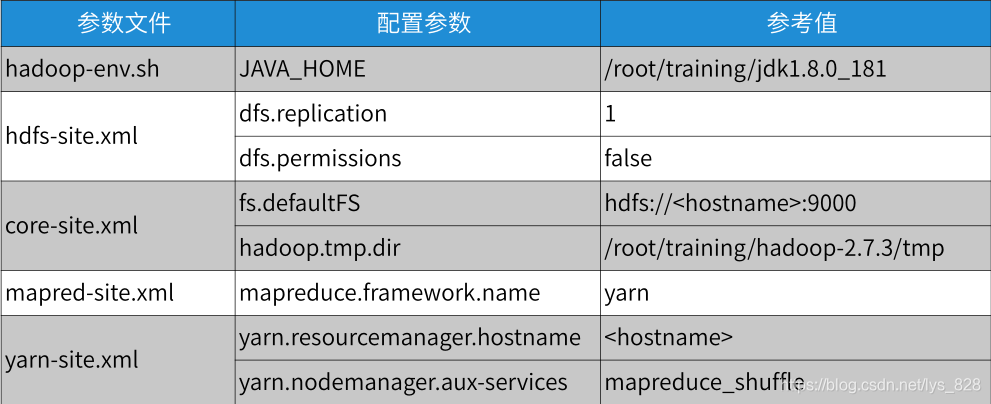
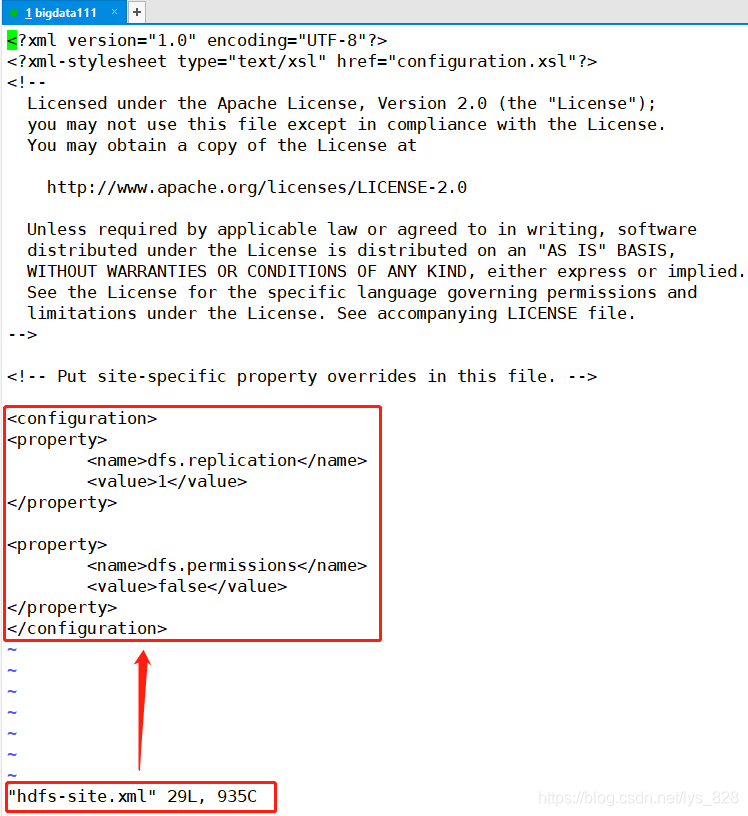
接下来就是配置其他文件中的参数,首先进行hdfs-site.xml文件的配置,配置的具体代码如下:
<!--数据块的冗余度,默认是3-->
<!--一般来说,数据块冗余度跟数据节点的个数一致,最大不超过3-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--禁用了HDFS的权限检查-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
上机操作如下:
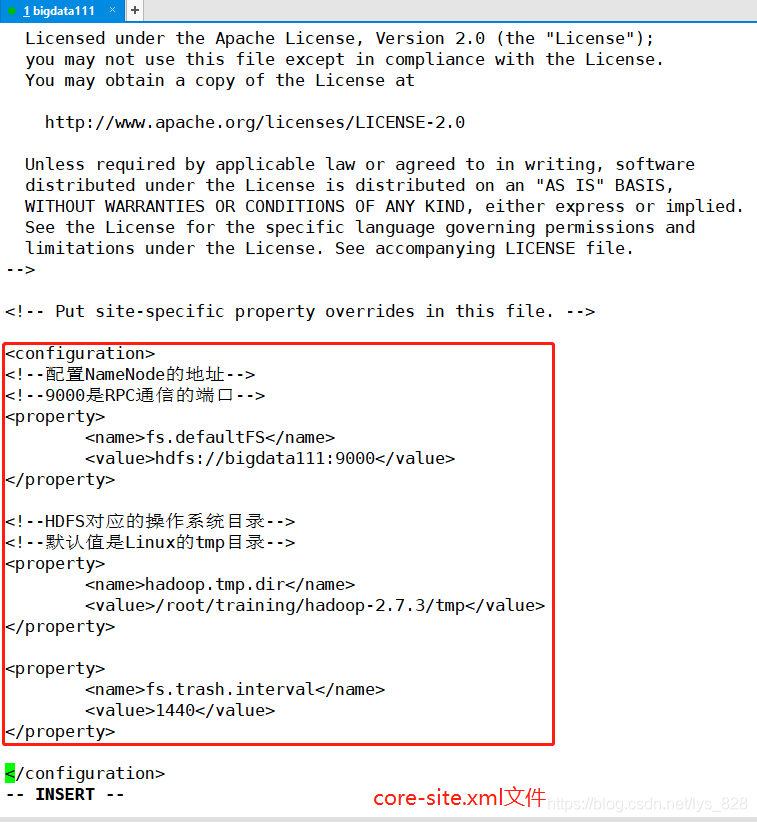
然后进行core-site.xml文件的配置,具体的代码内容如下:
<!--配置NameNode的地址-->
<!--9000是RPC通信的端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata111:9000</value>
</property>
<!--HDFS对应的操作系统目录-->
<!--默认值是Linux的tmp目录,需要提前创建-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.7.3/tmp</value>
</property>
上机操作如下:
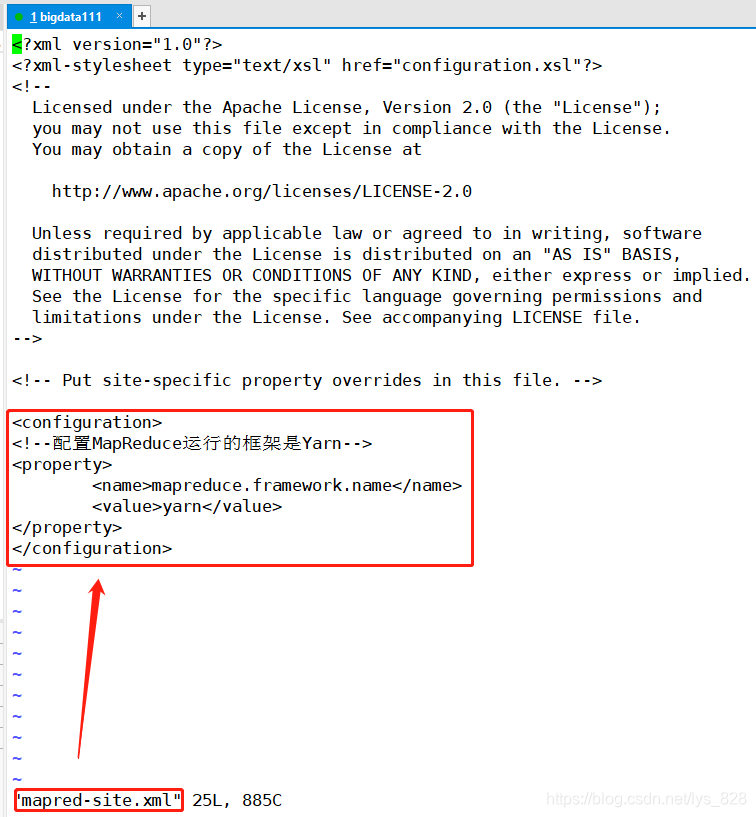
