DragGAN 完全自由 P 图指南
在上篇中,树先生教大家如何正确部署 DragGAN 项目,实现自由拖拽式 P 图。
但可惜只能使用项目预置的一些图片,本篇教大家如何利用该项目自由编辑修改任何图片。
这里主要使用到 PTI 项目,可以将你自定义的图片训练成 StyleGAN 潜空间模型,从而实现任何图片的编辑修改。

环境准备
这里我们还是继续选择 AutoDL 云平台,使用 Python 3.8,CUDA 11.8 的镜像,这个镜像的环境满足项目要求。

下载源码
git clone https://github.com/danielroich/PTI.git
# 安装依赖
cd PTI && pip install -r requirements.txt
你肯定好奇,项目里没有 requirements.txt 文件呀?放心,我给你准备好了~
torch>=2.0.0
scipy
Ninja==1.10.2
gradio>=3.35.2
imageio-ffmpeg>=0.4.3
huggingface_hub
hf_transfer
pyopengl
imgui
glfw==2.6.1
pillow>=9.4.0
torchvision>=0.15.2
imageio>=2.9.0
dlib
wandb
lpips
下载预训练模型
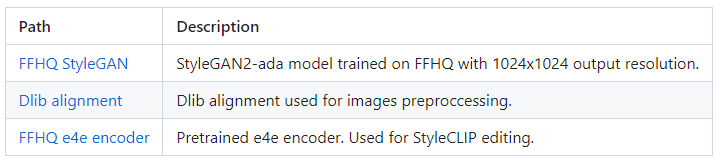
这里我们只要下载前 2 个即可,分别是 StyleGAN 的生成器文件 ffhq.pkl 和图片的预处理器文件 align.dat,下载完成后放到项目的 pretrained_models 目录下。
图片预处理
主要是完成原始图片人脸关键点检测工作,将你想要编辑的图片上传到项目的 image_original 目录下,然后将该目录的绝对路径写入 utils/align_data.py 文件中。
if __name__ == "__main__":
pre_process_images(f'/root/autodl-tmp/PTI/image_original')
同时修改 configs/paths_config.py 文件参数。
### Input dir, where the images reside
input_data_path = '/root/autodl-tmp/PTI/image_processed'
然后运行。
cp utils/align_data.py .
python align_data.py
使用 PTI 进行 GAN 反演
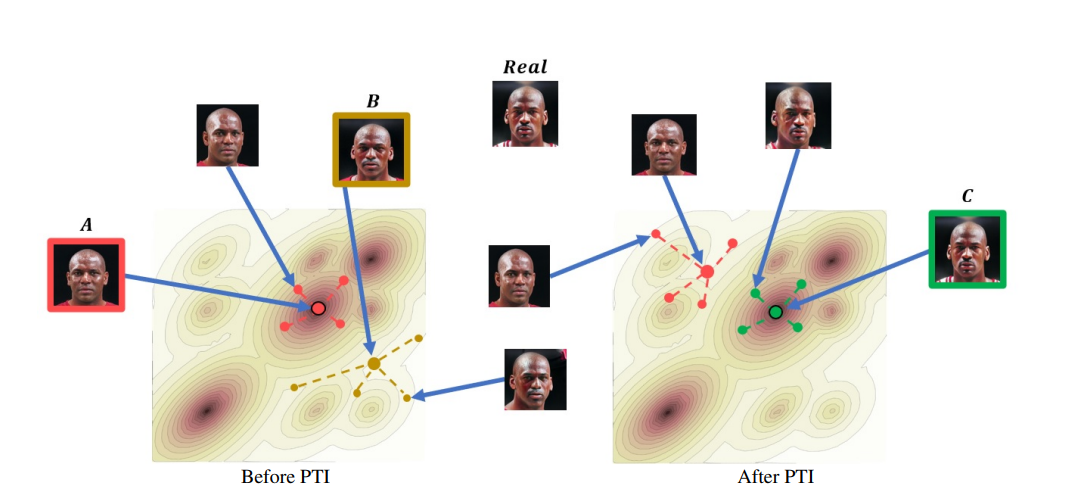
反演是指将一个图像映射到生成模型的潜空间中,然后通过调整潜空间向量来修改图像的外观。通过这种方式,可以实现对图像的各种编辑操作,例如改变姿势、修改外貌特征或添加不同的风格。通过编辑潜空间,可以实现对图像的高级编辑,同时保持图像的真实性和准确性。
本项目中通过如下命令即可完成图像反演工作。
cp run_pti.py .
