基于大数据的农产品价格数据分析
接下来让我分享一下我们近期所完成的一个大数据农产品价格数据分析平台,主要是分为三部分来实现,后端:python+flask,爬虫:python,前端:vue。
环境:Ubuntu
虚拟机软件:VMware17
所用技术:Hadoop、Spark、Vue、Python,Mysql
所用语言:Python、Vue
本系统是基于 hadoop+spark+vue 为主要技术研发的,使用 Ubuntu 作为平台支持, 前端使用虚拟机浏览器,采用前后端分离开发的模式,提高开发效率,对此相关技术支 持很多并且已经很成熟,所以在技术可行性方面上没有任何问题。
大概功能流程图如下:
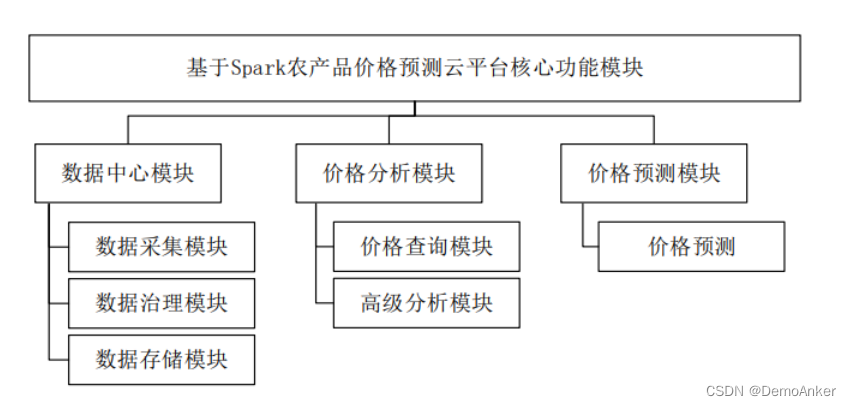
系统使用流程基本如下:首先先打开虚拟机进去,然后先启动hadoop和spark。然后就进入python虚拟环境然后就可以进行运行后端。
启动方法:
配置号网络后:就在里面打开一个终端,先运行Hadoop和spark启动代码如下:
hadoop启动:
start-all.sh
启动spark
/usr/local/spark/sbin/start-all.sh
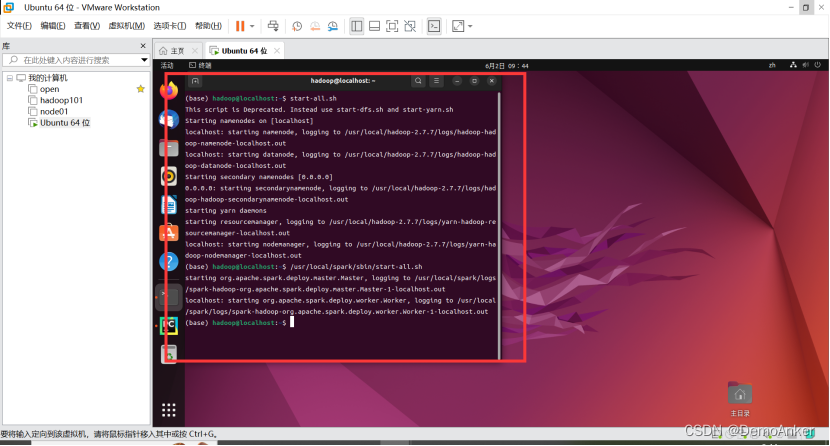
启动完后就去打开pycharm

在这里面,打开pycharm后就进行运行代码:
点击到这个文件:
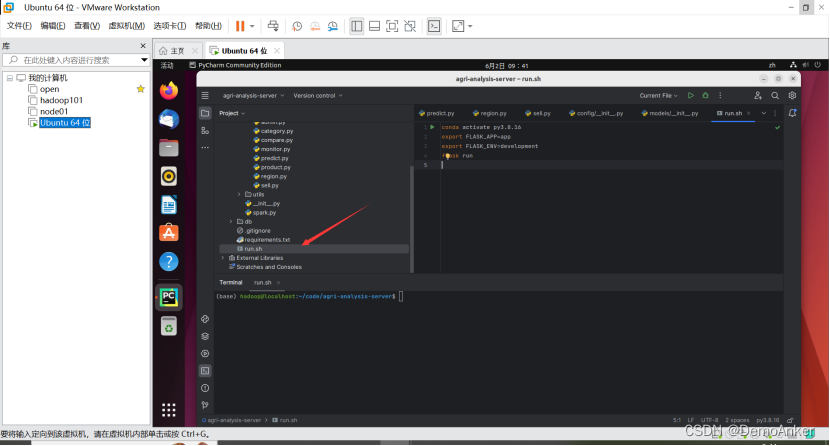
然后在下面的命令行启动py环境:conda activate py3.8
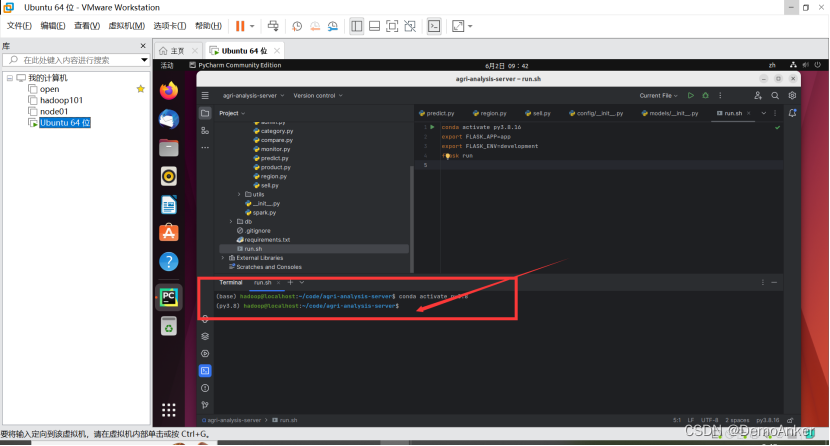
这样就是已经进入了
进入后就可以点击上面那个运行的三角形


这样的话就是运行成功了,然后就可以打开vscode,位置也是在
这个里面,打开vscode后就可以直接启动前端:npm run serve
然后前端启动成功后,直接点击那个运行成功的端口即可。
实现效果图大致如下:
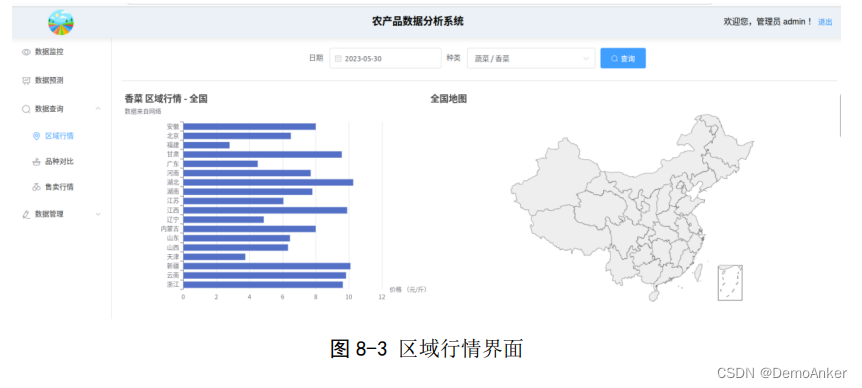
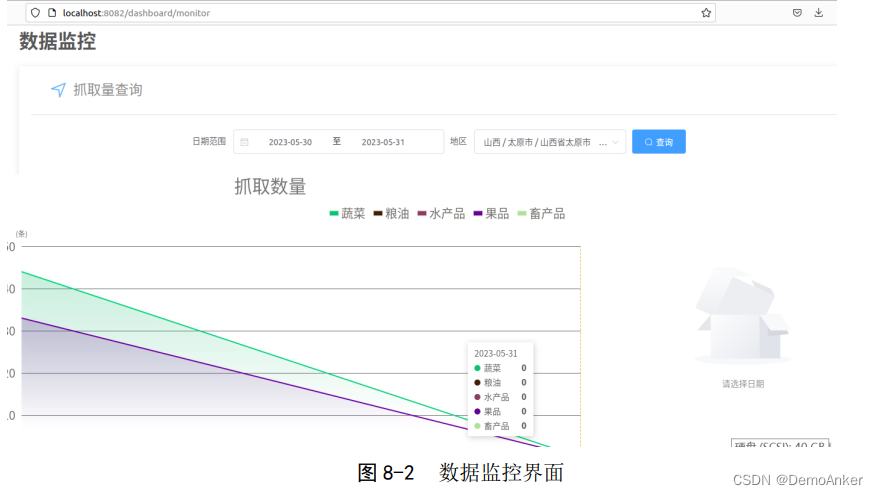
核心后端代码如下:
sprak.py:
import yaml
from pyspark import SparkConf
from pyspark.sql import SparkSession
app_name = "agri-analysis-spark"
master = "local[*]"
conf = SparkConf().setAppName(app_name).setMaster(master)
spark = SparkSession.builder.config(conf=conf).getOrCreate()
spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true")
mysql_config = {}
mysql_url = ""
def init_sql(config_name):
global mysql_config
global mysql_url
mysql_config = yaml.load(open('app/config/database.secret.yml'),
Loader=yaml.SafeLoader)[config_name]['database']
mysql_url = f"{mysql_config['jdbc']}://{mysql_config['host']}:{mysql_config['port']}/{mysql_config['database']}"
def df_reader(table, column=None, lower_bound=None, upper_bound=None, num_partitions=None,
predicates=None):
global mysql_config
global mysql_url
return spark.read.jdbc(
url=mysql_url,
table=table,
column=column,
lowerBound=lower_bound,
upperBound=upper_bound,
numPartitions=num_partitions,
predicates=predicates,
properties={
'user': mysql_config['username'],
'password': mysql_config['password']
}
)