支持HDFS相关配置的两个文件全部参数就配置完成,接下来就是对yarn配置的两个文件进行处理,首先进行mapred-site.xml文件进行配置,但是这个文件默认没有的,需要提前创建,只提供了一个模块文件,所以根据模板进行复制一份重命名即可

然后要添加的内容如下:
<!--配置MapReduce运行的框架是Yarn-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
上机操作如下:
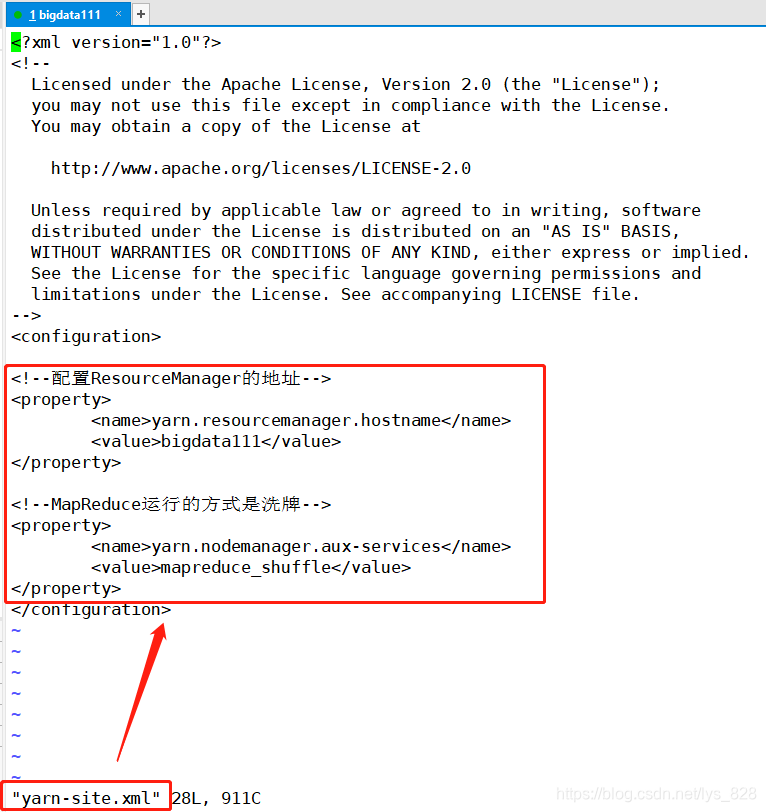
最后一个配置文件就是yarn-site.xml文件,需要配置的内容如下:
<!--配置ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata111</value>
</property>
<!--MapReduce运行的方式是洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
上机操作如下:
至此需要配置的四个文件全部配置完成,剩下就是对应NameNode进行格式化处理:hdfs namenode -format,然后在取启动Hadoop: start-all.sh,操作输出如下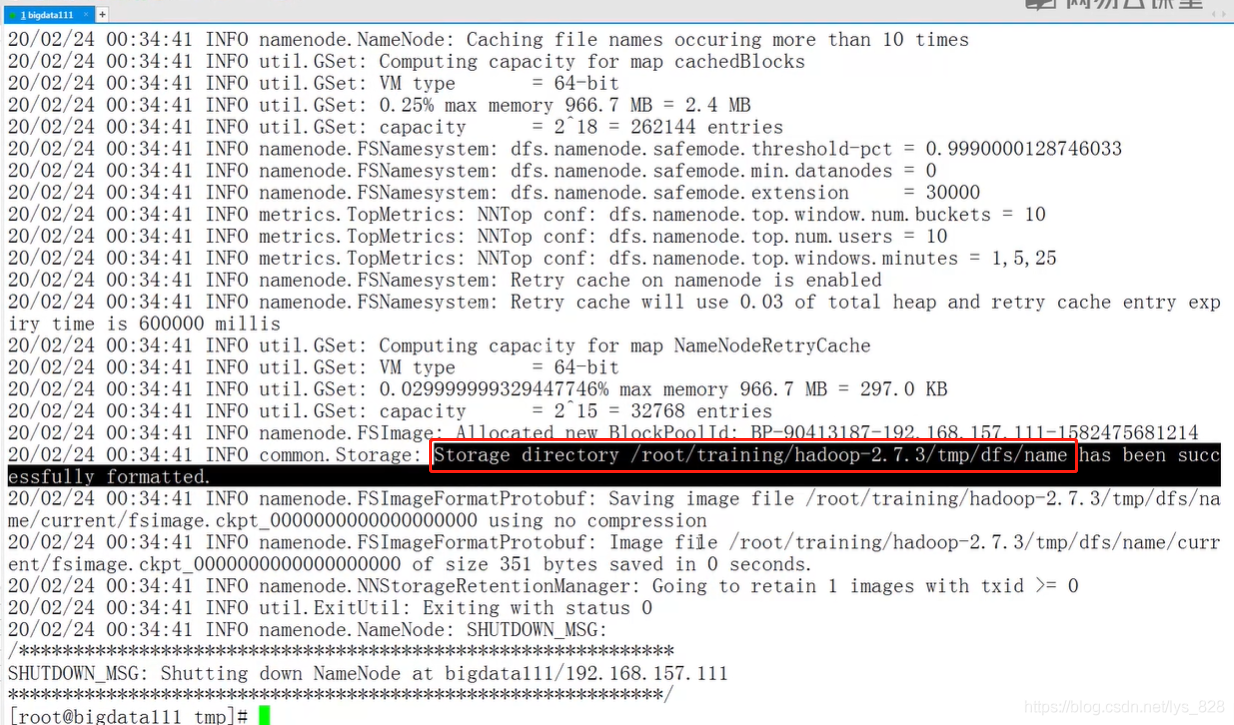
然后就会出现一个情况就是密码登录的问题,由于刚刚是第一次启动,运行Hadoop就需要进行密码的输入,一共需要输入四次密码(还有三次yes)
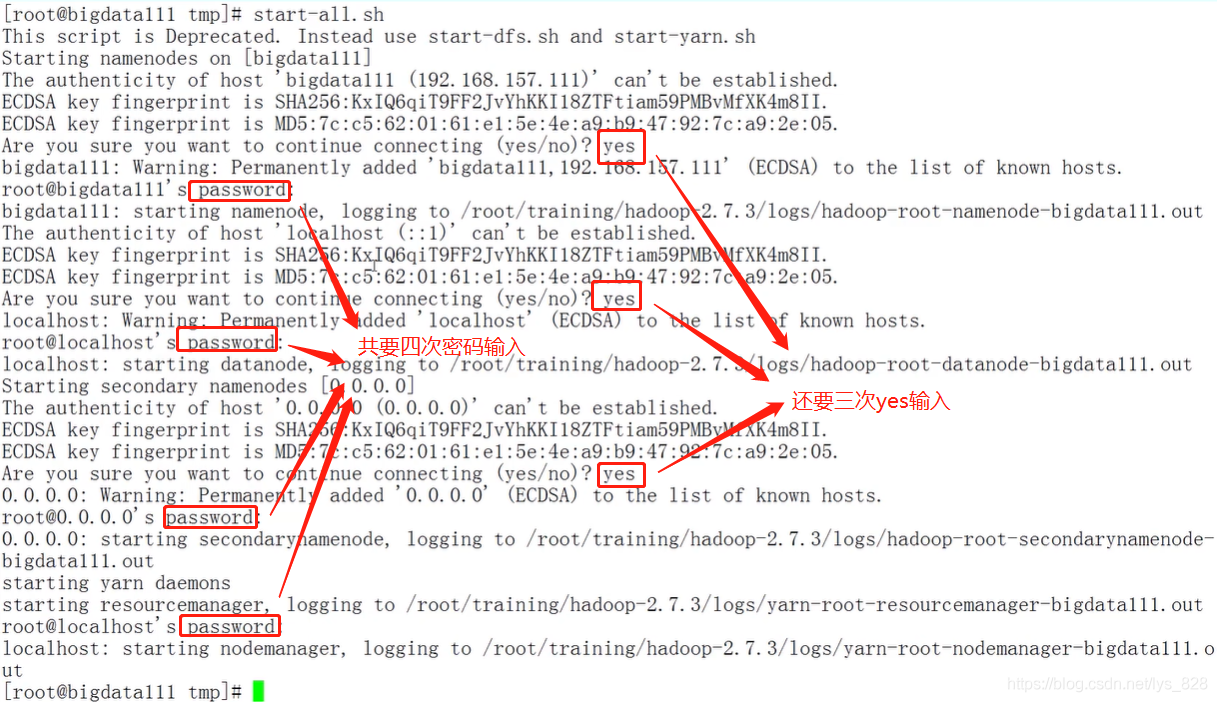