python run_pti.py
保存为 DragGAN 可识别的模型文件
上述经过 PTI 反演后的文件不是 DragGAN 可识别的模型文件格式,所以这里额外处理一下,将 pt 文件转换成 pkl 文件格式,转换脚本呈上。
import os
import sys
import pickle
import numpy as np
from PIL import Image
import torch
from configs import paths_config, hyperparameters, global_config
def load_generators(model_id, image_name):
with open(paths_config.stylegan2_ada_ffhq, 'rb') as f:
old_G = pickle.load(f)['G_ema'].cuda()
with open(f'{paths_config.checkpoints_dir}/model_{model_id}_{image_name}.pt', 'rb') as f_new:
new_G = torch.load(f_new).cuda()
return old_G, new_G
def export_updated_pickle(new_G,model_id):
print("Exporting large updated pickle based off new generator and ffhq.pkl")
with open(paths_config.stylegan2_ada_ffhq, 'rb') as f:
d = pickle.load(f)
old_G = d['G_ema'].cuda() ## tensor
old_D = d['D'].eval().requires_grad_(False).cpu()
tmp = {}
tmp['G'] = old_G.eval().requires_grad_(False).cpu()# copy.deepcopy(new_G).eval().requires_grad_(False).cpu()
tmp['G_ema'] = new_G.eval().requires_grad_(False).cpu() # copy.deepcopy(new_G).eval().requires_grad_(False).cpu()
tmp['D'] = old_D
tmp['training_set_kwargs'] = None
tmp['augment_pipe'] = None
with open(f'{paths_config.checkpoints_dir}/stylegan2_custom_512_pytorch.pkl', 'wb') as f:
pickle.dump(tmp, f)
if __name__ == "__main__":