接下来就是通过查看Java进程看看Hadoop是否正常启动,如果正常启动就运行一下MapReduce程序跑一下计数程序

最后就是核实一下最终生成的文件中的内容(核实无误后就代表着伪分布模式搭建成功)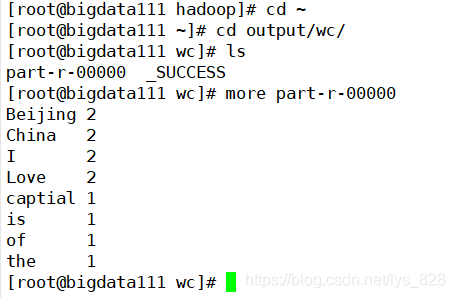
然后就是结束服务,只需要将最开始的start改成stop即可,一共也是需要输入4次密码才能进行关闭

目前还仅仅是一台虚拟机,当集群中的机器多了时候,那么每台虚拟机启动Hadoop都要进行四次密码登录或者退出的话就太影响开发效率,免密登录的需求就很明显要提上日程了,所以接下来要解决的就是免密登录
免密登录的原理梳理如下,其中执行的代码顺序为
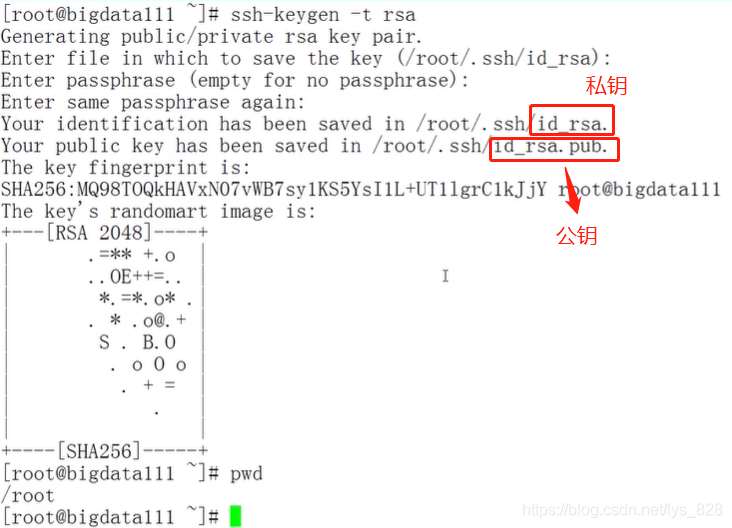
- 当前机器产生公钥和私钥:
ssh-keygen -t rsa - 把公钥提交给给ServerB(这里就是自己):
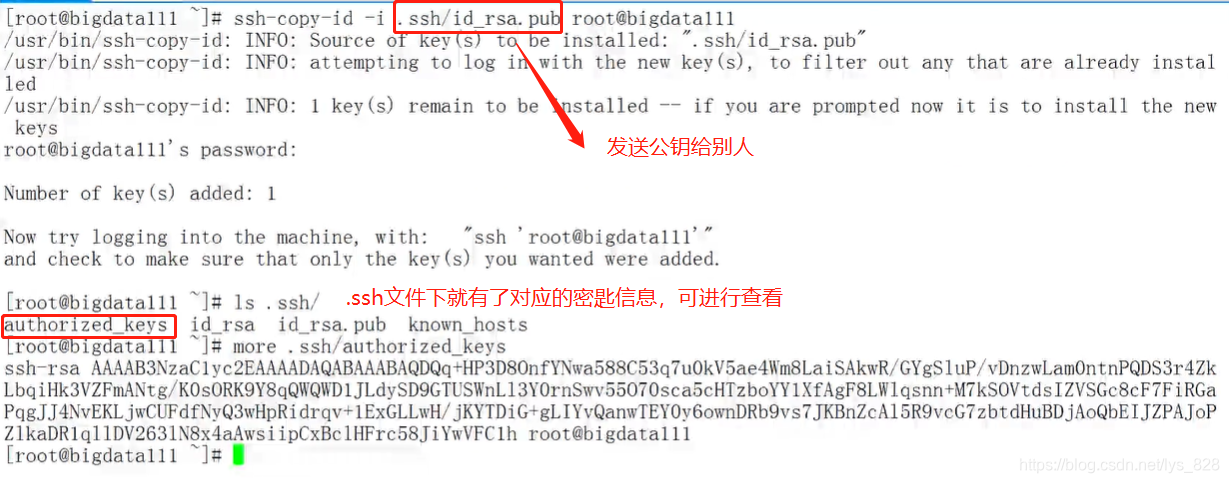
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata111
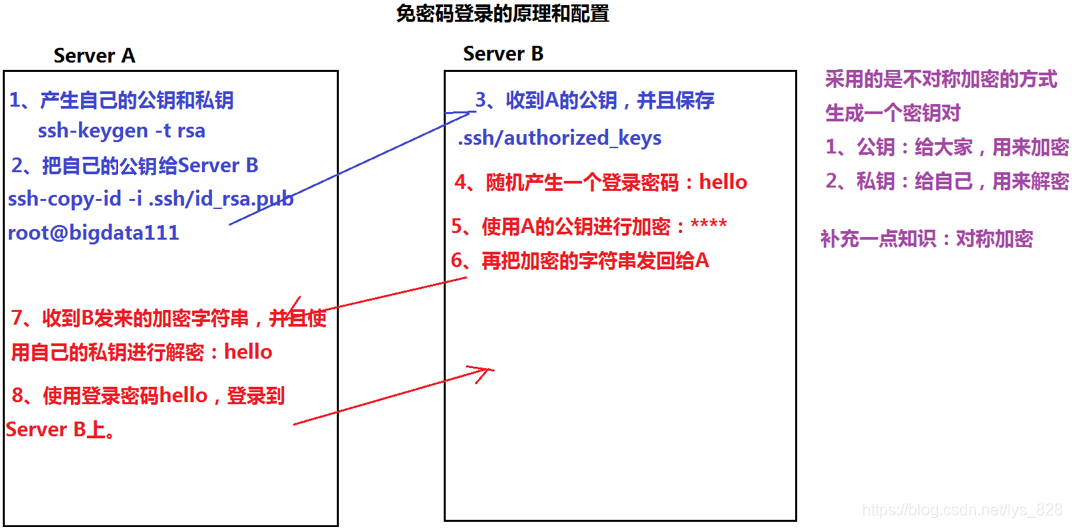
具体的上级操作如下:(先生成公钥和私钥)
然后在把公钥传给另外的服务端,就会在.ssh文件夹中保有别的服务端的密码信息
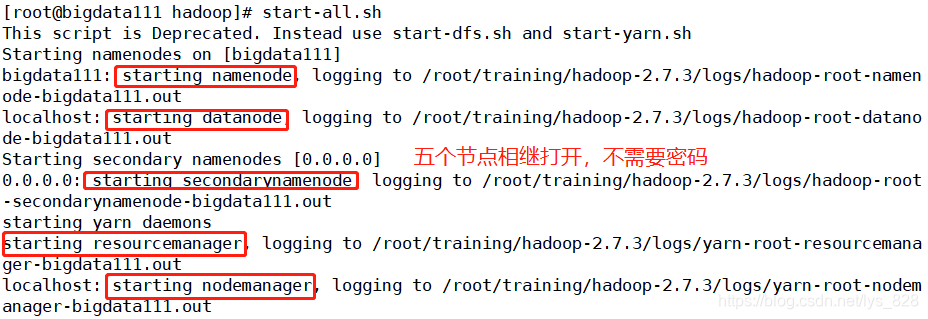
至此免密码登录设置就完成了,可以重新启动Hadoop验证一下
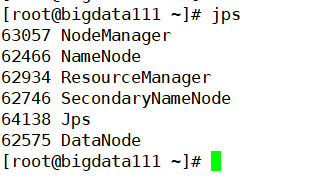
最后就是查看一下Java进程(核实是否五个节点都在进程中)
然后再看一下关闭服务是否需要密码(核实不需要密码。至此免密的设置完美结束)
4 全分布模式搭建
全分布模式的特点介绍如下
特点: (1)真正的分布式环境,用于生产
(2)具备Hadoop的所有功能:HDFS、Yarn
(3)3台机器
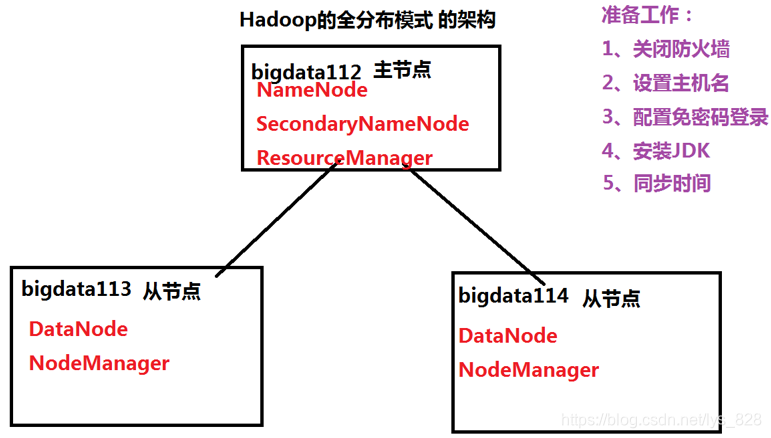
前面的博客中也介绍过,如果要搭建全分布模式Hadoop模式,至少需要三台虚拟机,这里就以bigdata112、bigdata113、bigdata114三台机子为例进行环境搭建。
4.1 准备工作
三台机器的架构如下,具体按照5步进行配置
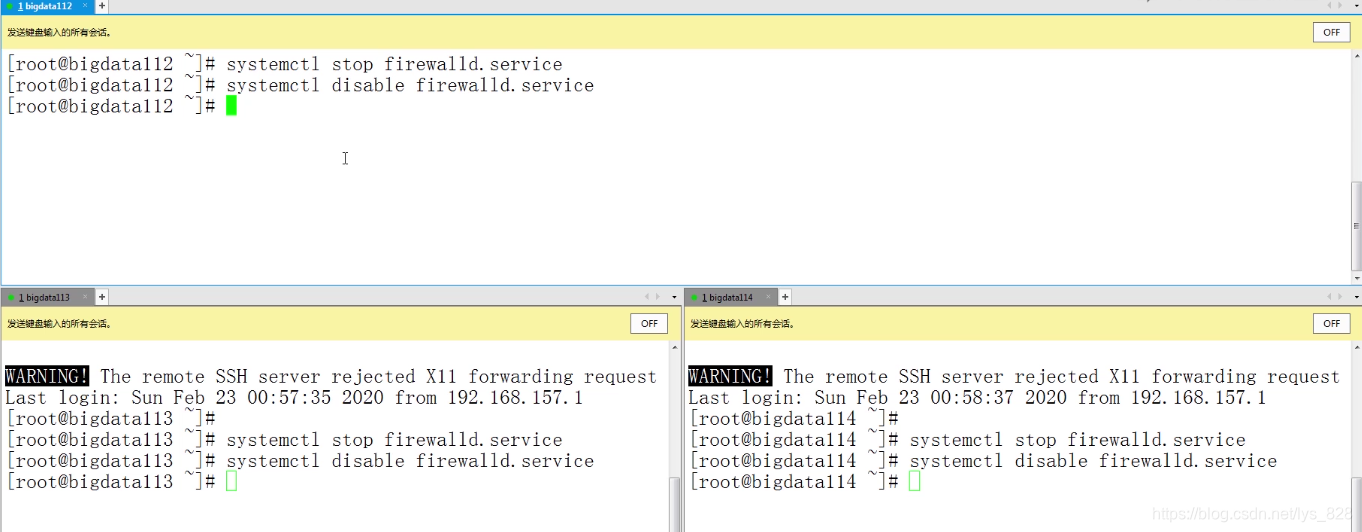
(1)首先第一步进行关闭防火墙,由于是对三台虚拟机同时进行操作,这时候就体现使用Xshell的优势了,在“工具”菜单栏选择“发送键输入到所有会话”,然后输入关闭防火墙的指令
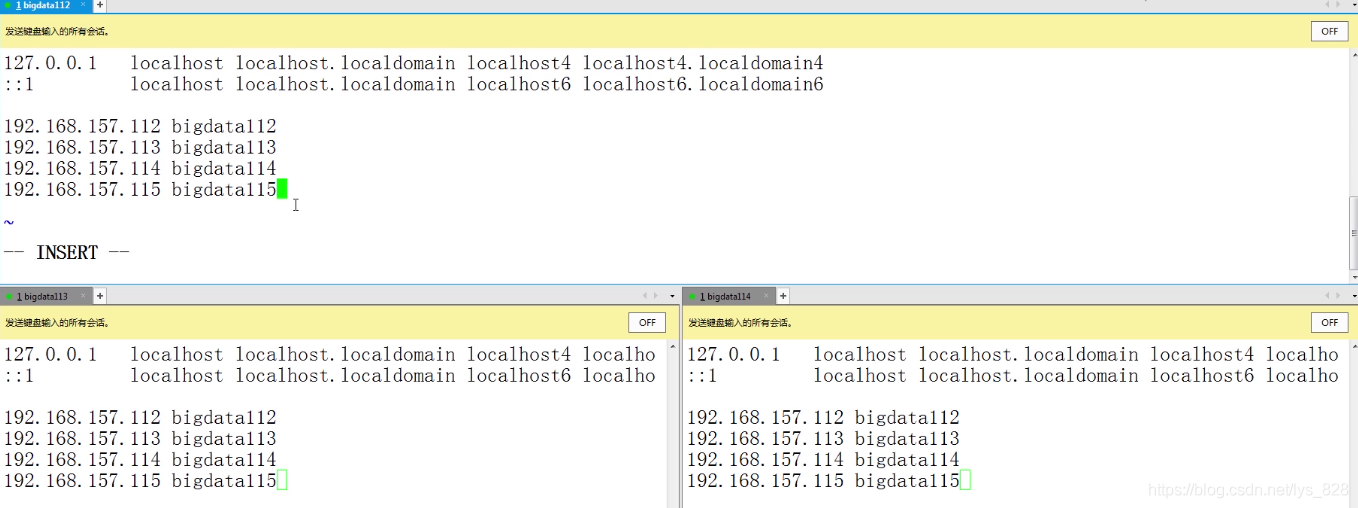
(2)第二步,设置主机名和ip地址,编辑etc/hosts文件,如下(顺带把bigdata115的也设置了,注意这里的ip地址要以自己的为主)
设置完之后就可以进行ping的操作,看看每台机器能否联通(下面举例是ping bigdata112,接下来还要ping剩下的几台机器,都确保无误后,主机名和ip地址就设置完成了)
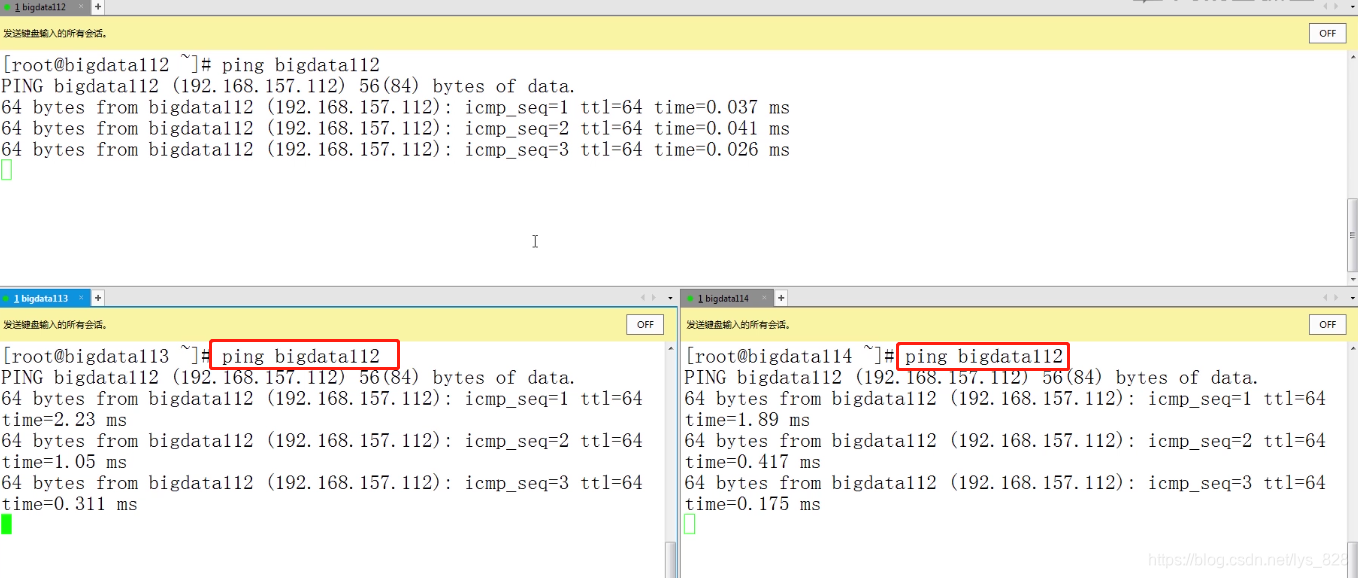