# checkpoints 目录下 pt 文件名的一部分
model_id = "BWISZTGIKPZT"
# 图片名
image_name = "myimg"
generator_type = image_name
old_G, new_G = load_generators(model_id, generator_type)
export_updated_pickle(new_G,model_id)
最后将 checkpoints 目录下生成的模型文件和对应的 embeddings 目录下的文件放入 DragGAN 项目的 checkpoints 目录下,然后重启 DragGAN,大功告成!
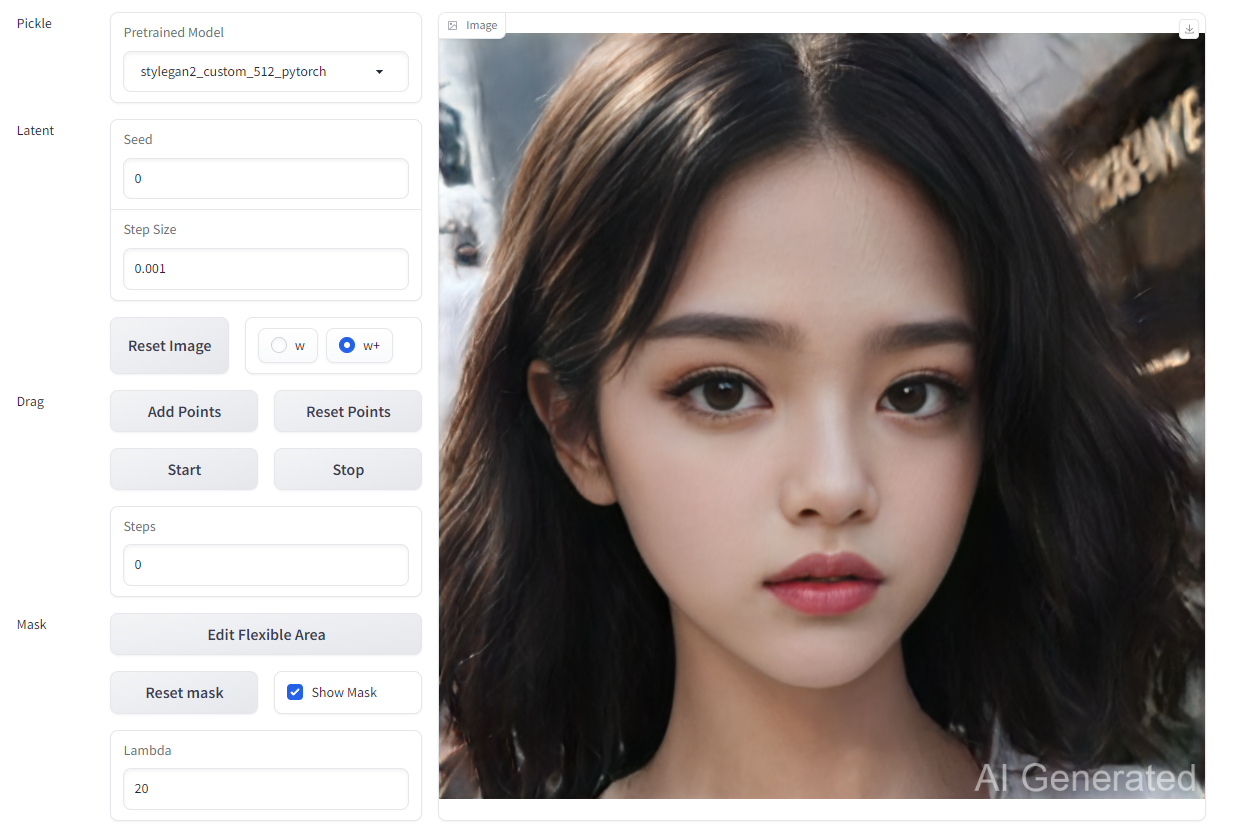
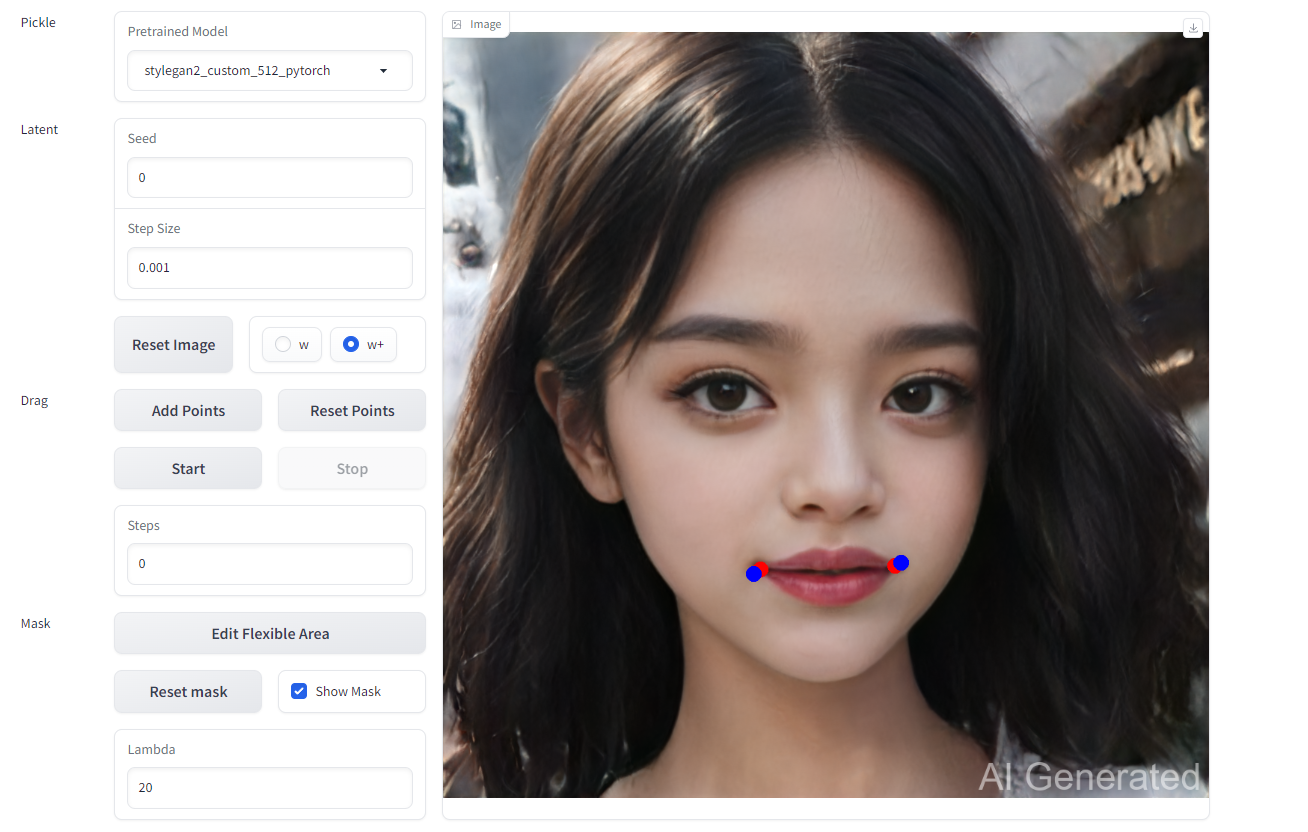
效果展示
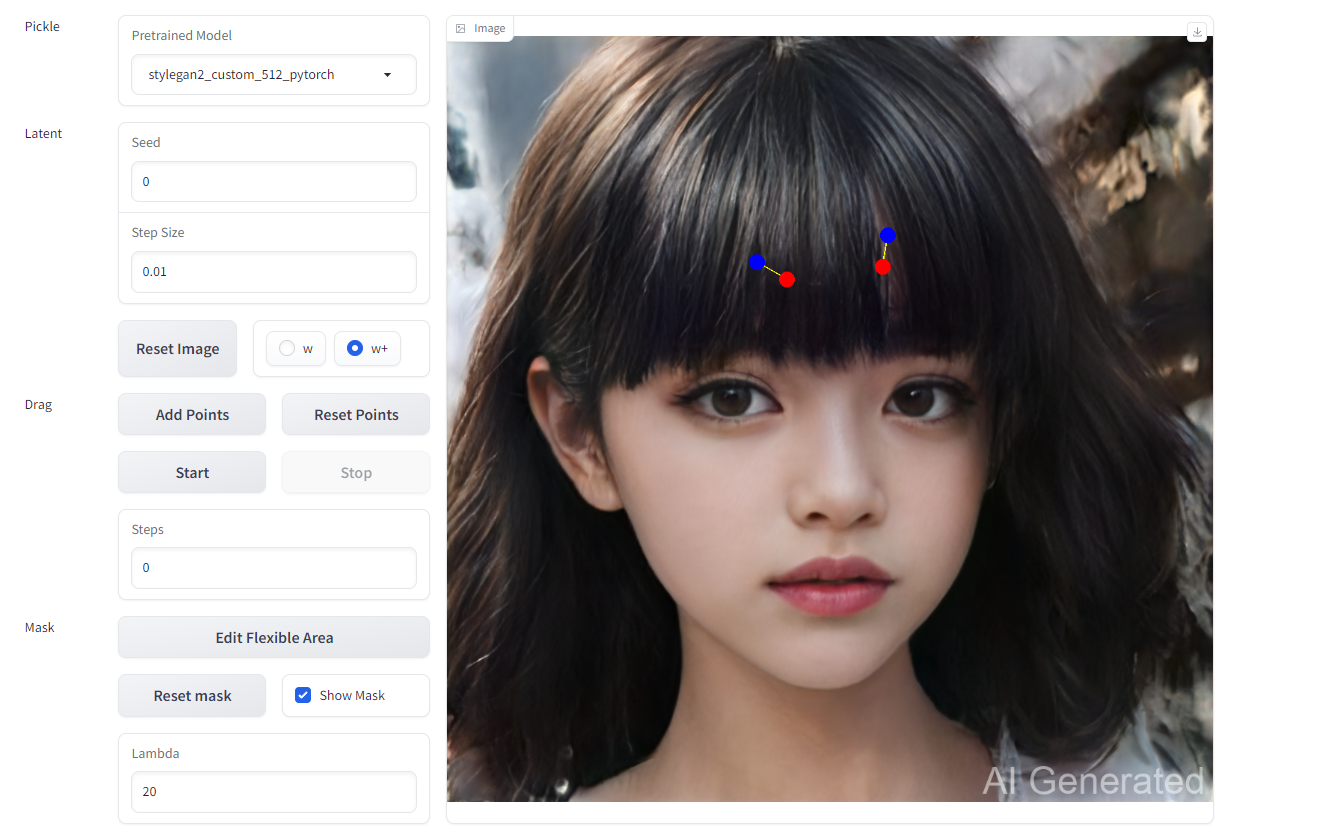
一键整合包
想必你看了上面这一通操作,心里已经默默打了退堂鼓,为了方便大家直接使用,我已经将上述步骤整合成 Jupyter Notebook 文档,一键即可运行,完成图像反演!
食用宝典: align.dat 放入项目 pretrained_models 目录下,visualizer_drag_gradio_custom.py 放入项目根目录下,ipynb 文件直接运行即可。

获取方式: 原文末尾处