(3)设置免密码登录,首先查看一下三台机器上面密码的信息,通过查看.ssh文件夹,三台机器都没有设置免密码登录,然后三台机器同时生成公钥和私钥
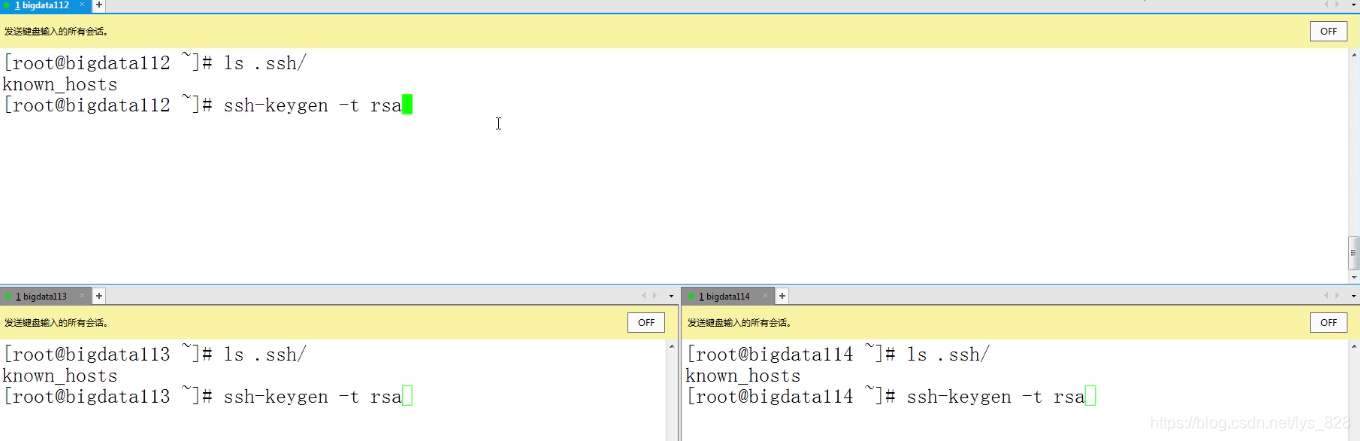
然后再查看一下秘钥是否已经生成,如果生成就把公钥发送给对方
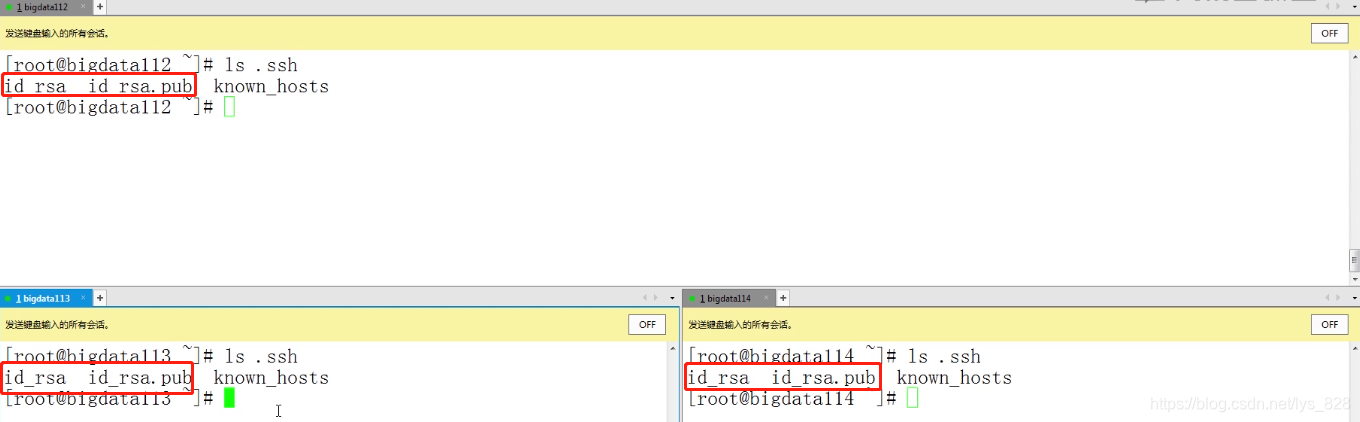
接着就把公钥发送给各个机器,这个演示发送到bigdata112,剩下的机器也是一样,修改最后一个数字再次输入回车即可
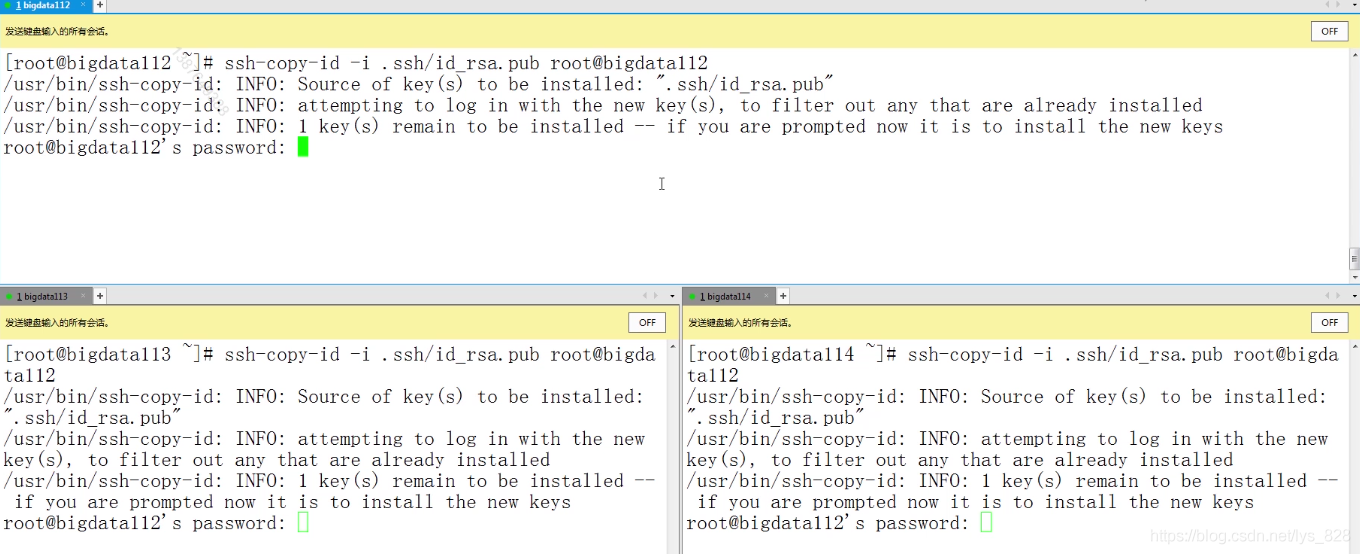
免密成功验证,就是通过ssh 主机名,看看是否能够直接访问(核实无误,bigdata114也可直接访问)
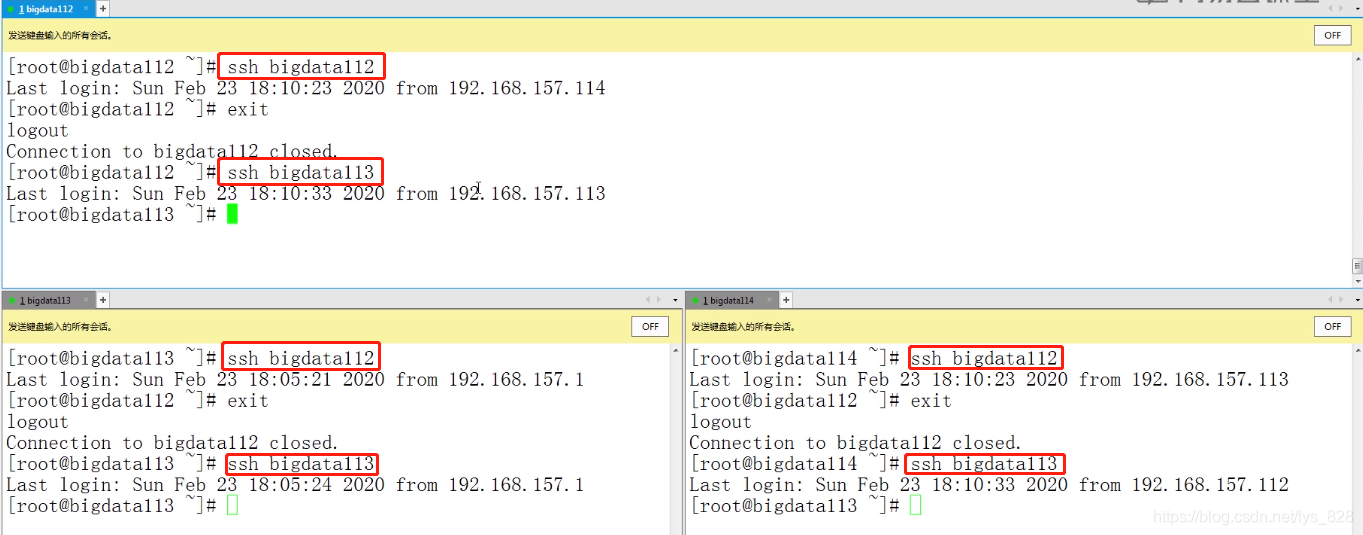
(4)Java JDK安装,这里和之前的操作一样,还有添加环境变量,这里就不再赘述了,直接验证安装后的结果(安装的软件都放在training文件中,顺带安装一下storm,之后的课程中会介绍如何安装使用)
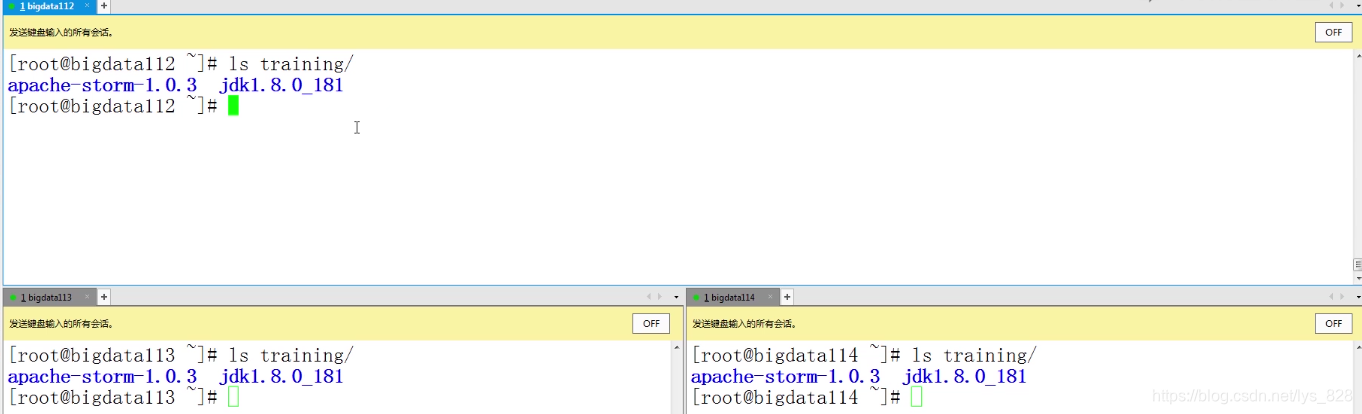
使用echo看看环境变量是否设置完毕
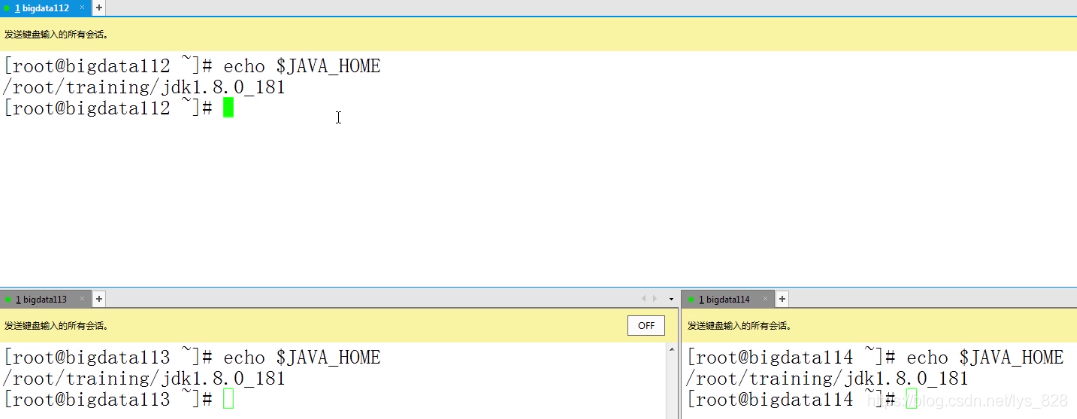
(5)最后一步就是同步各台机子的时间了,保证到时候传递到Hadoop上执行程序是同步进行,执行代码:date -s xxxx-xx-xx
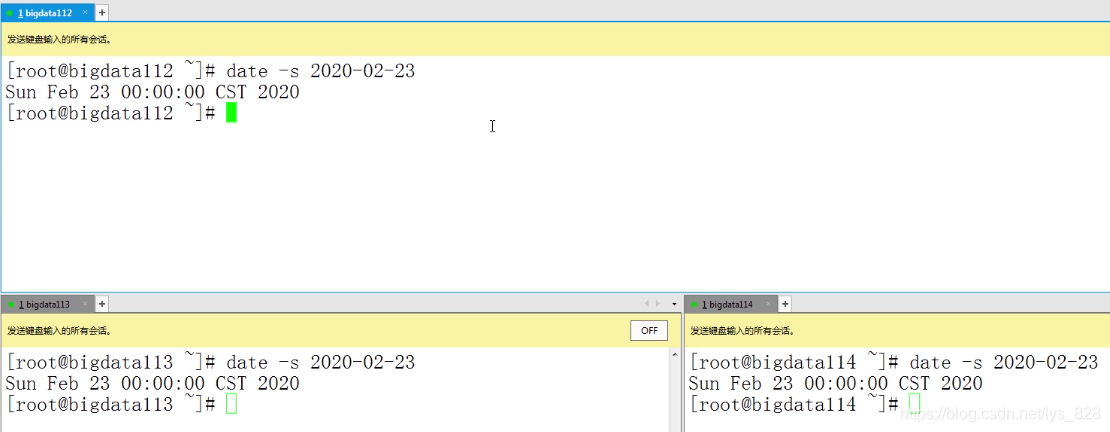
4.2 Hadoop部署
首先对于Hadoop的解压安装以及环境变量的配置是需要三台机器同步设置(如果无法做到同步也可以单独配置)
(*)解压安装包,配置环境变量
tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/
HADOOP_HOME=/root/training/hadoop-2.7.3
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
接下来就不需要进行三台机器的同步安装了,由于是要以bigdata112作为主节点,只需要配置一下这个机器上的Hadoop的其余文件就可以了,配置完成后直接将文件复制到剩下的两台机器上
bigdata112的配置Hadoop的配置和之前的伪分布环境的搭建基本上是类似,下面就是基本上完全照抄前面的配置。需要注意关于冗余度的设置,一般是要和DataNode数量保持一致,但是不要超过3,由于存在2个DataNode,所以这里
hdfs-site.xml文件中的dfs.replication值设置为2;core-site.xml文件的主节点改成bigdata112;tmp文件夹还是需要提前进行创建yarn-site.xml文件中配置ResourceManager的地址为bigdata112
以下只在bigdata112上进行设置
(*)仿照伪分布的模式进行编写
hadoop-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_181
hdfs-site.xml
<!--数据块的冗余度,默认是3-->
<!--一般来说,数据块冗余度跟数据节点的个数一致,最大不超过3-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--禁用了HDFS的权限检查-->
暂时先不配置
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
core-site.xml
<!--配置NameNode的地址-->
<!--9000是RPC通信的端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata112:9000</value>
</property>
<!--HDFS对应的操作系统目录-->
<!--默认值是Linux的tmp目录,需要提前创建-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.7.3/tmp</value>
</property>
mapred-site.xml:这个文件默认没有,需要先cp一下
<!--配置MapReduce运行的框架是Yarn-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
<!--配置ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata112</value>
</property>
<!--MapReduce运行的方式是洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
除了以上的配置之外还要单独设置一个slaves文件,用以指定定从节点的地址:bigdata113,bigdata114

至此所有的配置就完成了,然后对NameNode进行格式化,也就还是在bigdata112中进行,代码指令:hdfs namenode -format(和伪分布环境搭建一样,使用之前都需要进行格式化)
然后再将bigdata112中的文件直接复制到剩下两个机器中(在bigdata112的命令窗口执行)
scp -r hadoop-2.7.3/ root@bigdata113:/root/training
scp -r hadoop-2.7.3/ root@bigdata114:/root/training
上机操作如下:
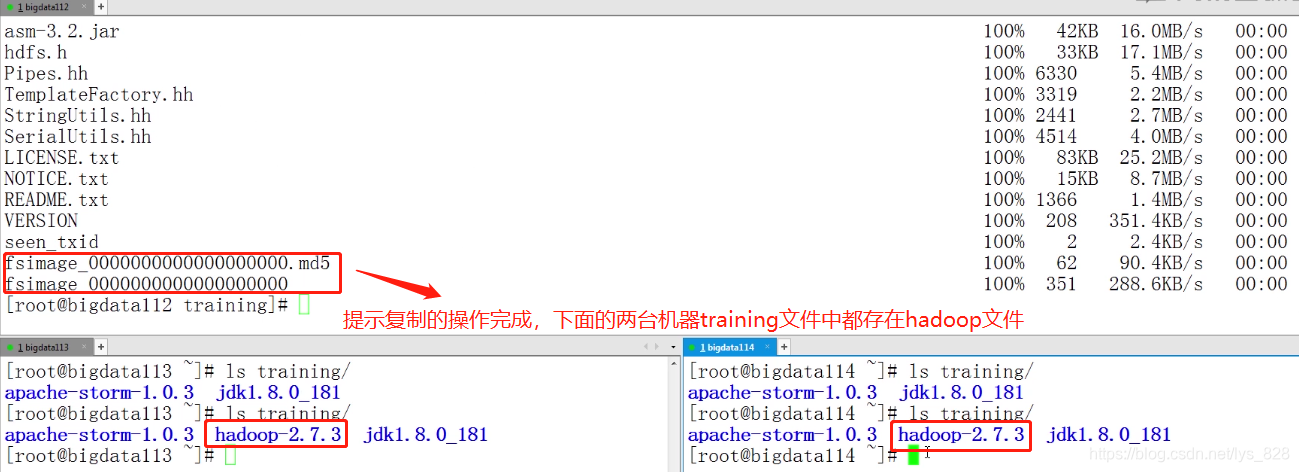
4.3 hadoop启动
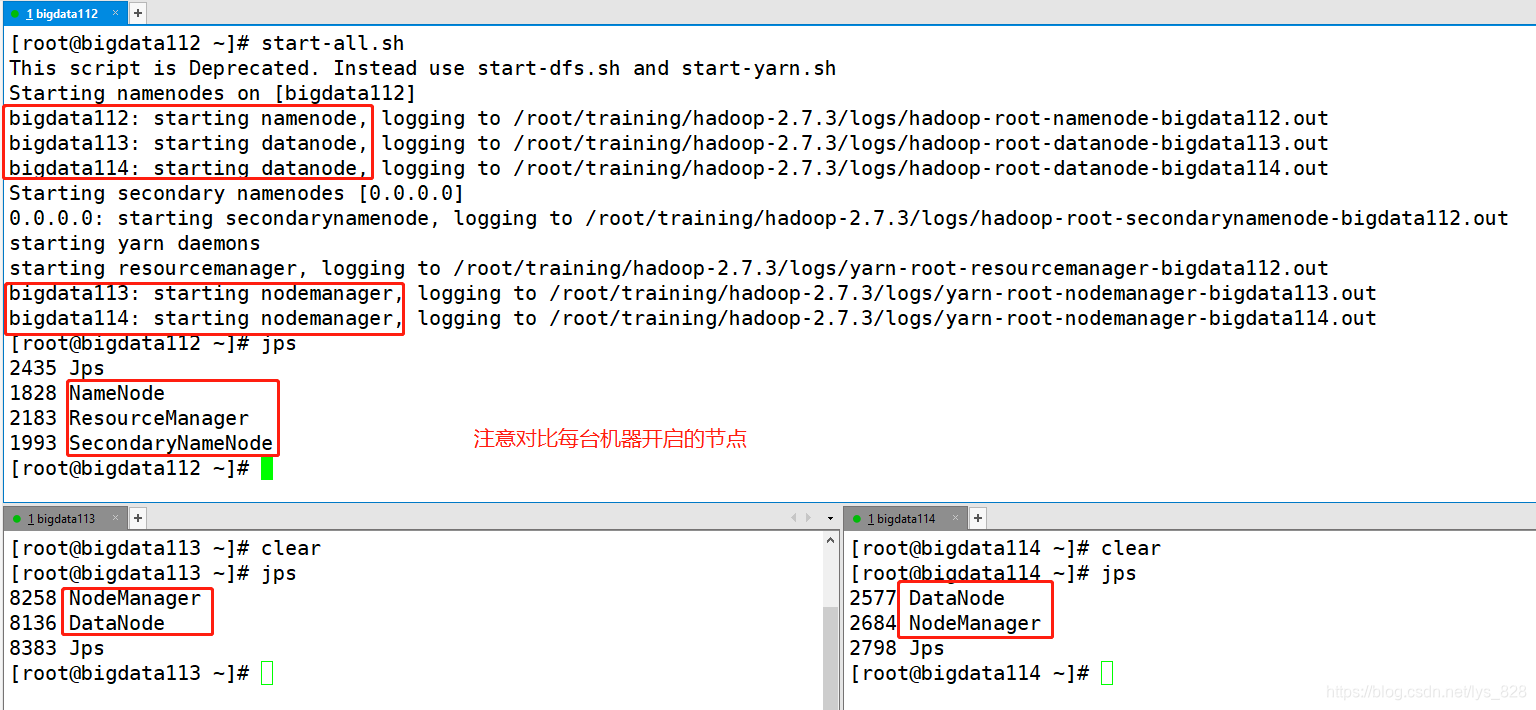
经历了这么多的磨难终于把全分布的模式部署完毕了,然后在bigdata112上面进行启动,输出结果如下(可以发现最终的各个机器开启的节点和最初设计的架构是一模一样)
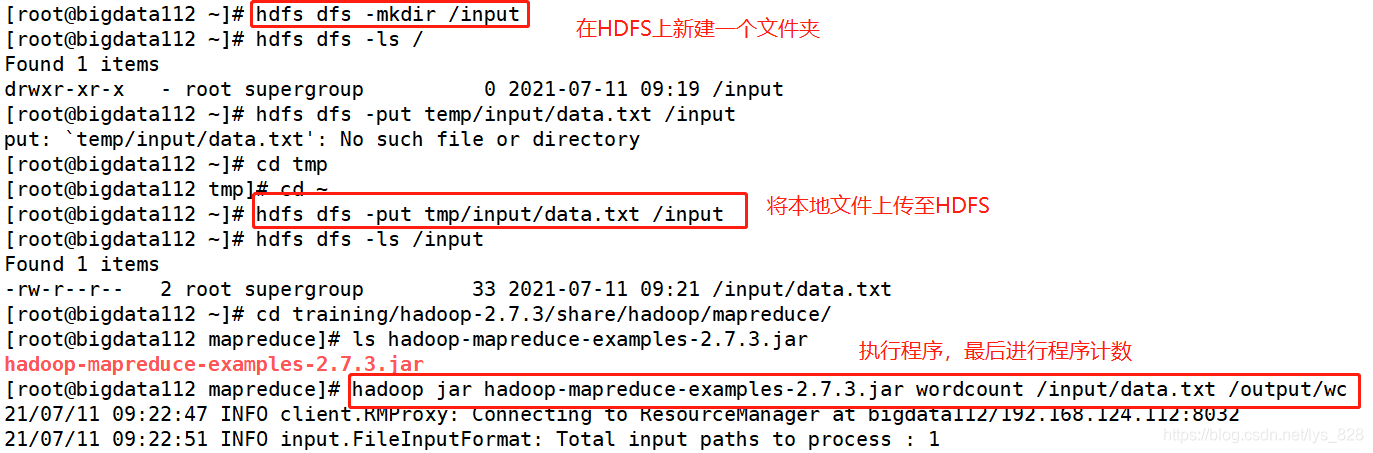
然后就要进行一个简单的计数程序的小测试了,首先将本地的文件上传到HDFS上,然后在调用jar包进行计数,代码如下
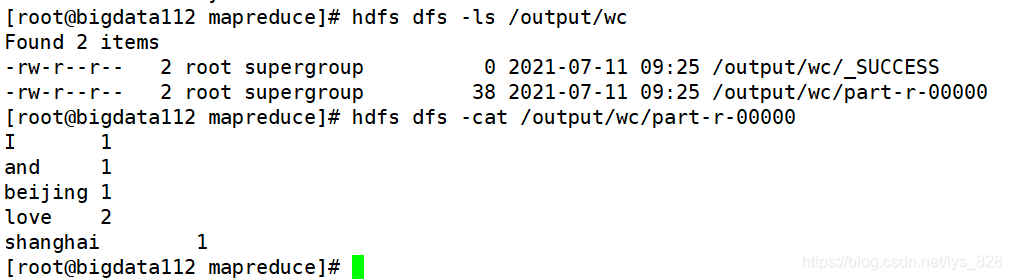
最后核实一下生成文件的内容,核实无误后,说明全分布环境部署成功了
至此,完结撒花了✿✿ヽ(°▽°)ノ✿,接下来就要介绍HDFS的体系架构。